
Data Engineering Weekly #219
The Weekly Data Engineering Newsletter


Try Apache Airflow® 3 on Astro
Airflow 3 is here and has never been easier or more secure. Spin up a new 3.0 deployment on Astro to test DAG versioning, backfills, event-driven scheduling, and more.
Editor’s Note: OpenXData Conference - 2025 - A Free Virtual Event
A free virtual event on open data architectures - Iceberg, Hudi, lakehouses, query engines, and more. Talks from Netflix, dbt Labs, Databricks, Microsoft, Google, Meta, Peloton, and other open data geeks.
May 21st, 9 am—3 pm PDT. There will be no fluff. You will experience solid content, good vibes, and a live giveaway!
Kirill Bobrov: Data Engineering: Now with 30% More Bullshit
So we beat on, boats against the current, borne back ceaselessly into the past. -The Great Gatsby
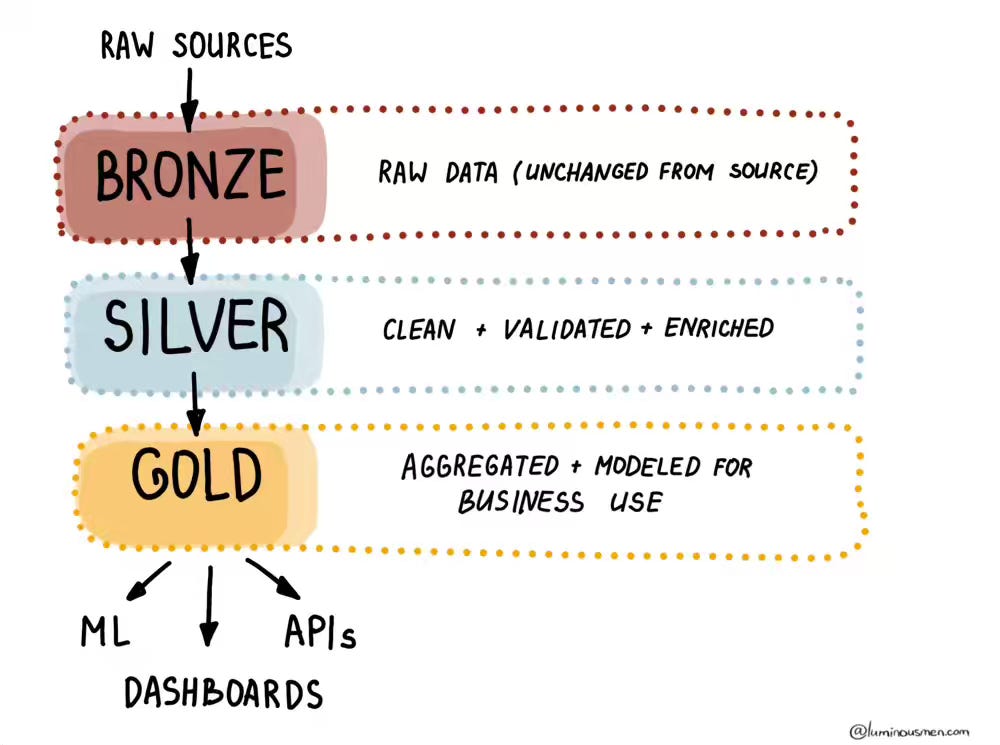
The author demonstrates that building a reliable data engineering practice is hard, then and now, no matter what terminology or naming we use. The fundamental complexity remains the same, and a deep understanding is essential to build data engineering practices.
https://luminousmen.com/post/data-engineering-now-with-30-more-bullshit
Matt Foster: From Architecture to Deployment - How AI-Powered Toolkits Are Unifying Developer Workflows
Many architectural practices, such as documentation generation, test suggestions, and architecture diagramming, are ignored due to time and cost pressure. The blog highlights how emerging AI tools automate otherwise cognitively intensive manual tasks to bring reliability in software engineering.
https://www.infoq.com/news/2025/05/ai-toolkit-unify-workflows/
Uber: Fixrleak - Fixing Java Resource Leaks with GenAI

Another interesting article from Uber demonstrates how AI significantly accelerates the reliability effects. Uber writes about FixrLeak, a generative AI-based framework that automates the detection and repair of resource leaks. FixrLeak combines Abstract Syntax Tree (AST) analysis with generative AI (GenAI) to produce accurate, idiomatic fixes while following Java best practices like try-with-resources.
https://www.uber.com/blog/fixrleak-fixing-java-resource-leaks-with-genai/
Meta: How Meta understands data at scale

Meta describes its data management practices as adopting a “shift-left” approach, integrating data schematization and annotations early in product development. The recommendation engine to find the data flow violation is an interesting design to monitor the data assets at scale.
https://engineering.fb.com/2025/04/28/security/how-meta-understands-data-at-scale/
Pinterest: Multi-gate-Mixture-of-Experts (MMoE) model architecture and knowledge distillation in Ads Engagement modeling development
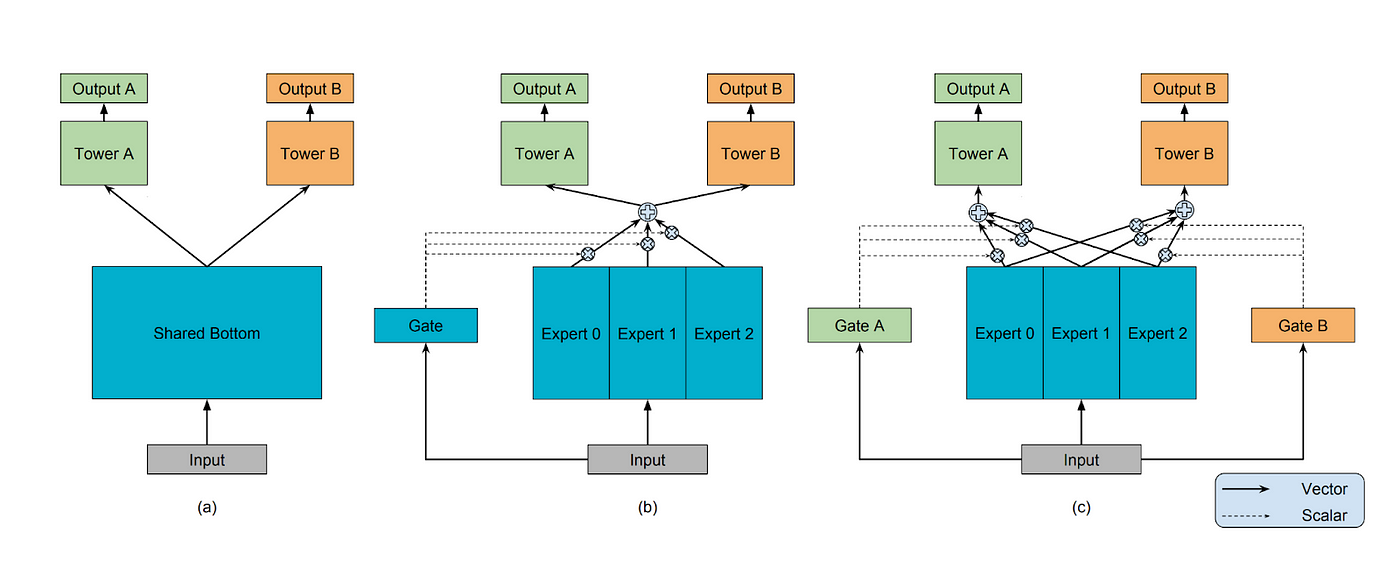
Pinterest writes about adopting Multi-gate Mixture-of-Experts (MMoE) architecture for its ad engagement models to improve performance beyond traditional deep learning models like DCNv2. Pinterest found MMoE effective, particularly with DCNv2 experts and lightweight gates, optimized serving costs using mixed precision inference (reducing latency by 40%), and addressed the challenge of limited data retention periods by using knowledge distillation (with a pairwise loss) from production models during batch training to transfer knowledge from older, deleted data to new experimental models.
Whatnot: Evolving Feed Ranking at Whatnot
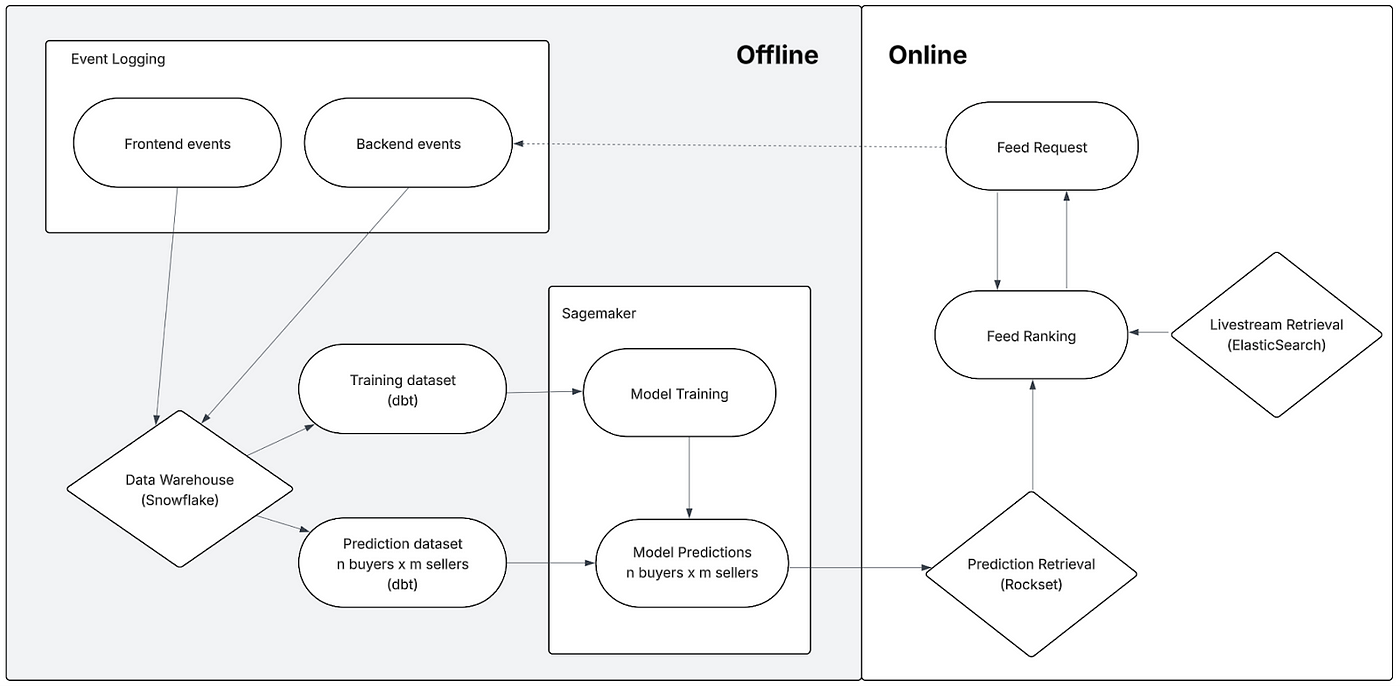
Whatnot describes their transition from a batch prediction system to an online inference framework for ranking, which is shown in their "For You Feed." The initial batch system, which pre-calculated watch/purchase likelihood for all buyer-seller pairs daily, faced O(nm) scaling issues, couldn't utilize real-time show-level features, suffered from data staleness, and had cold-start problems. The blog narrates the new online inference system-generated predictions at request time using real-time features retrieved from their feature store (Chalk) and how it significantly improved feed relevance and drove substantial increases in GMV, orders, and watch time.
https://medium.com/whatnot-engineering/evolving-feed-ranking-at-whatnot-25adb116aeb6
Dropbox: Building Dash: How RAG and AI agents help us meet the needs of businesses
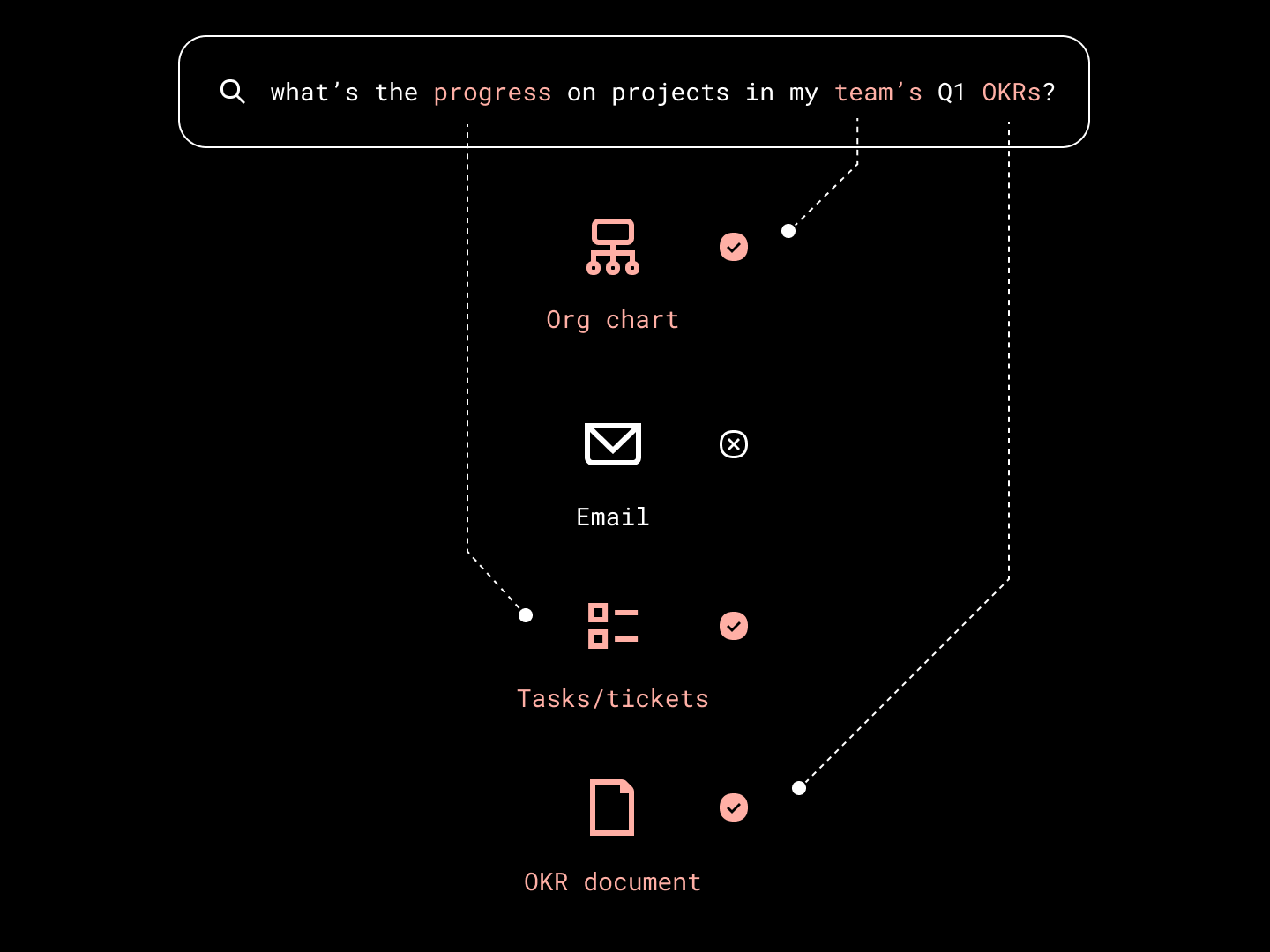
Dropbox describes building Dropbox Dash, a universal search and knowledge management product, highlighting the challenges of business data environments (diversity, fragmentation, modalities) and their solutions using retrieval-augmented generation (RAG) and AI agents. The article also explains their AI agent architecture, which uses a planning stage (LLM generates code in a Python-like DSL) and an execution stage (code validation and execution via a custom minimal interpreter) to handle complex multi-step tasks, emphasizing security, testing, and lessons learned about combining RAG and agents, prompt variability, and model trade-offs.
https://dropbox.tech/machine-learning/building-dash-rag-multi-step-ai-agents-business-users
Robin Moffatt: It’s Time We Talked About Time - Exploring Watermarks (And More) In Flink SQL
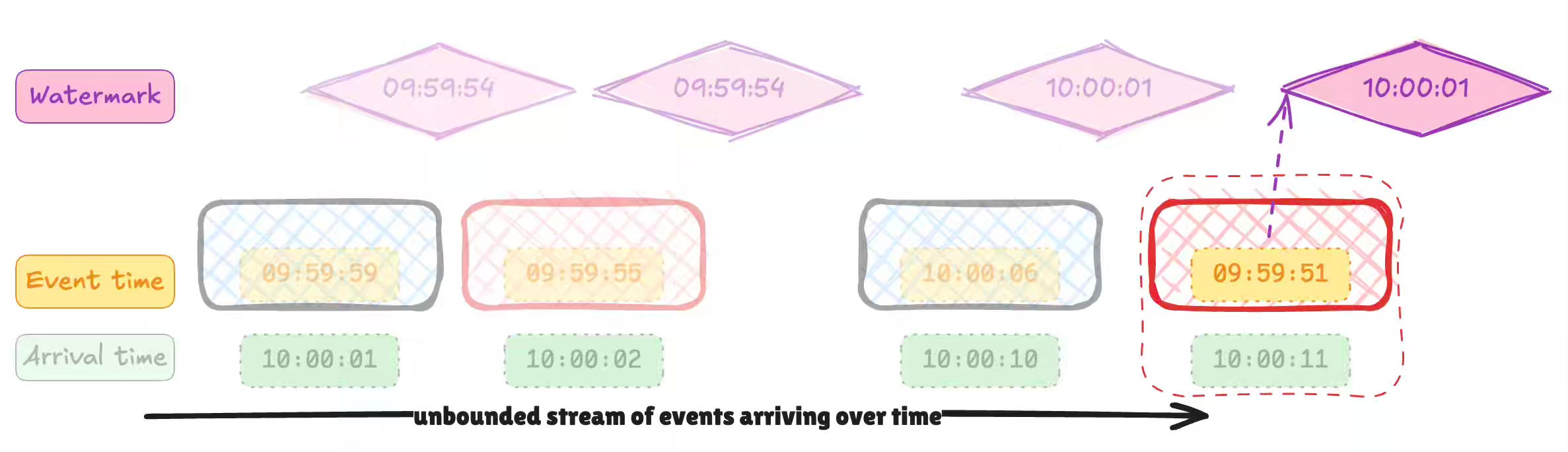
The authors write a comprehensive article to help readers understand the nuances of handling watermarks in Apache Flink. TIL about the idle stream problem. When a Kafka topic has multiple partitions, but one partition doesn't receive any data, it can block watermark progression for the entire operator since the watermark at each stage is the minimum across all source partitions.
Henry Zhu: An Intro to DeepSeek's Distributed File System

The author gives an overview of DeepSeek’s file system. It is on my to-do list to read their design notes. I’m looking forward to the author’s future notes on DeepSeek to understand how DeepSeek FS differs from other filesystems.
https://maknee.github.io/blog/2025/3FS-Performance-Journal-1/
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.