
Data Engineering Weekly #236
The Weekly Data Engineering Newsletter


Introducing Compass: Collaborative Analytics in Slack
If you’re on a data team, you know the drill: endless Slack pings, ad-hoc requests, dashboards no one reads. That’s why we built Compass. It’s a Slack-native, AI-driven analytics tool that empowers stakeholders to self-serve insights — while keeping data teams in control.
On Tuesday, September 9th, Dagster Labs CEO Pete Hunt will walk through:
- How Compass works directly in Slack
- How AI accelerates access to insights for non-technical users
- How governance and guidance are built in for data teams
Save your spot
OpenAI: Why language models hallucinate
Hallucination is one of the problems that can hinder or complicate LLM adoption. OpenAI writes about why language models hallucinate in this blog with a reference to the paper. In short, this summarizes the problem pretty well.
Suppose a language model is asked for someone’s birthday, but doesn’t know. If it guesses “September 10,” it has a 1-in-365 chance of being right. Saying “I don’t know” guarantees zero points
https://openai.com/index/why-language-models-hallucinate/
Niall Murphy & Todd Underwood: Unsolved Problems in MLOps
ML systems are inherently non-deterministic and data-driven, which makes classical SRE practices like testing, canarying, alerting, and rollbacks unreliable. The blog highlights unsolved problems in end-to-end quality measurement, multi-model canarying, model/data provenance and versioning, production monitoring, cost-aware load balancing, capacity planning, and defenses against data leakage and prompt injection.
https://queue.acm.org/detail.cfm?id=3762989
Hongtao Yang et al.: Unlocking the Power of CI/CD for Data Pipelines in Distributed Data Warehouses
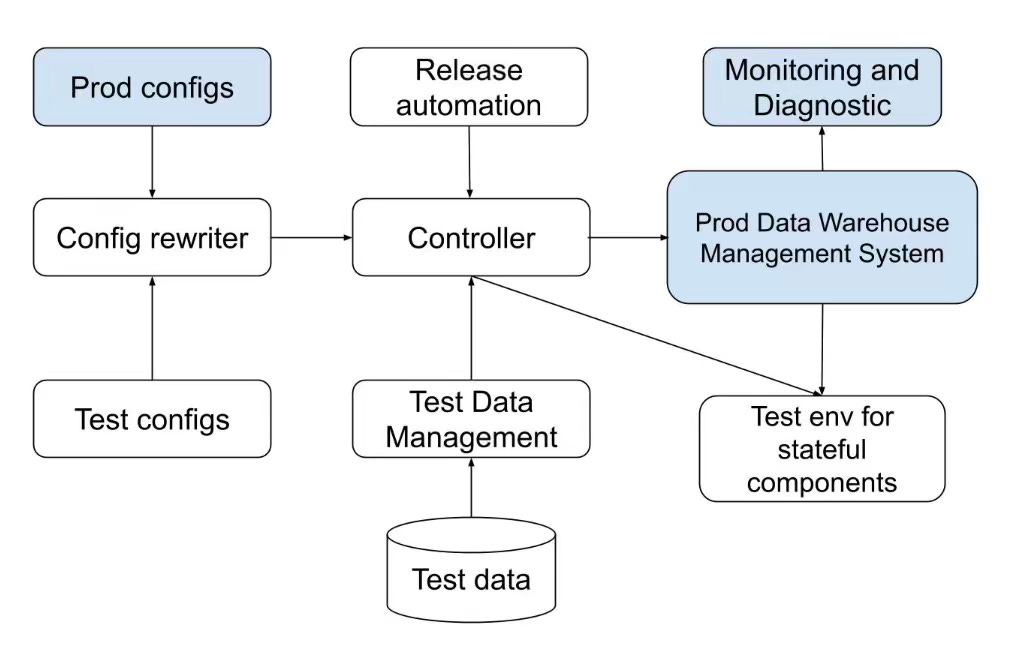
One of the hardest and unsolved problems in data engineering is the CI/CD pipelining for the data pipeline. The paper highlighted why it is particularly challenging, how the data pipeline CI/CD differs from operational systems CI/CD, and the potential solution for it.
https://www.vldb.org/pvldb/vol18/p4887-yang.pdf
Sponsored: Build a Data Platform From Scratch

A comprehensive guide for data platform owners looking to build a stable and scalable data platform, starting with the fundamentals:
- Architecting your Data Platform
- Design Patterns and Tools
- Observability
- Data Quality
The guide also features real-world examples illustrating how different teams have built in-house data platforms for their businesses.
Swiggy: Hermes V3 - Building Swiggy’s Conversational AI Analyst
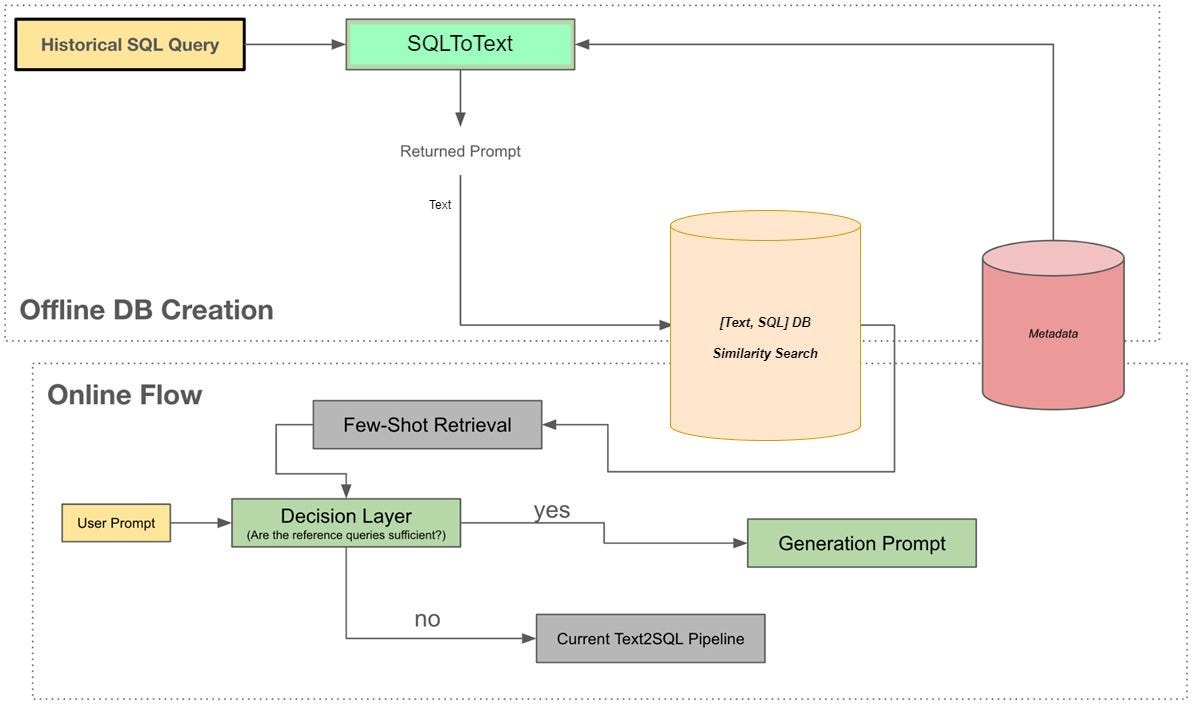
Swiggy writes about how Hermes, their GenAI-powered text-to-SQL assistant, evolved from a simple Slack tool into an agentic, explainable AI analyst. The blog details improvements such as few-shot learning with historical query embeddings, contextual memory for conversational querying, agentic orchestration for complex tasks, an explanation layer for transparency, enhanced metadata handling, and privacy-first Slack integration — boosting accuracy from 54% to 93% and enabling trust at scale.
https://bytes.swiggy.com/hermes-v3-building-swiggys-conversational-ai-analyst-a41057a2279d
Etsy: Building Etsy Buyer Profiles with LLMs
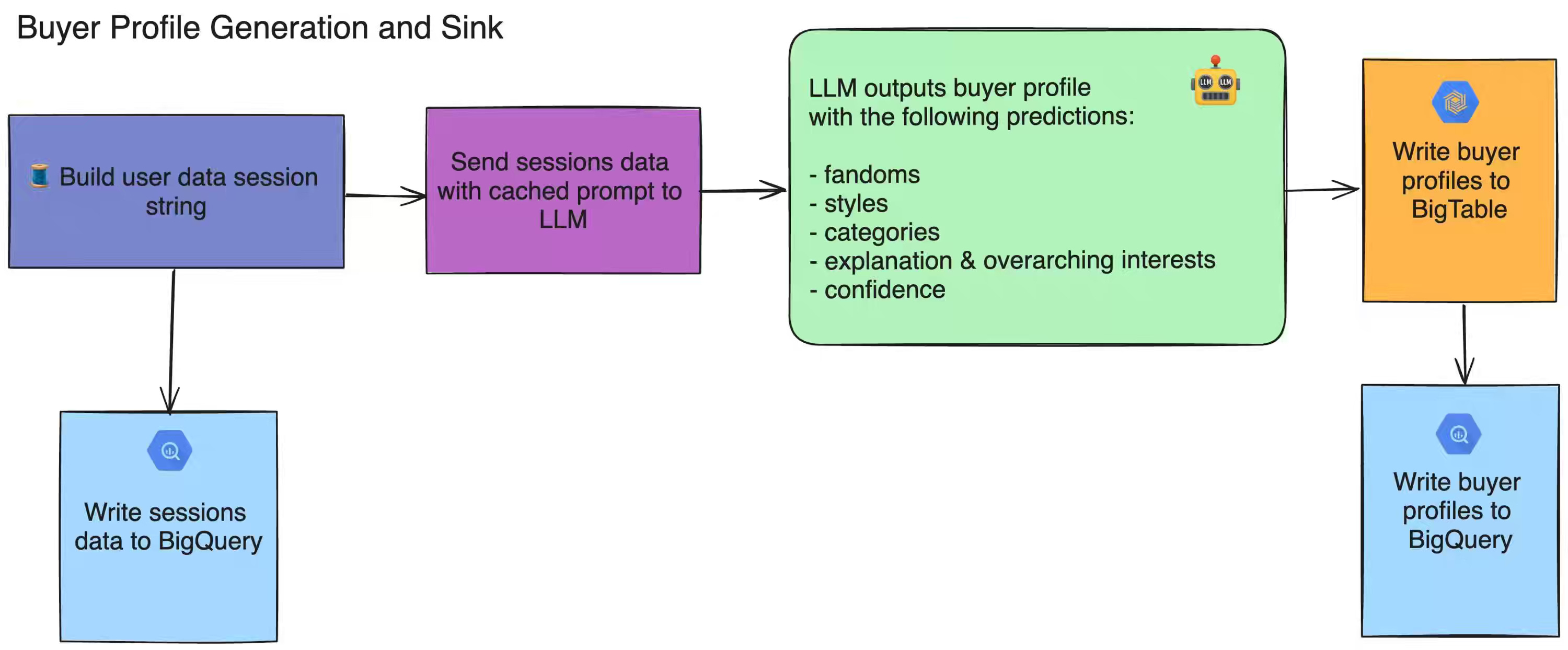
Etsy writes about leveraging LLMs to generate detailed buyer profiles that capture individual styles, interests, and shopping missions, all while respecting privacy laws and opt-outs. The blog details how Etsy rearchitected its pipeline with optimized data retrieval, token reduction, batching, and Airflow orchestration, cutting profile generation time from 21 days to 3 days for 10M users and reducing costs by 94%.
https://www.etsy.com/codeascraft/building-etsy-buyer-profiles-with-llms
Sponsored: StarRocks Summit 2025 — Free Access Ends Soon

Seats are going fast for a full day of engineer-to-engineer sessions (free & virtual) — packed with real stories, proven architectures, and lessons learned the hard way in production. We’ll dive into real-time customer-facing analytics, the lakehouse, and AI.
Join 25+ engineer-led talks from data teams at Coinbase, Intuit, Pinterest, Demandbase, and more — sharing how they use StarRocks, the open-source, high-performance analytical database, to:
- Sub-second queries at petabyte scale, even under high concurrency
- Fewer pipelines, fresher data, faster delivery—without join bottlenecks
- 10× lower storage overhead and major infra cost savings
- Run Apache Iceberg at production scale with warehouse-grade speed
- Fuel the next generation of AI-driven customer experiences
👉 Explore the full agenda — then claim your free pass now: https://summit.starrocks.io/2025/DataEngineering
Jack Vanlightly: Understanding Apache Fluss
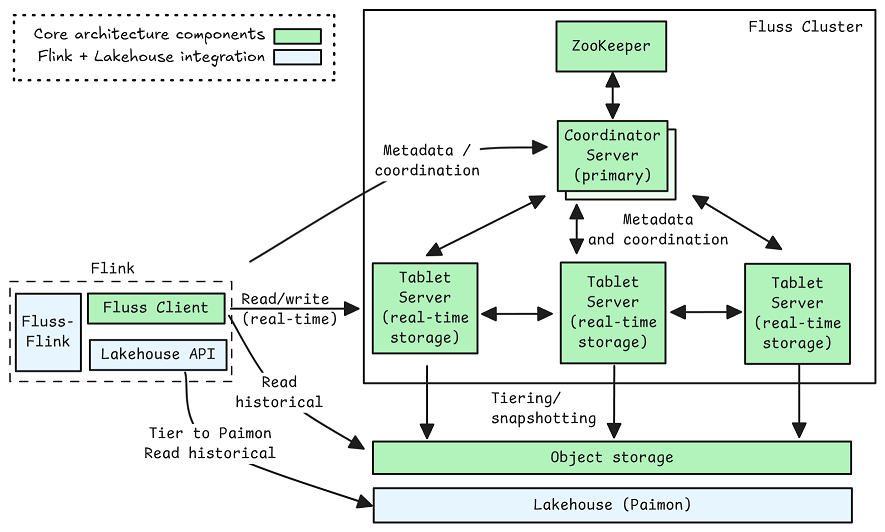
Apache Fluss, a disaggregated table storage engine, combines Kafka-derived log tablets with RocksDB-backed KV tablets to deliver low-latency append-only and primary-key tables with high-fidelity changelogs. We already talked about Apache Fluss here, and the article provides an excellent in-depth view of Apache Fluss.
https://jack-vanlightly.com/blog/2025/9/2/understanding-apache-fluss
Alibaba: Apache Paimon - Real-Time Lake Storage with Iceberg Compatibility 2025

Apache Paimon is another system we don’t talk much about, but it's a promising Lakehouse engine. The blog writes about how Apache Paimon evolves data lake technology with an LSM-tree architecture that delivers real-time ingestion, low-latency updates, and streaming schema evolution at scale.
Fresha: Iceberg MoR the Hard Way: StarRocks Code Dive
The author writes about how StarRocks implements Iceberg Merge-on-Read by applying positional deletes inline via bitmap checks during scans and handling equality deletes through anti-joins driven by the hash-join engine, all while preserving robustness to schema/partition evolution via field IDs. The blog details a frontend-orchestrated, queue-based planner that splits ranges (clean data, data with equality deletes, and delete rows), incremental/async metadata fetching, manifest and position-delete pruning, clear FE/BE separation (FE plans; BE executes bitmaps and joins), dedicated metrics, and tuning knobs for scalable, predictable performance.
https://medium.com/fresha-data-engineering/iceberg-mor-the-hard-way-starrocks-code-dive-fee5e1be66f5
Expedia: Chill Your Data with Iceberg Write Audit Publish

We discussed the importance of implementing the WAP pattern in one of our deep dives into the data quality guide. The blog from Expedia details a step-by-step approach to implementing the WAP pattern with Iceberg.
https://medium.com/expedia-group-tech/chill-your-data-with-iceberg-write-audit-publish-746c9eb3db48
Hugging Face: Parquet Content-Defined Chunking
Hugging Face writes about how Parquet Content-Defined Chunking (CDC) in PyArrow and Pandas, paired with the Hub’s Xet content-addressable storage, deduplicates at the data-page level so uploads/downloads transfer only changed chunks—dramatically cutting time and storage costs. The blog details wins across re-uploads, column adds/removals, type casts, appends/inserts/deletes, different row-group sizes, and varied file splits, and shows simple adoption via use_content_defined_chunking=True in to_parquet/write_table.
https://huggingface.co/blog/parquet-cdc
All rights reserved, Dewpeche, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.