
Data Engineering Weekly #225
The Weekly Data Engineering Newsletter


The Data Platform Fundamentals Guide
A comprehensive guide for data platform owners looking to build a stable and scalable data platform, starting with the fundamentals and wrapping up with real-world examples illustrating how teams have built in-house data platforms for their businesses.
Uber: The Evolution of Uber’s Search Platform
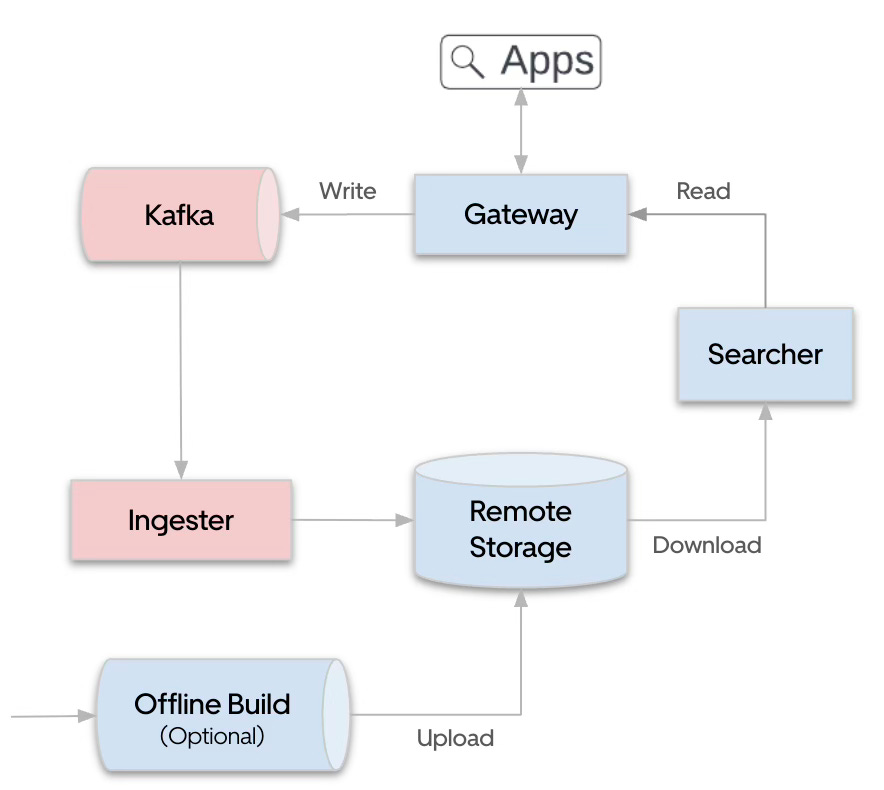
Uber writes about the evolution of its search infrastructure from Elasticsearch to the in-house Sia engine, which was built to support NRT semantics, gRPC/Protobuf, Kafka-based ingestion, and active-active deployment. Uber shifted to OpenSearch under Project Sunrise, citing community momentum and governance as key motivators, and highlighting its contribution —including gRPC support, LucenePlus enhancements, and a read/write split architecture—now part of OpenSearch 3.0 and its upcoming cloud-native variant.
https://www.uber.com/blog/evolution-of-ubers-search-platform/
Shopify: Introducing Roast - Structured AI Workflows Made Easy
Shopify introduces open-source Roast, a convention-oriented workflow orchestration framework designed for creating structured AI workflows that interleave non-deterministic AI steps with traditional code execution using YAML configuration and markdown prompts. Roast supports various step formats (directory-based, command execution, inline prompts, custom Ruby steps, parallel steps), includes built-in tools (ReadFile, WriteFile, Grep, CodingAgent powered by Claude Code), allows shared context between steps, and features advanced control flow (iteration, conditionals, case statements) and session replay for easier development.
http://shopify.engineering/introducing-roast
Sem Sinchenko: Why Apache Spark is often considered as slow?
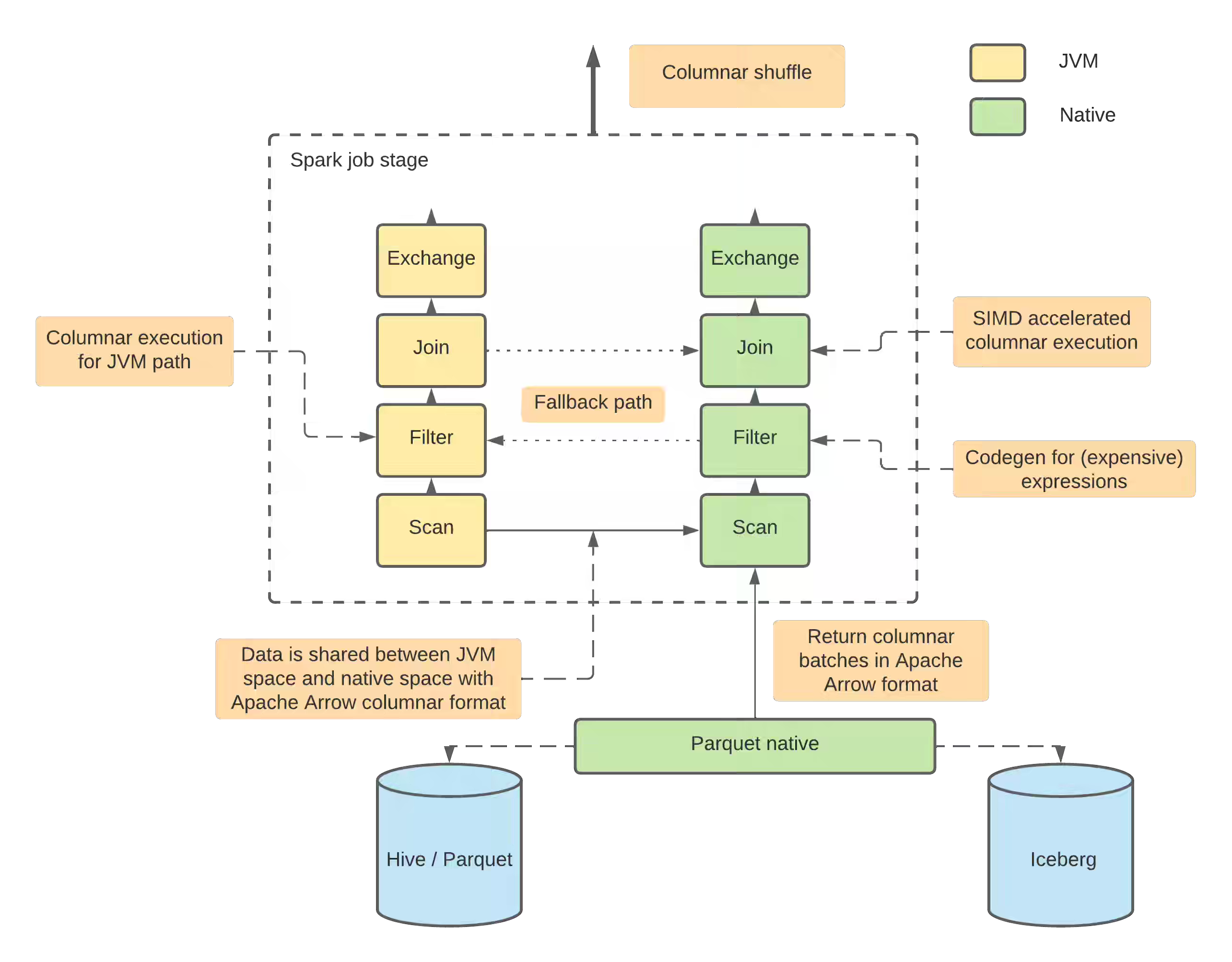
The article explains why Apache Spark can lag behind pure vectorized engines like Trino or Snowflake for OLAP on columnar data—its hybrid execution model blends code generation with fallback to Volcano-mode, limiting vectorization. It explains how Spark’s Catalyst optimizer and expression evaluation pipeline contribute to this, especially when UDFs trigger non-vectorized paths. To close the gap, projects like Databricks Photon, Apache Gluten, and Datafusion Comet retrofit Spark with vectorized execution, bringing it closer to purpose-built analytical engines.
https://semyonsinchenko.github.io/ssinchenko/post/why-spark-is-slow/
Sponsored: Dagster Deep Dive - Breaking Biology's Data Wall

In this session, Keith Kam from Basecamp Research shares practical insights from developing BaseData™, the world's most diverse metagenomic sequence database designed to power the next generation of bio AI foundation models. Learn how his team built a data platform that simultaneously supports bioinformatics, analytics, and machine learning teams, and how they managed complexity across multiple dimensions.
Meta: Collective Wisdom of Models: Advanced Feature Importance Techniques at Meta
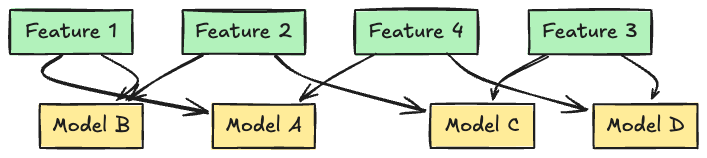
Meta’s data engineering team introduces the “Global Feature Importance” framework, a scalable way to consistently surface valuable features by aggregating and normalizing importance scores across multiple ML models. By leveraging existing logs, converting scores to percentiles for cross-model comparison, and computing global rankings, the framework helps teams identify high-impact features, accelerate model development, and prune underperformers. The approach has driven measurable impact, including a ~25% online lift, while streamlining feature selection across diverse use cases.
Booking.com: Unlocking the Power of Customization: How Our Enrichment System Transforms Recommendation Data Enrichments

Booking.com shares how it revamped its Recommendation Platform’s enrichment layer to tackle issues of tight coupling and low reusability when attaching data like prices, wishlist counts, and images to recommendations. Their new system uses field masks—like GraphQL or REST API selectors—to request enrichments on demand, decoupling enrichment logic from prediction. This design brings modularity, boosts performance (100 K+ enrichments/sec at 99.99% availability), and aligns with modern data access patterns for flexibility and maintainability.
Capital One: Refining input guardrails for safer LLM applications
Capital One's Enterprise AI team discusses its research on improving LLM input moderation guardrails, particularly for detecting adversarial attacks like direct malicious queries, jailbreaks, and prompt injections. The solution leveraged chain-of-thought (CoT) prompting to enhance the reasoning of LLM-as-a-Judge classifiers. It explored fine-tuning techniques (SFT, DPO, KTO) using LoRA on medium-sized open-source LLMs (Mistral 7B, Mixtral 8x7B, Llama2 13B, Llama3 8B) with small training sets. The findings show that SFT significantly improves attack detection (F1 score and ADR) and output format adherence, with DPO and KTO offering marginal further gains, and their best-performing DPO-aligned Llama3 8B model outperformed existing public guardrail models like LlamaGuard-2 and PromptGuard.
QuantumBlack: Overcoming production challenges for generative AI at scale
Iguazio (now part of McKinsey) introduces MLRun. This open-source orchestration framework simplifies the deployment of GenAI and ML models at enterprise scale, especially in on-prem and hybrid setups. MLRun handles GPU management, model serving, monitoring, and experiment tracking while offering modular, serverless infrastructure via Nuclio for scalable and compliant operations. Real-world examples—from retail banking call centers to Seagate’s AI-driven manufacturing—show how MLRun supports reproducibility, cost control, and governance in complex, multi-agent AI pipelines.
Karol Zak & Marc Gomez: Taming complexity: An intuitive evaluation framework for agentic chatbots in business-critical environments

The article presents an evaluation framework for LLM-powered line-of-business (LOB) agents, built to tackle non-determinism and ensure reliability in enterprise settings. It uses an LLM-based User Agent to simulate realistic, multi-turn conversations seeded with real business data. It captures outputs like chat history and function calls for precision/recall-based evaluation. Integrated with Azure’s AI Evaluation SDK, the framework enables reproducibility, detailed error analysis, and domain adaptability, making assessing and iterating on LLM agents in business-critical workflows easier.
Klaviyo: Bloom Filters & Supercharged Product Recommendations

Klaviyo shares how they optimized their product recommendation engine using dual Bloom filters to exclude items already purchased from marketing campaigns efficiently. Instead of querying two years of purchase data per recipient, they precompute monthly and 30-day Bloom filters per company and store them in Redis for fast membership checks. This drastically cut query load, improved campaign render times, and scaled smoothly for high-traffic events like BFCM without stressing infrastructure.
https://klaviyo.tech/bloom-filters-supercharged-product-recommendations-711d65c0a1b3
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.