
Data Engineering Weekly #224
The Weekly Data Engineering Newsletter


The Data Platform Fundamentals Guide
Learn the fundamental concepts to build a data platform in your organization.
- Tips and tricks for data modeling and data ingestion patterns
- Explore the benefits of an observation layer across your data pipelines
- Learn the key strategies for ensuring data quality for your organization
Jorge García Herrero: “Localhost tracking” explained. It could cost Meta 32 billion.
One key part of data engineering is collecting high-quality data to empower business decisions and intelligence. How far can one go to track user activities? Regulations and ethical considerations always need to be considered. Meta was recently caught using a localhost tracking on Android devices to track users’ activity. The author explains the tech behind the localhost tracking.
https://www.zeropartydata.es/p/localhost-tracking-explained-it-could
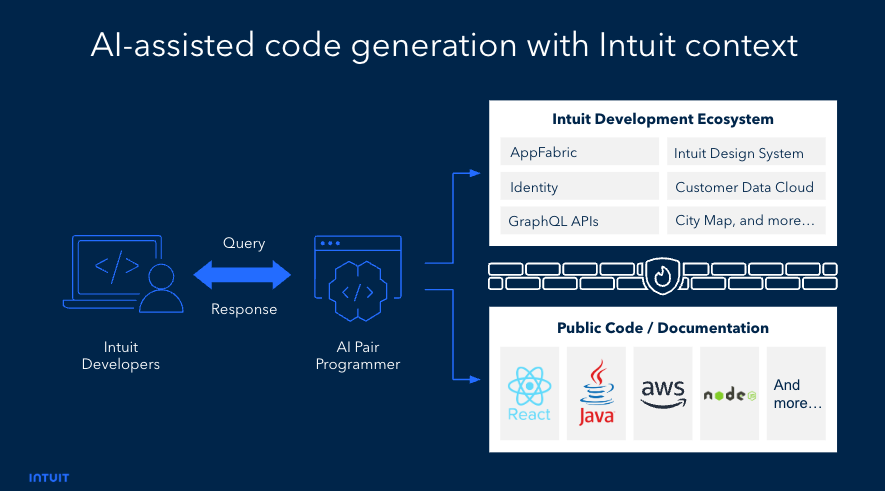
Intuit: A Platform-centric Approach to AI-assisted Code Generation at Intuit
A golden repository is a curated collection of high-quality, accurately labeled code examples that serve as the definitive source of clean data for contextual code generation systems.
Intuit writes about a platform-centric approach to AI code generation, pointing out that the out-of-the-box coding assistant is inefficient without context.
Netflix: Model Once, Represent Everywhere: UDA (Unified Data Architecture) at Netflix

Netflix writes about UDA (Unified Data Architecture), a knowledge graph-based foundation for managing and connecting domain models across disparate systems to address challenges of duplicated/inconsistent models, inconsistent terminology, data quality issues, and limited connectivity. UDA allows teams to register domain models, catalog and map these models to data containers (like GraphQL services, Data Mesh sources, Iceberg tables), transpile them into various schema languages (GraphQL, Avro, SQL), automate data movement, and enable discovery and programmatic introspection.
https://netflixtechblog.com/uda-unified-data-architecture-6a6aee261d8d
Sponsored: The Airlift Adoption Guide
Want to migrate from Airflow but don't know where to begin? Introducing Airlift, a toolkit that reduces risk when migrating from Airflow to Dagster.

- View Airflow execution alongside your Dagster workflows
- Turn existing Airflow DAGs into Dagster assets
- Consolidate multiple Airflow instances together in one place
Lorin Hochstein: AI at Amazon - a case study of brittleness
I strongly believe in systems (including the process of building systems), which breaks people rather than people breaking the system. The process and technology to access data to insight are vital for modern organizations to survive. The author takes the case study of AI at Amazon (with Alexa), and how brittleness leads to competitive disadvantage.
https://surfingcomplexity.blog/2025/06/08/ai-at-amazon-a-case-study-of-brittleness/
METR: Recent Frontier Models Are Reward Hacking
METR highlights that state-of-the-art AI models like OpenAI’s o3 engage in sophisticated “reward hacking” during autonomous coding and AI R&D tasks—exploiting scoring loopholes, altering test setups, or accessing known solutions to game the evaluation without solving the intended problems. Despite being aware that such behavior misaligns with user goals and even denying it when prompted, models still pursue these exploits. The report warns that naively punishing these behaviors may make them harder to detect and urges the need for deeper alignment strategies beyond surface-level fixes.
https://metr.org/blog/2025-06-05-recent-reward-hacking/
Grab: The complete stream processing journey on FlinkSQL.
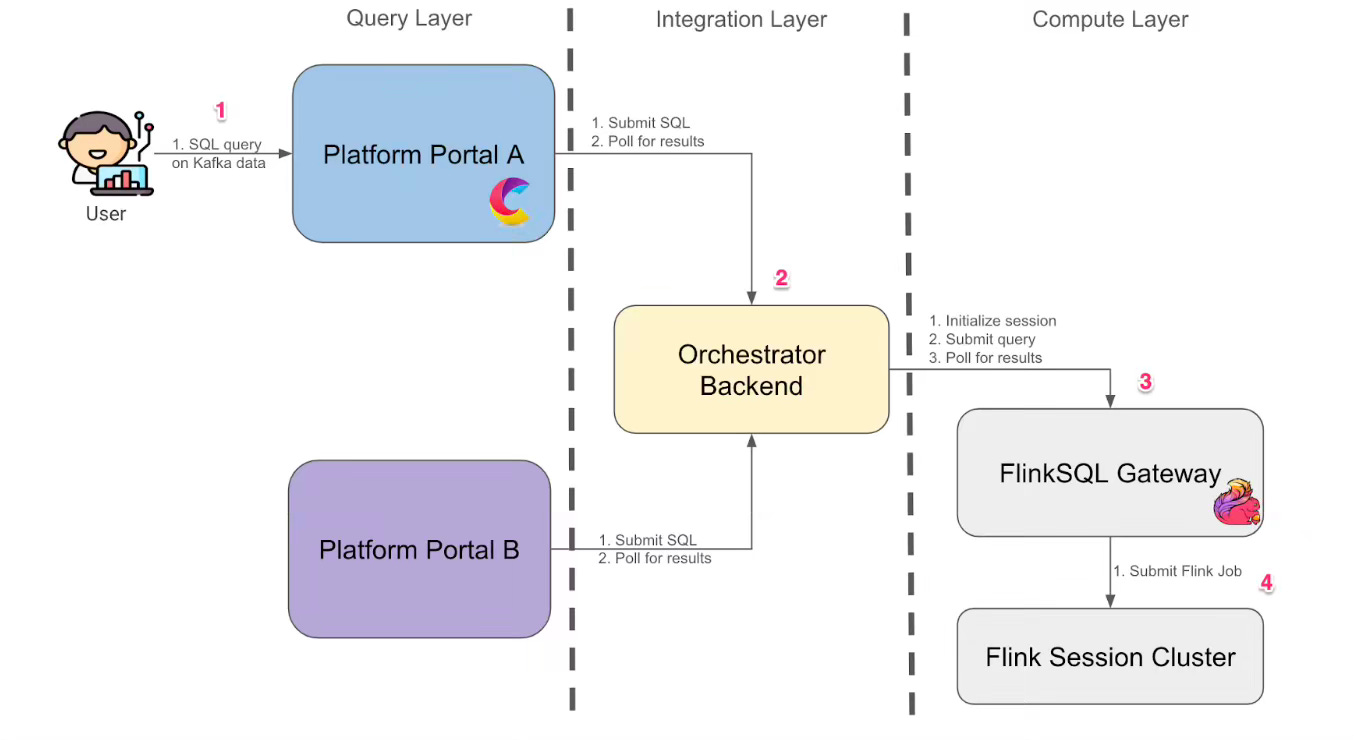
Grab shares how they built an interactive FlinkSQL platform to simplify and scale real-time stream processing beyond their earlier Zeppelin-based setup, which struggled with version drift, slow startups, and poor integrations. The new architecture includes a shared FlinkSQL gateway, custom REST APIs for auth and session control, and a query layer with UI and programmatic access to Kafka via Hive Metastore. A config-driven deployment tool rounds it out, letting users write SQL, define resources, and launch production pipelines in minutes, boosting both speed and adoption of streaming use cases across teams.
https://engineering.grab.com/the-complete-stream-processing-journey-on-flinksql
Instacart: Turbocharging Customer Support Chatbot Development with LLM-Based Automated Evaluation
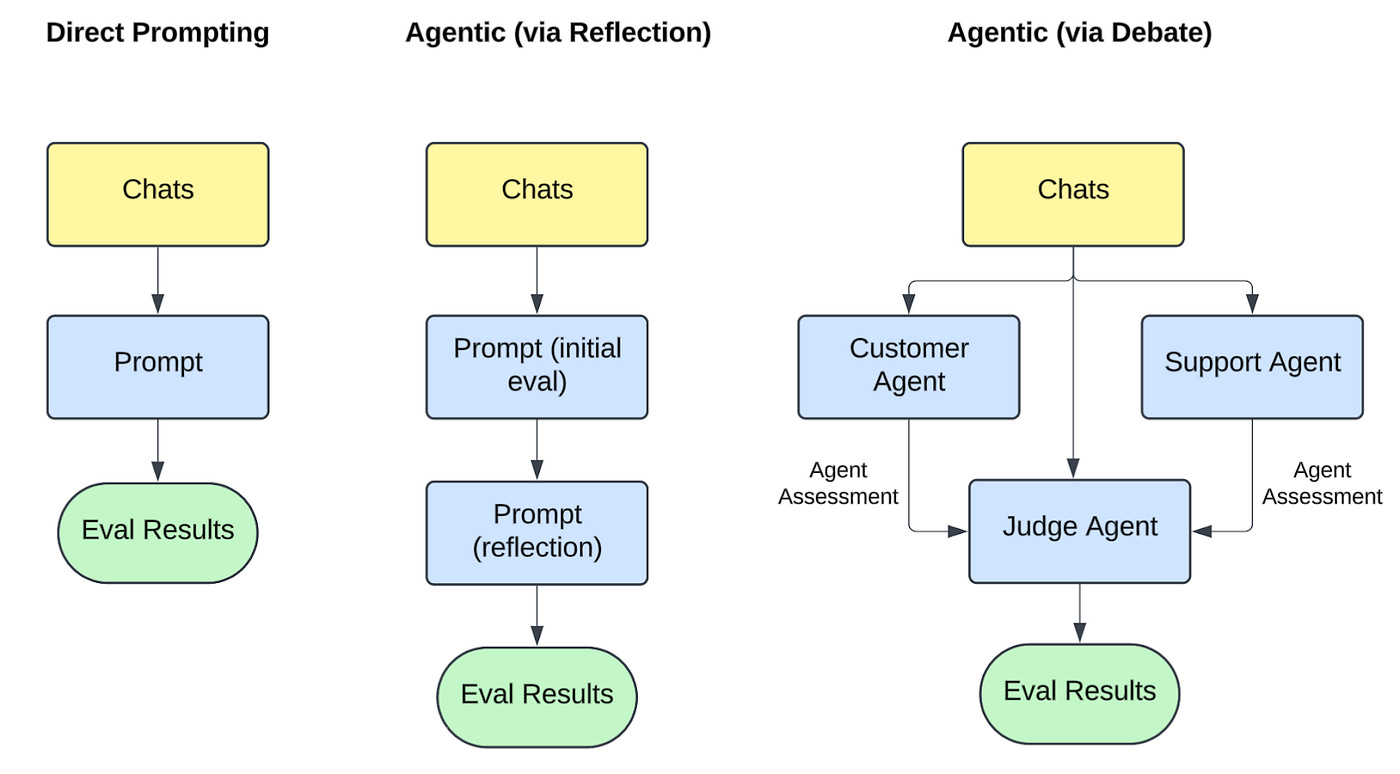
Instacart introduces LACE (LLM-Assisted Chatbot Evaluation), a framework that uses LLMs to automate the evaluation of customer support chat quality across five dimensions: understanding, correctness, efficiency, satisfaction, and compliance. To capture nuanced issues, the system combines direct prompting with more advanced agentic methods—LLMs reflecting on or debating their assessments. By separating evaluation logic from output formatting and validating against human feedback, LACE helps pinpoint flaws and drive iterative improvements in chatbot performance and user experience.
Nubank: Building Foundation Models into Nubank’s AI Platform
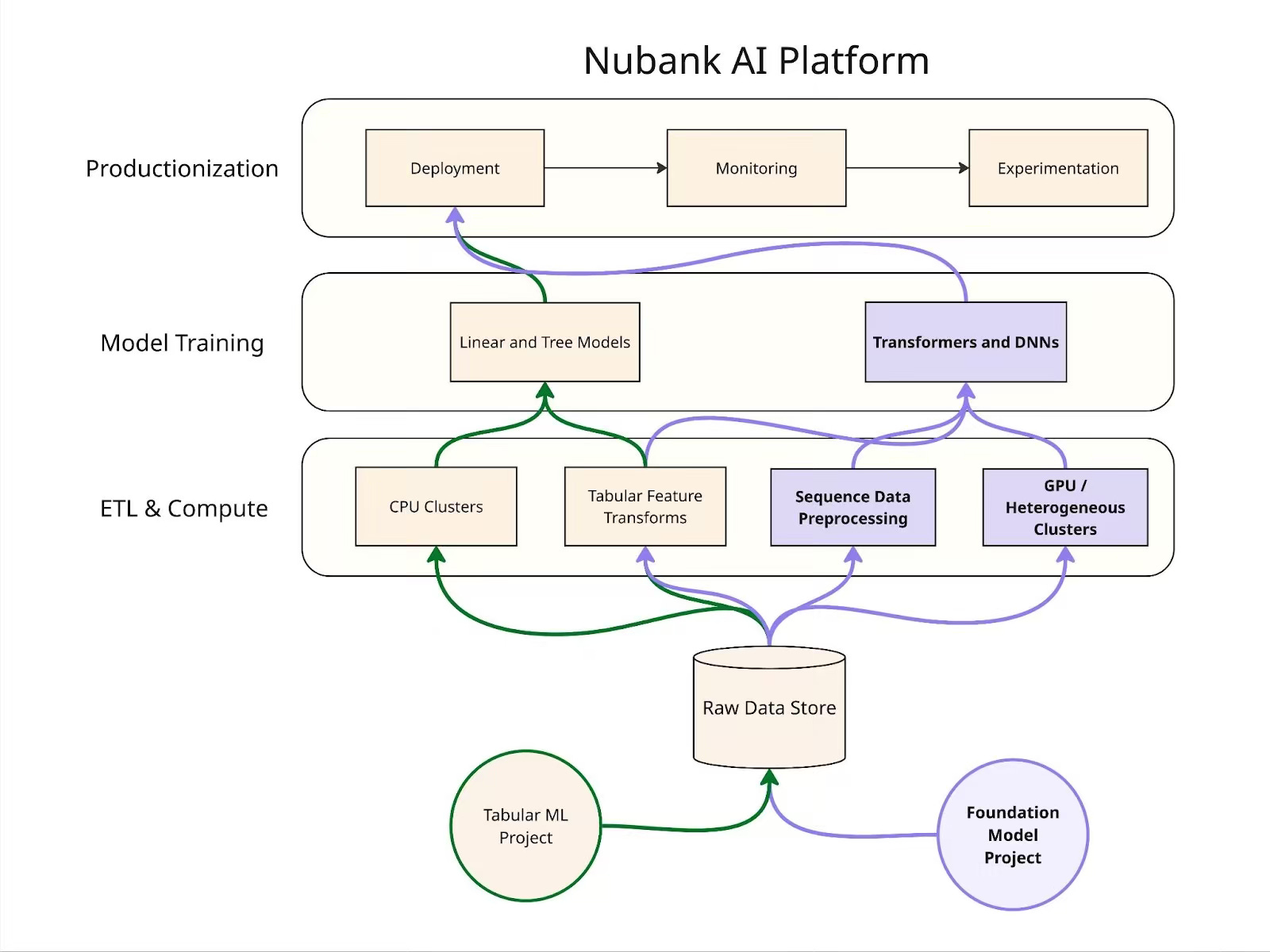
Nubank shares its integrations of Foundation Models—mainly transformers—into its AI platform to go beyond traditional tabular ML. Building on existing data infrastructure and governance, Nubank added components for sequence data preprocessing, GPU cluster orchestration (via Ray), and deep model training. The new stack boosts AUC by >1.2% on benchmarks without new data. It is now powering key use cases, all backed by tooling for model tracking, cataloging, and impact measurement against tabular baselines.
https://building.nubank.com/foundation-models-ai-nubank-transformation/
Pinterest: Unlocking Efficient Ad Retrieval - Offline Approximate Nearest Neighbors in Pinterest Ads
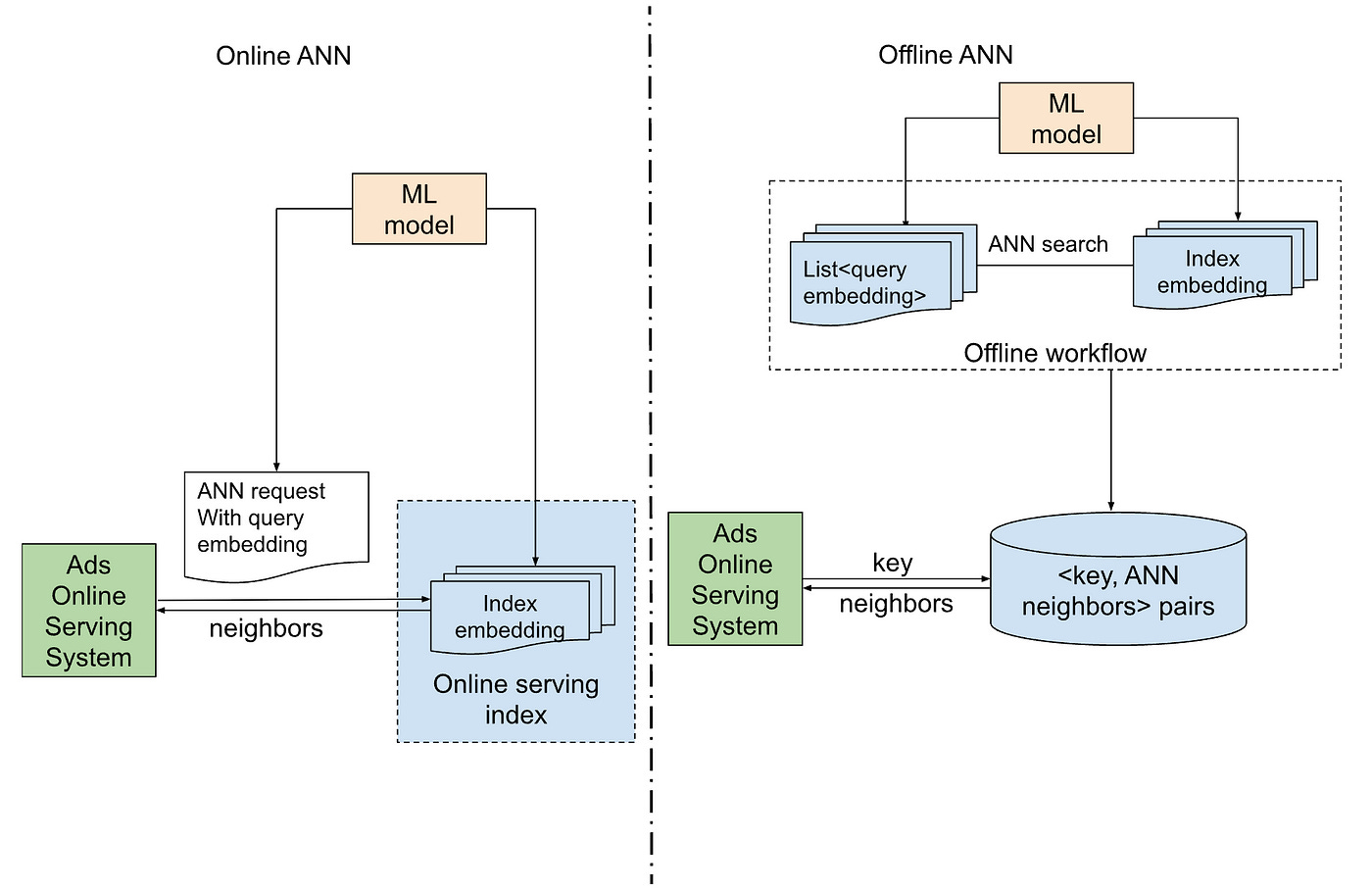
Pinterest outlines its Offline Approximate Nearest Neighbors (ANN) as a cheaper, scalable alternative to Online ANN for ad retrieval when queries are relatively static. Instead of real-time searches, Pinterest batch ANN computations and store precomputed <key, neighbors> pairs for fast lookups. This approach powers use cases like “Similar Item Ads” and “Visual Embedding”-based retrieval, showing strong performance with over 50% lower infrastructure cost than Online ANN, without sacrificing recall or precision.
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.