
Data Engineering Weekly #230
The Weekly Data Engineering Newsletter


How to Build a Data Platform From Scratch
Learn the fundamental concepts to build a data platform in your organization.
- Tips and tricks for data modeling and data ingestion patterns
- Explore the benefits of an observation layer across your data pipelines
- Learn the key strategies for ensuring data quality for your organization
Modern Data 101: The Three-Body Problem of Data: Why Analytics, Decisions, & Ops Never Align
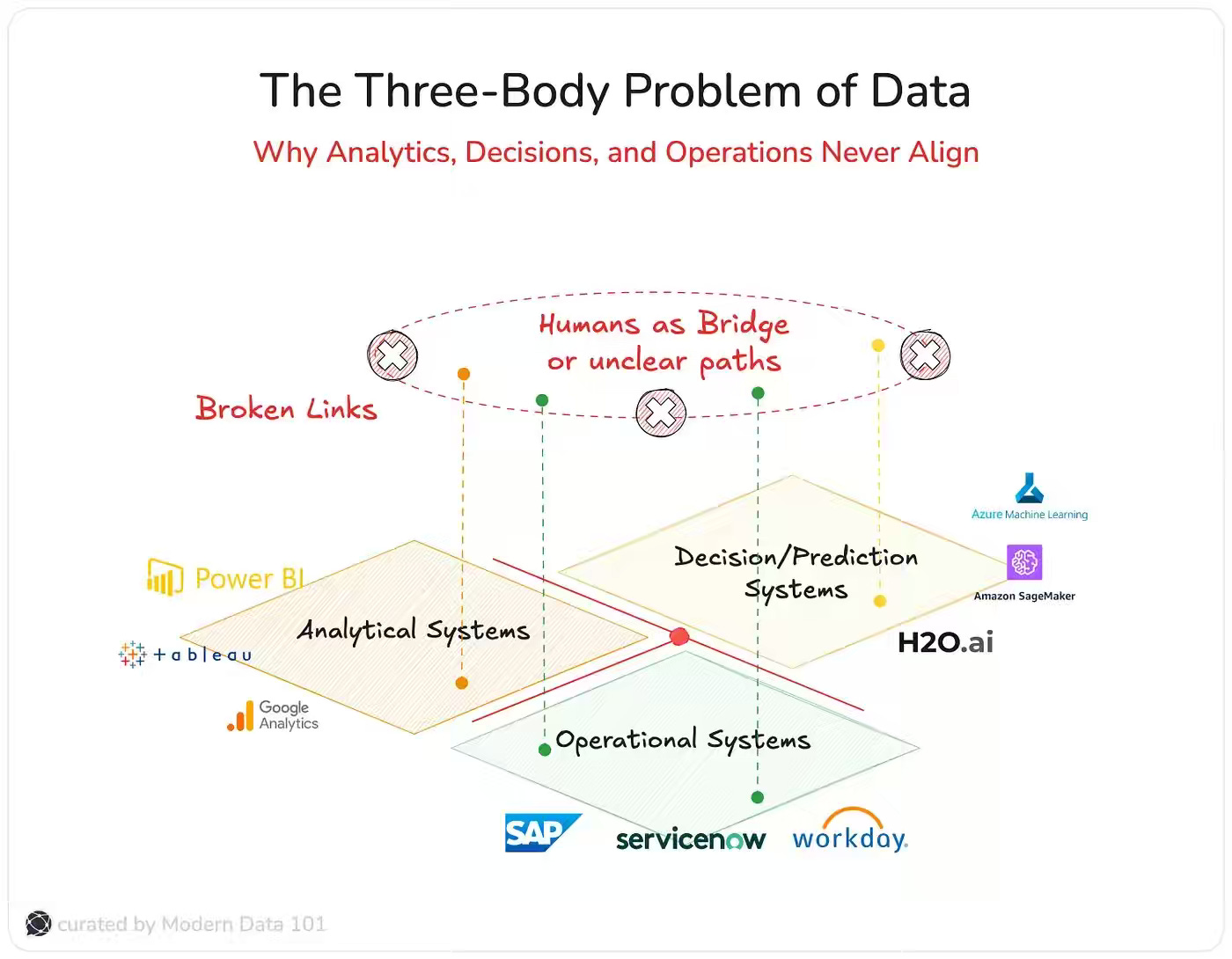
Everyone’s building systems that report. Few are building systems that respond.
The author captures the disaggregated nature of analytics, decision-making systems, and operational systems where humans are required to bridge insights to actions. The case for the action layer is certainly appealing, but it requires a strong feedback loop to build systems with tolerance to failures.
Grab: The evolution of Grab's machine learning feature store.
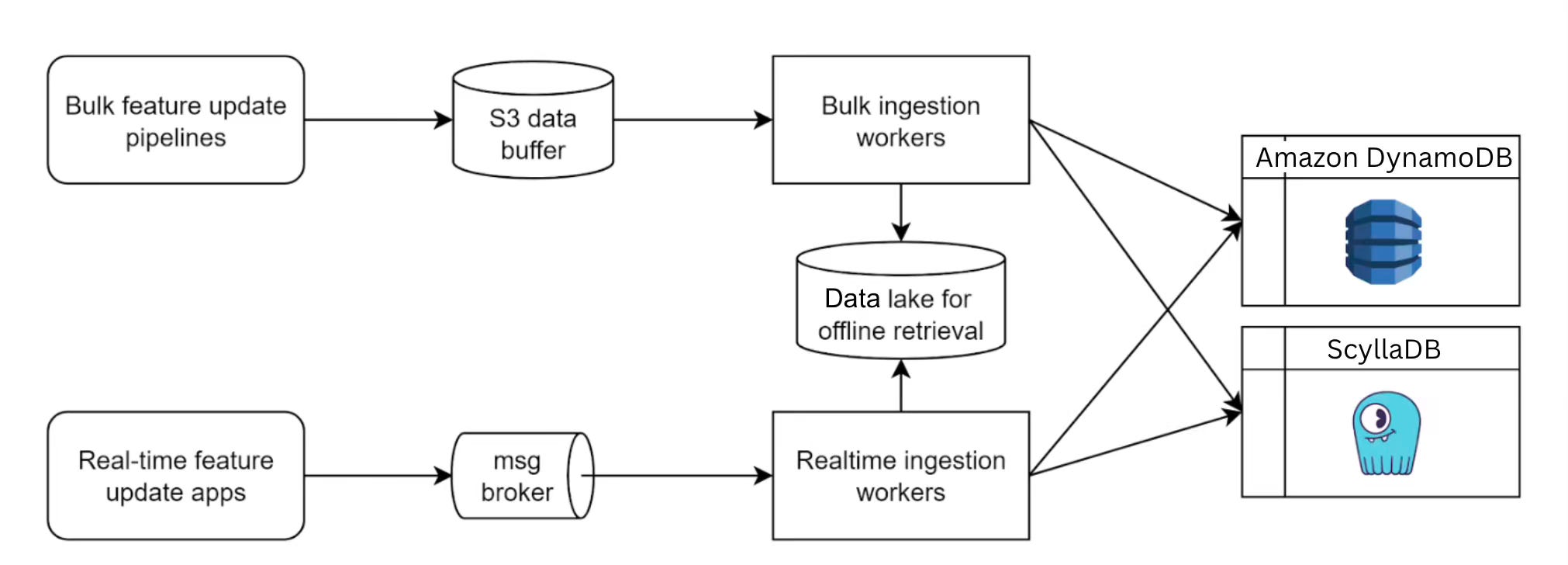
Grab writes about how Grab overhauled its ML feature store by introducing feature tables—user-defined data-lake tables ingested atomically into Amazon Aurora PostgreSQL to support high-cardinality features, contextual composite-key retrieval, and isolated read/write capacity. The blog details an S3-to-Aurora pipeline with schema validations, warm-up reads, and a decentralized SDK-driven serving layer that streamlines version control, boosts caching efficiency, and balances costs with serverless and provisioned Aurora nodes.
https://engineering.grab.com/evolution-of-grab-machine-learning-feature-store
Intuit: Vibe Coding in the Age of AI: Navigating the Future of Software Development 2.0
Vibe coding isn’t about displacing a skill set — it’s about elevating the role of the developer — freeing us from rote work so we can focus on the architecture, design, and problem-solving to really move the needle for our customers.
The vibe coding, or coding with an agent as a companion, is an efficient way to build software, allowing you to focus on higher-order functions as a software engineer. It is exciting to see how far it will go and how the industry evolves around the concept of vibe coding.
Sponsored: What CoPilot Won’t Teach You About Python

Python is a joy to write. Part of the appeal is just how flexible it is. But flexibility can also hide some of the more interesting and powerful features of the language, especially if you’re primarily writing code with the help of AI agents. While AI agents can be incredibly helpful, they often default to safe, conventional solutions rather than code that really push the bounds of Python.
In this article, we highlight some of the advanced Python features we use ourselves across the Dagster codebases and explore how they might help you elevate your code.
Learn advanced Python features that AI agents may miss
TigerData: Three TigerData Engineers Told Us the Truth About MCP – Security Is Its Achilles Heel

TigerData writes about how TigerData’s engineers reveal that the Model Context Protocol (MCP) is inevitable but suffers from serious security flaws that threaten its production use. The blog presents the perspectives of three engineers on MCP’s strengths, including standardized API integration and contextual retrieval, alongside critical vulnerabilities (CVE-2025-6514, CVE-2025-49596), and best practices such as least-privilege permissions and human-in-the-loop confirmations.
Cloudflare: Building Jetflow: a framework for flexible, performant data pipelines at Cloudflare
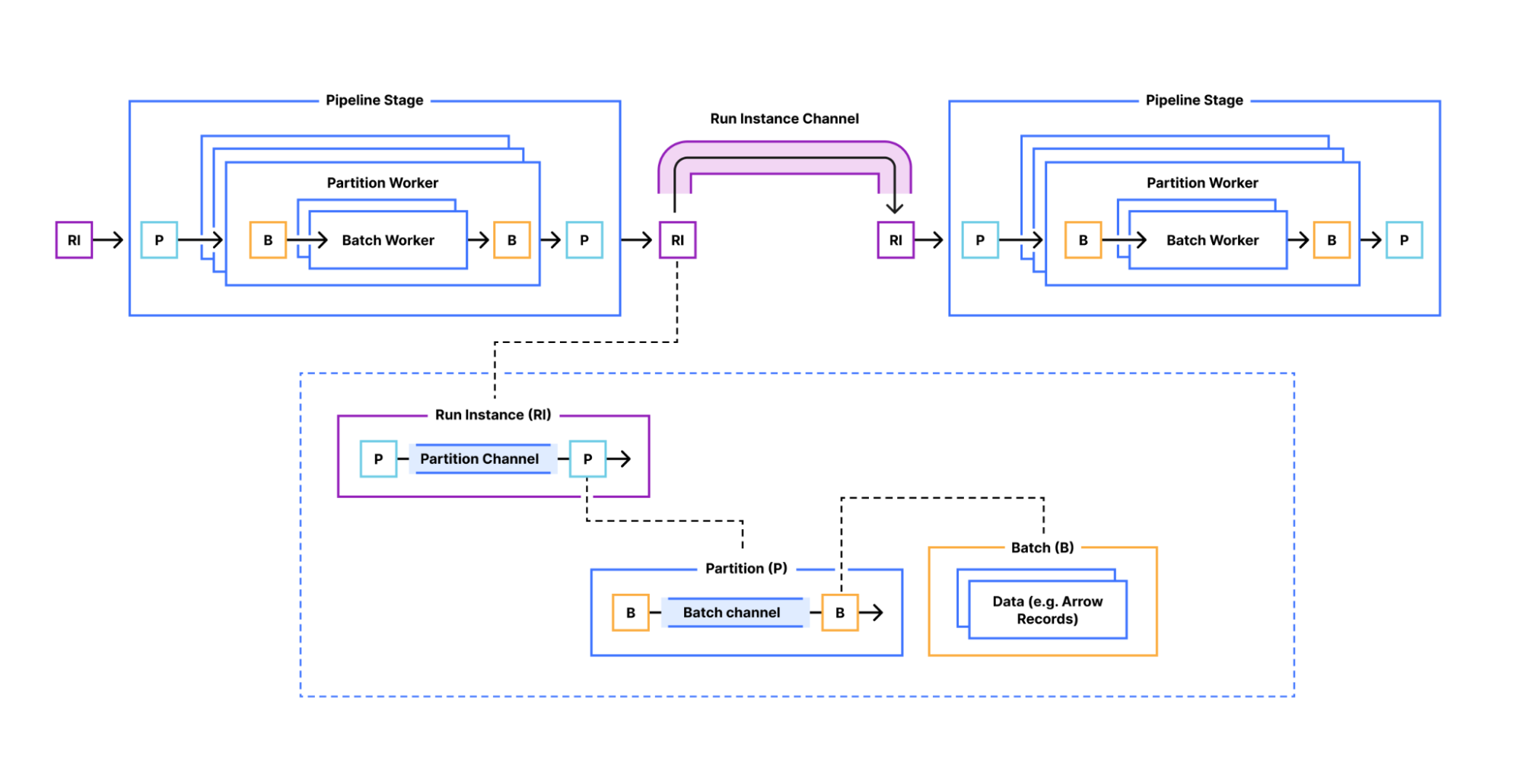
Cloudflare discusses how it built Jetflow to address its petabyte-scale ingestion challenges, achieving over 100× GB-efficiency gains (reducing a 19 billion-row job from 300 GB/48 hours to 4 GB/5.5 hours) and more than 10× throughput improvements. The blog details Jetflow’s YAML-configured consumer-transformer-loader stages, deterministic run/partition/batch divisions, as well as Arrow-based columnar optimizations that enable streaming, low-allocation pipelines across Postgres, ClickHouse, Kafka, SaaS APIs, and more.
Meta: Policy Zones - How Meta enforces purpose limitation at scale in batch processing systems
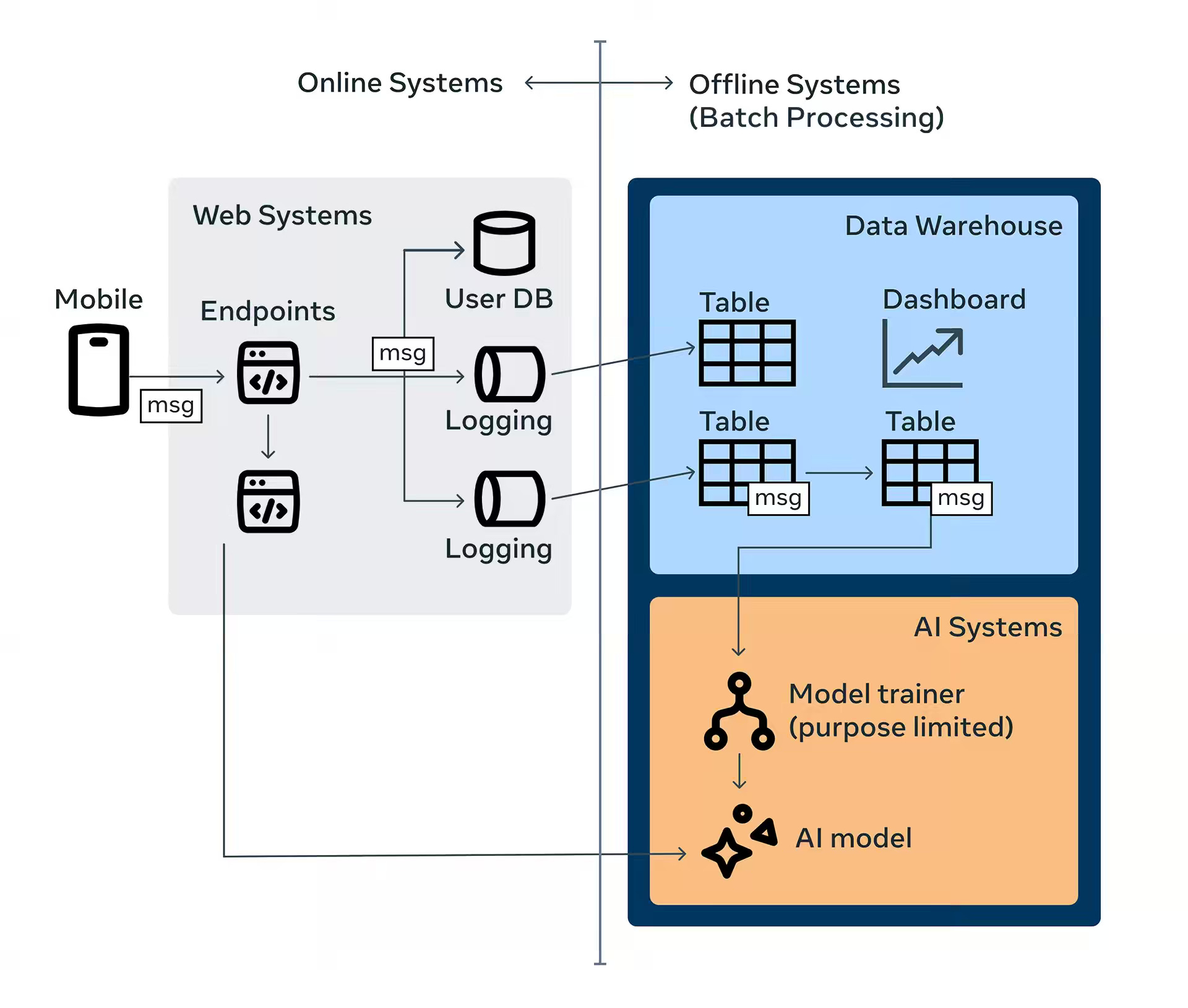
Meta writes about how Meta developed Privacy Aware Infrastructure (PAI) and Policy Zones to enforce purpose limitations across its exabyte-scale batch and stream processing systems using runtime enforcement and SQL parsing. The blog details how Policy Zones applies fine-grained information-flow tracking with Governable Data Annotations, performs trillions of user-consent checks via a Policy Evaluation Service, and equips engineers with tools like PZM and Dr. PZ for seamless integration, reclassification, and end-to-end privacy compliance.
Dipankar Mazumdar: What is Apache Arrow Flight, Flight SQL & ADBC?
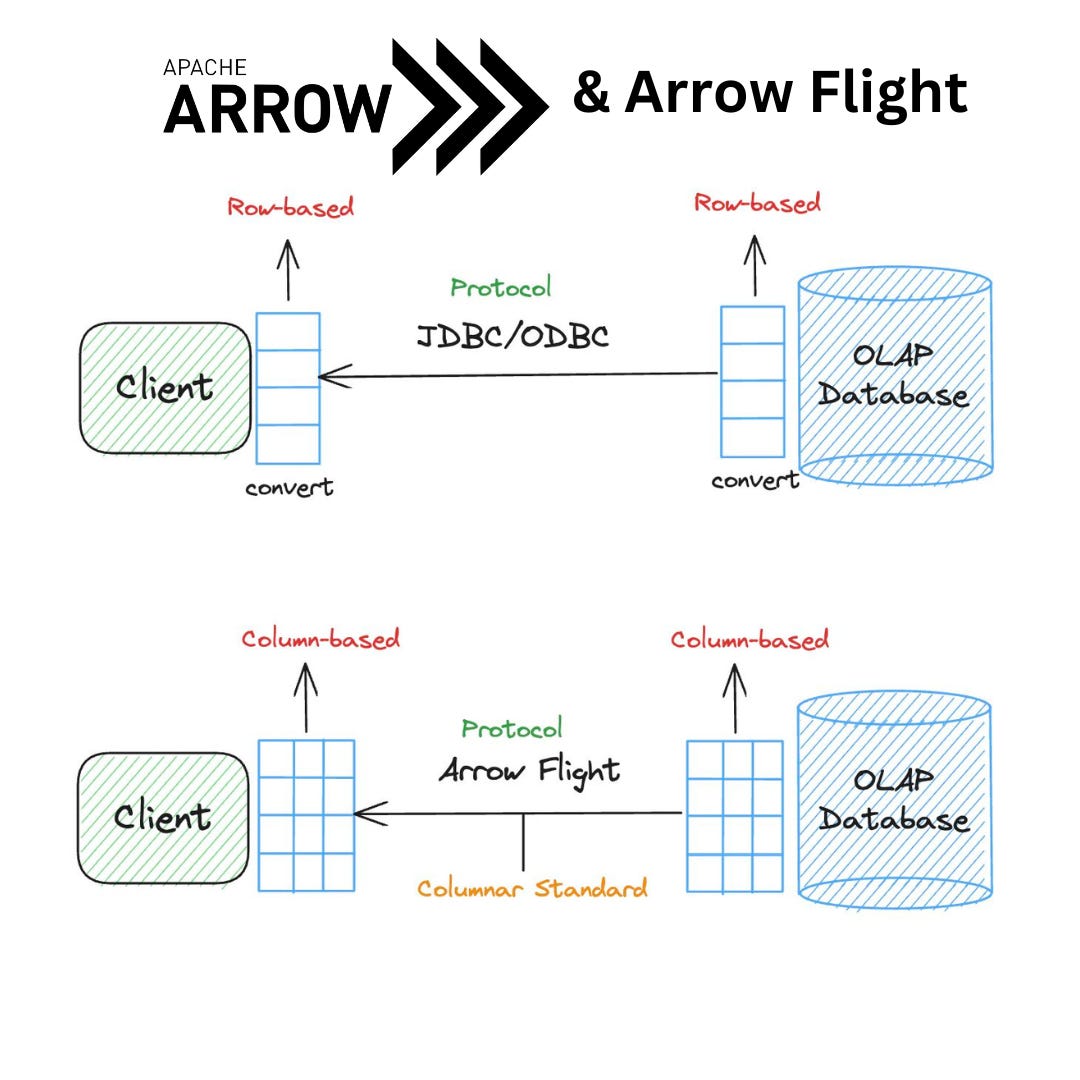
An excellent overview about how Apache Arrow Flight, Flight SQL & ADBC overhaul database connectivity by replacing ODBC/JDBC’s row-based transfers with a columnar-native, high-performance RPC protocol and standardized APIs. The blog details Arrow Flight’s zero-copy parallel streaming, Flight SQL’s direct SQL-over-Arrow transport, and ADBC’s unified, Arrow-native API, highlighting massive performance gains, cross-language support, and seamless integration with legacy systems.
https://dipankar-tnt.medium.com/what-is-apache-arrow-flight-flight-sql-adbc-a076511122ac
Apache DataFusion: Embedding User-Defined Indexes in Apache Parquet Files
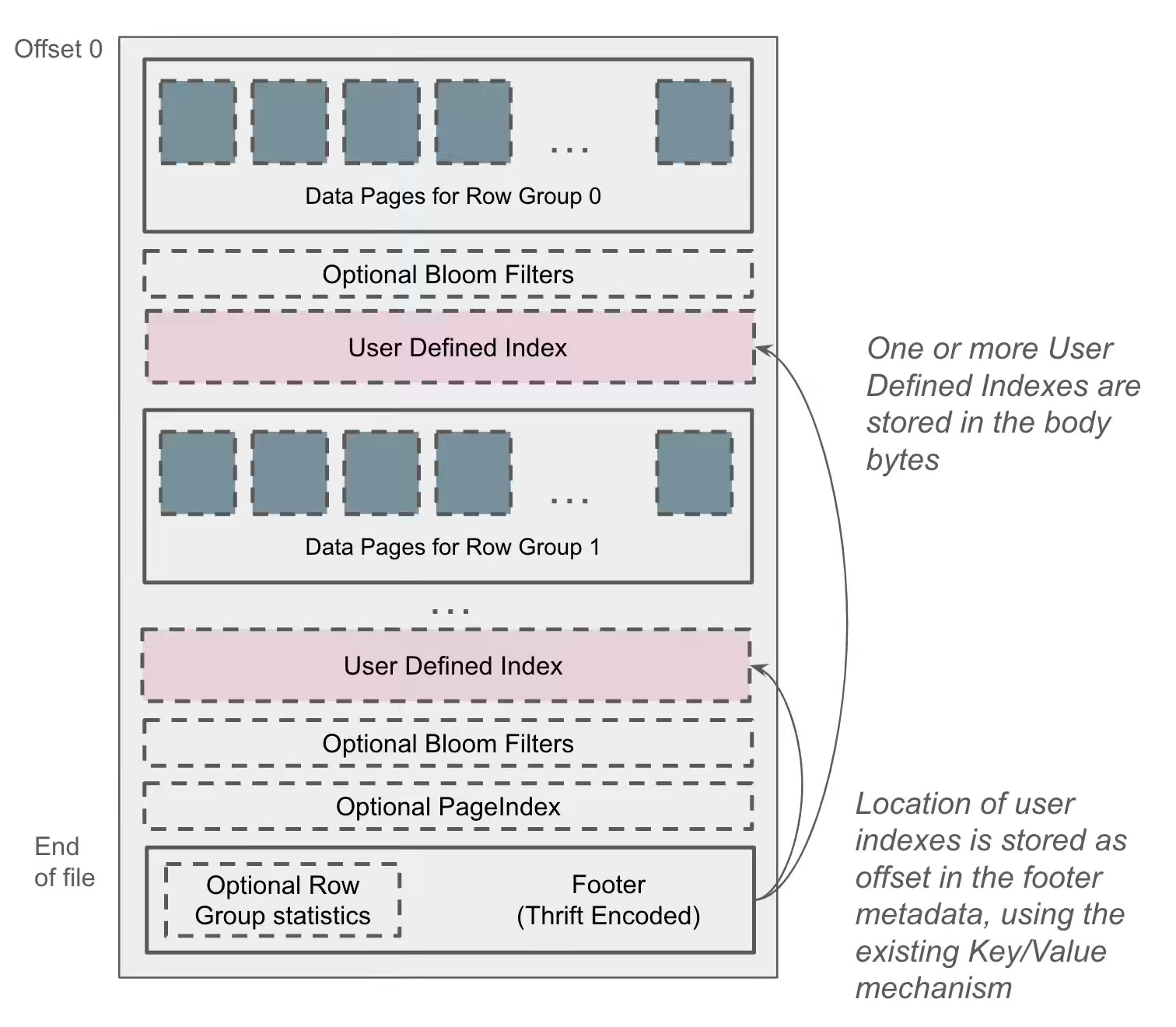
TIL: You can write a custom index for Apache Parquet. I wish the query engines' construction also offered an easier and extensible way to utilize the custom indexes.
The blog discusses how user-defined index structures in Apache Parquet files are achieved by appending serialized index bytes to the file body and recording their offsets in the footer metadata, all without altering the Parquet specification or compromising reader compatibility. The blog details an example of a distinct-value index—showing magic-header serialization, ArrowWriter API usage, and metadata key/value recording—and demonstrates how to extend DataFusion’s TableProvider to prune files at query time using the embedded index.
https://datafusion.apache.org/blog/2025/07/14/user-defined-parquet-indexes/
Databricks: Spark UI Simulator
The Spark UI simulator, provided by Databricks, is a tool designed to help developers understand and debug Apache Spark jobs. It provides a collection of pre-run Spark jobs that demonstrate various performance scenarios and common issues. The recent announcement from AWS to support the MCP server for Spark history servers, together, makes the debugability of Apache Spark jobs much simpler.
https://www.databricks.training/spark-ui-simulator/index.html
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.