
Data Engineering Weekly #223
The Weekly Data Engineering Newsletter


Dagster Deep Dive: A real-world AI pipeline in action
Discover how Dagster's unified control plane enables teams to build reliable, scalable AI/ML systems. Join us with our friends at Neurospace for a hands-on session showcasing:
- Dagster's core capabilities for MLOps orchestration
- Live demo of production AI pipeline implementation
- Practical strategies for EU AI Act compliance
Perfect for data teams navigating the intersection of AI innovation and regulatory compliance.
Michael Gschwind: AI - It's All About Inference Now
The author highlights the increasing importance of model inference in the AI landscape, shifting the focus from solely training to optimizing the affordability and performance of deploying models. The article discusses various inference optimization techniques, including model compression (pruning, distillation, quantization like GPTQ) and KV cache management (MQA, GQA, MLA, sparsification, multilevel caching).
https://queue.acm.org/detail.cfm?id=3733701
Hamel Husain & Shreya Shankar: LLM Eval FAQ
The author writes an FAQ-style guide to evaluating Large Language Model (LLM) applications, emphasizing that successful AI teams prioritize measurement and iteration. The FAQ clarifies that Retrieval-Augmented Generation (RAG) is not dead but requires effective retrieval strategies beyond naive vector search, especially for complex tasks like coding. The author strongly advocates for building custom annotation tools for faster iteration, recommends binary (pass/fail) evaluations over Likert scales for clarity, and offers strategies for debugging multi-turn conversations, building automated evaluators, and determining the number of annotators (favoring a single domain expert).
https://hamel.dev/blog/posts/evals-faq/
Wix: 7 Operating System Concepts Every LLM Engineer Should Understand
Every platform engineering team desires to build LLM as an intelligence operating system. The author maps the operating system concepts to the LLM applications to give a new dimension to thinking about LLM.
Sponsored: How to Build a Data Platform

Learn the fundamental concepts to build a data platform in your organization, covering common design patterns for data ingestion and transformation, data modeling strategies, and data quality tips.
ML CMU: Unlearning or Obfuscating? Jogging the Memory of Unlearned LLMs via Benign Relearning
The research highlights the vulnerability of current machine unlearning techniques in Large Language Models (LLMs) to "benign relearning attacks," where even small amounts of seemingly unrelated or publicly available data can "jog" an unlearned model's memory, causing it to output previously forgotten information. The authors demonstrate that finetuning-based unlearning methods often obfuscate rather than truly erase knowledge through experiments on benchmarks like TOFU, Who's Harry Potter (WHP), and WMDP.
Uber: From Archival to Access: Config-Driven Data Pipelines
Uber's Compliance Data Store (CDS) team describes its config-driven archival and retrieval framework designed to manage petabytes of regulatory data, addressing challenges like HDFS storage quotas, schema evolution, data consistency during backfills, and efficient data access. The architecture uses Python, Piper (Airflow-based orchestrator), Terrablob (S3 abstraction) for cold storage, and MySQL for metadata. The archival process, driven by database and dataset-level YAML configurations, schedules daily or weekly jobs to move data from HDFS (hot storage) to cold storage based on TTL policies.
https://www.uber.com/blog/from-archival-to-access/
Lyft: How science inspires our ETA models
The article explores micro-patterns in traffic to improve ETA (Estimated Time of Arrival) models, observing that while short-distance travel times can be highly variable due to random events (like traffic lights or minor congestions), longer journeys tend to exhibit more predictable and statistically stable travel times. It draws an analogy to the "traffic light dance," where short-term discrepancies between two vehicles on the same route even out over distance, and proposes that this phenomenon resembles the Central Limit Theorem (CLT), where the sum of (not strictly independent) travel times across many road segments empirically converges towards a normal distribution.
https://eng.lyft.com/how-science-inspires-our-eta-models-bf229e3148e8
Daniel Lemire: Fast character classification with z3
The author discusses using the Z3 theorem prover to automatically compute lookup tables (LUTs) for fast character classification, specifically for vectorized base64 decoding using SIMD instructions. The approach splits each character's ASCII value into two 4-bit nibbles and uses two 16-byte LUTs (lut_lo and lut_hi) for classification via a bitwise AND operation and by modeling the classification rules (base64 characters classify to 0, others to >0) as a satisfiability problem in Z3, the tool can automatically derive the content of these LUTs, simplifying a potentially complex and error-prone manual task.
https://lemire.me/blog/2025/06/01/easy-vectorized-classification-with-z3/
Pinterest: Automated Migration and Scaling of Hadoop™ Clusters
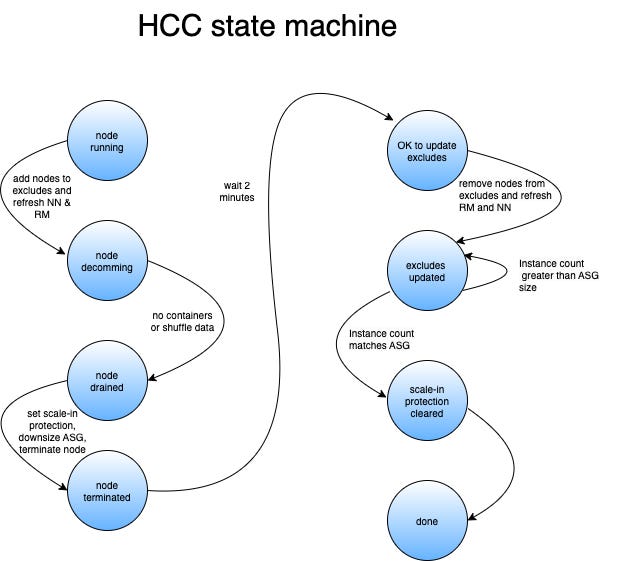
Pinterest describes the Hadoop Control Center (HCC), the internal tool to automate and streamline Hadoop cluster operations, particularly for in-place migrations and scaling. Faced with challenges in manual scaling, including IP address limitations, instance availability, cost of running parallel clusters, and risks of application migration, HCC automates the complex scale-in process by managing Auto Scaling Groups (ASGs), decommissioning nodes gracefully (ensuring HDFS data replication and no impact on running YARN applications), and handling excludes files.
Pinterest: Next-Level Personalization - How 16k+ Lifelong User Actions Supercharge Pinterest’s Recommendations
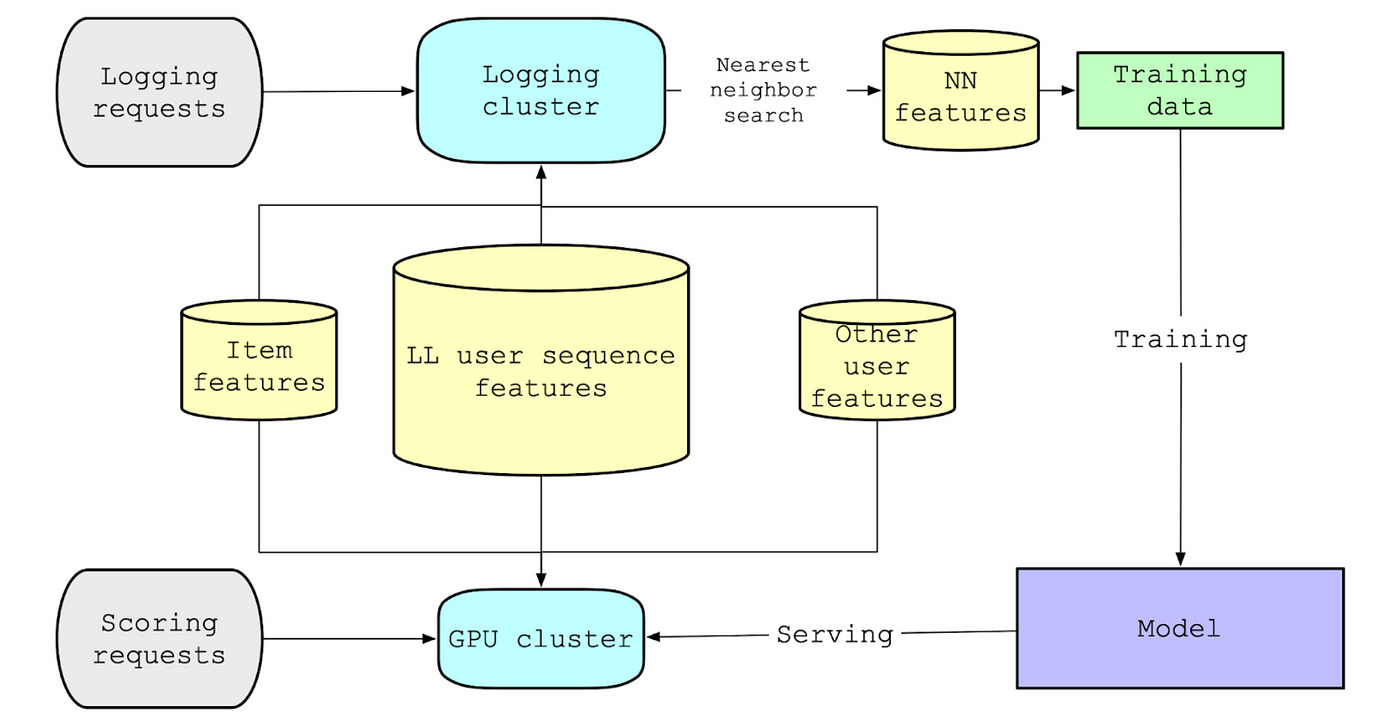
Pinterest details TransActV2, its home feed recommendation model. To handle the scale, TransActV2 uses nearest neighbor selection at ranking time to feed only the most recent and relevant historical actions to the model, employs int8 quantization for action storage, and utilizes custom OpenAI Triton kernels, fused transformers (SKUT), pinned memory, and request-level de-duplication for efficient, low-latency serving, resulting in substantial offline metric improvements (e.g., +13.31% top-3 repin hit rate) and significant online A/B test lifts (e.g., +6.35% repin increase, +1.41% time spent).
Databricks: Introducing Apache Spark 4.0
Apache Spark 4.0 introduces significant advancements, including enhanced SQL language features like SQL scripting, reusable SQL UDFs, and PIPE syntax, major improvements to Spark Connect with near-complete feature parity for Python and Scala clients, and new support for Go, Swift, and Rust. The release also emphasizes reliability and productivity with ANSI SQL mode enabled by default, a new VARIANT data type for semi-structured data, structured JSON logging, new Python API capabilities like native Plotly-based plotting and a Python Data Source API, and advances in Structured Streaming such as the transformWithState API for arbitrary stateful processing and a State Store Data Source for improved observability.
https://www.databricks.com/blog/introducing-apache-spark-40
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.