
Data Engineering Weekly #232
The Weekly Data Engineering Newsletter


Dagster Running Dagster: Event Driven Pipelines
We had a huge response to our last Dagster Running Dagster session, and we’re bringing it back with a focus on event-driven pipelines and real-time observability.
Dagster engineer Nick Roach (with Alex Noonan & Colton Padden) will walk through how we orchestrate millions of daily events with real-time observability using Dagster+.
What you’ll learn:
- Designing reliable streaming workflows
- Integrating Dagster with Kafka & Flink
- Monitoring event-driven pipelines in production
Reserve your spot now.
Event Alert: Atlan Activate - Reimagining Data Catalogs & Governance in the AI Era
Models don’t know what data is fit for purpose. Agents don’t understand business logic. Chatbots expose what they shouldn’t.
On August 21st at 1 PM ET, Atlan will unveil its next chapter at Activate- a complete reimagination of metadata infrastructure for the AI era.
Expect major product launches, live demos, and answers to questions shaping AI strategy today:
→ Can we govern AI agents & prompts the way we govern data?
→ How can AI find the right data for its use case?
→ Can context make “talk to data” truly enterprise-ready?
👉 Register now: https://atlan.com/activate
Capital One: AI agents vs. predefined workflows: a practical decision guide
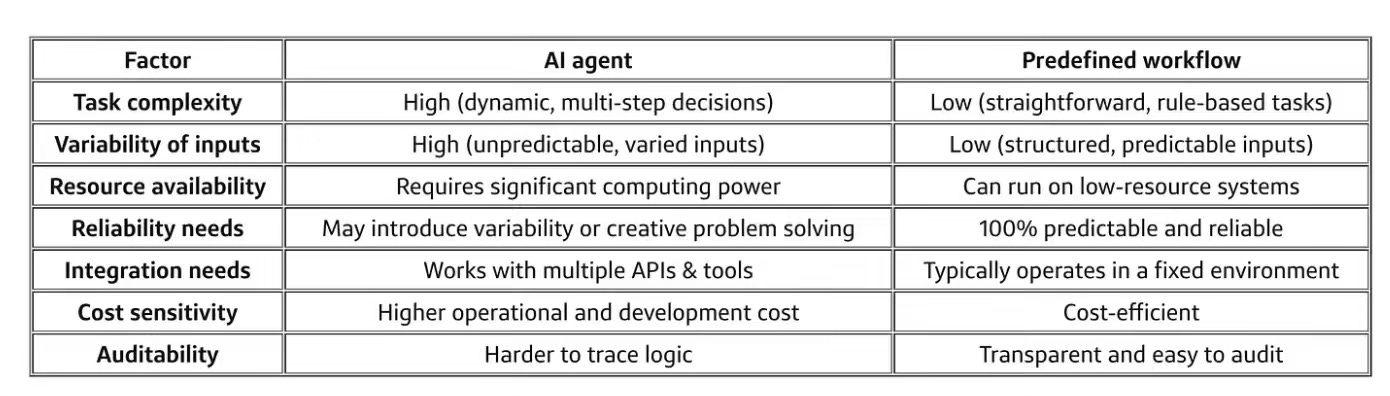
Most operational business processes can be modeled as a set of interacting state machines (with attached data), executing event-driven flows, sometimes with human steps, timeouts, and probabilistic outcomes.
AI agents are playing a pivotal role in the way we build software, and the fundamental question is how and where to apply an agentic flow vs a predefined workflow. Capital One writes an excellent guide narrating the criteria to decide between them.
Shopify: MCP UI - Breaking the text wall with interactive components
Shopify writes about how Shopify extends the Model Context Protocol with MCP UI to let agents return fully interactive commerce components—like product selectors, image galleries, and carts—via embedded UI resources and an intent-based messaging system. The blog details three delivery modes (inline HTML, remote resources, remote DOM), an intent framework for actions (e.g., add_to_cart, checkout) that keeps the agent in control, adaptive styling via render data, and an open-source spec that generalizes to data viz, form builders, and media players.
https://shopify.engineering/mcp-ui-breaking-the-text-wall
Wix: The AI Code Velocity Trap: When “Done” Isn’t Done.

As enterprises adopt AI to generate code, there is an inherent assumption built into the executives' thinking that coding is a commodity now. As with any automation process, the complexity around quality control increases since we often don't know what the definition of done is. The blog details a "Pyramid of Reviewers" process (developer self-review, AI as sparring partner, human peer review) and a strict small-PR policy, arguing that real velocity comes from preserving quality, context, and long-term ownership.
https://medium.com/wix-engineering/the-ai-code-velocity-trap-when-done-isnt-done-8c39e403fc48
Sponsored: Build a Data Platform From Scratch

Learn the fundamental concepts to build a data platform in your organization.
- Tips and tricks for data modeling and data ingestion patterns
- Explore the benefits of an observation layer across your data pipelines
- Learn the key strategies for ensuring data quality for your organization
Agoda: A Retrospective: Agoda’s GenAI Journey Thus Far
Enterprises have well passed the argument of Human vs AI, and are looking to AI to accelerate productivity. We started to see case studies from different companies, and Agoda does the same. The blog details grassroots communities (mastering-gpt), shared infrastructure for provider routing, compliance, and cost attribution, engineering/productivity assistants (Copilot rollouts, coding/plan/review agents, AskGoda, meeting/docs tools), and customer features (Q&A, review summarization, content curation), stressing a foundation-first approach, rigorous testing/monitoring, and leadership support for continued scale.
https://medium.com/agoda-engineering/a-retrospective-agodas-genai-journey-thus-far-b0739683d53e
Hamel Husain & Ben Clavié: Stop Saying RAG Is Dead
The author argues that RAG isn’t dead—only the 2023 “embed everything and cosine it” version is, emphasizing that retrieval remains essential and must move beyond single-vector compression. The blog outlines a path forward, which involves evaluating for coverage/diversity/relevance, utilizing instruction-following retrievers that reason, adopting late-interaction/token-level representations (e.g., ColBERT), and routing queries across multiple specialized indices with intelligent orchestration.
https://hamel.dev/notes/llm/rag/not_dead.html
Netflix: FM-Intent: Predicting User Session Intent with Hierarchical Multi-Task Learning
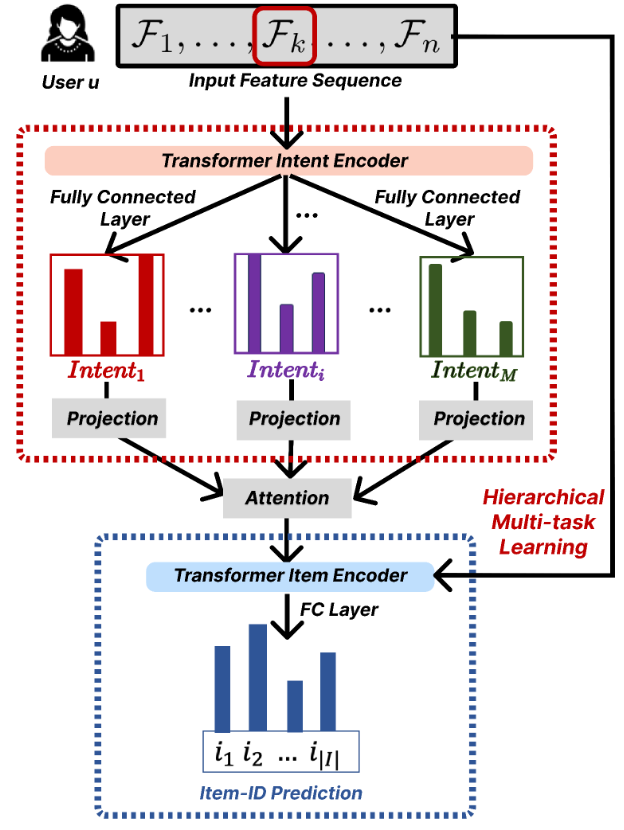
Netflix writes about how Netflix extends its recommendation foundation model with FM-Intent. This hierarchical multi-task learner predicts session-level user intent and feeds it into next-item ranking, delivering a ~7.4% accuracy lift over strong baselines. The blog details a Transformer-based intent module that aggregates multiple intent signals into an embedding used by the next-item predictor, offline validation results, intent-embedding clusters, and downstream applications including personalized UI optimization, search prioritization, analytics, and richer recommendation features.
LinkedIn: Optimizing LinkedIn Sales Navigator’s search pipeline with Spark

LinkedIn writes about how LinkedIn optimized Sales Navigator’s search pipeline by centralizing search-as-a-service and migrating a 100+ job data-manipulation pipeline from MapReduce to Spark, cutting end-to-end runtime from 6–7 hours to ~3 hours for fresher results. The blog details pruning the job graph and attacking critical-path bottlenecks; fixing skew via repartitioning and tuned shuffle partitions; accelerating joins with broadcast joins (for ~≤40 MB tables) and rule-based auto-right-sizing; and selectively parallelizing DataFrame joins with Scala’s .par, emphasizing holistic, system-wide optimization.
Fiverr: Breaking the Lineage with dbt Cloud
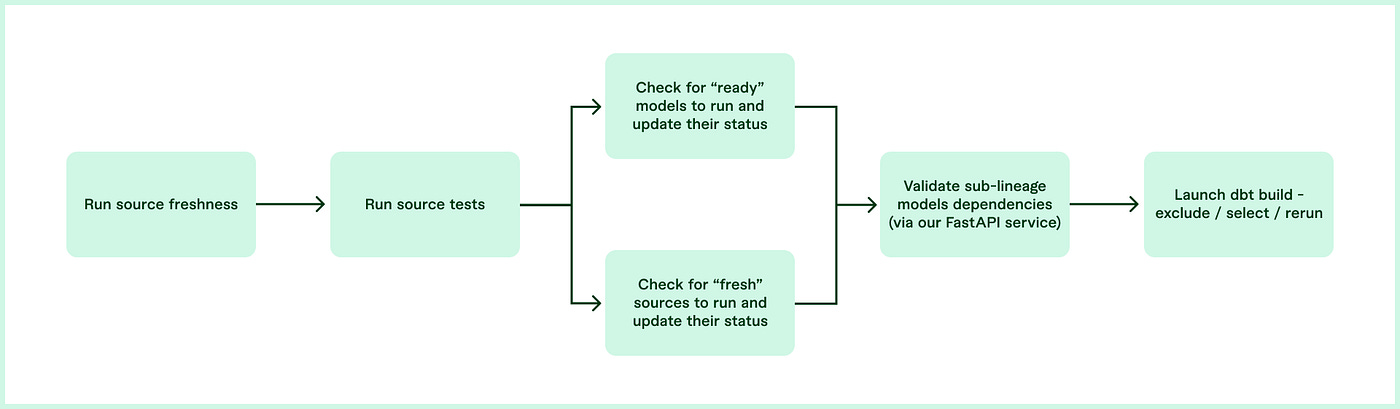
Fiverr writes about how Fiverr breaks monolithic dbt DAG runs into dynamic sub-lineages by layering Prefect over dbt Cloud, using the dbt Discovery API to trigger only “ready” slices of the graph and avoid unnecessary rebuilds.
The blog details a freshness-and-tests gate, on-the-fly-select/--exclude generation, a FastAPI readiness service, and a run-status table to run each branch exactly once, plus guardrails—auto-retries for overlapping DAGs, a PROD/PROD_OFFLINE split, dynamic model tagging, and combined dbt/job-slot queues—for safer parallelism, lower compute, and faster delivery.
https://medium.com/fiverr-engineering/breaking-the-lineage-with-dbt-cloud-bcd8babb16b3
DuckDB: Spatial Joins in DuckDB
DuckDB writes about how DuckDB v1.3.0 makes geospatial joins scale by introducing a dedicated SPATIAL_JOIN operator that builds a temporary R-tree on the smaller input and probes it from the larger side. The blog explains why spatial predicates are expensive, how the old approach cached MBRs and sorted for IE-joins, and why an index-backed operator prunes far more efficiently.
https://duckdb.org/2025/08/08/spatial-joins
Meta: How Meta keeps its AI hardware reliable

Meta writes about how it keeps AI fleets reliable by treating silent data corruption (SDC)—not crashes—as the primary risk to training/inference, citing ~66% of Llama-3 training interruptions from hardware faults and SDC rates near 1 in 1,000 accelerators (e.g., a single miscompute causing missing Spark rows).
https://engineering.fb.com/2025/07/22/data-infrastructure/how-meta-keeps-its-ai-hardware-reliable/
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.