
Data Engineering Weekly #218
The Weekly Data Engineering Newsletter


Try Apache Airflow® 3 on Astro
Airflow 3 is here and has never been easier to use or more secure. Spin up a new 3.0 deployment on Astro to test DAG versioning, backfills, event-driven scheduling, and more.
Chip Huyen: Exploring three strategies - functional correctness, AI-as-a-judge, and comparative evaluation
As AI development becomes mainstream, so does the need to adopt all the best practices in software engineering. The author emphasises the need for evaluation-driven development, inspired by test-driven development. The author walks through three broad categories of evaluation-driven development.
functional correctness
AI-as-a-judge
comparative evaluation
https://queue.acm.org/detail.cfm?id=3722043
OpenAI: A practical guide to building agents
OpenAI publishes a comprehensive guide on building AI Agents. The guide walks through three core components of AI Agents.
Model
Tools
Instructions
https://cdn.openai.com/business-guides-and-resources/a-practical-guide-to-building-agents.pdf
Anthropic: Claude Code - Best practices for agentic coding
Coding is one of the fastest domains to adopt large language models, and Claude is recognized as one of the most effective models for coding tasks. Claude outlines best practices for agent coding, including connecting with Git and a walkthrough of the explore, plan, code, and commit ” model.
https://www.anthropic.com/engineering/claude-code-best-practices
Sponsored: Airflow 3 Deep Dive Series
This introduction to Apache Airflow® 3 series will cover everything you need to know, from feature deep dives to upgrade preparedness tips.

Join Airflow experts and contributors to learn:
- Tips to improve your productivity with DAG versioning and backfills
- How to use new features like data assets and event-driven scheduling
- New architectural changes that allow you to run tasks anywhere, any time
Register now to join the Astronomer webinar series to learn everything you need to know to take advantage of this release.
Register Now →
Sebastian Raschka: The State of Reinforcement Learning for LLM Reasoning
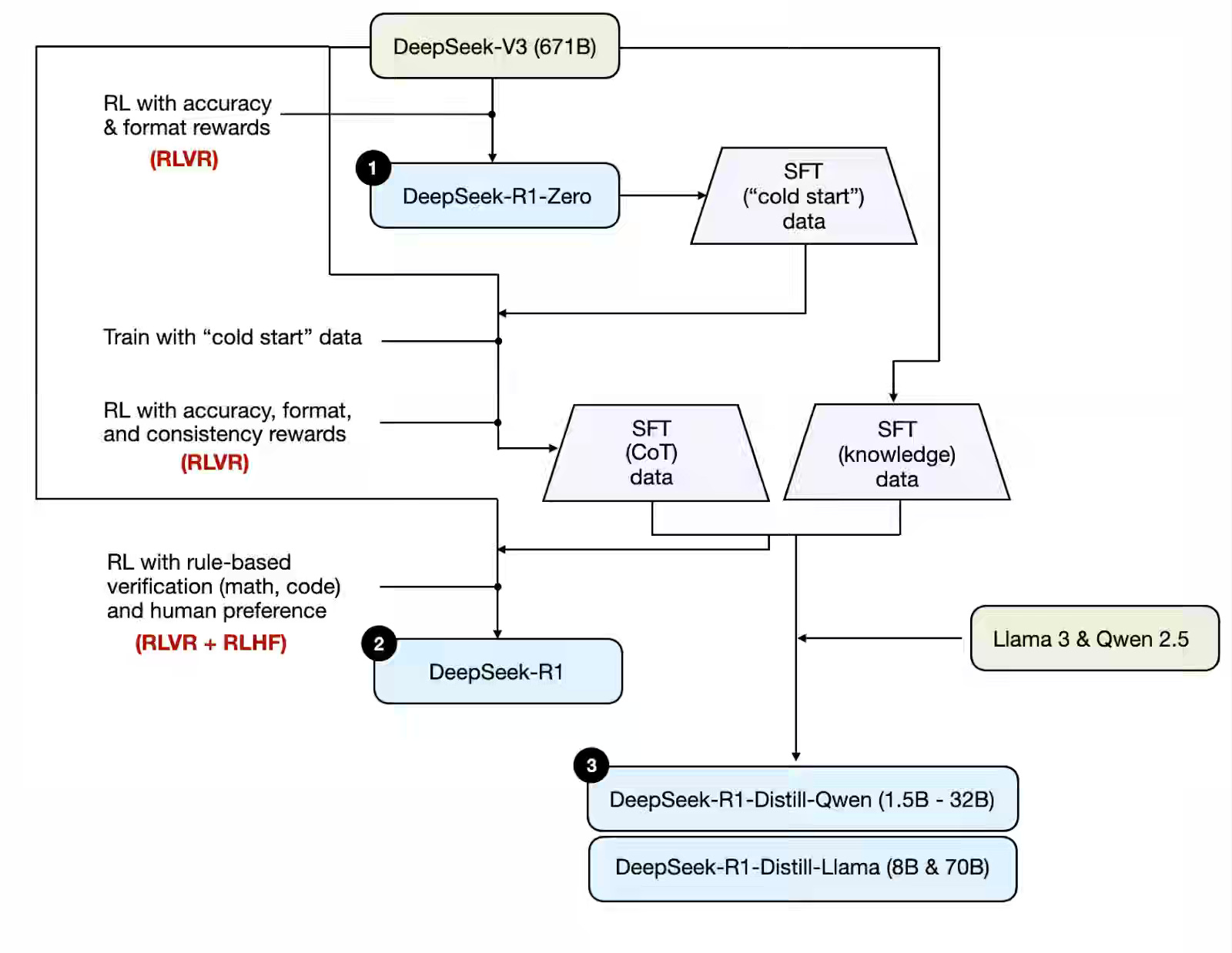
The author explores recent developments in reinforcement learning (RL) for enhancing large language model (LLM) reasoning, with a focus on training-time methods. Proximal and Group Relative Policy Optimization, together with DeepSeek-R1’s RL with Verifiable Rewards, show that well-shaped rewards not only tighten LLM reasoning but also curb “too-long-yet-wrong” answers and coax emergent self-verification that transfers to search and other domains.
https://sebastianraschka.com/blog/2025/the-state-of-reinforcement-learning-for-llm-reasoning.html
Discord: How Discord Indexes Trillions of Messages

Discord writes about its message-search stack from a monolithic, Redis-queued Elasticsearch cluster to a Kubernetes-based, cell architecture-backed Elasticsearch deployment managed by ECK, pairing Pub/Sub-driven ingestion with an index-aware router, user-sharded DM search, and dedicated multi-shard “BFG” cells for supersized guilds. I find Discord’s approach a persuasive blueprint for any high-growth platform: treat search as a fleet of right-sized, self-healing cells, and you gain resilience, upgrade agility, and capacity headroom without rewriting your query layer.
https://discord.com/blog/how-discord-indexes-trillions-of-messages
LinkedIn: Powering Apache Pinot ingestion with Hoptimator
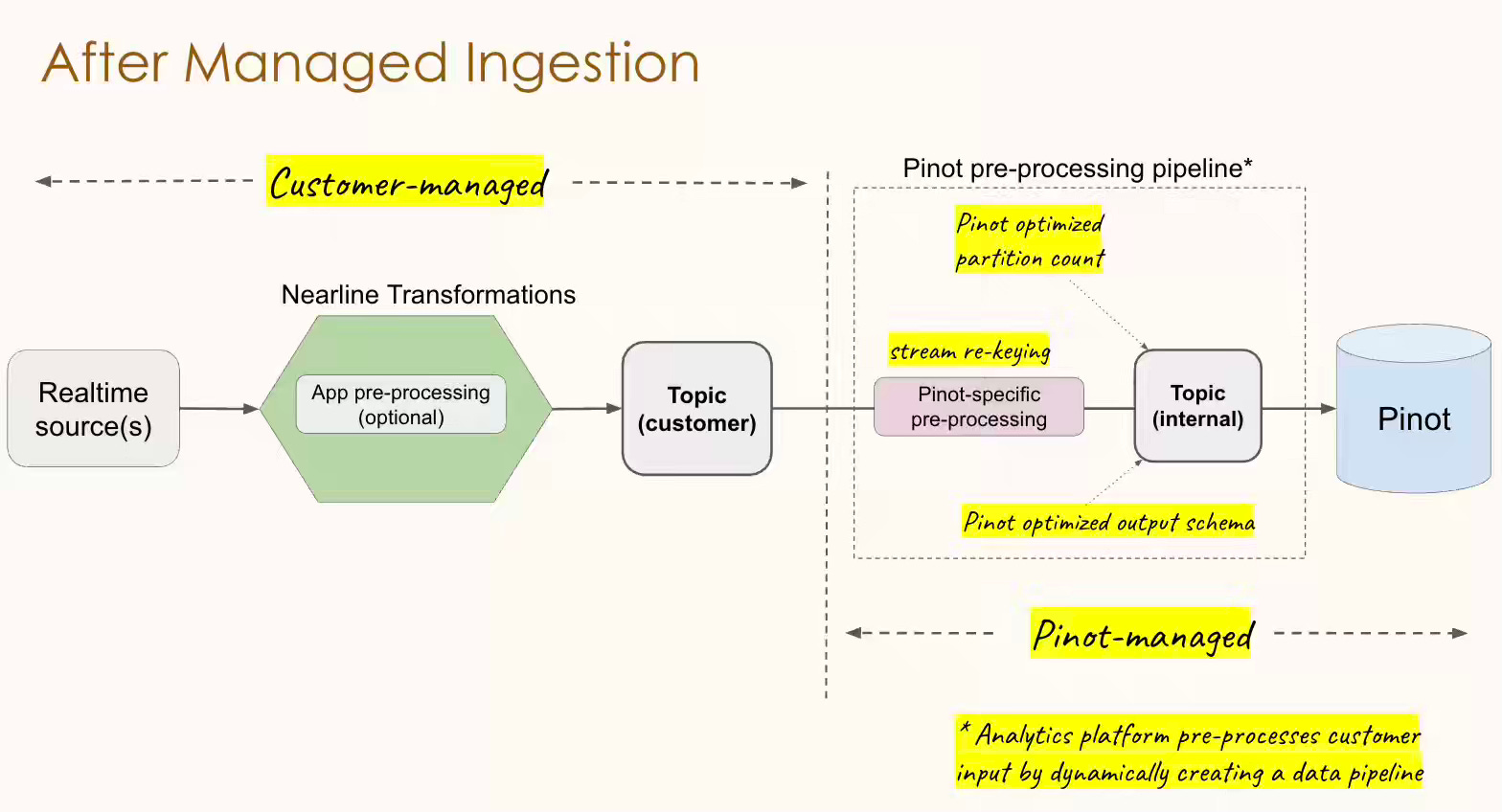
LinkedIn discusses Hoptimator, a system that enables consumer-driven, managed ingestion pipelines, specifically for Apache Pinot. Before Hoptimator, Pinot ingestion often required data producers to create and manage separate, Pinot-specific preprocessing jobs to optimize data, such as re-keying, filtering, and pre-aggregating. With Hoptimator, Pinot itself can dynamically create, control, and optimize these ingestion pipelines via a Subscription API, using Flink SQL jobs orchestrated by Hoptimator to deliver data tailored to Pinot's needs (correct fields, partitioning, etc.), reducing user friction, operator toil, and resource consumption on Pinot servers, while automating pipeline management.
Zomoto: Eliminating Bottlenecks in Real-Time Data Streaming - A Zomato Ads Flink Journey
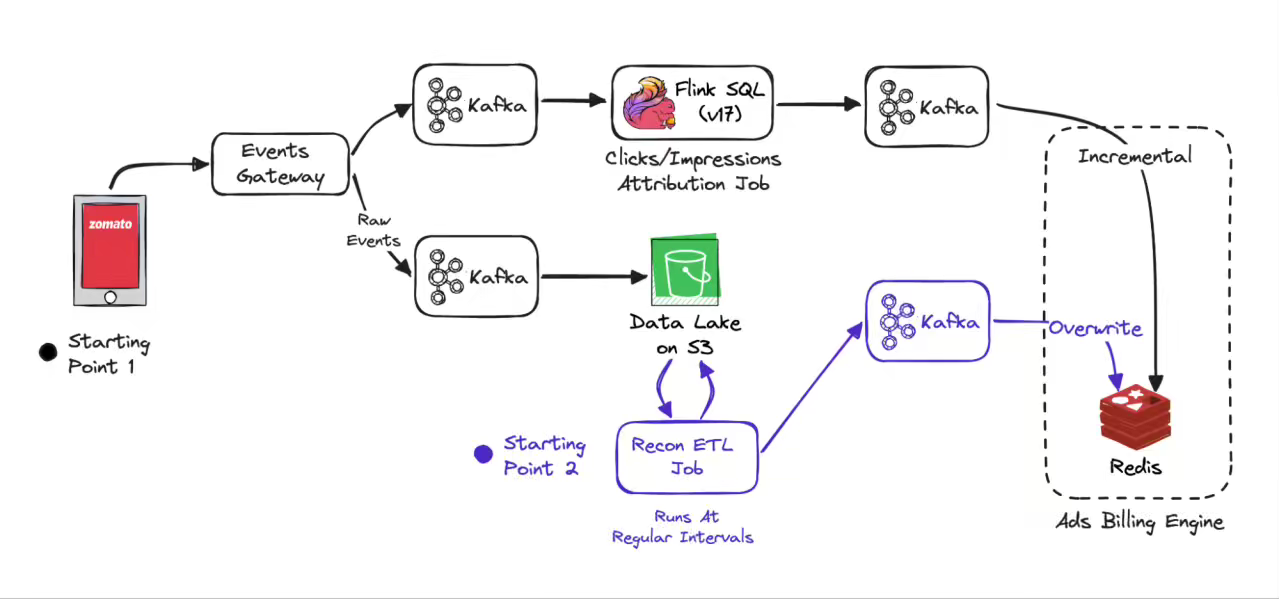
Zomato writes about replacing a brittle 150 GB Flink Java job with a lean Flink SQL pipeline, offloading late-event handling to a reconciliation ETL on S3, emitting incremental rather than daily aggregates, and reducing the deduplication TTL from 24 hours to 2 hours. The redesign reduced state size by more than 99%, saved over $3,000 per month, and delivered zero-downtime reliability with far simpler operations. Treating state as a cost to be minimised—not a convenience—turns Flink from a liability into a flexible, low-maintenance growth lever.
Kakao Tech: Iceberg Operation Journey: Takeaways for DB & Server Logs

The article details methods for loading and optimizing two types of logs (database change logs [DB logs] and server logs) into Apache Iceberg tables using Apache Flink. The article explores compression strategies (finding zstd level 9 optimal for server logs despite increased CPU usage), partitioning approaches (addressing timezone issues with string-based identity partitioning for server logs), optimization techniques (binpack compaction, partial progress, delayed cleanup), and monitoring methods (using Trino/Spark metadata tables and Prometheus/Grafana) for maintaining Iceberg table health and performance.
https://tech.kakao.com/posts/695
Confluent: Guide to Consumer Offsets - Manual Control, Challenges, and the Innovations of KIP-1094
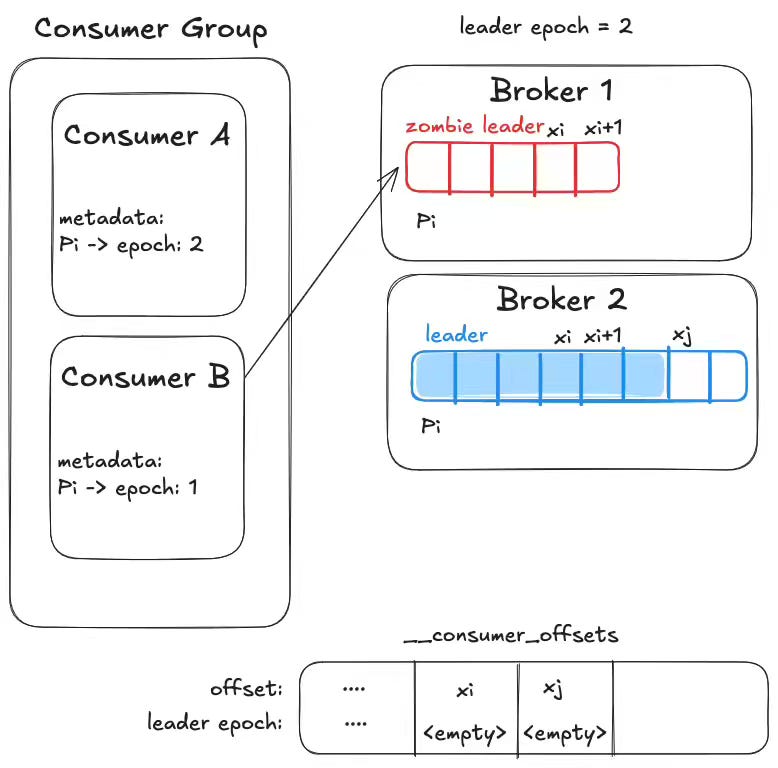
The article provides a comprehensive guide to Kafka consumer offsets, explaining their role in tracking consumption progress and the importance of manual offset control for reliability and exactly-once semantics (EOS). The blog outlines the challenges of traditional offset management, including inaccuracies stemming from control records and potential issues with stale metadata during leader changes. It highlights the benefits of committing the leader epoch alongside the offset. Finally, it introduces KIP-1094 (available in Kafka 4.0.0), which addresses these challenges by adding a nextOffsets method to ConsumerRecords, providing consumers with the accurate next offset and leader epoch directly from the poll response, thus enabling more precise and reliable offset commits.
https://www.confluent.io/blog/guide-to-consumer-offsets/
Databricks: Deep Dive - How Row-level Concurrency Works Out of the Box

Databricks discusses how Liquid Clustering, combined with row-level concurrency, simplifies managing concurrent writes in Delta Lake tables, thereby eliminating the need for complex partitioning strategies or error-prone retry loops that are often required with traditional approaches. The article explains that row-level concurrency, automatically enabled with Liquid Clustering or deletion vectors, detects conflicts at the row level, allowing multiple writes to succeed even if they modify the same data file, as long as they don't touch the same rows, leveraging deletion vectors and row tracking to reconcile changes efficiently during commit time.
https://www.databricks.com/blog/deep-dive-how-row-level-concurrency-works-out-box
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.