
Data Engineering Weekly #229
The Weekly Data Engineering Newsletter


The Data Platform Fundamentals Guide
A comprehensive guide for data platform owners looking to build a stable and scalable data platform, starting with the fundamentals:
- Architecting Your Data Platform
- Design Patterns and Tools
- Observability
- Data Quality
The guide also features real-world examples illustrating how different teams have built in-house data platforms for their businesses.
Sebastian Raschka: From DeepSeek-V3 to Kimi K2: A Look At Modern LLM Architecture Design
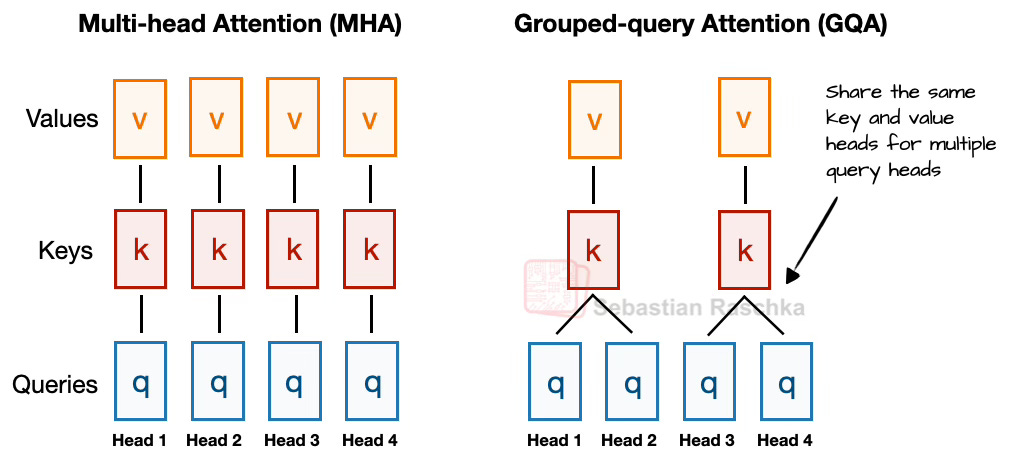
This article examines the structural changes and architectural developments in modern Large Language Models (LLMs), such as DeepSeek-V3, OLMo 2, Gemma 3, and Llama 4, rather than focusing on benchmark performance or training algorithms. The author details key innovations, including Multi-Head Latent Attention (MLA), Mixture-of-Experts (MoE), various normalization layer placements (Pre-Norm, Post-Norm, and QK-Norm), and sliding window attention, which primarily aim to enhance computational efficiency, memory usage, and training stability.
https://sebastianraschka.com/blog/2025/the-big-llm-architecture-comparison.html
Paul Levchuk: The Metric Tree Trap
The article defines a Metric Tree as a hierarchical decomposition of a top-level business goal into measurable drivers, acknowledging its value primarily for visualisation and team alignment of key performance indicators. However, the author critically argues that Metric Trees are unreliable for making robust decisions, as they frequently obscure crucial operational insights due to issues such as contradictory metric definitions, inconsistent granularity, hidden trade-offs, and confounding factors, making the effective identification of key drivers, root cause analysis, and accurate prioritization challenging. To mitigate these "traps" and ensure reliable conclusions, the author strongly advises pairing Metric Tree insights with rigorous root cause analysis, scenario testing, and a thorough cost-benefit assessment.
https://medium.com/@paul.levchuk/the-metric-tree-trap-4280405fd35e
Uber: Unlocking Financial Insights with Finch: Uber’s Conversational AI Data Agent
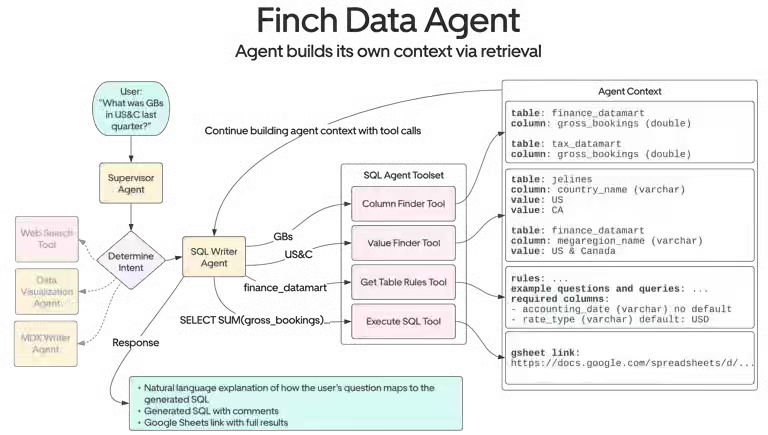
Uber writes about Finch, its AI financial data agent, integrated directly into Slack, designed to transform natural language queries into secure, real-time financial intelligence. The system addresses the significant bottlenecks that financial analysts faced with traditional data access methods, such as manually searching multiple platforms, writing complex SQL queries, or submitting lengthy data requests, which caused delays in decision-making. By leveraging generative AI, RAG, and self-querying agents, Finch streamlines data retrieval, enabling finance teams to access accurate insights rapidly and focus on strategy rather than troubleshooting data pipelines.
https://www.uber.com/en-IN/blog/unlocking-financial-insights-with-finch/
Sponsored: Free ELT Course from Dagster

Dagster is excited to announce the launch of ETL with Dagster, a comprehensive seven-lesson course. This free course guides you through the practical implementation of ETL and architectural considerations, from single-file ingestion to full-scale database replication.
Explore other Dagster University courses covering everything from Dagster fundamentals to best practices for integrating with popular tools.
Uber: Optimizing Search Systems: Balancing Speed, Relevance, and Scalability
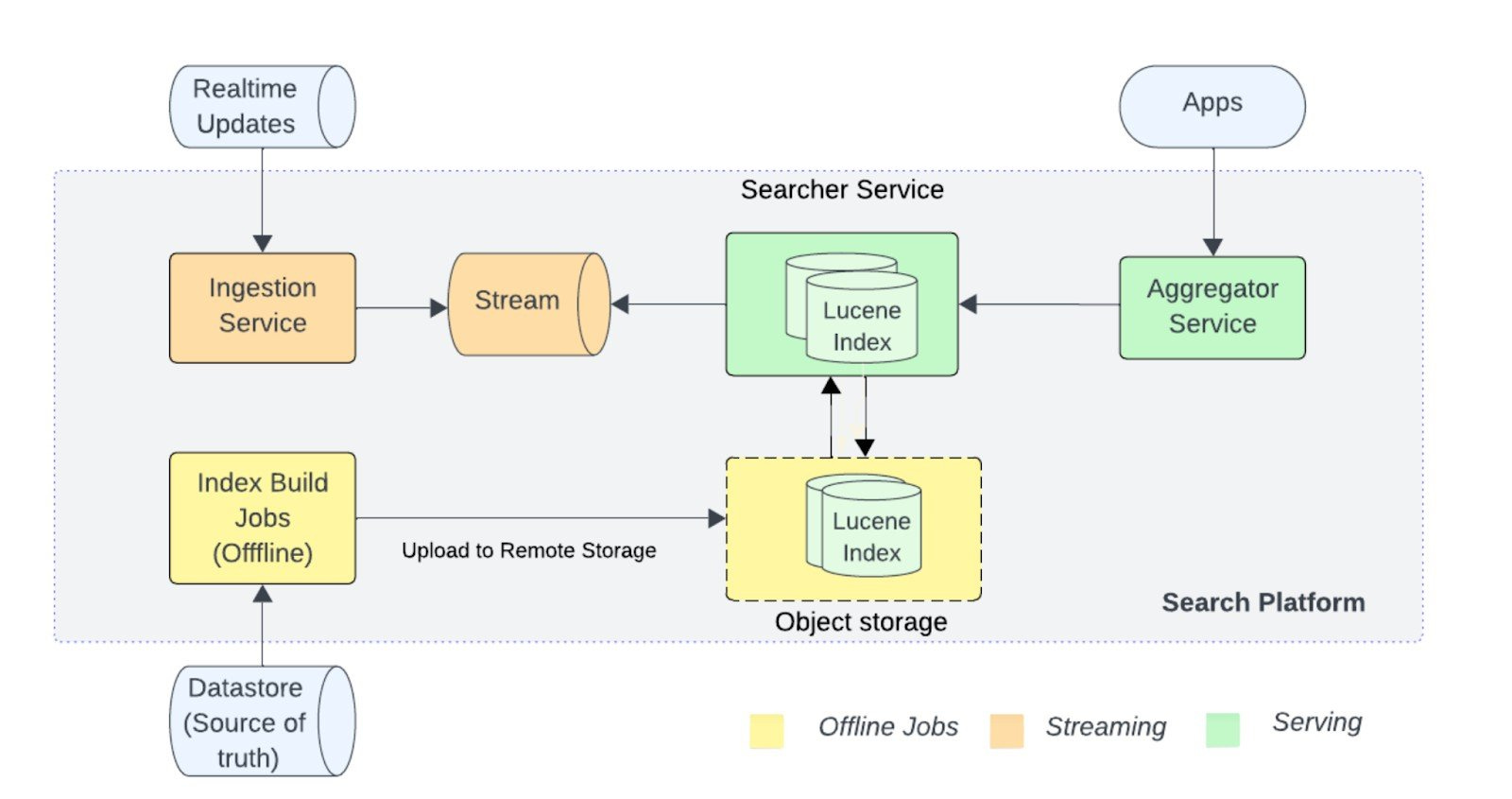
Uber Eats discusses re-architecting its search stack to balance speed, relevance, and the explosive growth of data. By utilizing ETA-aware indexing, grouping data by city and store, geo-sharding with latitude-hex grids, and distributing queries in parallel, the team significantly reduced latency while enhancing recall and horizontal scalability.
https://www.infoq.com/articles/optimizing-search-systems/
Shopify: Leveraging Multimodal LLMs for Shopify’s Global Catalogue: Recap of Expo Talk at ICLR 2025
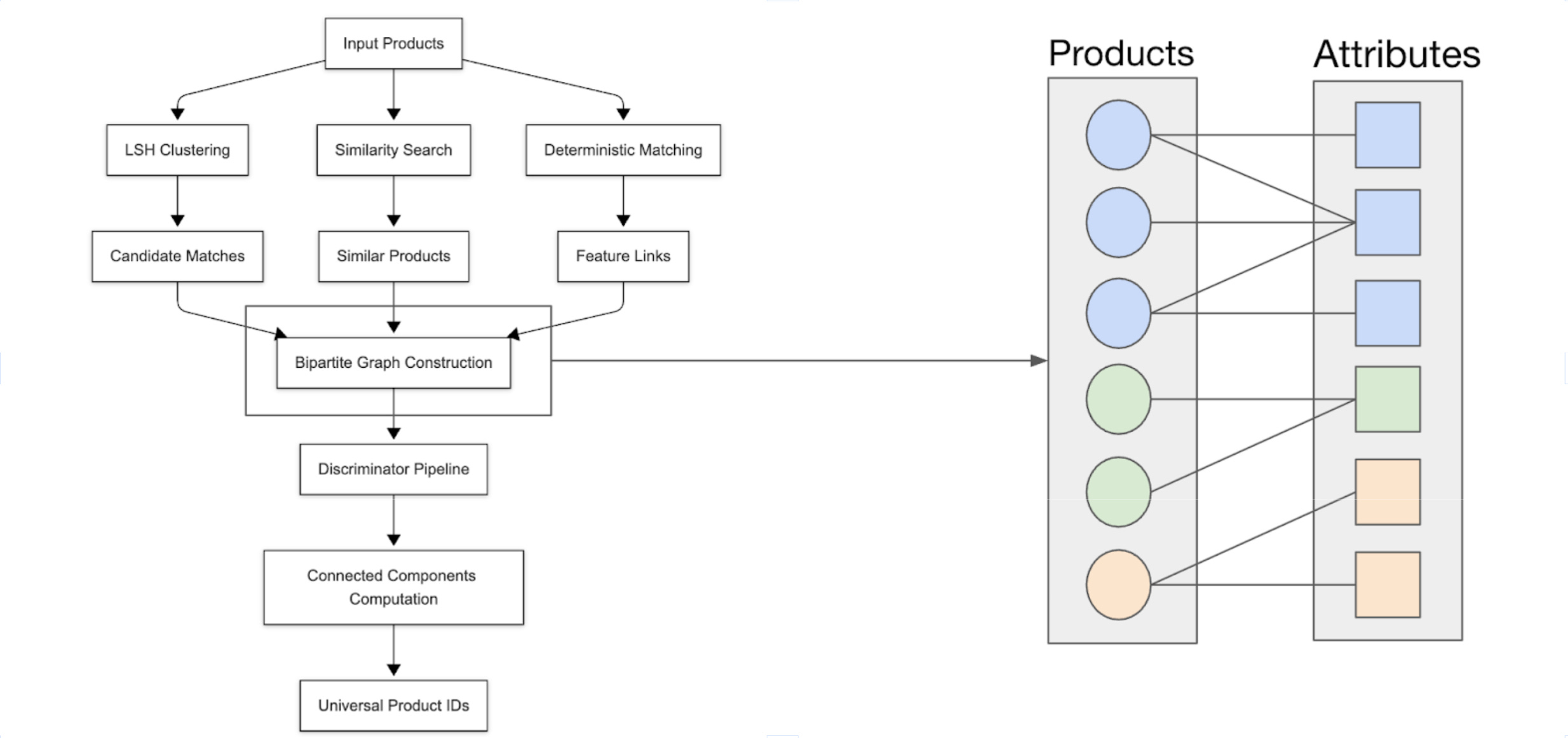
Shopify tackles the substantial data engineering challenge of unifying billions of fragmented, unstructured product listings from millions of merchants, processing over 10 million product updates daily, which often have diverse schemas and data quality issues. The solution involves a four-layer system – product data, understanding, matching, and reconciliation – built upon multimodal Large Language Models (LLMs) to standardise, enrich, and match product listings across the platform.
https://shopify.engineering/leveraging-multimodal-llms
Peloton: Modernizing Data Infrastructure at Peloton Using Apache Hudi
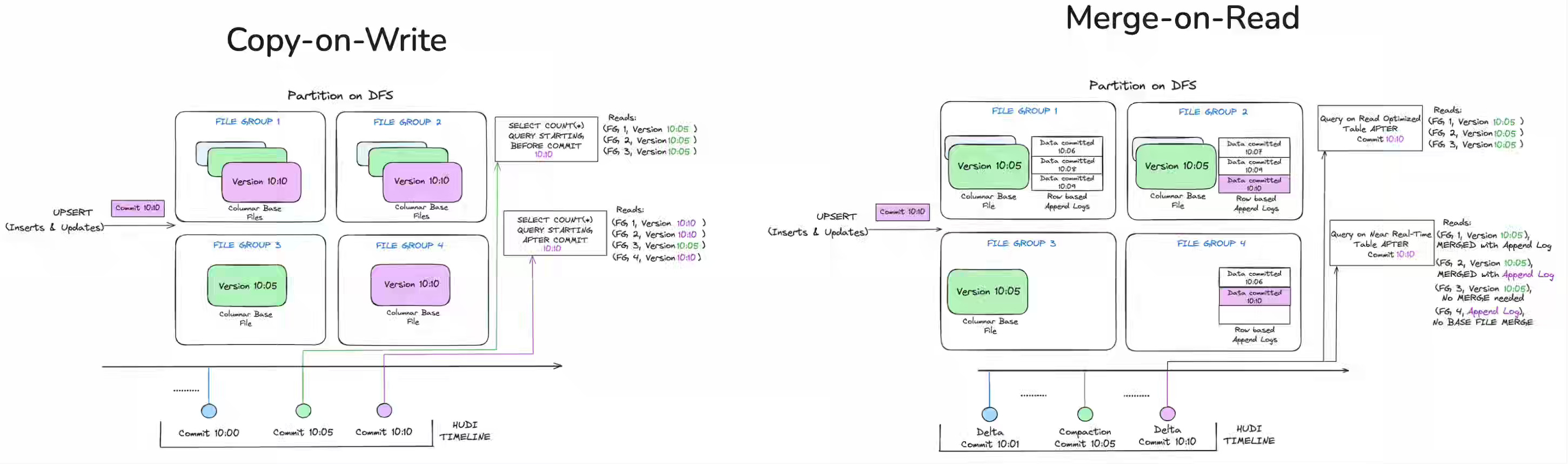
Peloton discusses its adoption of Apache Hudi as part of its effort to modernize its data platform. The article reinforces my experience that for low-latency workloads, the MoR is a viable option in any Lakehouse format.
https://hudi.apache.org/blog/2025/07/15/modernizing-datainfra-peloton-hudi/
Guidewire: How We Cut Operating Costs by 80% While Ensuring Data Integrity at Scale
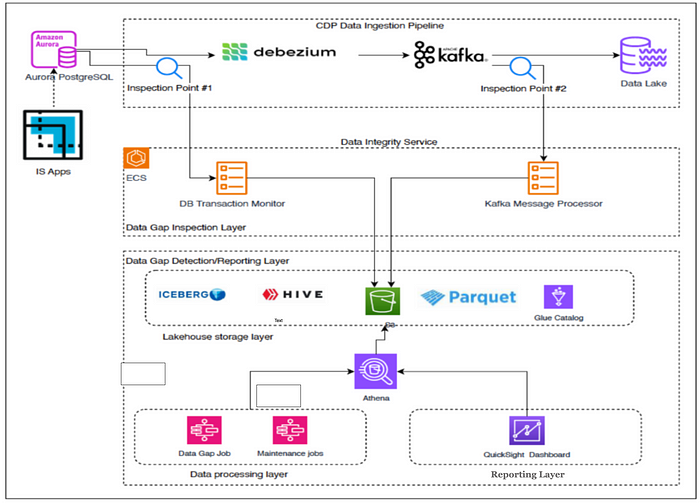
Guidewire writes about the evolution of their Data Integrity Service (DIS), a system designed to detect and recover missing Change Data Capture (CDC) events in real-time from their InsuranceSuite applications. The initial architecture employed a dual-checkpoint system, comprising a DB Transaction Monitor and a Kafka Message Processor, which sent metadata to Kinesis Firehose and subsequently to S3 and Redshift. However, it faced scalability and cost challenges with managed AWS services. To address this, they redesigned the architecture, replacing Firehose with a custom S3 upload client for greater control and efficiency, and migrating from Redshift to a cost-effective Lakehouse architecture using S3 and Apache Iceberg.
Apache Hudi: RFC-92 (or 93): Pluggable Table Formats in Hudi
An interesting read for me this weekend about Hudi's attempt to provide the pluggable table format support similar to MySQL (InnoDB & MyISAM). The RFC is strategically sound and aligns with your “one writer, many readers” lakehouse vision. One of the most challenging problems I encounter in the Lakehouse is the ability to handle rapidly changing dimensions with sub-second latency. I would love to see the Lakehouse emerging from a file overwrite to truly become a database with row-level transactions guarantee on top of the object storage. However, interoperability among the lakehouse formats is a welcome step.
https://github.com/bvaradar/hudi/blob/c6cc666e692c9395a8909ddaed28d994dee59089/rfc/rfc-93/rfc-93.md
Capital One: Delta Lake transaction logs explained
The article explains the _delta_log, the transactional log at the core of the Delta Lake table format, which provides ACID guarantees, schema governance, and time-travel capabilities to data lakes. The author details how updates work by rewriting files rather than in-place modification, how optimistic concurrency control handles concurrent writes, how failure recovery is ensured by writing data files before committing the transaction log, and how the log enables schema evolution, schema enforcement, and time-travel queries.
https://medium.com/capital-one-tech/delta-lake-transaction-logs-explained-6b5f036e64e2
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
Thank you so much for the knowledge share, it was really educative.