
Data Engineering Weekly #209
The Weekly Data Engineering Newsletter


Automate Airflow deploys with built-in CI/CD.
Streamline code deployment, enhance collaboration, and ensure DevOps best practices with Astro's robust CI/CD capabilities.
Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA
Data Council has always been one of my favorite events to connect with and learn from the data engineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. As a special perk for Data Engineering Weekly subscribers, you can use the code dataeng20 for an exclusive 20% discount on tickets!
https://www.datacouncil.ai/bay-2025
Alireza Sadeghi: Open Source Data Engineering Landscape 2025
This article comprehensively overviews the 2025 open-source data engineering landscape, highlighting key trends, active projects, and emerging technologies. It covers nine categories: storage systems, data lake platforms, processing, integration, orchestration, infrastructure, ML/AI, metadata management, and analytics. Key highlights include the rise of DuckDB, zero-disk architectures, the consolidation of open table formats around Apache Iceberg, the growth of single-node processing, the expansion of stream processing engines, the "Catalog War," and the emergence of composable BI stacks and LLMOps.

https://medium.com/@ApacheDolphinScheduler/open-source-data-engineering-landscape-2025-db53ce18d53d
Ernani Castro: A non-beginner Data Engineering Roadmap — 2025 Edition
I often get requests seeking advice on breaking into data engineering and how to keep learning new skills. I found the blog to be a comprehensive roadmap for data engineering in 2025.

https://blog.det.life/a-non-beginner-data-engineering-roadmap-2025-edition-2b39d865dd0b
Jack Vanlightly: Towards composable data platforms
This article explores table virtualization enabled by Open Table Formats (OTFs) like Apache Iceberg, Delta Lake, and Apache Hudi. It allows different data platforms to access and share the same underlying data without copying, treating OTFs as a storage-layer abstraction. The author highlights integrating this concept with stream-to-table materialization (like Confluent's Tableflow), enabling a composable data architecture across the operational and analytical infrastructure.

https://jack-vanlightly.com/blog/2025/2/17/towards-composable-data-platforms
Sponsored: Webinar - The State of Airflow 2025
We asked 5,000+ data engineers how Airflow is shaping the modern DataOps landscape. The results?

💰 Airflow has evolved beyond internal analytics to power business-critical and revenue-generating solutions
🤖 Experienced Airflow users are deploying AI into production faster than the competition
✅ Data engineers have selected Airflow as the de facto DataOps tool of choice
Learn more insights from the largest data engineering survey to date and how the upcoming release of Airflow 3.0 will shape the future of DataOps.
Save Your Spot →
Animesh Kumar, Shubhanshu Jain, and Samadrita Ghosh: Data Products - A Case Against Medallion Architecture
The article presents a case against the Medallion architecture, contrasting it with a Data Product approach. The authors note that Medallion's Bronze-Silver-Gold tiered structure creates a "pull" mechanism, which leads to increased latency, unnecessary data movement, compounded quality issues, and a lack of business context in upstream layers. Conversely, Data Products promote a "push" mechanism, prioritizing business context from the outset, enabling leaner data movement, improving data quality, and enhancing consumption flexibility, ultimately advocating for a model-driven, context-led data foundation.
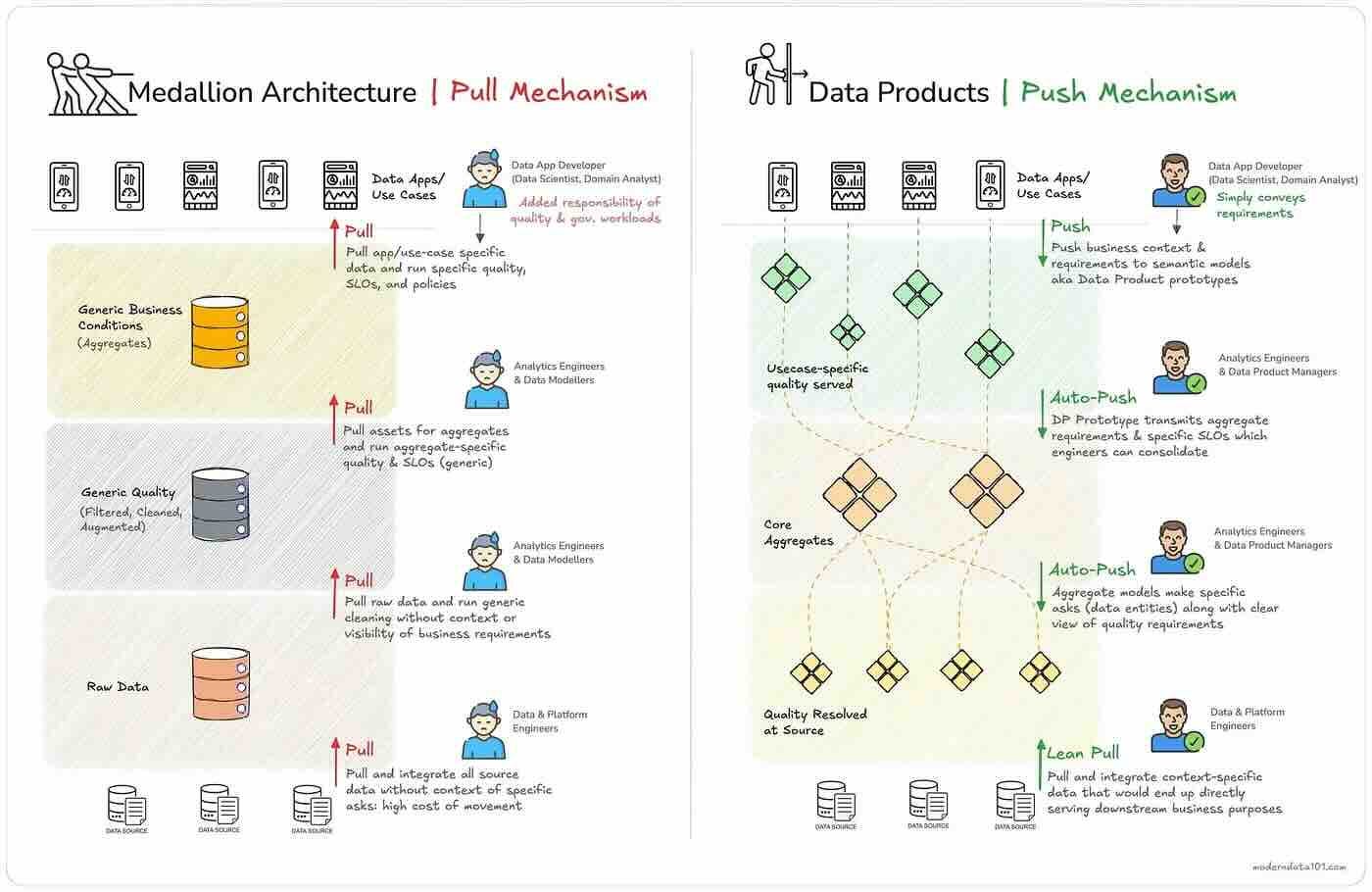
https://medium.com/@community_md101/data-products-a-case-against-medallion-architecture-139096ceea08
Barry McCardel: The myth of measuring “data team ROI.”
What is the ROI of the data team? It is a hard push from the executive team towards the data team. The author highlights that quantifying the ROI of a data team is challenging and often ineffective. Instead, the author suggests measuring the data team's value through stakeholder satisfaction, similar to a Net Promoter Score (NPS). The author emphasizes that data teams are service organizations that support other departments, and their success depends on driving action through insights and gaining advocacy from stakeholders who can articulate the team's value.
https://hex.tech/blog/myth-of-data-team-roi/
Grab: Grab AI Gateway - Connecting Grabbers to Multiple GenAI Providers
Grab writes about its AI Gateway, a centralized platform designed to streamline access to multiple Generative AI (GenAI) providers like OpenAI, Azure, AWS, and Google for Grab employees. The blog narrates the gateway's purpose: simplifying access, enabling experimentation, achieving cost-efficiency, and providing auditing and platformization benefits. The article details the architecture, user journey, features (like exploration keys, unified API, and dynamic routing), challenges faced, current use cases, plans for a model catalog, out-of-the-box governance, and smarter rate limits.
https://engineering.grab.com/grab-ai-gateway
Yelp: Revenue Automation Series: Building Revenue Data Pipeline
Yelp writes about its journey to automate revenue recognition by building a revenue data pipeline. The blog analyzes the ambiguity in translating ambiguous accounting requirements into engineering-friendly specifications, performing data gap analysis, and evaluating different system design options, ultimately choosing a Data Lake + Spark ETL approach.
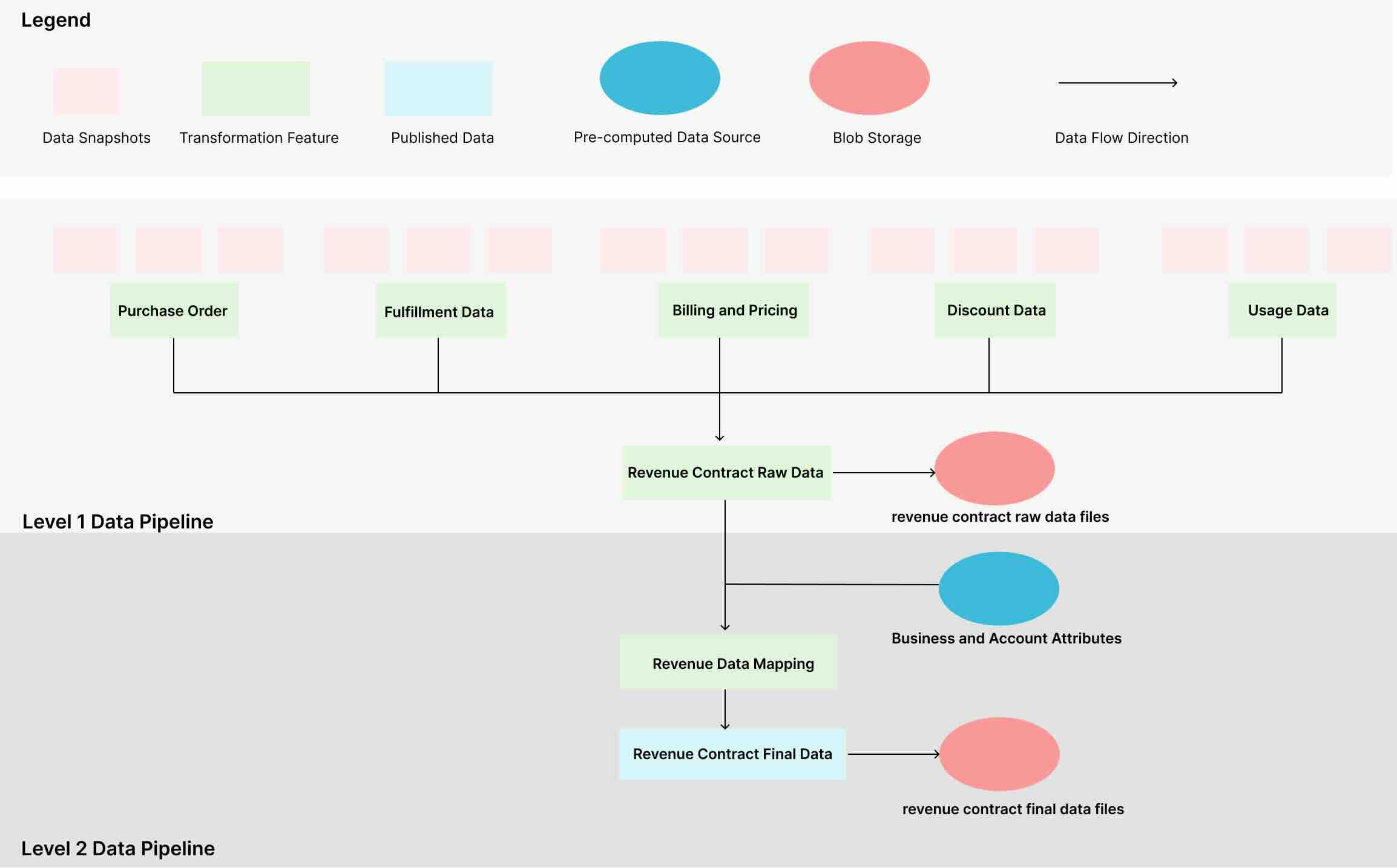
Gusto: Tackling AI Hallucinations in LLM Apps
Gusto writes about using token log probabilities in large language models (LLMs) like GPT to predict and mitigate AI hallucinations. The blog narrates how the LLM confidence, measured as the average log probability of generated tokens (Seq-Logprob), correlates with output quality, and by monitoring and setting thresholds for this confidence score, developers can reject low-quality responses, trigger a human review, or gather more information to improve LLM accuracy.
https://engineering.gusto.com/tackling-ai-hallucinations-in-llm-apps-6d46692f8cac
Apache Kafka: KIP-932 - Queues for Kafka
One exciting weekend read for me was the KIP-932 proposal to add queue guarantees to Apache Kafka. The proposal discusses how Kafka will implement queue functionality similar to SQS and RabbitMQ. RabbitMQ also implemented many parts of stream processing, and I believe at this point, both the queues and event stream processing are merging into the same system offerings.
I wonder if these systems expand more capabilities that eventually fall on their own weight. Let me know in the comments.
https://cwiki.apache.org/confluence/display/KAFKA/KIP-932%3A+Queues+for+Kafka
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.