
Data Engineering Weekly #217
The Weekly Data Engineering Newsletter


Exclusive look at Apache Airflow® 3.0
Get a first look at all the new features in Airflow 3.0, such as DAG versioning, backfills, and dark mode, in a live session this Wednesday, April 23. Plus, get your questions answered directly by Airflow experts and contributors.
Thoughtworks: AI on Technology Radar
ThoughtWorks' technology radar inspired many enterprises to build their internal tech radars, standardizing and suggesting technology, tools, and framework adoption. The blog took out the last edition’s recommendation on AI and summarized the current state of AI adoption in enterprises.
https://www.thoughtworks.com/insights/blog/machine-learning-and-ai/ai-technology-radar-vol-32
Jing Ge: Context Matters — The Vision of Data Analytics and Data Science Leveraging MCP and A2A

All aspects of software engineering are rapidly being automated with various coding AI tools, as seen in the AI technology radar. Data engineering is one aspect where I see a few startups starting to disrupt. One of the core challenges of data engineering, as the author put it elegantly,
The core difficulty lies in the fact that each step in the process requires specialized domain knowledge. A requirement originating from the business domain must pass through a series of experts, including data analysts, data scientists, data engineers, platform engineers, and infrastructure teams. Each of these groups speaks its own “language” and brings its context.
It leads to building a sequence of agents, integrates well with the existing workflow, and makes data engineering a more interesting problem to solve.
Alex Miller: Decomposing Transactional Systems
I was re-reading Jack Vanlightly's excellent series on understanding the consistency model of various lakehouse formats when I stumbled upon the blog on decomposing transaction systems. The simplistic model expressed in the blog made it easy for me to reason about the transactional system design.

If you want to understand the lakehouse system designs, I recommend reading these blogs a couple of times.
Alex Miller: https://transactional.blog/blog/2025-decomposing-transactional-systems
Jack Vanlightly: https://jack-vanlightly.com/analysis-archive
Marc Brooker: https://brooker.co.za/blog/2025/04/17/decomposing.html
Sponsored: The Ultimate Guide to Apache Airflow® DAGs
Download this free 130+ page eBook for everything a data engineer needs to know to take their DAG writing skills to the next level (+ plenty of example code).

→ Understand the building blocks DAGs, combine them in complex pipelines, and schedule your DAG to run exactly when you want it to
→ Write DAGs that adapt to your data at runtime and set up alerts and notifications
→ Scale your Airflow environment
→ Systematically test and debug Airflow DAGs
By the end of the DAG guide, you'll know how to create and manage reliable, complex DAGs using advanced Airflow features such as those in the screenshot 📸.
Chris Ricommani: Everything You Need to Know About Incremental View Maintenance
When the Timely DataFlow paper came out, I tried my best to understand the paper with little to no success :-) It is still the case tbh, and I’m not alone, but I found Chris's blog to be the closest explanation about the incremental view maintenance that reignites my curiosity to learn more about it. With the chatGPTs as your knowledge assistance, I hope to get this time around :-)
https://materializedview.io/p/everything-to-know-incremental-view-maintenance
TopicPartition: KIP-1150 in Apache Kafka is a big deal (Diskless Topics)
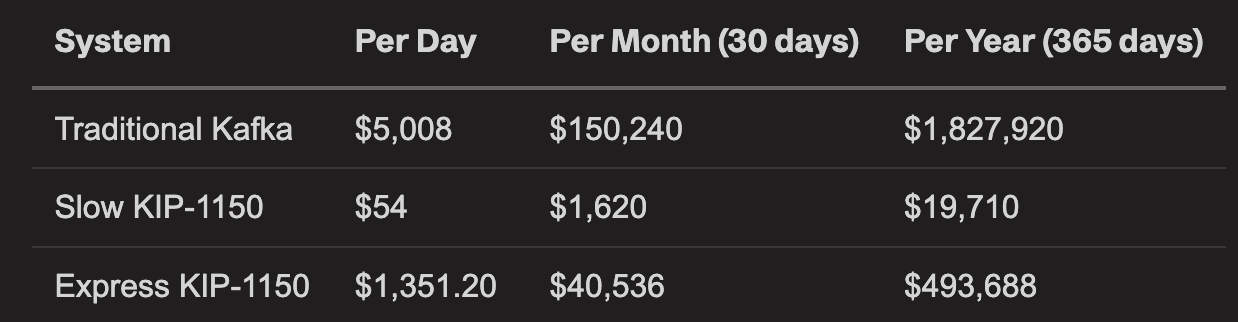
When I saw the KIP-1150 proposal, I was like, okay, finally it is happening. Kafka is probably the most reliable data infrastructure in the modern data era. The popularity also exposes its Achilles heel, the replication and network bottlenecks. With AWS rapidly slicing the cost of S3 Express, the blog makes a solid argument that disk-based Kafka is 3.7X expensive than diskless Kafka out of S3 Express One.
https://topicpartition.io/blog/kip-1150-diskless-topics-in-apache-kafka
AWS: Prime Video improved stream analytics performance with Amazon S3 Express One Zone

Continue on the slow but steady impact of S3 Express One in the data infrastructure, the AWS team writes about how adopting Express One to save Flink checkpoints significantly improves its performance.
It makes me think, what could the impact of a similar system design be in a Lakehouse architecture? Apache Hudi, for example, introduces an indexing technique to Lakehouse. We all know that data freshness plays a critical role in the performance of Lakehouse. If we can place the metadata, indexing, and recent data files in Express One, we can potentially build a Snowflake-style performant architecture in Lakehouse.
Alibaba: Xiaomi's Real-Time Lakehouse Implementation - Best Practices with Apache Paimon
As Iceberg is getting growing adoption, I also noticed some of its weaknesses popping up around the real-time data ingestion, upsert operations, and incremental data processing. The blog from Xiaomi on adopting Poimon narrates the challenges around Iceberg with equality deletes.
Agoda: How Agoda Uses GPT to Optimize SQL Stored Procedures in CI/CD
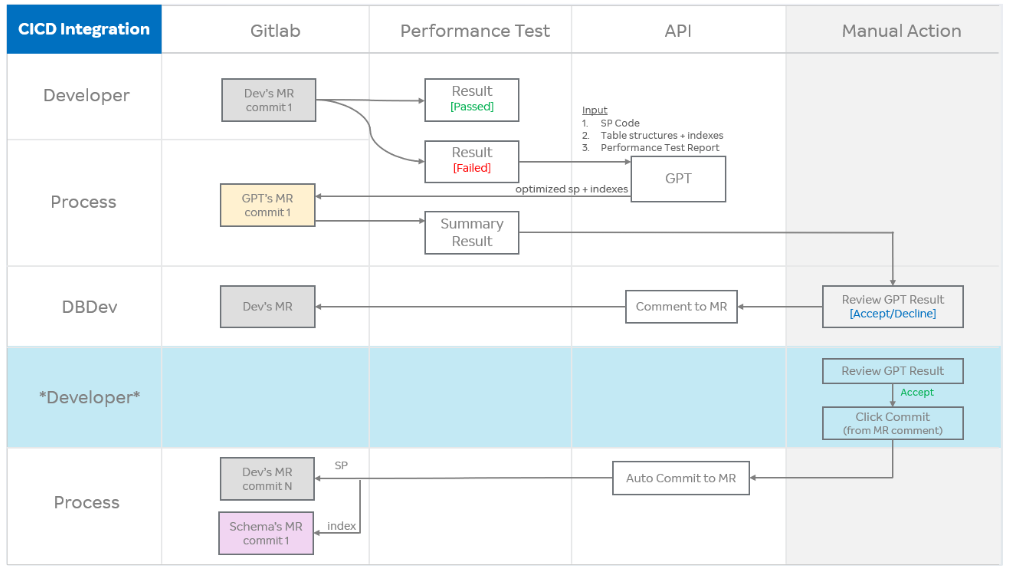
Agoda integrated GPT into its CI/CD pipeline to optimize SQL stored procedures by feeding the model SP code, schema definitions, and performance metrics, then surfacing optimized queries and indexing recommendations as merge requests. This AI‑driven workflow has slashed manual review effort, accelerated approvals, and materially improved SP quality, exemplifying a practical way to boost database developer productivity.
Swiggy: Business Monitoring at Swiggy [Part 1]: Apache Superset at Scale

Swiggy writes about transforming Apache Superset into a high‑performance monitoring platform by tuning Gunicorn’s worker configuration and migrating from Databricks Classic Warehouse to a Serverless Warehouse to eliminate timeouts and shutdowns. The strategic embedding of dashboards, the development of custom plugins, and the creation of a mobile UI to align analytics with diverse internal workflows is an excellent read to think about building an in-house BI system.
https://bytes.swiggy.com/business-monitoring-at-swiggy-apache-superset-at-scale-b784d0c4012d
Booking.com: Anomaly Detection in Time Series Using Statistical Analysis
If you’re looking to build an anomaly detection out of time series data (which is pretty common in the data engineering workflow), this is an interesting read. In the data pipeline, we have many commercial anomaly detection tools available, and often expensive ones.
I wonder if anyone has tried building a Prometheus exporter for a data pipeline to hook some of the anomaly detection (not the infrastructure, but the data itself)? Please comment if you’ve done so, I would love to discuss the design.
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.