
Data Engineering Weekly #226
The Weekly Data Engineering Newsletter


The Data Platform Fundamentals Guide
Learn the fundamental concepts to build a data platform in your organization.
- Tips and tricks for data modeling and data ingestion patterns
- Explore the benefits of an observation layer across your data pipelines
- Learn the key strategies for ensuring data quality for your organization
Kiran Gopinathan: Programming Language Design in the Era of LLMs - A Return to Mediocrity?
As languages become more niche and specific, the performance of these models drops off a cliff and becomes abysmal.
Suddenly, the opportunity cost for a DSL has just doubled: in the land of LLMs, a DSL requires not only the investment of building and designing the language and tooling itself, but the end users will have to sacrifice the use of LLMs to generate any code for your DSL.
It is an interesting perspective, and it makes me wonder what the language design protocol would be in the era of LLM to create a DSL. Is there any need for it?
https://kirancodes.me/posts/log-lang-design-llms.html
Anthropic: How we built our multi-agent research system
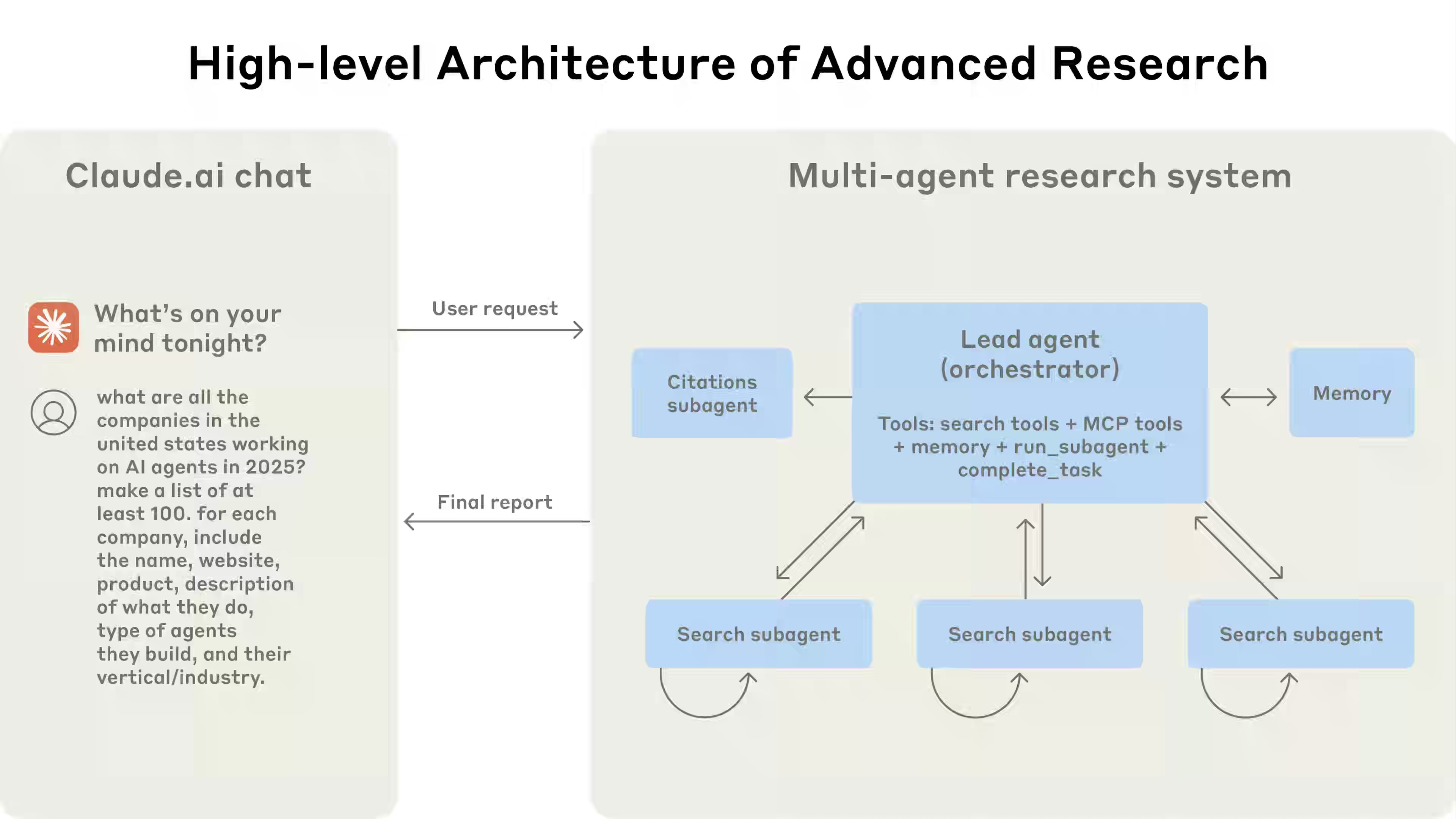
Anthropic writes about its Claude’s Research feature using a multi-agent system that distributes research tasks across specialized subagents via an orchestrator-worker pattern. The architecture boosts performance by parallelizing exploration and token usage, with key insights into prompt engineering (delegation, scaling, tool design), evaluation (LLM-as-judge, human-in-the-loop), and production hardening (stateful runs, debugging, orchestration).
https://www.anthropic.com/engineering/built-multi-agent-research-system
LinkedIn: Introducing Northguard and Xinfra: scalable log storage at LinkedIn

LinkedIn unveils Northguard, a Kafka replacement built to handle over 32 trillion daily records by addressing scalability, operability, and durability challenges at hyperscale. Northguard introduces a sharded log architecture with minimal global state, decentralized coordination (via SWIM), and log striping for balanced load, backed by a pluggable storage engine using WALs, Direct I/O, and RocksDB LinkedIn developed Xinfra—a virtualized Pub/Sub layer with dual-write and staged topic migration to enable seamless migration, ensuring zero-downtime interoperability between Kafka and Northguard.
https://www.linkedin.com/blog/engineering/infrastructure/introducing-northguard-and-xinfra
Sponsored: Rapidly developing ELT pipelines with dltHub and Dagster

Join us for a technical deep dive co-hosted by Dagster Labs and our partners at dltHub, where we explore how to rapidly build and scale ELT pipelines using the power of open-source tooling. Whether you're exploring your first data ingestion project or scaling existing pipelines, this session will equip you with the tools and best practices to iterate faster, ship confidently, and operate reliably in production.
Canva: Measuring Commercial Impact at Scale at Canva
Canva writes about its internal app “IMPACT,” a Streamlit-on-Snowflake app that automates measurement of business metrics like MAU and ARR across 1,800+ annual experiments. Built with Snowpark, Cortex, and the Snowflake Python connector, the app replaces manual, error-prone analysis with a self-serve interface that aligns with finance models, supports pre/post-experiment workflows, and stores results for downstream use. Its modular architecture and PR-driven dev workflow enable scalable collaboration, while natural language summaries and scheduled metric calculations streamline impact analysis from hours to minutes.
https://www.canva.dev/blog/engineering/measuring-commerical-impact-at-scale/
Pinterest: Scaling Pinterest ML Infrastructure with Ray: From Training to End-to-End ML Pipelines

Pinterest outlines its shift from Spark to a fully Ray-native ML infrastructure, extending Ray beyond training and inference to accelerate feature development, sampling, and labeling. By leveraging a Ray Data transformation API, Iceberg-based bucket joins and writes, and optimized UDFs, Pinterest eliminates the need for large pre-joined tables and accelerates data iteration. The result is a 10x speedup in ML workflow iteration and a significant drop in infrastructure costs—all powered by Ray and Iceberg.
Nubank: Making Real-time ML Models more robust in adversarial scenarios: Practical Tips and Monitoring Considerations
The article shares practical strategies to harden real-time ML models against adversarial attacks, focusing on rapid detection, resilient design, and operational readiness. Key tactics include using SHAP and PDP to understand feature vulnerabilities, setting up feature and decision-layer monitoring, and deploying business-metric-based alerts for real-time anomaly detection. To mitigate risks, it recommends frequent retraining, limiting attacker feedback loops, applying robustness-over-accuracy tradeoffs, and using feature flags for rapid rollback—all supported by granular monitoring of raw inputs, feature distributions, and downstream decisions.
Agoda: How Agoda Handles Kafka Consumer Failover Across Data Centers

Agoda shares how it built a custom Kafka consumer failover solution to ensure business continuity across multiple on-prem data centers, handling over 3 trillion records daily. Standard tools like stretch clusters and MirrorMaker 2 fell short due to latency and lack of failback, so Agoda extended MirrorMaker 2 with a bidirectional offset sync service. This always-on system translates and updates consumer group offsets across clusters, enabling seamless failover and failback without coupling producers and consumers or triggering cyclic sync issues.
Modern Data 101: Lakehouse 2.0 - The Open System That Lakehouse 1.0 Was Meant to Be

The article discusses the evolution from "Lakehouse 1.0" to "Lakehouse 2.0," arguing that the initial lakehouse architecture. At the same time, unifying data lakes and warehouses was only "open" on paper due to tight coupling between proprietary compute engines (often Spark), storage, and metadata layers, leading to vendor lock-in and limited interoperability. The "Open Table Format (OTF) revolution," driven by Apache Iceberg, Hudi, and Delta Lake, decoupled compute from storage, enabling a more modular and composable "Lakehouse 2.0" where different engines (Trino, DuckDB, Spark, etc.) can operate on the same data. The author highlights that as storage and table formats become open standards (validated by moves like AWS S3's native Iceberg support), strategic control shifts up the stack to metadata and catalog layers, with interoperability across formats, as enabled by tools like Apache XTable, being a key tenet of this new, truly open paradigm.
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.