
Data Engineering Weekly #216
The Weekly Data Engineering Newsletter


Introducing Apache Airflow® 3.0
Be among the first to see Airflow 3.0 in action and get your questions answered directly by the Astronomer team. You won't want to miss this live event on April 23rd!
Stanford HAI: AI Index 2025 - State of AI in 10 Charts
Stanford gives an insight into AI adoption in the industry with the AI adoption. The key factors are
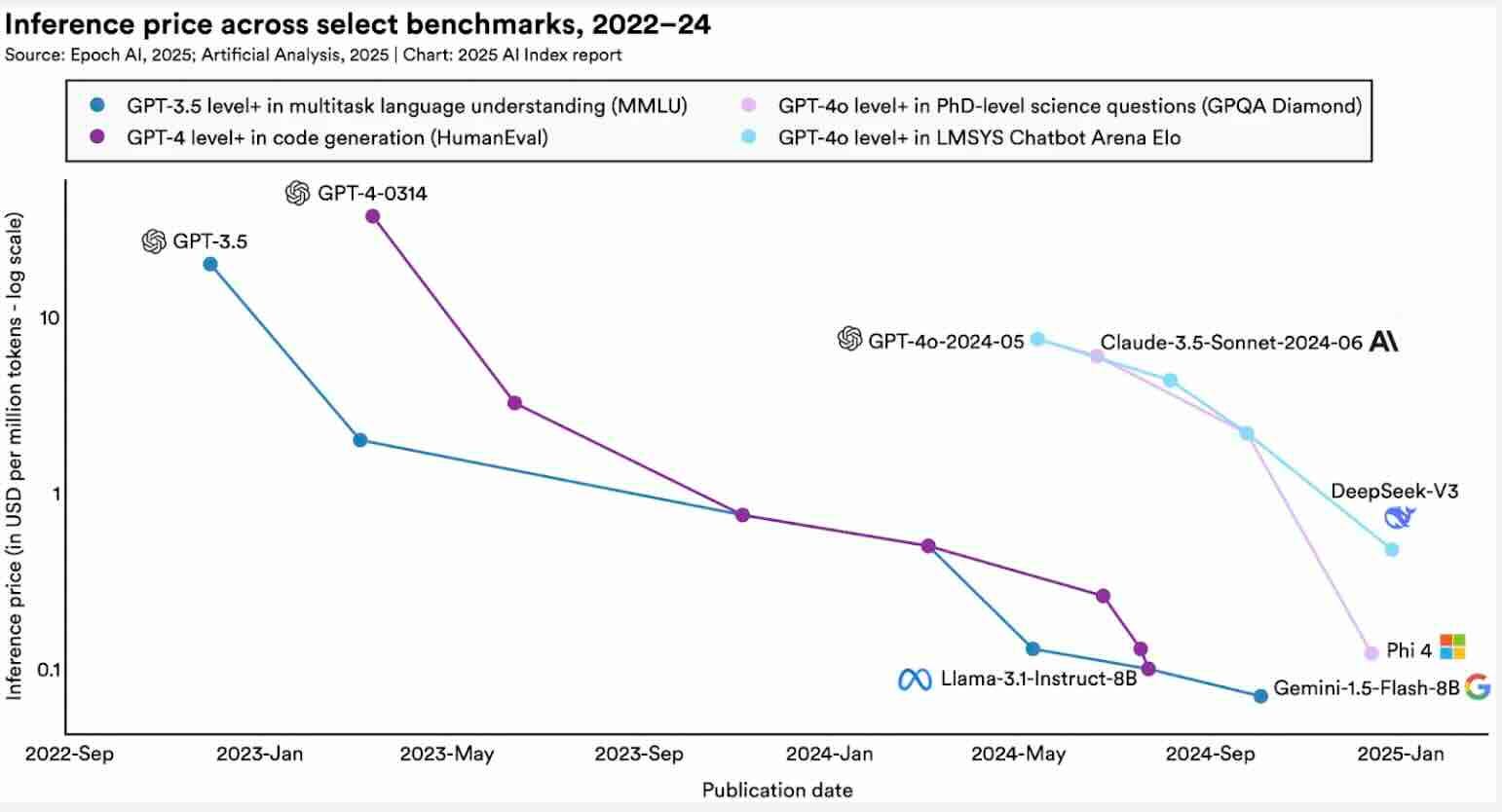
The smaller models are getting better.
The models become cheaper to use
The rise of more useful agents
Both corporate and venture capital are flowing into AI
All the key factors indicate AI is no longer a niche field and is rapidly getting commoditized.
https://hai.stanford.edu/news/ai-index-2025-state-of-ai-in-10-charts
Grab: How Transformers Understand Language - Attention Explained Simply

With the rapid adoption of AI, it is critical to take time to understand the foundation from an abstract reasoning perspective. Grab writes the same about Self-Attention, Multi-Head Attention, and Masked Attention.
Nathan Lambert: RL backlog - OpenAI's many RLs, clarifying distillation, and latent reasoning
The article highlights recent trends in reinforcement learning (RL) and examines OpenAI’s strategic application across products such as the O-series models, Operator agent, Deep Research, and CoPilot. It clarifies misconceptions around DeepSeek R1, emphasizing that DeepSeek leverages RL and latent reasoning models internally to refine thought processes without verbose outputs rather than mere distillation from OpenAI’s o1 model.
https://www.interconnects.ai/p/rl-backlog-openais-many-rls-clarifying
Sponsored: The Ultimate Guide to Apache Airflow® DAGs
Download this free 130+ page eBook for everything a data engineer needs to know to take their DAG writing skills to the next level (+ plenty of example code).

→ Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to
→ Write DAGs that adapt to your data at runtime and set up alerts and notifications
→ Scale your Airflow environment
→ Systematically test and debug Airflow DAGs
By the end of the DAG guide, you'll know how to create and manage reliable, complex DAGs using advanced Airflow features such as those in the screenshot 📸.
Swiggy: Building Rock-Solid ML Systems
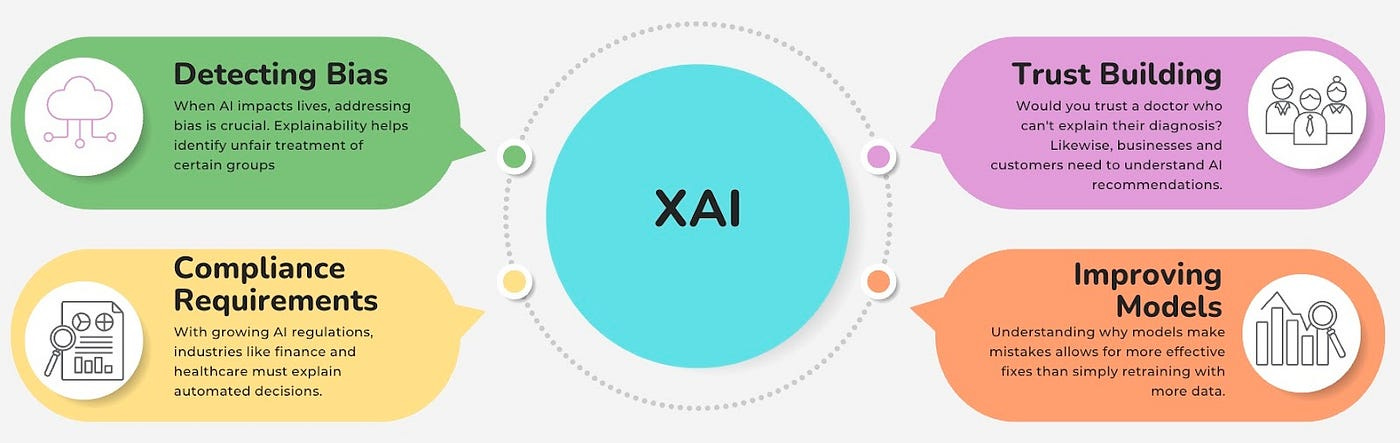
Swiggy shares best practices for operationalizing machine learning (ML), highlighting four core areas:
Rigorous Exploratory Data Analysis (EDA) for anomaly detection and drift monitoring via statistical techniques like Z-scores and KS tests;
Sensitivity Analysis to assess feature importance, set reliable operational bounds, and mitigate outliers;
Explainable AI (XAI) leveraging methods such as SHAP to foster transparency and trust in predictions.
Meticulous Coding Standards, including clean coding practices, collaborative reviews, robust unit testing, and clear documentation.
https://bytes.swiggy.com/building-rock-solid-ml-systems-bb775f8a7126
Discord: Overclocking dbt - Discord's Custom Solution in Processing Petabytes of Data
Discord’s methodical, macro-driven customizations significantly elevate collaboration, performance, and reliability—an exemplary demonstration of thoughtful engineering that tackles practical challenges in large-scale data operations.
Discord details its innovative approach to scaling dbt for petabyte-scale data management across over 2,500 models by introducing custom environment isolation via macros, performance enhancements with configurable incremental processing and “dbt turbo” strategies, precise data backfills through meta field-driven targeted refreshes, and comprehensive CI/CD guardrails using automated cost and dependency analyses.
https://discord.com/blog/overclocking-dbt-discords-custom-solution-in-processing-petabytes-of-data
Wealthfront: Our Journey to Building a Scalable SQL Testing Library for Athena

Wealthfront introduces an in-house SQL testing library tailored for AWS Athena, emphasizing principles of zero-footprint testing via CTEs, usability through Python integration and existing Avro schemas, dynamic test execution, and clear test feedback. They thoughtfully address practical challenges such as logging, SQL-Python type compatibility using custom Pydantic types, SQL length constraints through temporary views, and adoption friction by automating test generation integrated seamlessly into Airflow and CI/CD pipelines.
Apoorv Mittal: Shadow Table Strategy for Seamless Service Extractions and Data Migrations
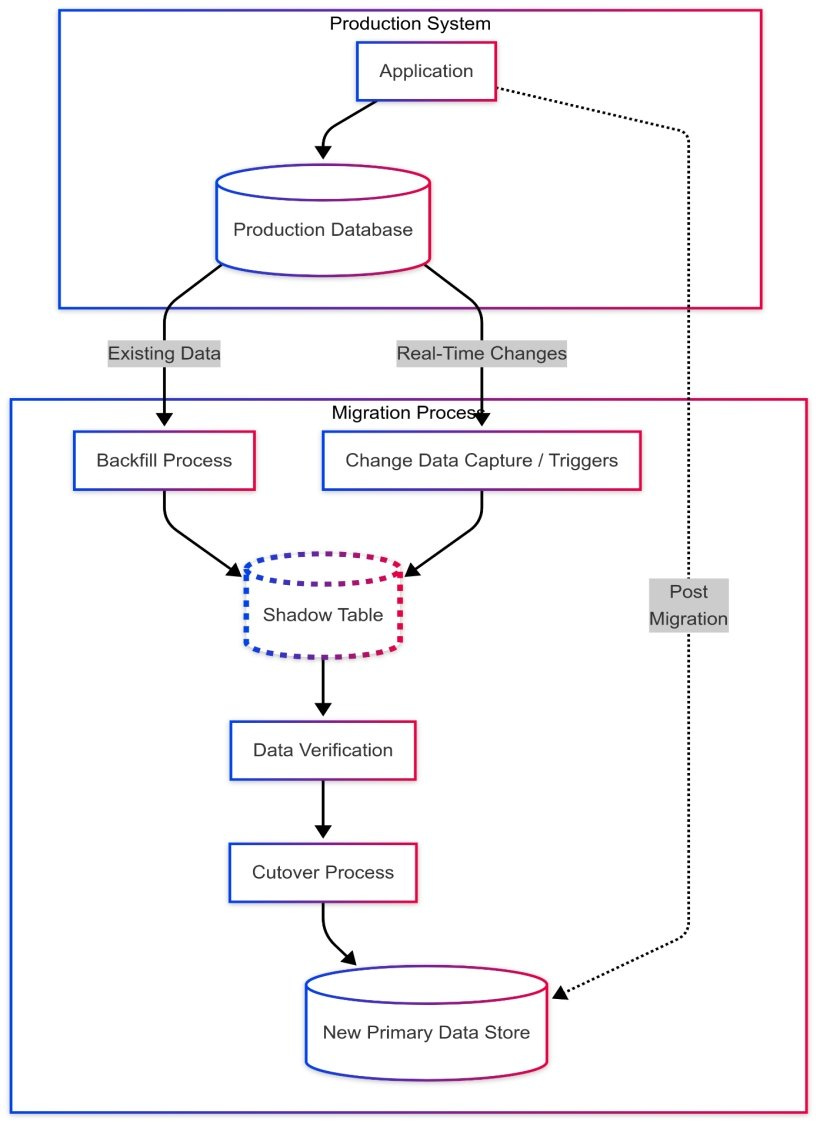
The article introduces the “shadow table” strategy, which manages complex data migrations (such as schema refactoring, microservice extraction, or database upgrades) by maintaining synchronized parallel data copies. This strategy typically uses a pattern of creation, backfilling, real-time synchronization via CDC or triggers, verification, and strategic cutover. The shadow table approach is particularly effective, as it balances control, consistency, and operational safety in critical, large-scale migrations.
https://www.infoq.com/articles/shadow-table-strategy-data-migration/
Agoda: Reducing Runtime Errors in Spark: Why We Migrated from DataFrame to Dataset
The article evaluates Apache Spark’s Dataset versus DataFrame APIs, advocating for Dataset’s compile-time type safety, reduced runtime errors, schema clarity, and maintainability—key for accuracy-focused teams—while acknowledging shared performance optimizations like Catalyst and Tungsten. Although it notes the Dataset’s drawback of needing explicit join conditions, it suggests practical solutions using UDFs and tuple transformations to achieve type-safe joins without sacrificing readability. Despite minor performance trade-offs, Dataset’s benefits significantly enhance correctness, clarity, and long-term maintainability in robust data engineering practices.
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.