
Data Engineering Weekly #234
The Weekly Data Engineering Newsletter


Join our data team this week for Dagster Running Dagster.
We had a huge response to our last Dagster Running Dagster session, and we’re bringing it back with a focus on event-driven pipelines and real-time observability.
Dagster engineer Nick Roach (with Alex Noonan & Colton Padden) will walk through how we orchestrate millions of daily events with real-time observability using Dagster+.
What you’ll learn:
- Designing reliable streaming workflows
- Integrating Dagster with Kafka & Flink
- Monitoring event-driven pipelines in production
Felicis: Rocket Fuel for AI: Why Reinforcement Learning Is Having Its Moment
The author writes about how reinforcement learning (RL) is emerging as a transformative force in AI, powered by scalable environments and accessible RL-as-a-Service (RLaaS) platforms. The blog details how platforms like Kaizen and Mechanize are simulating real-world workflows for AI training, while services like Applied Compute and Osmosis offer enterprises tools to deploy adaptive agents without deep RL expertise. Together, these innovations signal a shift toward dynamic, continuously learning AI systems with broad implications for enterprise automation and infrastructure.
https://www.felicis.com/insight/reinforcement-learning
Netflix: From Facts & Metrics to Media Machine Learning: Evolving the Data Engineering Function at Netflix
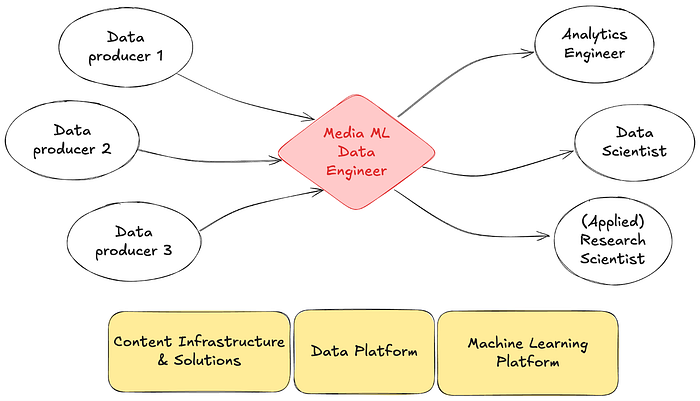
Netflix writes about its evolving data engineering functions in its media production. The use of LanceDB is noticeable. The Netflix case study is a glimpse of the future. We barely brought in unstructured data into the data lakehouse. As with AI advances, we will see Lakehouse mature its capabilities to handle unstructured data.
Etsy: Context engineering case studies: Etsy-specific question answering
Context engineering is the new frontier of data engineering—where pipelines don’t just feed dashboards, but inject precise, traceable knowledge into AI reasoning systems.
Etsy’s case study on context engineering demonstrates how AI pipelines can be repurposed to deliver truthful, source-grounded answers by injecting Etsy-specific knowledge into LLM prompts via embeddings and retrieval. Instead of dashboards, these pipelines power AI assistants that reason with internal policy and community data, showing how data engineering evolves to serve the needs of intelligent systems.
https://www.etsy.com/codeascraft/context-engineering-case-studies-etsy-specific-question-answering
Sponsored: How to Build a Data Platform From Scratch

A comprehensive guide for data platform owners looking to build a stable and scalable data platform, starting with the fundamentals:
- Architecting your Data Platform
- Design Patterns and Tools
- Observability
- Data Quality
The guide also features real-world examples illustrating how different teams have built in-house data platforms for their businesses.
Wilson Lin: Building a web search engine from scratch in two months with 3 billion neural embeddings
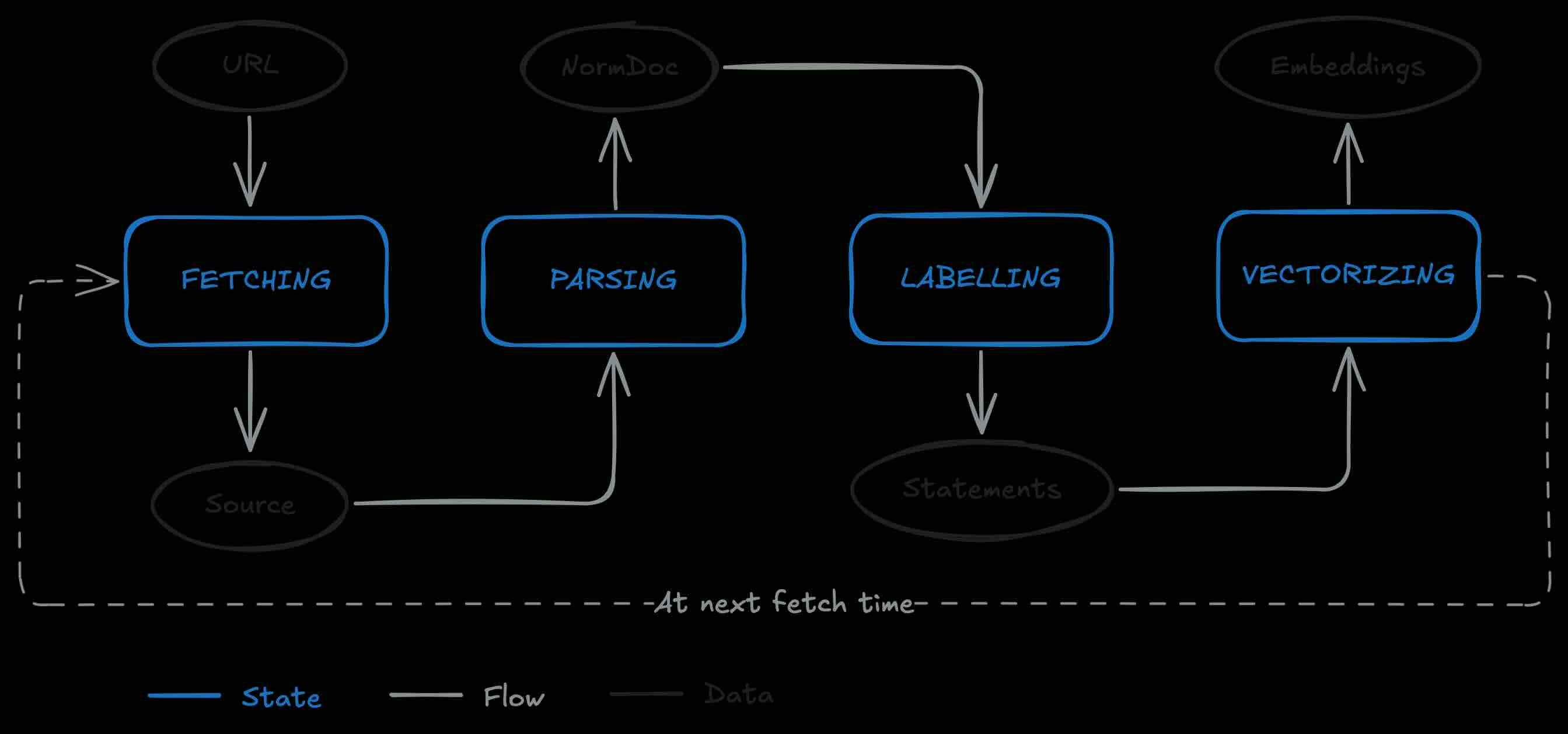
If you had to build a search engine from scratch, how would you design your pipeline? Chunking is, after all, a form of data modeling technique, but for a Large Language Model. The blog narrates the pipeline strategy from fetching the content, parsing, labeling, and vectorizing.
https://blog.wilsonl.in/search-engine/
Grab: Data mesh at Grab part I: Building trust through certification
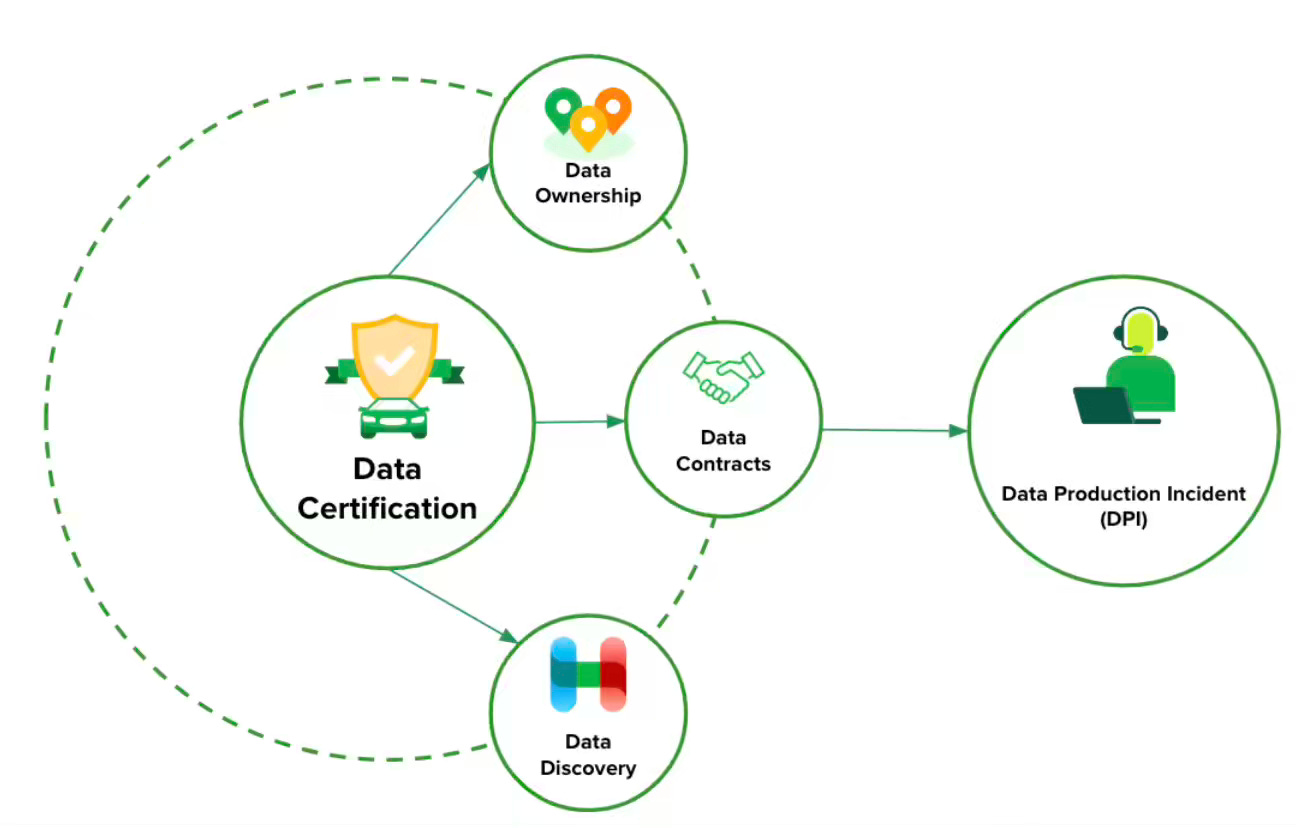
The certified data product is the central part of building trust in data. The certification process enables clear ownership, well-defined expectations from consumers regarding data quality, freshness, and structure. The blog is a good starting point if you intend to start implementing the data mesh principles.
https://engineering.grab.com/signals-market-place
Sponsored: StarRocks Summit 2025 — Sept 10, Free & Virtual

A full day of engineer-to-engineer sessions — real stories, real architectures, and lessons learned the hard way.
Hear how leading companies use StarRocks, the open-source, high-performance analytical database, to:
- Run sub-second queries on petabyte-scale data
- Power real-time, customer-facing analytics
- Simplify complex stacks without sacrificing performance
Spare a few hours to learn what took other teams months to figure out. Whether you’re tuning your current setup or planning what’s next, grab your free pass now.
Grab Your Free Pass Now: https://summit.starrocks.io/2025/DataEngineering
Robin Moffatt: Kafka to Iceberg - Exploring the Options
Data ingestion is hard — Iceberg just makes sure you don’t forget it.
The author explores all the options to ingest data into Iceberg. The fact that it requires a sophisticated data processing engine and no native upsert support still surprises me. A common pattern where a Kafka topic can end up in multiple tables is surprisingly challenging to implement in Iceberg.
https://rmoff.net/2025/08/18/kafka-to-iceberg-exploring-the-options/
Arcesium: Your Data Just Got Swifter — Meet SwiftLake
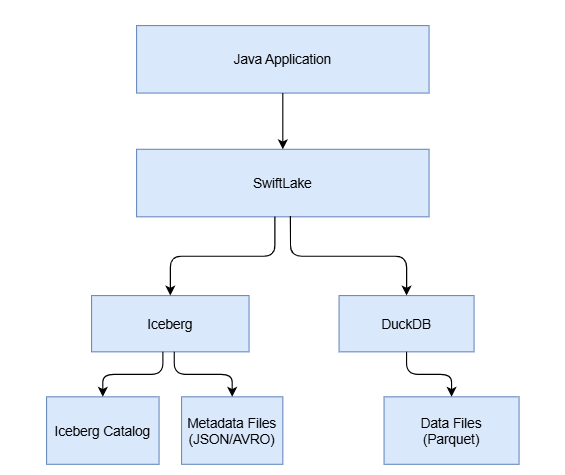
I can see a growing architecture evolution on top of Apache Iceberg, augmenting it with Postgres or DuckDB. SwiftLake augments DuckDB on top of Iceberg. I’ven’t been looking into the design of this system, but I'm looking forward to a deep dive on this one this week.
https://medium.com/arcesium-engineering-blog/your-data-just-got-swifter-meet-swiftlake-7568cc85ee57
Mark Burgess: Why Semantic Spacetime (SST) is the answer to rescue property graphs

I quote this in one of the comments about Data Engineering Weekly featuring more articles around AI. Any technology change will directly impact the way we store and analyse the data. My criticism of the current data modeling techniques is that they focus on addressing the storage and memory limitations of the systems rather than the information architecture. I’ve been following the graph modeling for some time, and the concept of Semantic Spacetime(SST) modeling truly excites me.
Wix: How Wix Slashed Spark Costs by 50% and Migrated 5,000+ Daily Workflows from EMR to EMR on EKS
I wrote a bit about the EMR pricing model in the past. [The Curious Case of EMR Pricing]. To avoid EMR pricing, we are seeing an increased adoption of running data processing workloads on EKS, with solutions like Apache YuniKorn supporting running Yarn on top of EKS. Wix shares its migration strategy and narrates how it helped them to cut the cost by 50%.
Richard Yao: Migrating from EMR on EC2 to EMR on EKS: Gains, Losses, and Lessons Learned
The Wix article sparked my curiosity to explore more migration stories involving EMR on EKS. The author shares the migration and optimization techniques to achieve similar performance of EMR of EC2. The articles also highlight the scheduler differences, noting that the Capacity Scheduler is more tolerant of resource usage compared to the strict resource limitations imposed by the Kubernetes scheduler.
All rights reserved, ProtoGrowth Inc., India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.