
Data Engineering Weekly #228
The Weekly Data Engineering Newsletter


Free ELT Course from Dagster
Dagster is excited to announce the launch of ETL with Dagster, a comprehensive seven-lesson course. This free course guides you through practical ETL implementation and architectural considerations, from single-file ingestion to full-scale database replication.
Simply sign up at Dagster University to get started. Once enrolled, you can track your progress and learn at your own pace.
Thomas Kejser: Iceberg, The Right Idea - The Wrong Spec
In the article "Iceberg, the right idea, wrong spec," the author presents several excellent points about the Iceberg spec, highlighting the operational complexities it entails. Storing metadata in this manner makes it significantly larger than necessary, leading to fragmented and bloated metadata, and the space management problem is a pressing issue.
The article is probably the beginning of the debate, along with Ducklake, about the next gen iteration of Lakehouse
https://database-doctor.com/posts/iceberg-is-wrong-1.html
https://database-doctor.com/posts/iceberg-is-wrong-2.html
Pinterest: Next Gen Data Processing at Massive Scale At Pinterest With Moka
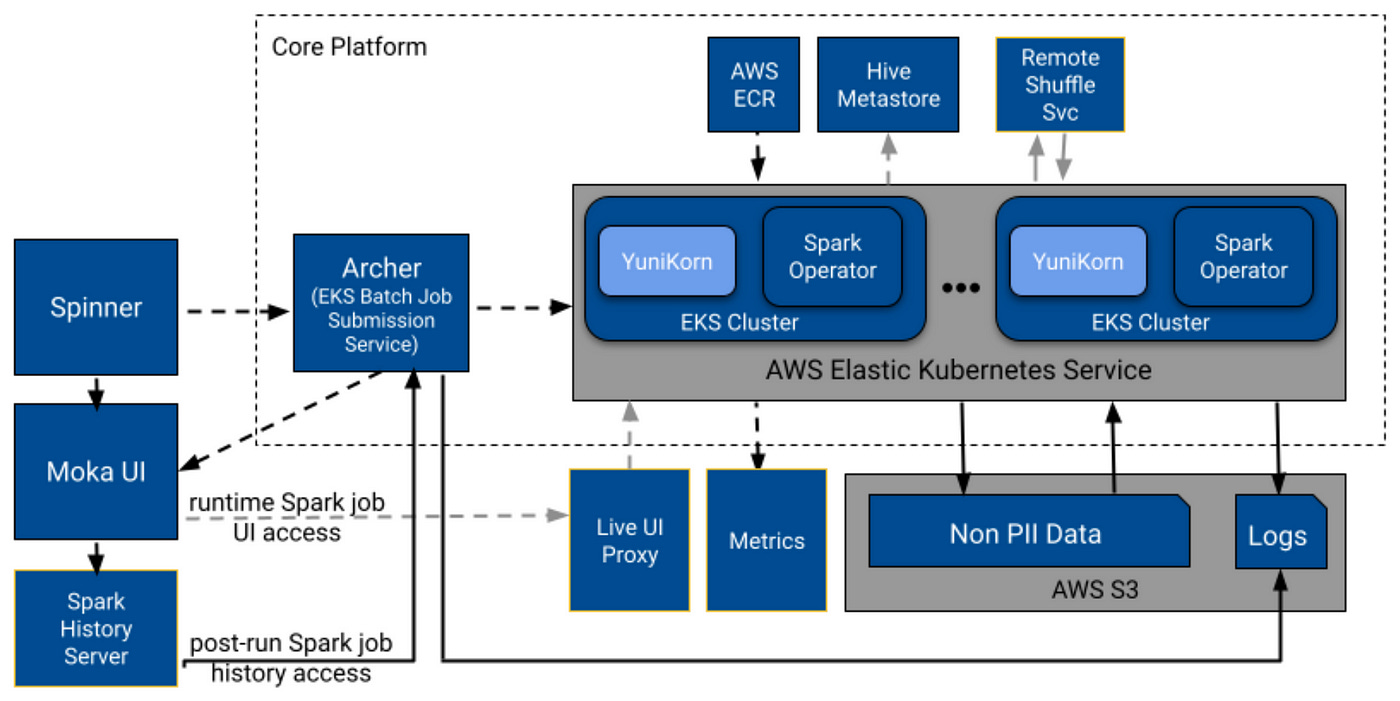
Pinterest writes about the next-gen data processing infrastructure, Moka, built on top of AWS EKS. The blog details Archer, the batch job submission service, and the usage of Apache YuniKorn scheduler instead of the default Kubernetes scheduler to bring YARN-style batch processing capabilities.
Zalando: Direct Data Sharing using Delta Sharing - Introduction: Our Journey to Empower Partners at Zalando

Data sharing across the internal and external partners is often the most fragile part of the data pipeline. The author captures the current challenges with the traditional methods and demonstrates that the data sharing techniques, like Delta sharing, improve the pipeline.
https://engineering.zalando.com/posts/2025/07/direct-data-sharing-using-delta-sharing.html
Sponsored: The Data Platform Fundamentals Guide
Learn the fundamental concepts to build a data platform in your organization.

- Tips and tricks for data modeling and data ingestion patterns
- Explore the benefits of an observation layer across your data pipelines
- Learn the key strategies for ensuring data quality for your organization
Addie Stevens Carlos Condado Saša Zelenović: Ollama or vLLM? How to choose the right LLM serving tool for your use case
As the adoption of LLM increases in enterprise systems, developer productivity and local development environments take a central stage. The blog compares Ollama and vLLM to build a serving tool.
Grab: DispatchGym: Grab’s reinforcement learning research framework.
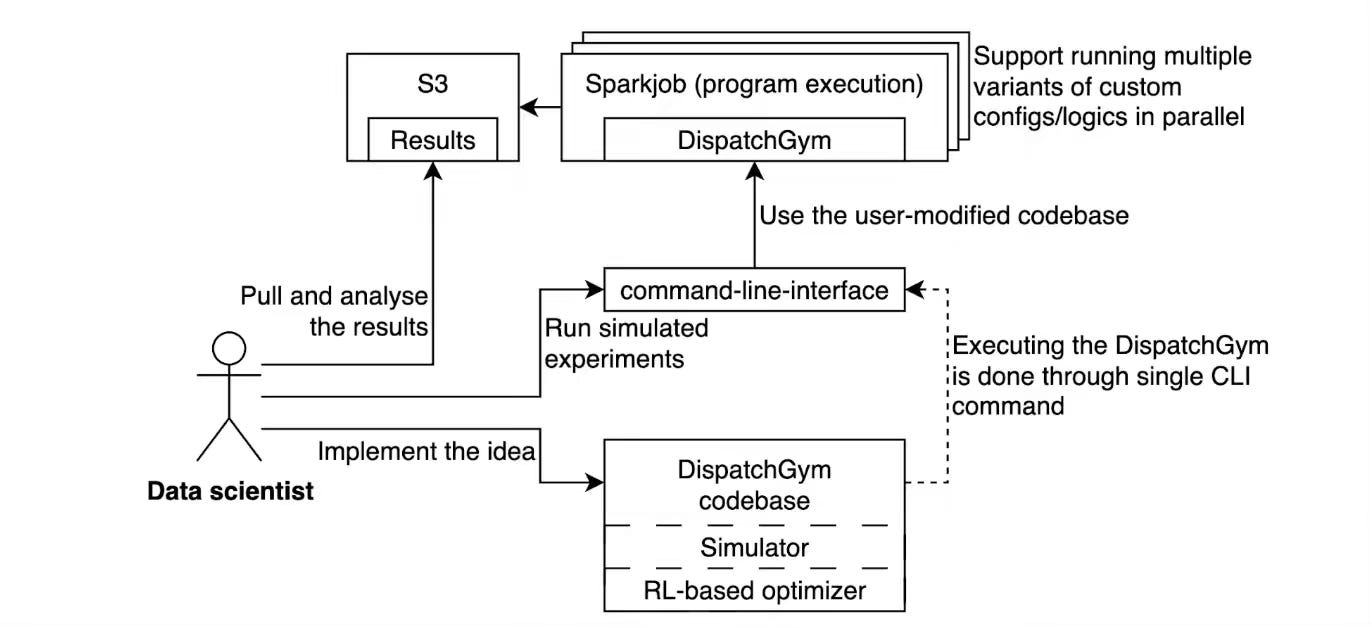
Grab open-source DispatchGym, a modular Python framework that simulates its driver-booking dispatch flow and ships Gymnasium-compatible RL algorithms accelerated with Numba. The tool lets data scientists prototype, tune, and evaluate policies—such as contextual bandits—on Spark, prioritizing cost-effective, directionally accurate experimentation without wrangling production complexity.
https://engineering.grab.com/techblog_-dispatchgym
OLX: Scaling recommendations service at OLX

OLX pushed its FastAPI recommendation service to tens of thousands of requests per second while keeping p99 latency below 10 ms. The team achieved this by adopting async I/O with aioboto3, batching ScyllaDB reads, replacing Pydantic with dataclasses, and tuning Python’s garbage collector, guided by rigorous profiling and load testing with New Relic and vegeta.
https://tech.olx.com/scaling-recommendations-service-at-olx-db4548813e3a
Nubank: Making Real-time ML Models more robust in adversarial scenarios: Practical Tips and Monitoring Considerations
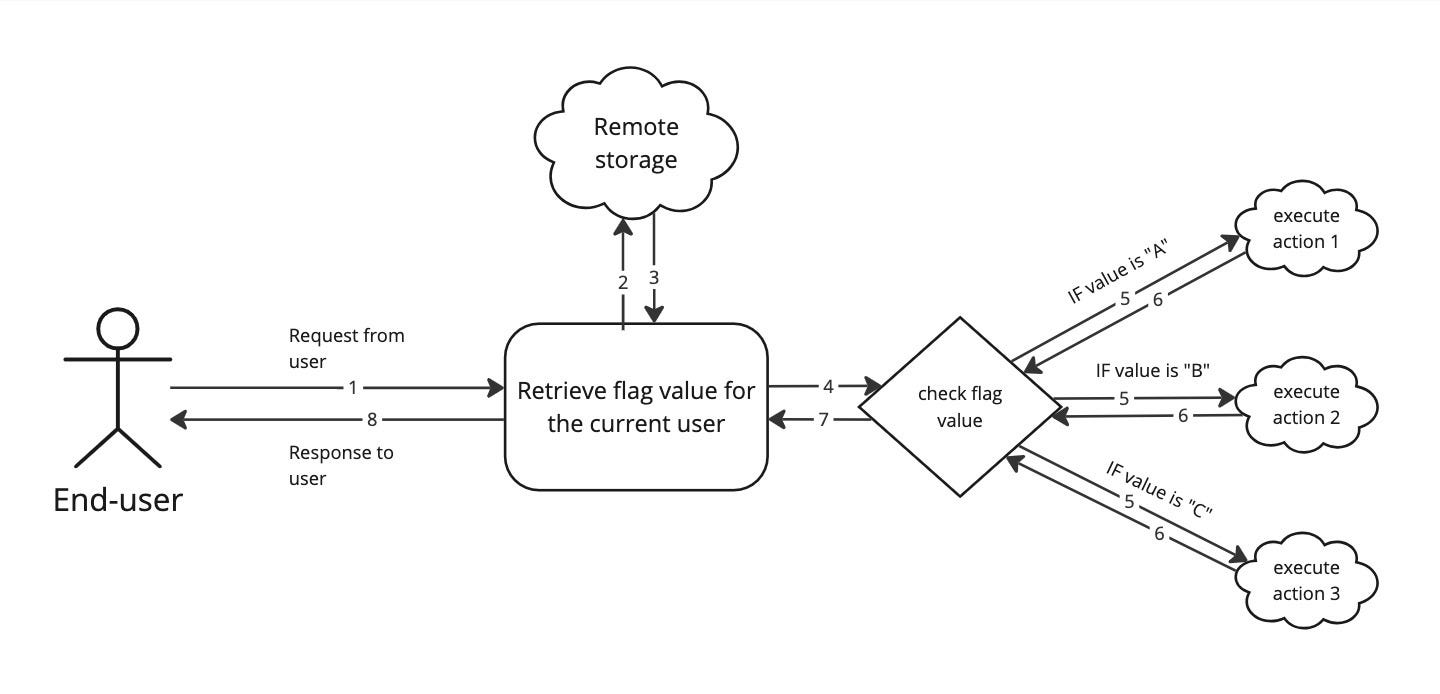
The author lays out a playbook for hardening real-time ML systems against adversarial users: mapping feature influence with SHAP/PDP, instrumenting decision-layer monitoring, and then stacking rapid alerts, frequent retraining, throttling, and feature coarsening or regularization behind feature flags. These tactics raise the cost of trial-and-error attacks while preserving business accuracy.
Mehul Jain: Fine-tuning LLMs with Reinforcement Learning
The article provides a guide to fine-tuning Large Language Models (LLMs) using Reinforcement Learning (RL), starting with an explanation of the two primary stages of LLM alignment: Supervised Fine-Tuning (SFT) and RL. The author then explains the core concepts of RL, including policy gradients and advantage functions, before detailing four popular RL-based optimizers: Proximal Policy Optimization (PPO), which uses a reward model and a clipping mechanism for stable updates; Direct Preference Optimization (DPO), which simplifies training by learning directly from preference pairs (chosen vs. rejected) without a separate reward model.
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
I am really enjoying the course on Dagster. Thank you so much. I am looking forward to expanding my skills on Data Engineering.