
Data Engineering Weekly #237
The Weekly Data Engineering Newsletter


Platform Engineering with Dagster at Empirico
This Tuesday, Dagster Labs welcomes Empirico's Lead Platform Engineer Zach Romer to walk through the real-world orchestration patterns that enable life sciences companies to scale their data operations efficiently.
You'll see how Empirico's unified orchestration approach transforms cost management from reactive monitoring to proactive optimization, enabling teams to make data-driven decisions about computational resource allocation across complex, multi-platform genomics workflows.
Anthropic: Writing effective tools for agents — with agents
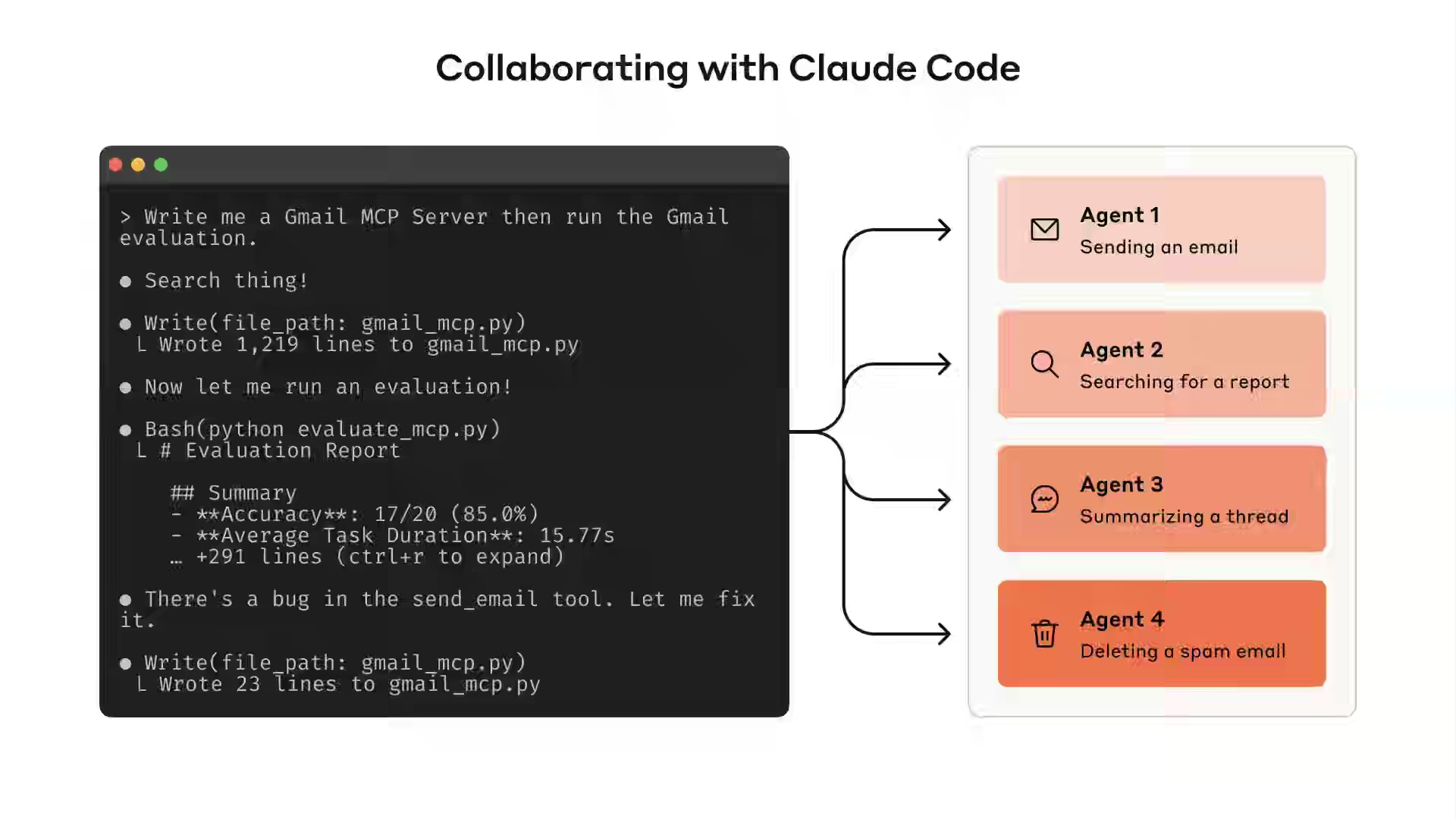
Agents are only as effective as the tools we give them.
Tools are crucial for AI agents as they expand their capabilities to interact with the real world and bridge the gap with deterministic systems. This enables more efficient, guided problem-solving, making the agents significantly more effective and reliable in completing tasks. Antropic writes about the best practices of building tools for agents.
https://www.anthropic.com/engineering/writing-tools-for-agents
Erik Meijer: Guardians of the Agents - Formal verification of AI workflows
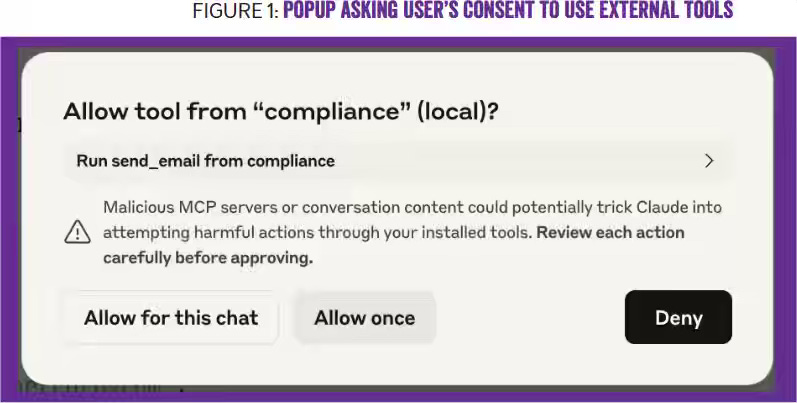
The article highlights the core problem that prompt-injection attacks exploit AI agents because these agents cannot reliably distinguish between executable instructions and the data they are meant to process. The blog emphasizes the cruciality of static verification to proactively prevent these security violations before they can occur, which eliminates the need for complex rollbacks. This automated approach ensures that AI systems generate provably safe plans, providing scalable security without requiring human intervention.
https://queue.acm.org/detail.cfm?id=3762990
LinkedIn: The LinkedIn Generative AI Application Tech Stack - Extending to Build AI Agents
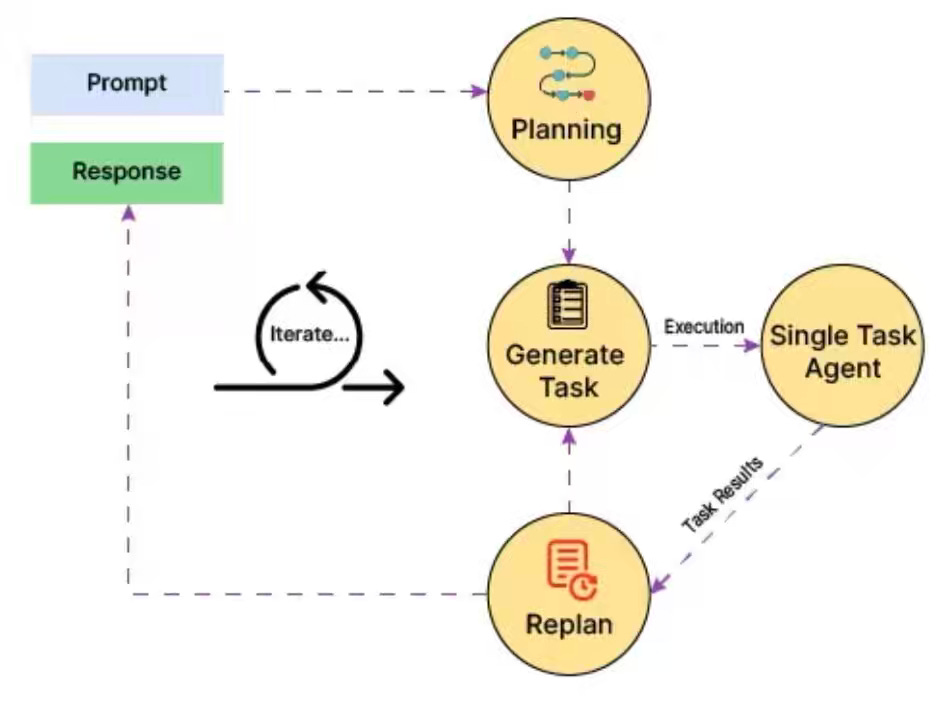
LinkedIn extends its generative AI stack to power multi-agent systems, focusing on modularity, human-in-the-loop controls, and observability. The platform adopts open protocols and developer abstractions to scale adaptive, trustworthy agent experiences. Reusing existing infrastructure, LinkedIn enables agents to reason, plan, and collaborate while preserving security and interoperability.
Sponsored: The Data Platform Fundamentals Guide

Learn the fundamental concepts to build a data platform in your organization.
- Tips and tricks for data modeling and data ingestion patterns
- Explore the benefits of an observation layer across your data pipelines
- Learn the key strategies for ensuring data quality for your organization
Databricks: Databricks on Databricks - Scaling Database Reliability
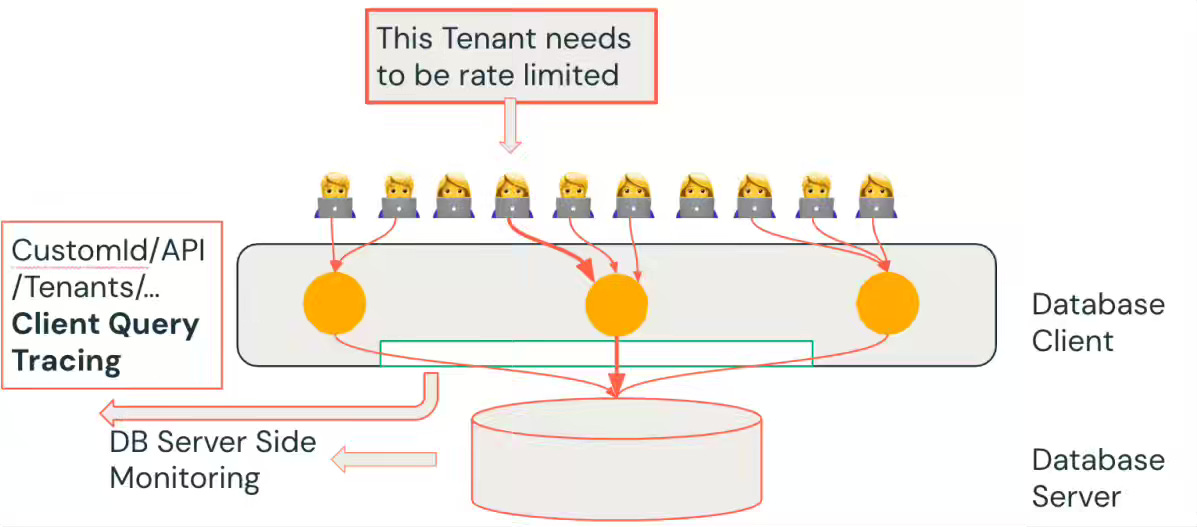
It is always exciting to read about how the tool maker uses the tool. Databricks engineers shifted from reactive firefighting to proactive reliability by embedding a Query/Schema Scorer into CI pipelines and enforcing database best practices before code reaches production. The unified client query tracing, Delta Tables, and DLT pipelines into a Database Usage Scorecard that quantifies efficiency and flags anti-patterns across thousands of databases.
https://www.databricks.com/blog/databricks-databricks-scaling-database-reliability
George Chouliaras: LLm Evaluation Practical Tips at Booking.com
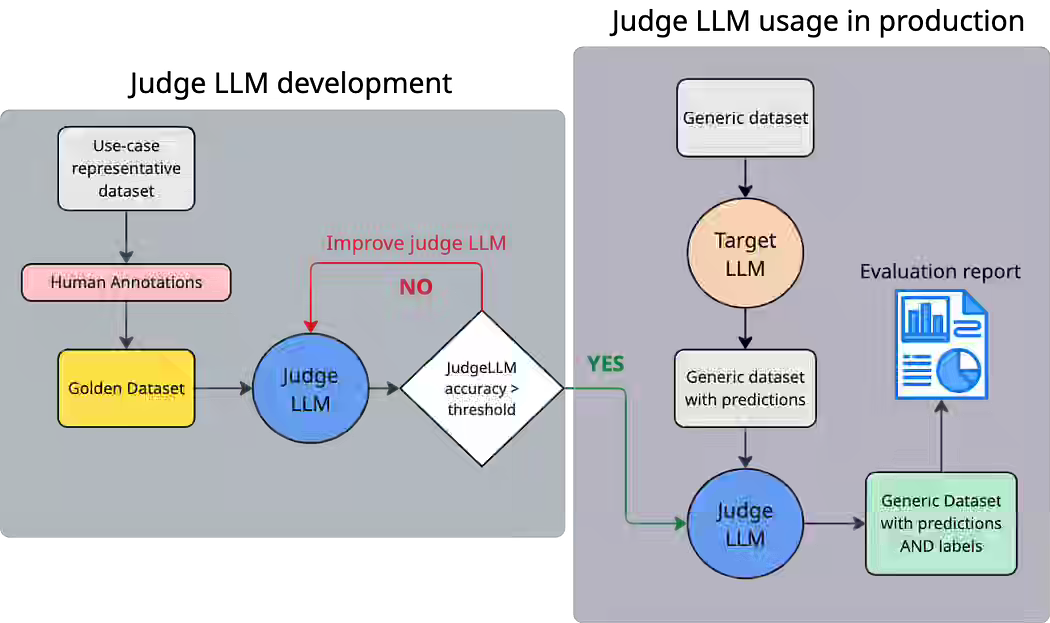
Evaluating LLM-powered applications remains a major challenge since generative outputs often lack ground truth, can hallucinate, and are costly to assess with human reviewers. Booking.com introduces the Judge-LLM framework, which uses a stronger model trained on a rigorously annotated “golden dataset” to replicate human judgment and evaluate target LLMs at scale with structured protocols, prompt engineering, and automated pipelines. This enables continuous, low-cost monitoring of GenAI applications, improves the reliability of evaluation metrics, and sets the foundation for scalable assessment of both models and future LLM-based agents.
https://mlops.community/llm-evaluation-practical-tips-at-booking-com/
Pinterest: Next Gen Data Processing at Massive Scale At Pinterest With Moka
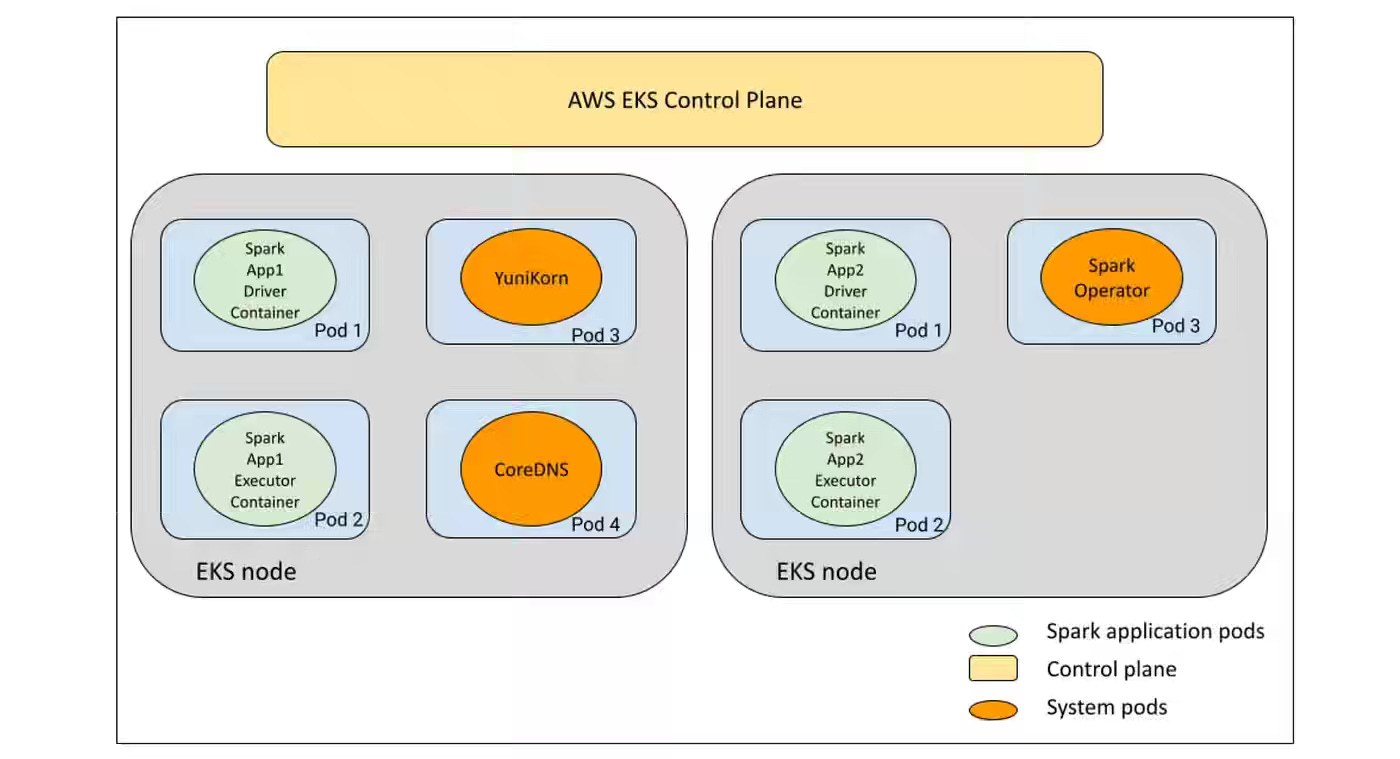
Scaling data processing platforms while retiring legacy Hadoop systems remains a core challenge for enterprises operating at massive scale. Pinterest Engineering introduces Moka, its next-generation Spark-on-EKS platform, with infrastructure advances in Terraform-based cluster deployment, Fluent Bit log aggregation to S3, OTEL-powered observability, multi-architecture image pipelines, and a custom UI to abstract away cluster complexity. The modernization not only streamlines Spark operations but also unlocks broader Kubernetes adoption across data and ML workloads, positioning Pinterest for greater scalability, efficiency, and platform unification.
HuggingFace: Jupyter Agents - training LLMs to reason with notebooks
Training LLMs to handle real-world data science tasks remains difficult, especially as smaller models struggle with reasoning and code execution in complex workflows. Hugging Face researchers present Jupyter Agent, a pipeline that fine-tunes Qwen-3 models using curated Kaggle notebooks, synthetic QA generation, scaffolding, and code execution traces inside Jupyter to improve performance on the DABStep benchmark. This approach shows that even small models can become capable notebook-based agents, achieving significant accuracy gains and opening a path toward scalable, open-source data science assistants.
https://huggingface.co/blog/jupyter-agent-2
MiQ: Building a Natural Language Interface for Apache Pinot with LLM Agents

Business teams often struggle to query complex real-time databases like Apache Pinot without relying on engineers, slowing down decision-making. MiQ built a natural language interface using Google’s Agent Development Kit, where an LLM agent orchestrates tools to translate plain English into SQL, verify and execute queries, and handle follow-ups with conversational memory. This agentic workflow enables faster, error-resilient, and more natural access to campaign performance insights, reducing friction between business users and data systems.
UnSkew Data: Distributed Data Systems - Understanding Join Algorithms
Your query is as good as your joins
Performance tuning in distributed analytics often stalls because teams treat joins as a black box, leading to slow, memory-heavy, and failure-prone workloads. The author explains how architectural choices in Spark and Trino shape join strategy—covering Catalyst/Tungsten and BHJ/SMJ/SHJ in Spark, partitioned vs. broadcast hash joins and CBO in Trino—and provides clear Python implementations (hash, sort-merge, grace/parallel hash) to demystify the trade-offs. The guidance equips engineers to pick the right join for scale, reduce shuffles and spills, and debug bottlenecks with intention rather than guesswork.
https://www.unskewdata.com/blog/join-algorithms
Robert Anderson: The joke of Data Vault generation.
Data teams often debate whether Data Vault modeling is overhyped or overly rigid, given its reputation for jargon, certifications, and repetitive structures. The author argues that the “joke” is not that Data Vault fails, but that its core innovation—separating stable identities (Hubs) from volatile context (Satellites) and relationships (Links)—is simply a disciplined repetition of a pattern as old as relational modeling. This strict uniformity enables scalability, auditability, and agility at enterprise scale, proving that the real power of Data Vault lies in its simplicity and consistency rather than novelty.
https://medium.com/@rdo.anderson/the-joke-of-data-vault-generation-1ef8c170ce55
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.