
Data Engineering Weekly #231
The Weekly Data Engineering Newsletter


Dagster Running Dagster: Event Driven Pipelines
At Dagster, we process millions of events a day from Dagster+. This event data is used for tracking credit usage, powers tools like Insights, and provides a peek into how organizations are using our platform. This data comes in at such velocity that we need to take advantage of stream processing tools like Apache Kafka and Flink to ensure that we are capturing every event and doing so efficiently.
In this webinar, we'll show you how we integrate these tools into our data platform, take advantage of Dagster's observability features to monitor this streaming pipeline, and ingest this data into our internal data warehouse.
Kurt Cagle: Why It's Time To Rethink Linked Data
As the LLM takes center stage in the way we interact with data, the knowledge graphs are becoming a critical part of the data infrastructure. The author highlights the shortcomings of both named graphs and property graphs and explains how the RDF-star specification offers flexibility in building entity relationships.
https://ontologist.substack.com/p/why-its-time-to-rethink-linked-data
Stackoverflow: 2025 Developer Survey
The "Almost Right" Problem: 66% of developers are frustrated with AI solutions that are almost right, but not quite, making debugging AI-generated code more time-consuming than helpful.
It is undeniable that AI accelerates the coding process, but operationalizing the code remains a bottleneck. Despite the usage continuing to grow, the positive sentiment for AI tools has decreased in 2025: 70%+ in 2023 and 2024 to just 60% this year.
https://survey.stackoverflow.co/2025
LangChain: How to Build an Agent
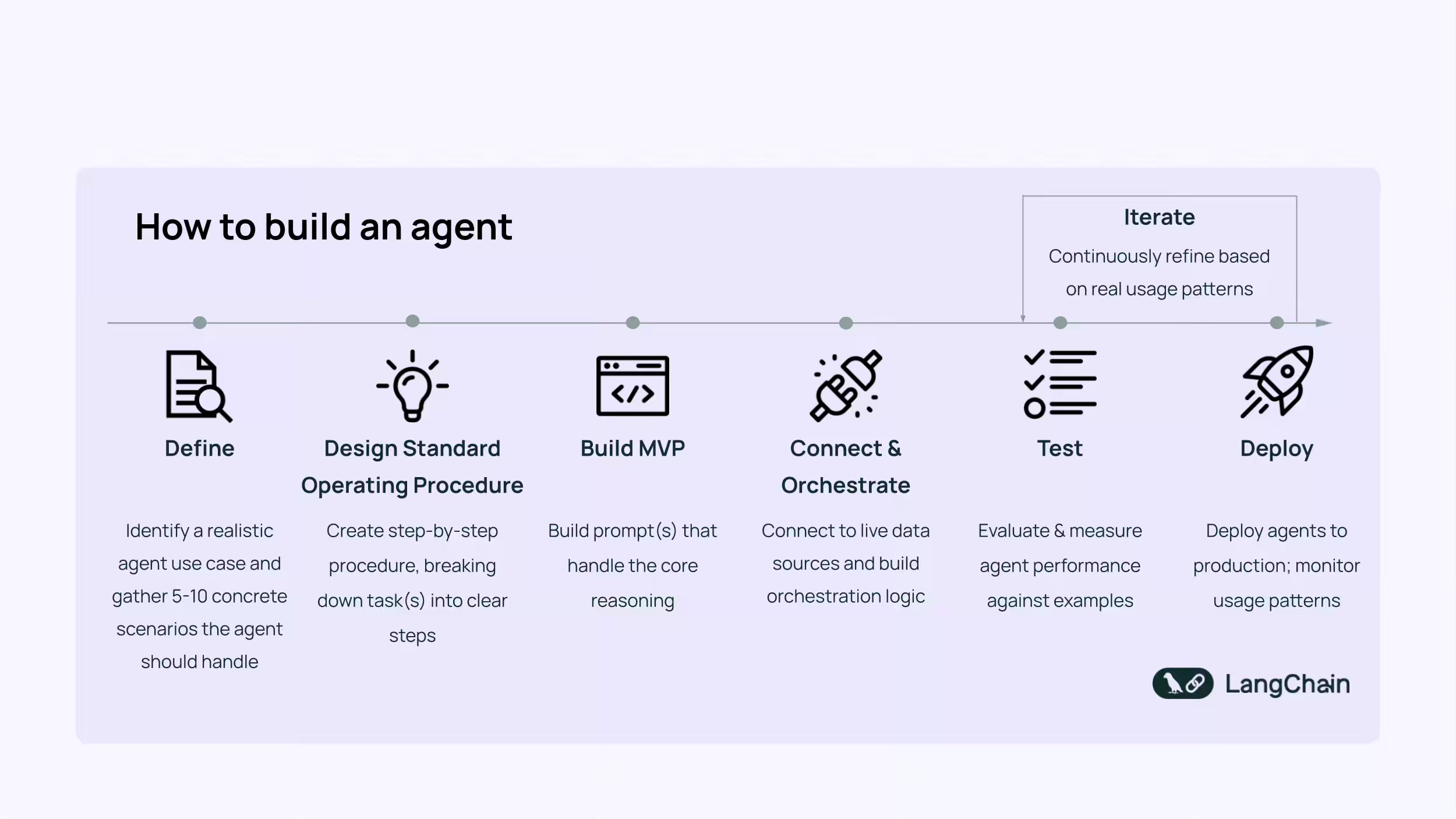
Instead of a typical technical walkthrough of building an agent, the LangChain blog narrates how to think through an agent-building process structurally. The blog walks through six practical steps—from defining realistic task examples and drafting a detailed SOP to developing an MVP prompt, orchestrating data and APIs, testing iteratively, and deploying at scale.
https://blog.langchain.com/how-to-build-an-agent/
Sponsored: How to Build a Data Platform From Scratch

A comprehensive guide for data platform owners looking to build a stable and scalable data platform, starting with the fundamentals:
- Architecting Your Data Platform
- Design Patterns and Tools
- Observability
- Data Quality
The guide also features real-world examples illustrating how different teams have built in-house data platforms for their businesses.
LinkedIn: OpenConnect - LinkedIn’s next-generation AI pipeline ecosystem
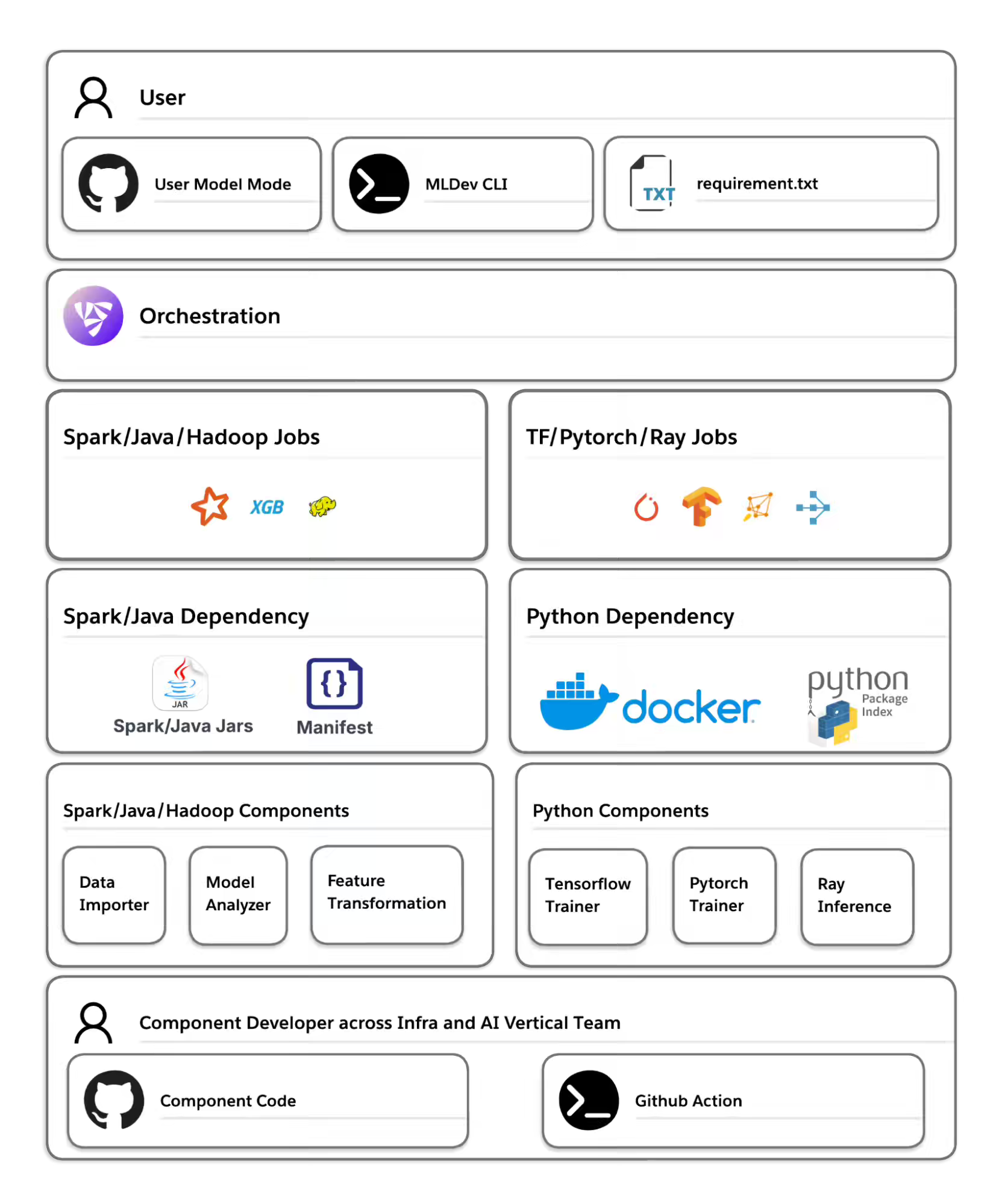
LinkedIn writes about how LinkedIn built OpenConnect to replace its legacy ProML pipelines, slashing launch times from 14 minutes to under 30 seconds and cutting failure-detection time by 80% across 100k+ monthly AI executions. The blog details OpenConnect’s architecture—featuring a reusable component hub, decoupled dependency caching, output caching, and partial reruns, and a global, multi-cluster scheduler—to deliver scalable, robust, and rapid AI pipeline development.
Meta: Table Compare: Safeguarding Data Integrity at Meta
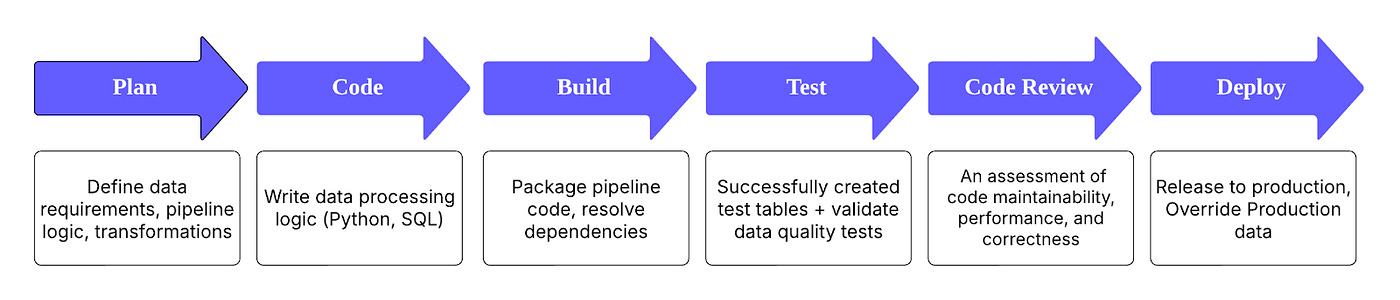
A surprising fact about data engineering is that the process is very waterfall-like. I find it surprising because we don’t talk about this inefficiency. Yes, code-first data asset creation is a must, but that pushed us towards code validation rather than data validation. The blog from Meta rightly calls out these nuances and writes about how it built the table comparison feature to safeguard against data integrity problems.
https://medium.com/@AnalyticsAtMeta/table-compare-safeguarding-data-integrity-at-meta-bb77e5363dd4
Wix: How Wix Cut 50% of Its Data Platform Costs - Without Sacrificing Performance
Establishing a chargeback model is always an aspiration for the internal platform engineering teams. Wix writes about its approach to understanding the cost spending by tagging various stages of infrastructure and data assets.
Klaviyo: Ray Data, Train & Tune at Klaviyo
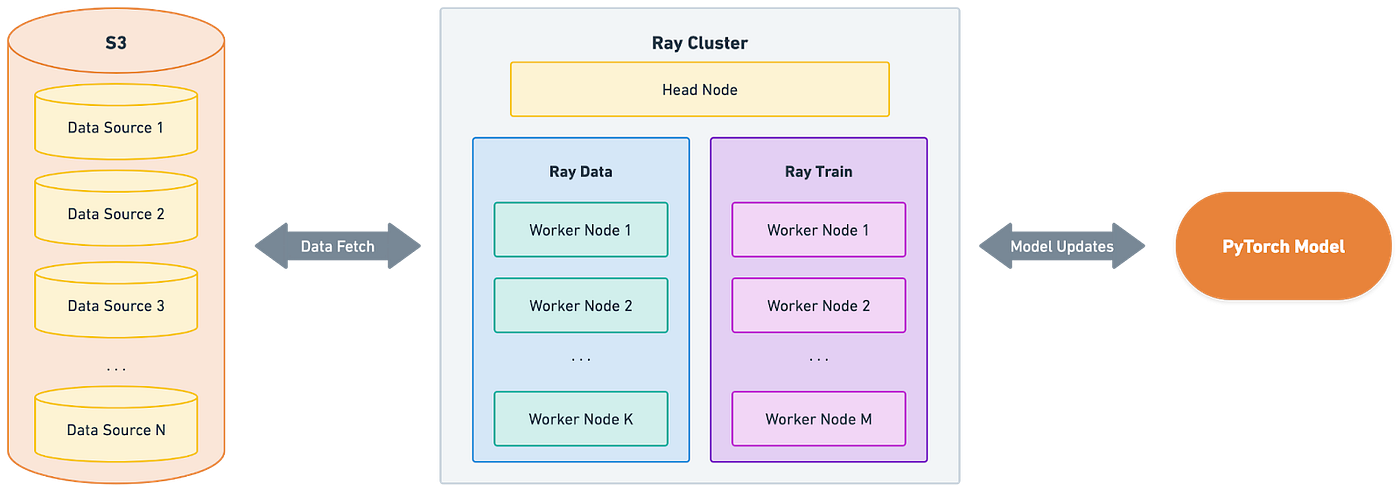
Klaviyo writes about how it leverages Ray Data, Ray Train, and Ray Tune to create scalable, cost‐efficient pipelines for large‐scale data preprocessing, distributed model training, and hyperparameter optimization. The blog details Ray Data’s Python‐native, Arrow‐backed ETL on massive datasets; Ray Train’s seamless DDP‐powered PyTorch orchestration; and Ray Tune’s Optuna‐integrated search for large‐scale hyperparameter tuning, all with minimal code changes from development to production.
https://klaviyo.tech/ray-data-train-tune-at-klaviyo-bca9f14abf21
Anant Kumar: Building Reproducible ML Systems with Apache Iceberg and Spark SQL: Open Source Foundations
The author narrates how Apache Iceberg transforms data lakes into ML-ready platforms by adding database-grade features like time travel, schema evolution, intelligent partitioning, and ACID transactions to solve reproducibility and reliability challenges. The blog details snapshot-based versioning for precise data tracking, smart partitioning aligned with filter columns to slash query times, non-disruptive schema evolution for seamless feature rollout, and ACID guarantees for consistent reads—all provided via an open-source framework that avoids vendor lock-in.
https://www.infoq.com/articles/reproducible-ml-iceberg/
Ly Corp: Milvus: Building a large-scale vector DB for LINE VOOM's real-time recommendation system
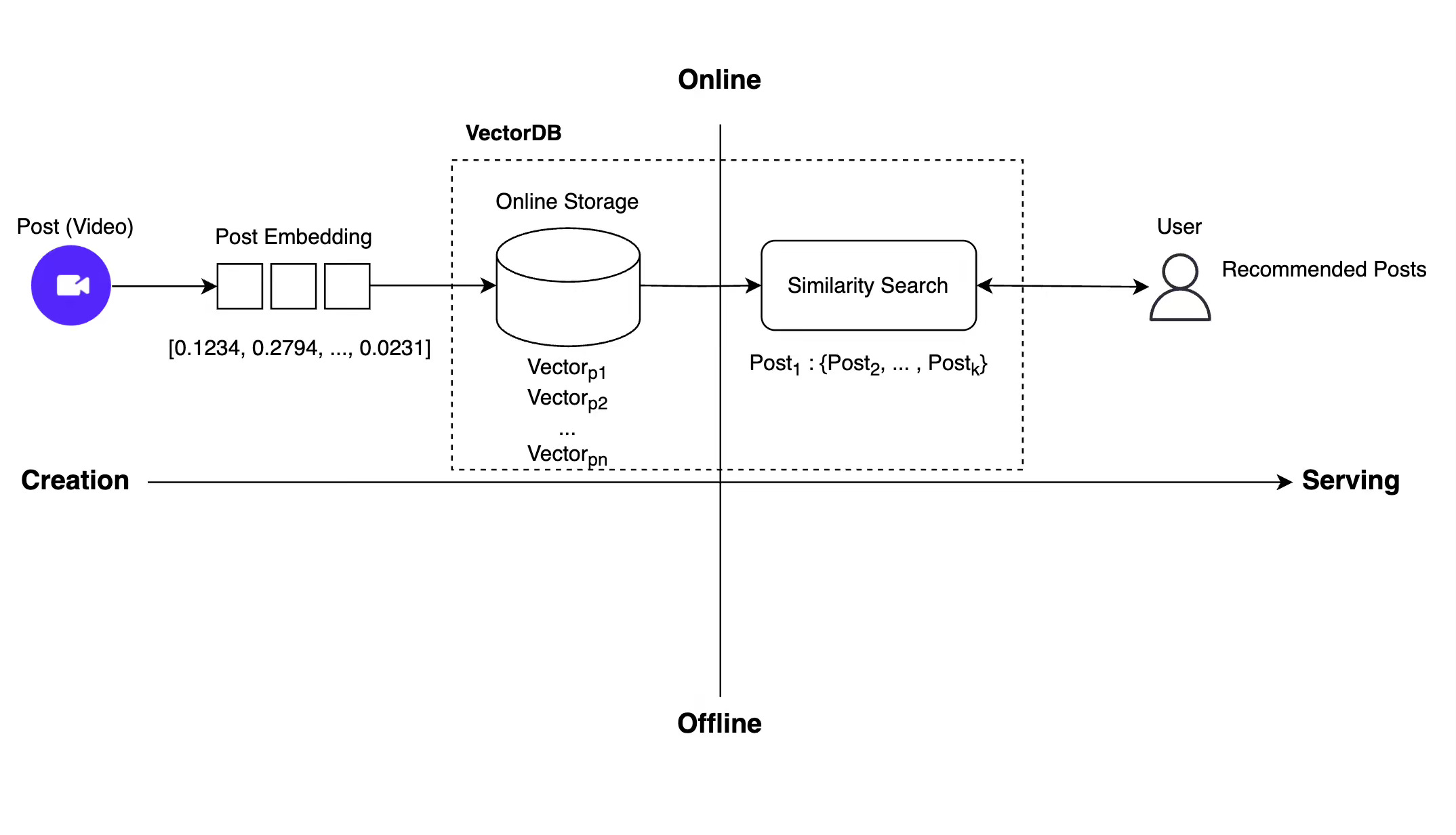
Ly Corp writes about how Milvus underpins LINE VOOM’s shift from daily batch to real-time content recommendations by storing embeddings online and running instant ANN searches via a scalable vector database.
The blog details selection criteria versus Qdrant, chaos testing, and high-availability setups (collection aliases, standby coordinators, backups), performance tuning across ANN indexes (HNSW, IVF), scale-up/out, and in-memory replication—achieving sub-5 ms queries, > 10,000 QPS, 12 % fresher feeds, and a 39 × jump in same-day post exposure.
https://techblog.lycorp.co.jp/en/large-scale-vector-db-for-real-time-recommendation-in-line-voom
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.