
Data Engineering Weekly #235
The Weekly Data Engineering Newsletter


Get the first look at Compass from Dagster.
Dagster Labs has been cooking up something new: Compass, a Slack-native, AI-accelerated, collaborative analytics tool that makes it easier for anyone to gain insights from your data warehouse while allowing data teams to govern and guide their access.
Join Pete Hunt, CEO of Dagster, as he dives into Compass's features, explains how it works, and discusses why we think this tool will transform the dynamics between your data team and stakeholders.
Register now to see Compass in action.
IEEE Spectrum: Why AI Isn’t Ready to Be a Real Coder
Is AI ready to be a real coder? Can it replace data engineering jobs? The manufacturing of code with the coding agents becomes much faster, which leads me to rephrase this famous Starbucks coffee analogy.
The AI Agents are improving their capabilities at a remarkably fast rate. I think the gap here is formal proofing methodologies and a safe sandboxing environment.
https://spectrum.ieee.org/ai-for-coding
Uber: uReview - Scalable, Trustworthy GenAI for Code Review at Uber

AI Coding Agents have proven to be a remarkable companion for developers throughout the software lifecycle. Uber writes about such a case where it built a GenAI for code review. The blog shares insights into the review process and lessons learned while developing the uReview system.
https://www.uber.com/en-IN/blog/ureview/
Atlassion: Comment ranker – An ML-based classifier to improve LLM code review quality using Atlassian’s proprietary data

More case studies on improving code review processing using LLM: Atlassian writes about how an ML-based classifier enhances code review quality. The blog narrates the function of the comment ranker and its adoption success.
https://www.atlassian.com/blog/atlassian-engineering/ml-classifier-improving-quality
Sponsored: The Data Platform Fundamentals Guide

Learn the fundamental concepts to build a data platform in your organization, covering common design patterns for data ingestion and transformation, data modeling strategies, and data quality tips.
Shopify: Building Production-Ready Agentic Systems: Lessons from Shopify Sidekick

Shopify shares its lessons learned building a production-ready agentic system. The blog highlights the limitations of the traditional software evaluation process, which is not well-suited for agentic systems, and emphasizes the need to shift away from the golden dataset model to Ground Truth Sets (GTS) to reflect real-world data better.
https://shopify.engineering/building-production-ready-agentic-systems
Instacart: Simplifying Large-Scale LLM Processing across Instacart with Maple
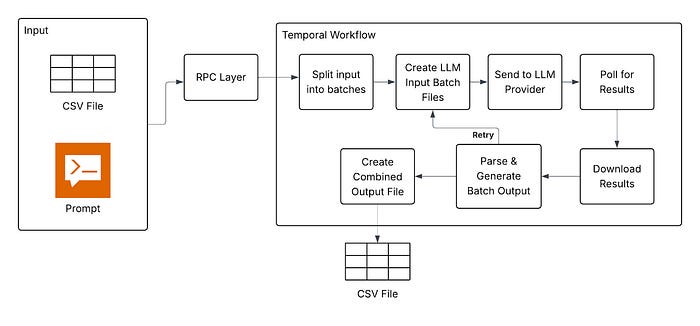
LLM-driven system design is rapidly evolving, and it is initiating a shift in the way we build data pipelines. The case study from Instacart is a classic example of a beginning. Historically, we have tried designing CSV/JSON-based systems, but they bring type safety issues, and we have advocated strongly typed systems such as Protobuf. However, what if LLM can address the type safety issues in CSV/JSON?
Sponsored: StarRocks Summit 2025 — Learn What Actually Works in Production

From 49 clusters cut to one…
From 65s queries down to 6s…
From 10× storage bloat to 90% savings…
These aren’t benchmarks — they’re real production results from teams that switched to StarRocks, the open-source, high-performance analytical database.
On Sept 10, at StarRocks Summit 2025 (free & virtual), hear how data teams across industries went from real pain to real wins — no buzzwords, no sales decks, just engineers sharing what worked in production on real-time customer-facing analytics, the lakehouse, and AI.
👉 Grab your free pass now: https://summit.starrocks.io/2025/DataEngineering
LinkedIn: How we leveraged vLLM to power our GenAI applications at LinkedIn
LinkedIn discusses how it adopted vLLM to power over 50 GenAI use cases, including Hiring Assistant and AI Job Search, by delivering high-throughput, low-latency inference at scale. The blog details LinkedIn’s phased journey—from initial offline deployment to an OpenAI-compatible, modular serving stack—highlighting key optimizations such as prefix caching, asynchronous engines, and GPU utilization tuning, along with its open-source contributions that improved CUDA graph coverage and decoding speed.
https://www.linkedin.com/blog/engineering/ai/how-we-leveraged-vllm-to-power-our-genai-applications
Meta: Meta’s Data Scientists’ Framework for Navigating Product Strategy as Data Leaders
The author writes about how data scientists at Meta serve as product leaders, shaping strategy through a framework that strikes a balance between data availability and problem clarity. The blog details four quadrants—Pioneer, Craftsperson, Explorer, and Optimizer—each requiring different approaches, from first-principles thinking in low-data settings to optimization in high-data, concrete problems, all while collaborating closely with PMs, engineers, and designers to transform insights into strategic execution.
Alibaba: Flink State Management: A Journey from Core Primitives to Next-Generation Incremental Computation
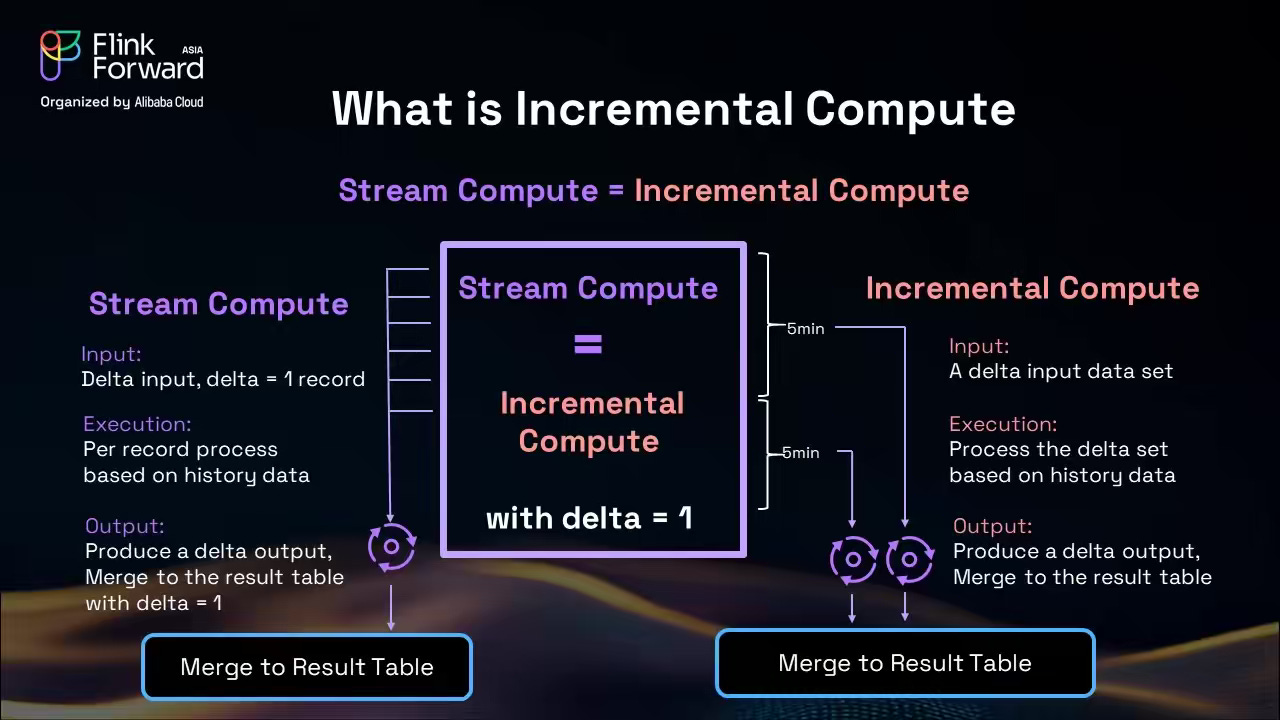
The author writes about how Apache Flink’s state management evolved from embedded local storage in Flink 1.x to the cloud-native, disaggregated ForSt architecture in Flink 2.0. The blog details how this shift enables exactly-once semantics, instant recovery, lightweight checkpointing, and independent scaling of compute and storage, cutting costs while improving performance. Looking forward, it highlights generic incremental computation as the next frontier, unifying batch and stream paradigms to make real-time analytics more efficient and accessible to a broader audience.
Ancestry: How Ancestry optimizes a 100-billion-row Iceberg table
Ancestry writes about how it optimized its 100-billion-row Hints dataset, which processes 7 million hourly updates, by building an Apache Iceberg–based architecture on Amazon S3 with EMR. The blog outlines best practices, including a two-level partitioning strategy, merge-on-read updates, aggressive file compaction, snapshot management, and storage-partitioned joins, which collectively reduce query costs and update overhead. These optimizations cut costs by 75% while enabling scalable, high-performance analytics for diverse teams across Ancestry’s data ecosystem.
https://aws.amazon.com/blogs/big-data/how-ancestry-optimizes-a-100-billion-row-iceberg-table/
Vincent Daniel: Boost Iceberg Performance and Cut Compute Costs with Well-Scoped MERGE Statements
The author writes about how improper use of the WHEN NOT MATCHED BY SOURCE clause in Apache Iceberg MERGE statements can trigger full table scans, driving up runtime and compute costs. The blog explains why partition pruning fails in this case, explores the pitfalls of splitting MERGE and DELETE operations, and demonstrates how well-scoped MERGE statements—targeted at relevant partitions and aided by checksums—can efficiently handle upserts and deletes in a single atomic step. This approach yields faster pipelines, simpler logic, and up to 10x cost savings.
All rights reserved, Dewpeche, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
have you published any links in the past where organizations were using knowledge graphs for enterprise analytics?