
Data Engineering Weekly #214
The Weekly Data Engineering Newsletter


Introducing Apache Airflow® 3.0
Be among the first to see Airflow 3.0 in action and get your questions answered directly by the Astronomer team. You won't want to miss this live event on April 23rd!
Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA
Data Council has always been one of my favorite events to connect with and learn from the data engineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. As a special perk for Data Engineering Weekly subscribers, you can use the code dataeng20 for an exclusive 20% discount on tickets!
https://www.datacouncil.ai/bay-2025
BVP: Roadmap: Data 3.0 in the Lakehouse Era
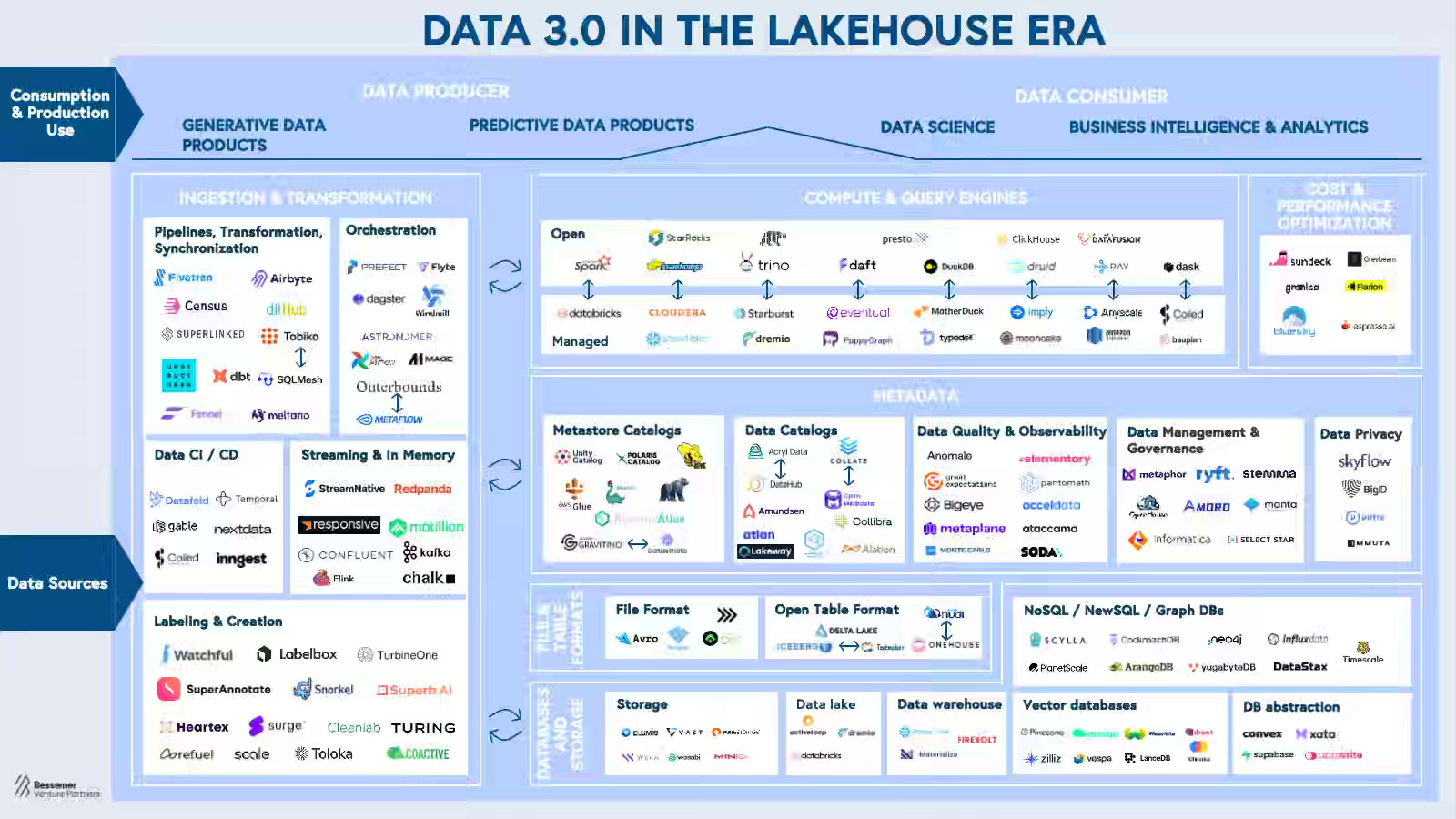
BVP writes about its thesis around Data 3.0 and its challenges and opportunities. A few exciting theses exist around composite data stack, catalogs, and MCP. One thing that stands out to me is
As AI-driven data workflows increase in scale and become more complex, modern data stack tools such as drag-and-drop ETL solutions are too brittle, expensive, and inefficient for dealing with the higher volume and scale of pipeline and orchestration approaches.
https://www.bvp.com/atlas/roadmap-data-3-0-in-the-lakehouse-era
Hamel Husain: A Field Guide to Rapidly Improving AI Products
The article emphasizes that successful AI development depends more on robust evaluation and iterative improvement than merely relying on tools and frameworks. The author highlights several key principles:
• Prioritize error analysis to identify improvements with the highest return on investment (ROI).
• Invest in simple, customized data viewers to efficiently analyze AI outputs.
• Empower domain experts to craft effective prompts directly.
• Leverage synthetic data effectively to bootstrap evaluation processes.
• Ensure trust in evaluation systems through clearly defined criteria and regular alignment checks.
• Structure AI roadmaps around experiments rather than fixed features, enabling continuous learning and adaptation.
https://hamel.dev/blog/posts/field-guide/
Jannik Maierhöfer: Open-Source AI Agent Frameworks: Which One Is Right for You?
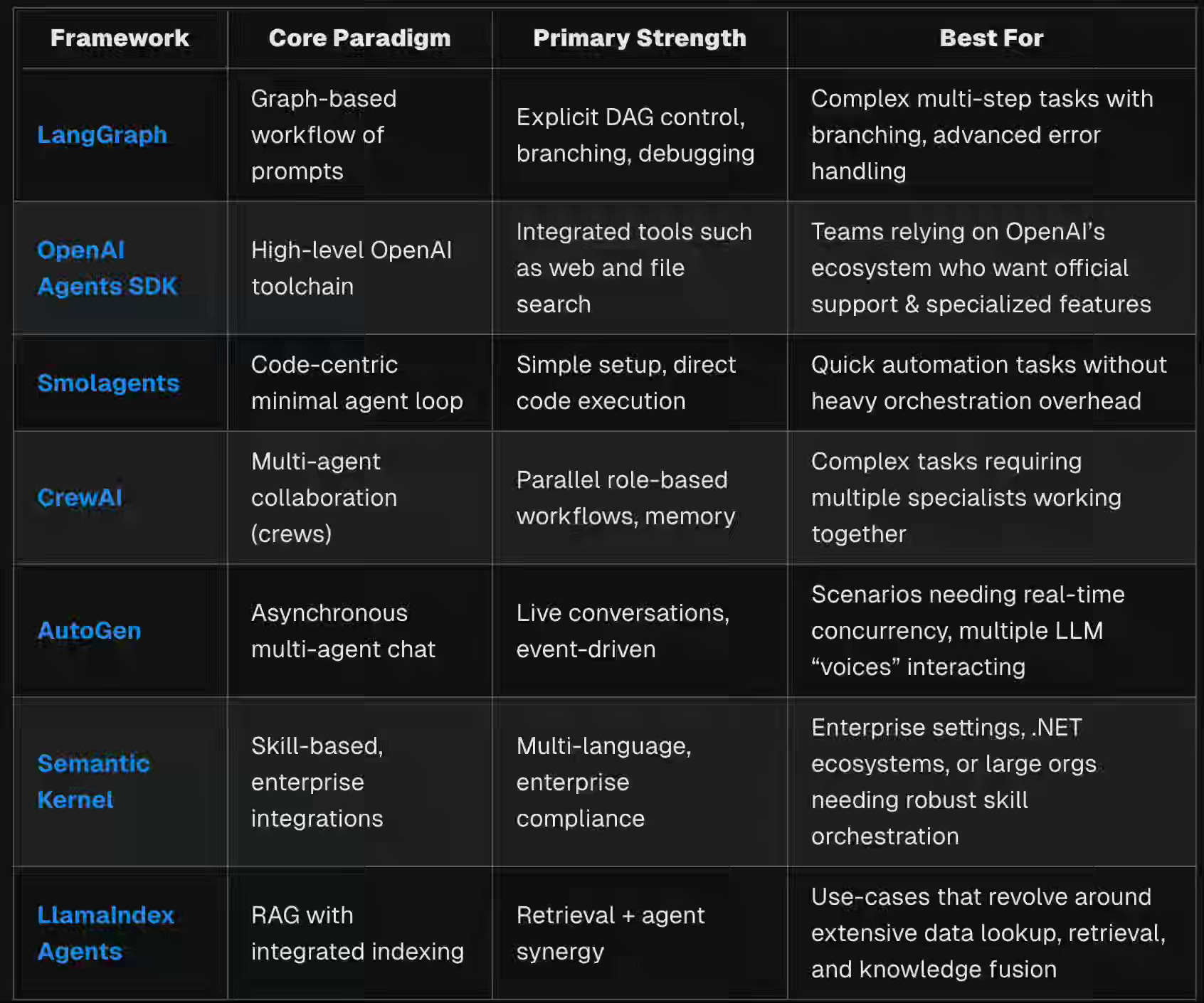
We all bet on 2025 being the year of Agents. It is no surprise that we see the growth of agent frameworks emerging. The blog is an excellent comparison of all the leading agent frameworks in the market now.
https://langfuse.com/blog/2025-03-19-ai-agent-comparison
Sponsored: eBook - Debugging Apache Airflow® DAGs
Written by practitioners, for practitioners. Everything you need to know to solve issues with your DAGs:

✅ Identifying issues during development
✅ Using tools that make debugging more efficient
✅ Conducting root cause analysis for complex pipelines in production
Thoughtworks: How to evaluate an LLM system

It goes to the classic saying, "Everyone wants to build, but no one wants to test." Eval plays a critical role in the growth and maturity of LLM-centric systems. The article provides an excellent overview of evaluating an LLM system.
https://www.thoughtworks.com/insights/blog/generative-ai/how-to-evaluate-an-LLM-system
Apple: Fundamental Challenges in Evaluating Text2SQL Solutions and Detecting Their Limitations
Interacting with the data in natural language is a long-standing quest for data engineers. The paper critically examines the Text2SQL task, highlighting that limitations go beyond model performance to encompass the entire solution pipeline and evaluation process. The study identifies significant data-quality issues and biases in current benchmarks (such as the widely-used Spider dataset), noting that these problems hinder accurate evaluation and real-world application.
Paper: https://arxiv.org/pdf/2501.18197
https://machinelearning.apple.com/research/evaluating-text2sql-solutions
The Autodidacts: On Troubleshooting
We can’t deny the advancement of LLM and AI coding tools bought last year. Coding will never be the same again, but a few fundamental skills can’t be disrupted and will be proven valuable in the age of AI. Debugging and troubleshooting are the most valuable skills to develop, and the author has written an exciting article on them.
https://autodidacts.io/troubleshooting/
Meta: The Power of Asymmetric Experiments @ Meta

Meta discusses the use and benefits of asymmetric experiments (different test and control group sizes) compared to traditional symmetric experiments. The article explains the mathematical trade-off: reducing the test group size while increasing the control group size can maintain the same confidence interval width, which is beneficial when recruitment is cheap but the test intervention is expensive or potentially risky, illustrating this with Meta's use of asymmetric designs for "holdout" experiments to measure the long-term impact of positive product changes while minimizing the number of users held back from the improvement.
https://medium.com/@AnalyticsAtMeta/the-power-of-asymmetric-experiments-meta-8a8030d68c31
Airbnb: How Airbnb Measures Listing Lifetime Value

Airbnb writes about its framework for estimating listing lifetime value (LTV) on its platform, which differs from traditional single-seller models. Airbnb defines and estimates three types of LTV:
Baseline (total bookings over 365 days, predicted using machine learning),
Incremental (baseline LTV adjusted for cannibalization from other listings, estimated via a production function)
Marketing-induced incremental (additional LTV generated by Airbnb initiatives).
The article discusses challenges, including accurate baseline LTV prediction amidst market shocks (like COVID-19), measuring incrementality without direct labels, and handling uncertainty by dynamically updating LTV estimates based on accrued bookings and updated features.
https://medium.com/airbnb-engineering/how-airbnb-measures-listing-lifetime-value-a603bf05142c
Lyka: We built a data lakehouse to help dogs live longer
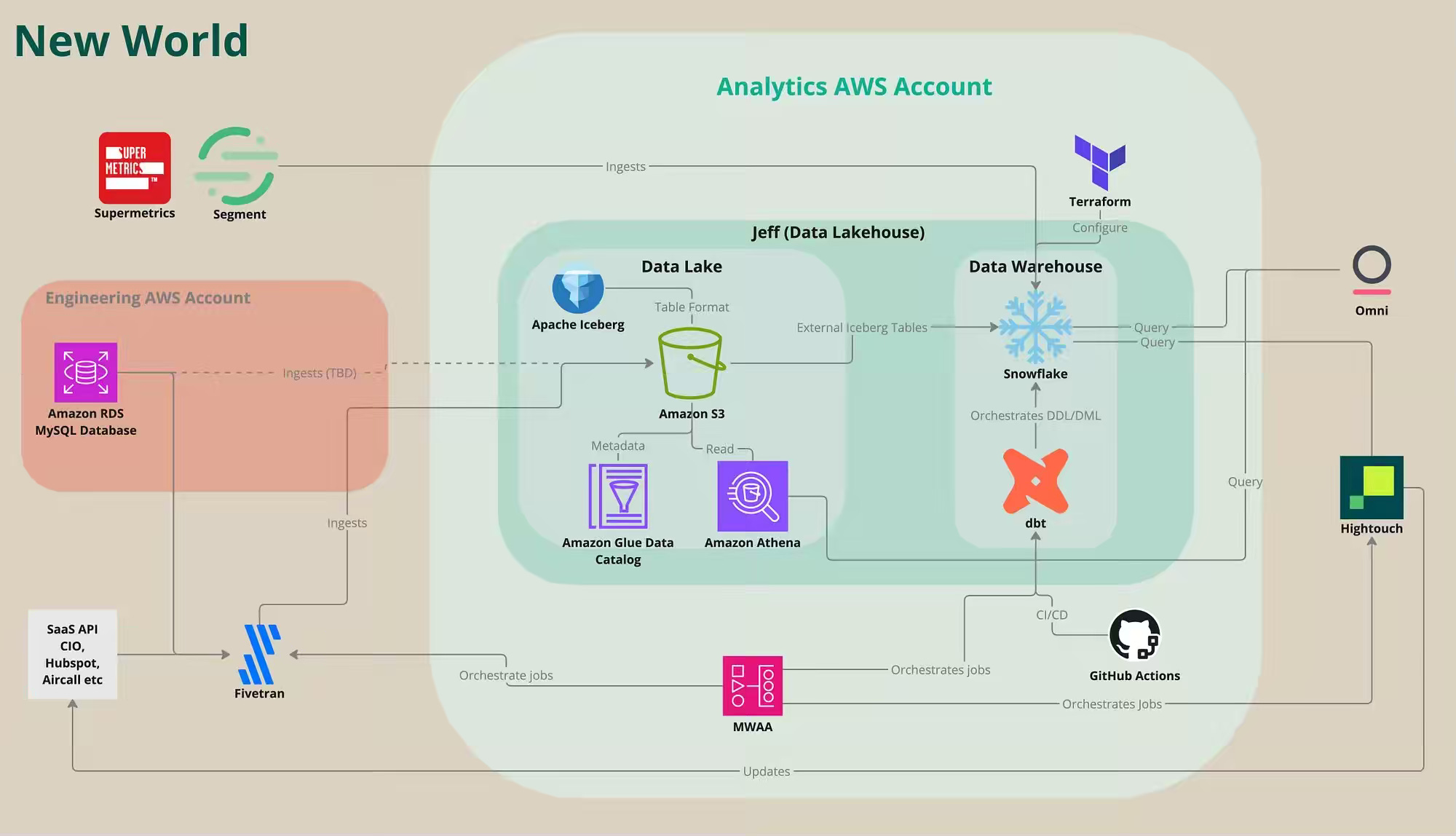
Lyka, a direct-to-consumer dog food company, describes migrating its data analytics platform from Google BigQuery to an AWS-based lakehouse architecture. The new architecture integrates tools like S3, Iceberg, Glue Catalog, Snowflake, Athena, dbt, Airflow, and Omni.
The article outlines key steps in the migration process:
1. Setting up the storage layer:
Established Iceberg tables on Amazon S3.
2. Translating data models:
Converted approximately 400 dbt models from BigQuery SQL to Snowflake SQL, using Claude 3.5 Sonnet for assistance.
3. Adapting to Snowflake’s cost model:
Optimized workflows to align with Snowflake’s pricing and operational model.
4. Implementing comprehensive testing:
Conducted extensive testing at multiple levels, including:
dbt tests
Row-level tests
Aggregate tests
5. Migrating Dashboards:
Migrated approximately 90 dashboards created in Omni.
6. Stakeholder management and change control:
Managed the migration process effectively by emphasizing clear communication, stakeholder engagement, and robust control measures.
https://medium.com/@coreycheung/we-built-a-data-lakehouse-to-help-sell-dog-food-a94f6ea9c648
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.