
Data Engineering Weekly #215
The Weekly Data Engineering Newsletter


Introducing Apache Airflow® 3.0
Be among the first to see Airflow 3.0 in action and get your questions answered directly by the Astronomer team. You won't want to miss this live event on April 23rd!
Thoughtworks: Macro trends in the tech industry
That raises an important question: not whether AI becomes foundational infrastructure, but how we prepare for that without getting caught flat-footed.
The article summarizes the recent macro trends in AI and data engineering, focusing on Vibe coding, human-in-the-loop system design, and rapid simplification of developer tooling.
https://www.thoughtworks.com/insights/blog/technology-strategy/macro-trends-tech-industry-april-2025
Alibaba: AI Virtual Assistants: Current Trends, Challenges & Future
AI virtual assistants like Siri and Alexa exemplify large-scale, real-time data systems in action—blending conversational AI, personalization, and IoT integration. This article highlights their growing complexity, from multimodal interaction to enterprise adoption, underscoring the data and infrastructure challenges beneath the surface. As these assistants evolve, they signal a future where scalable, low-latency data pipelines become essential for seamless, intelligent user experiences.
https://www.alibabacloud.com/blog/ai-virtual-assistants-current-trends-challenges-%26-future_602099
Grab: Facilitating Docs-as-Code implementation for users unfamiliar with Markdown.
One reason why all the engineering documentation fails and quickly becomes outdated is that it is always written from the author's perspective. Unlike coding, we never (or rarely) apply a code review process for documentation.

The Grab blog delights me since I have tried to do this many times. Writing on Github is not intuitive, and Google Docs has poor version and review management. Kudos to the Grab team for building a docs-as-code system.
https://engineering.grab.com/facilitating-docs-as-code-with-markdown
Sponsored: eBook - Debugging Apache Airflow® DAGs
Written by practitioners, for practitioners. Everything you need to know to solve issues with your DAGs:

✅ Identifying issues during development
✅ Using tools that make debugging more efficient
✅ Conducting root cause analysis for complex pipelines in production
Pinterest: Improving Pinterest Search Relevance Using Large Language Models

Using a five-level relevance scale, Pinterest built an LLM-based system to enhance search relevance by mapping Pins to user queries. A cross-encoder teacher model, fine-tuned on human-labeled data and enriched Pin metadata, was distilled into a lightweight student model using semi-supervised learning over billions of impressions. The system demonstrated strong improvements in nDCG@20 and fulfillment rates in offline and online tests, with robust generalization across languages.
LinkedIn: Revenue Attribution Report - how we used homomorphic encryption to enhance privacy and cut network congestion by 99%
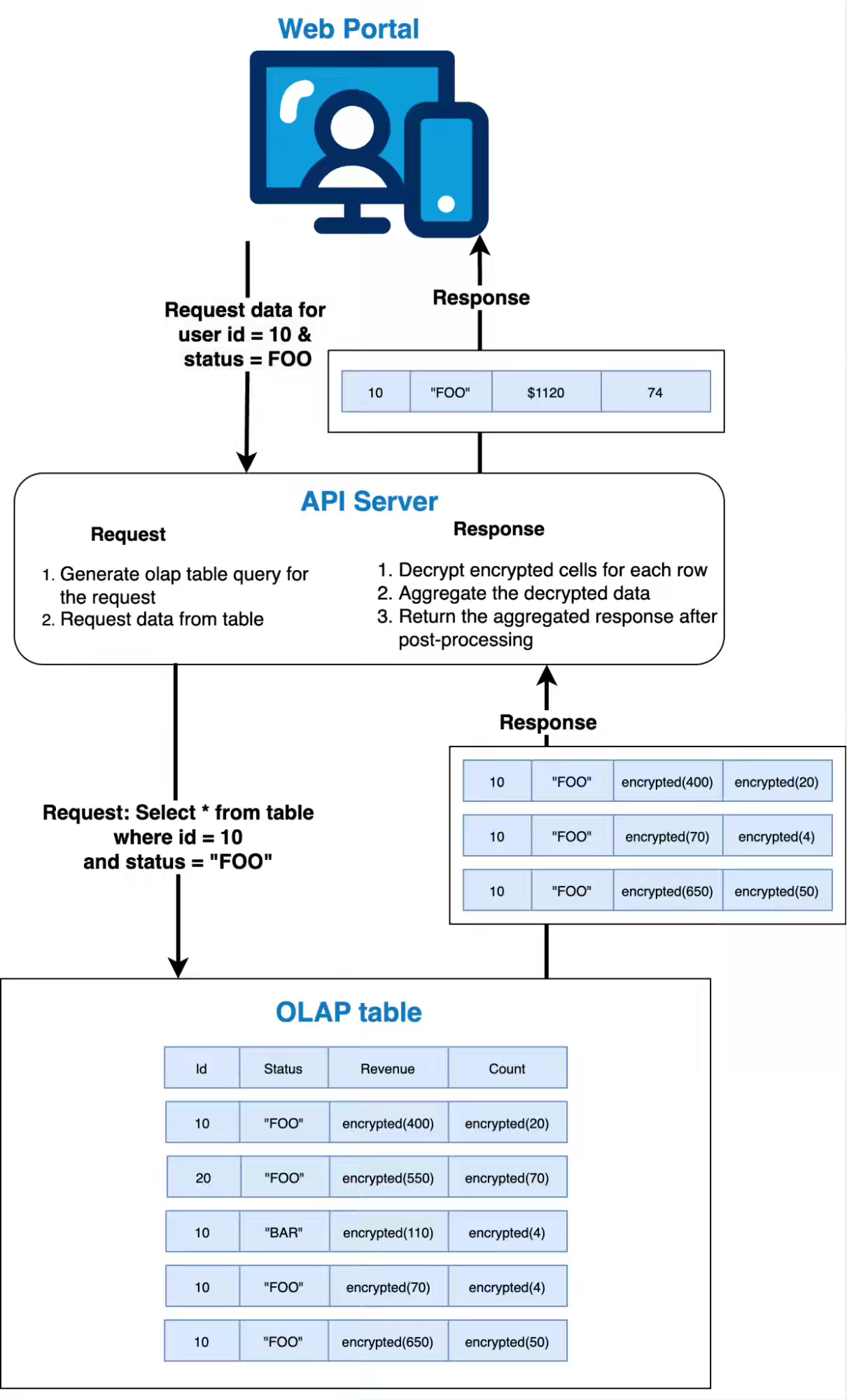
LinkedIn describes enhancing its Revenue Attribution Report (RAR) system, which analyzes encrypted advertiser CRM data and LinkedIn ad activity stored in Apache Pinot, by replacing AES encryption with Additive Symmetric Homomorphic Encryption (ASHE). This new approach allows aggregate queries (like sum) to be computed directly on the encrypted data within Pinot without decrypting individual rows, significantly reducing network traffic (by over 99%), lowering CPU usage, enabling better use of Pinot's aggregation capabilities, and improving privacy by minimizing plaintext data handling, while maintaining low latency.
Zillow: Leveraging Knowledge Graphs in Real Estate Search

Zillow shares an in-depth look into building a real estate Knowledge Graph to unify diverse home-related data sources and enhance user-facing applications like search and personalization. The article outlines a methodical approach—from ontology design to ML-driven entity disambiguation and relationship discovery using SBERT/BERT—that underscores the importance of structured semantics in real-world product impact. I find this a compelling example of operationalizing knowledge graphs at scale, and it highlights the growing convergence of ML, search, and knowledge engineering in building data-driven user experiences.
https://www.zillow.com/tech/leveraging-knowledge-graphs-in-real-estate-search/
Duolingo: How we built a robust ecosystem for dataset development

Duolingo shares how it reimagined data modeling through the lens of software engineering, treating modeled datasets like APIs to enhance consistency, reliability, and developer experience. By introducing code linting, automated data diffs, blue-green-style deployments, and focused observability, they built a resilient, company-wide system for working with raw user interaction data. The approach bridges the data and software engineering gap, offering a practical blueprint for scaling trustworthy data systems.
https://blog.duolingo.com/dataset-development/
GumGum: Switching from Snowpipe to Data Lake Ingestion for Simplicity and Cost Savings
The documentation even reads like it’s better not to define them yourself, as the automatic system will be better and will adjust to dynamic factors. But in a company that does a lot of hourly processing, it feels criminal to me not to have an hour partition field defined on every table referenced by your pipeline.
In one of the recent vendor calls, I heard the exact same phrase: the claim was that our system would be very efficient and the user shouldn’t worry about data distribution. My response: “The user knows their data better than anyone.” This is one of the traps all the vendors and platform teams fall into, which eventually becomes a rigid system. The article reiterates the same.
ManoMano: Handle errors in Spring Kafka consumers like a bliss - retry and DLT reporting for duty

The tiered-topic approach to handling backoff and DLQ made me think deeply about the pattern. I presume the system design is tuned to process recent data without impacting ordering and causing additional Kafka consumer costs.
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.