
Data Engineering Weekly #239
The Weekly Data Engineering Newsletter


The data platform playbook everyone’s using
We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating undering a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Editor’s Note: MLOps World | GenAI summit - 2025
The MLOps World | GenAI Summit will be hosted on October 8-9, featuring over 60 sessions from prominent companies, including OpenAI and HuggingFace, among others. Members can redeem 150$ off tickets. Sessions are the real deal, featuring practical workshops, use cases, food, drink, and parties throughout Austin.
You can join to see more here: DataEngineeringWeekly (150$ OFF)
InfoQ: InfoQ AI, ML, and Data Engineering Trends Report - 2025
InfoQ’s 2025 Trends Report highlights that the center of gravity is shifting toward Physical AI and robust agent ecosystems—powered by multimodal and on-device models, interoperable protocols like MCP/A2A, and AI-driven DevOps. The report promotes vector DBs / MLOps / synthetic data into mainstream use, highlights emerging areas (reasoning models, AI DevOps), and predicts that the near term will favor the agentic co-creation of software, real-time video RAG, and quietly embedded, context-aware AI experiences.
https://www.infoq.com/articles/ai-ml-data-engineering-trends-2025/
StreamNative: Latency Numbers Every Data Streaming Engineer Should Know
One of the informative articles for me this week. Teams misuse “real-time” because they don’t budget for physics: disks, networks, replication, and table commit cadences each add hard milliseconds to minutes of delay. The article classifies latency tiers (<5 ms, 5–100 ms, >100 ms), quantifies common costs (fsync, cross-AZ/region hops, and Iceberg commit intervals), and contrasts synchronous vs. asynchronous paths with tuning levers such as batching, acknowledgments, and polling.
https://streamnative.io/blog/latency-numbers-every-data-streaming-engineer-should-know
Meta: Behind the Numbers: How Meta’s Data Engineers Bring Transparency to Life
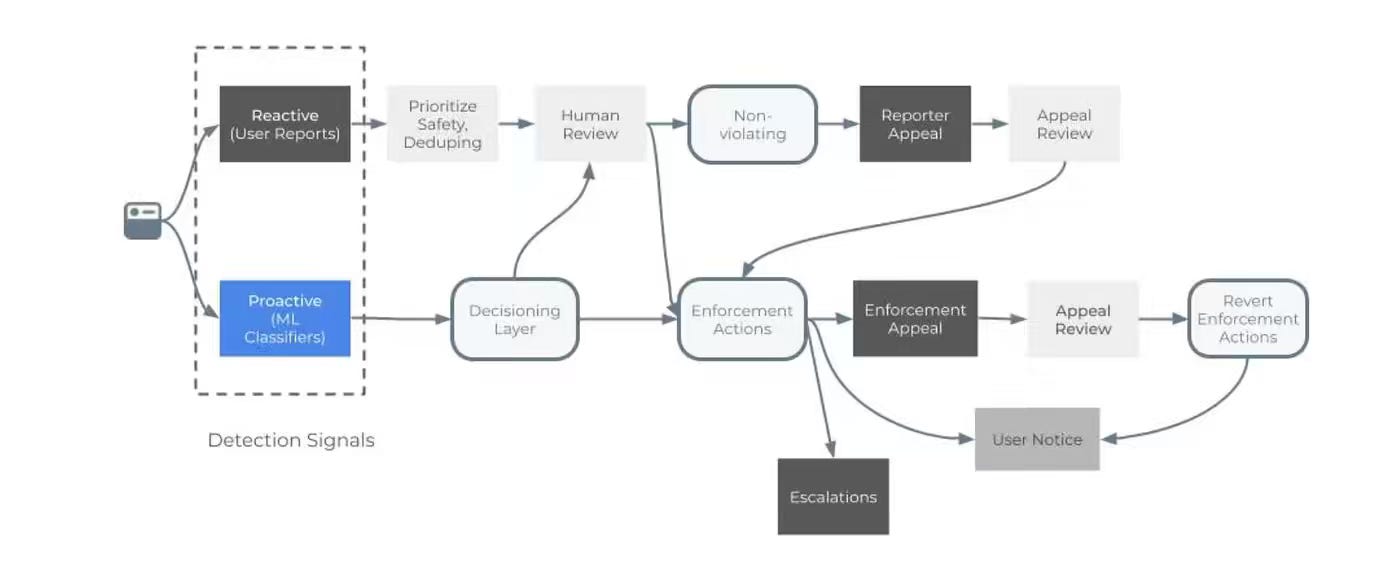
Enterprises face increasing regulatory scrutiny and must transform ambiguous policies into precise, auditable metrics at a massive scale. Meta builds an upstream governance layer, a canonical “Integrity Core Data” model of the enforcement funnel, and snapshot-versioned reporting pipelines with monitoring and re-runs to centralize logging, unify taxonomy, and enforce reportable behavior by design. The design shifts transparency from retrospective reporting to product guardrails, enabling consistent CSER/DSA metrics, faster onboarding of new surfaces, and a roadmap toward automated, self-serve, canonical metrics.
Sponsored: How to build your first Dagster Component

Components takes your Python code and makes it reusable and configurable, opening up a powerful new layer of flexibility. We’re only just getting started with Components at Dagster, and we’re excited to see the creative ways our users will apply them to their data platforms.
If you’re beginning your journey with components, check out these tips to give you a strong foundation.
Netflix: Scaling Muse: How Netflix Powers Data-Driven Creative Insights at Trillion-Row Scale
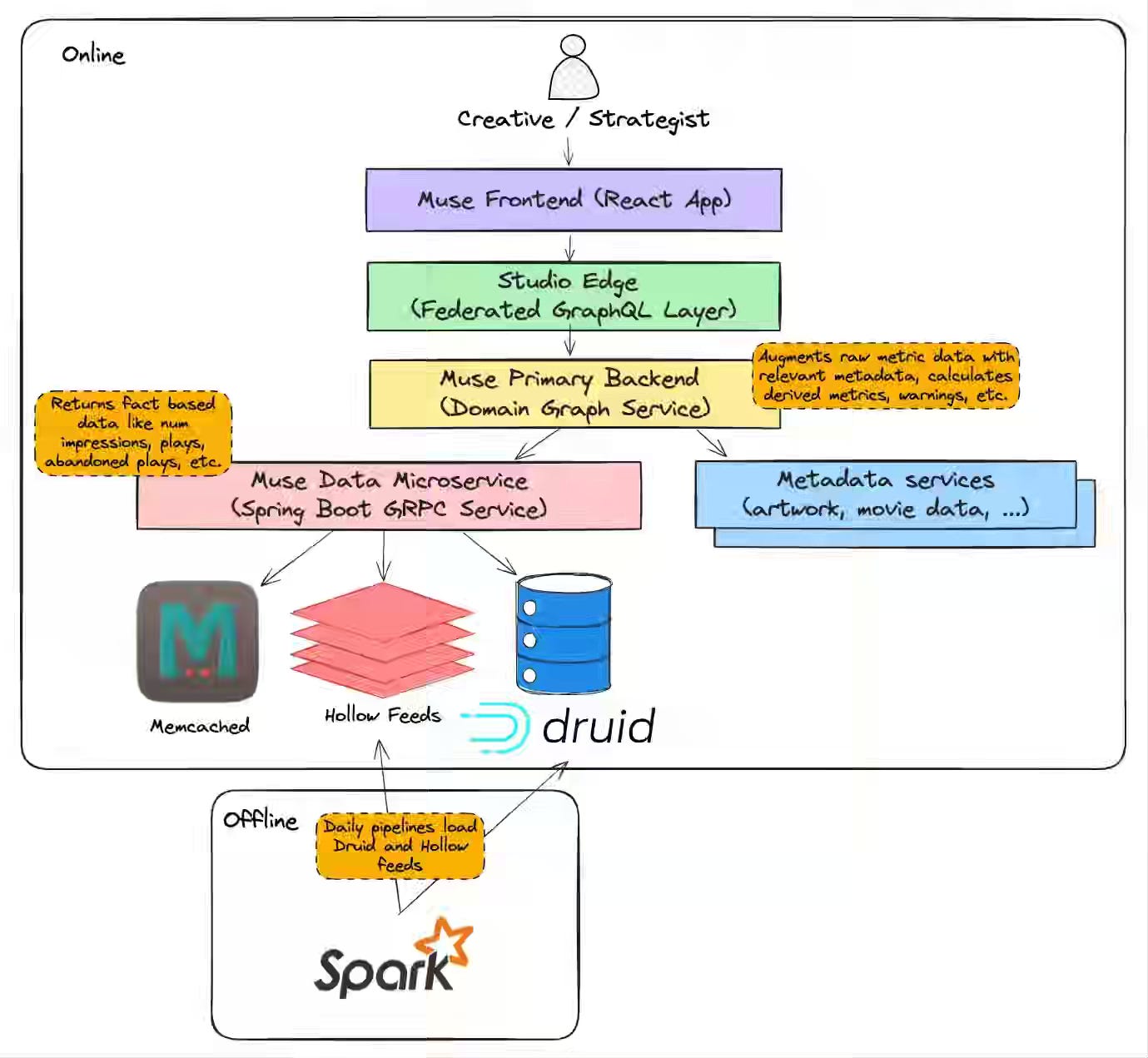
As data volumes grow, analytics applications struggle to balance advanced features, low latency, and accuracy at scale. Netflix writes about evolving its Muse architecture with HyperLogLog sketches for approximate distinct counts, Hollow in-memory feeds for precomputed aggregates, and deep Druid optimizations to cut query latency by ~50% while offloading concurrency pressure.
Uber: Uber’s Strategy to Upgrading 2M+ Spark Jobs
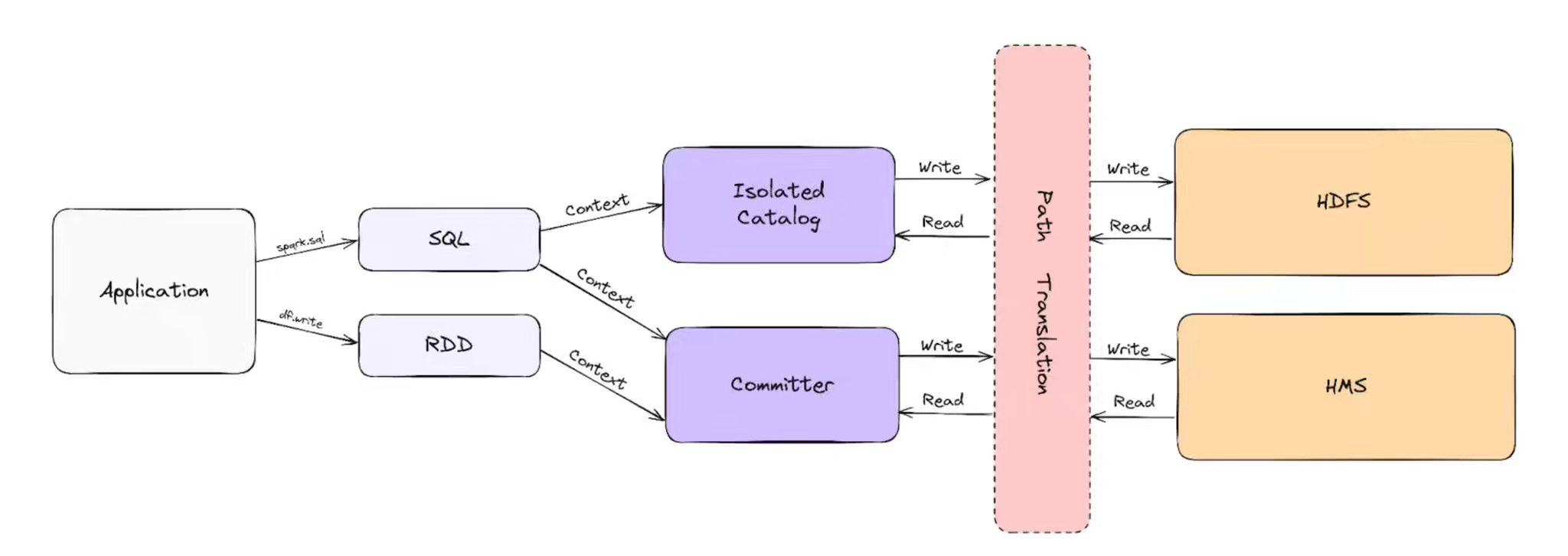
Upgrading large-scale data infrastructure often stalls on dependency complexity, code rewrites, and the risk of breaking production workloads. Uber writes about migrating over 2 million daily Spark jobs from version 2.4 to 3.3 by rebasing its Spark fork, automating code changes with Polyglot Piranha, and validating behavior with a custom shadow testing framework that safely reroutes outputs for comparison. The result of a full migration in six months is impressive, with 50% runtime and resource reductions, millions in cost savings, and reusable automation that now accelerates future upgrades across Uber’s data platform.
https://www.uber.com/en-IN/blog/ubers-strategy-to-upgrading-2m-spark-jobs/
Sponsored: Join the industry’s first survey on data platform migrations.

Most data teams have faced code or logic migrations—rewriting SQL, translating stored procedures, or replatforming ETL workloads—and they’re rarely straightforward. But there’s no clear benchmark for how long these projects take, what they cost, or how teams actually validate success.
Datafold is running a 5-minute survey to collect ground truth from practitioners on timelines, validation, budgets, and how AI is introducing new ways of tackling code translation and validation. Qualified Data Engineering Weekly subscribers (with a valid work email) get a $25 gift card, and all participants receive early access to the results.
Grab: Powering Partner Gateway metrics with Apache Pinot.
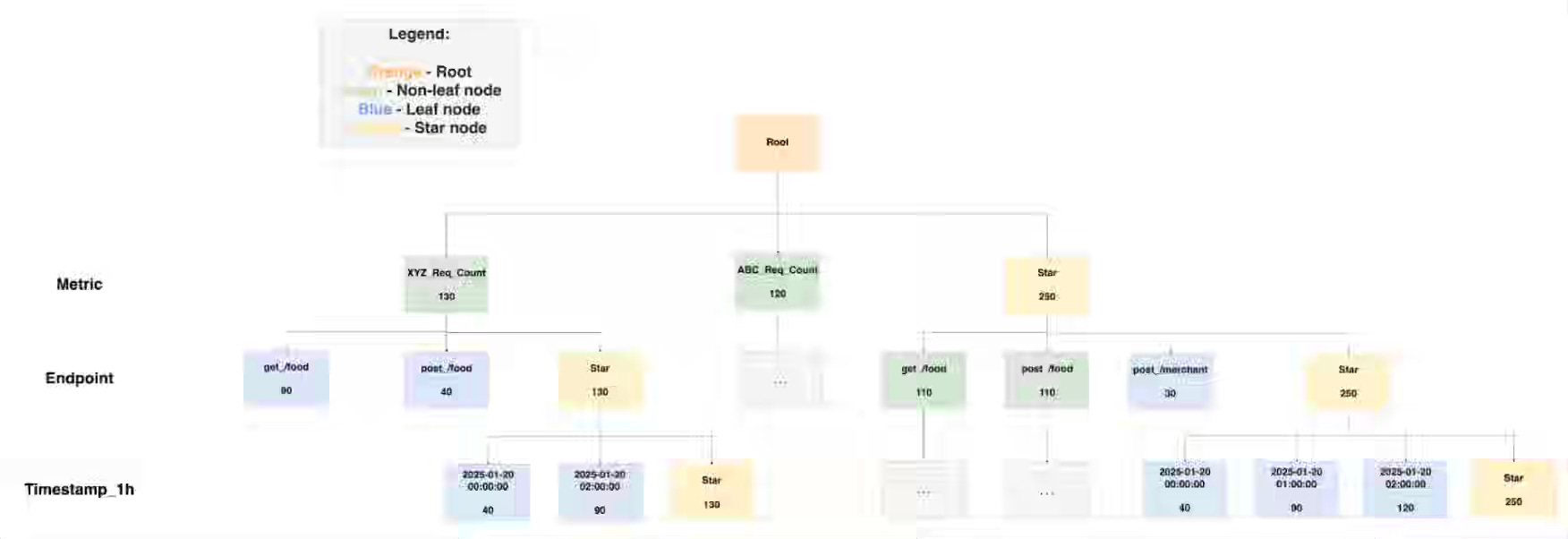
Real-time partner integrations require low-latency analytics at scale; however, large datasets and complex aggregations often exceed query times beyond SLA thresholds. Grab writes about addressing this in its Partner Gateway by adopting Apache Pinot with Kafka–Flink ingestion, partitioning by metric, rounded time columns, and Star-tree indexing to cut query latency from tens of seconds to under 300 ms, even across billions of rows. This design trades modestly higher storage costs for sub-second insights, enabling partners to monitor APIs, resolve issues quickly, and operate with greater efficiency and reliability.
https://engineering.grab.com/pinot-partnergateway-tech-blog
Airbnb: Building a Next-Generation Key-Value Store at Airbnb
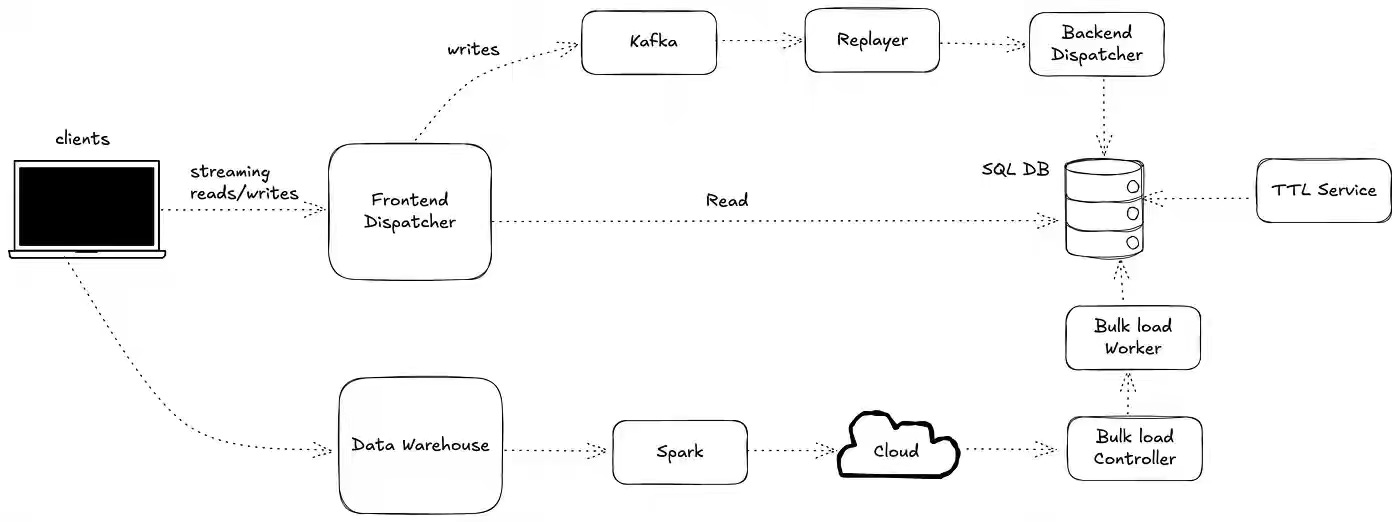
A real-time serving layer with real-time ingestion and bulk upload is critical for feature stores, fraud detection, and other applications. Airbnb writes about building the next-gen key-value store to support both real-time ingestion and bulk upload with sub-second latency serving. The blog details how the previous generation system was unable to adopt the new requirements and how it was optimized with the newer system.
Scribd: Building a Scalable Data Warehouse Backup System with AWS
Backing up petabyte-scale S3 data warehouses is costly and error-prone if every job copies full datasets and deletes files aggressively. Scribe writes about a re-architected backup with a hybrid Lambda/Fargate pipeline that performs incremental copies of only new Parquet files (while always preserving delta logs), validates manifests, and stores results in Glacier. A safe deletion workflow tags stale files for lifecycle cleanup instead of immediate removal, yielding automated, resilient backups that cut costs, shrink runtimes, and scale seamlessly from small to massive datasets.
https://tech.scribd.com/blog/2025/building-scalable-data-warehouse-backup-system.html
Dipankar Mazumdar: Apache Parquet vs. Newer File Formats (BtrBlocks, FastLanes, Lance, Vortex)
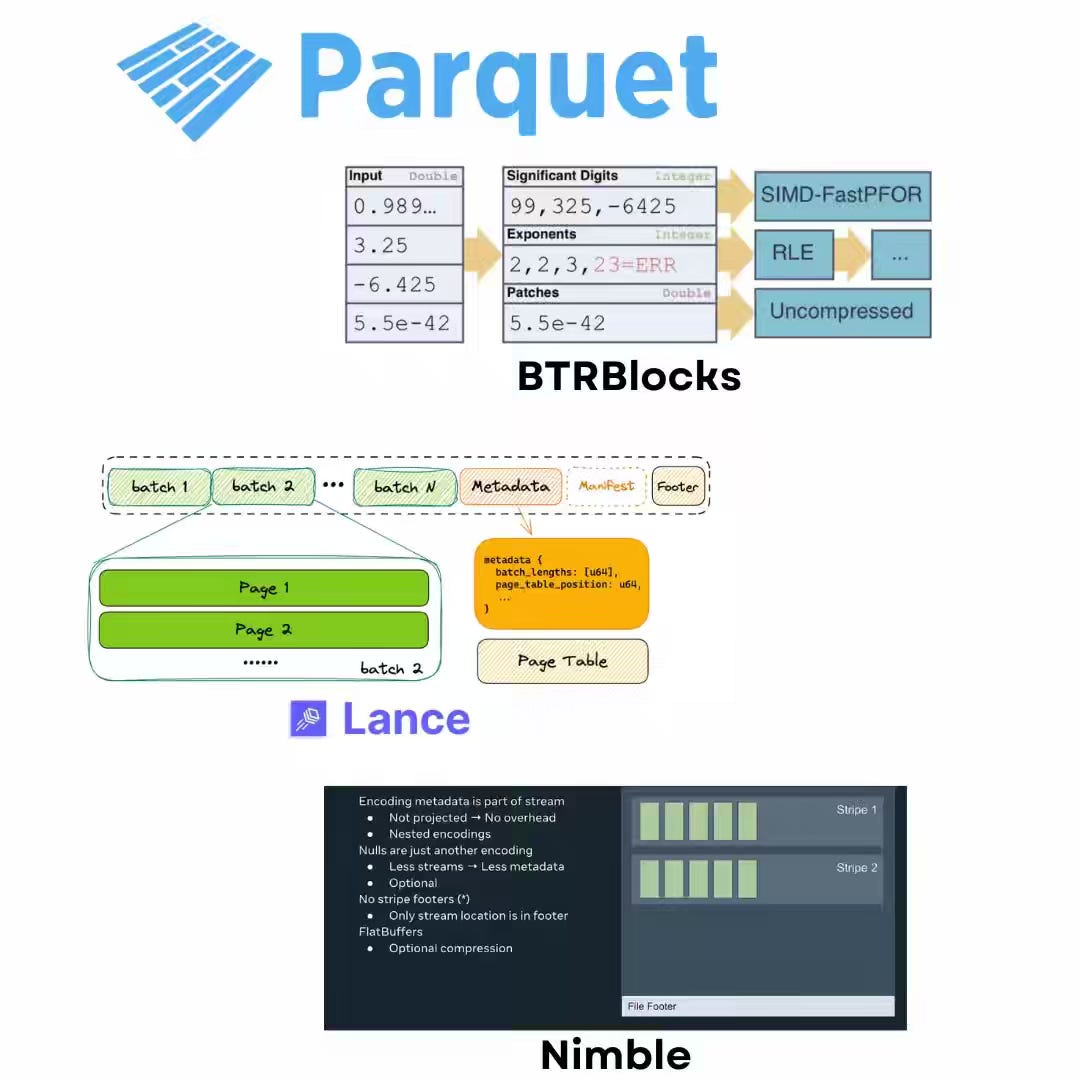
Parquet remains the backbone of data lakes, but its batch-first design struggles with today’s AI and vector search workloads that demand low-latency random access and hardware-aware execution. The author walks through how newer formats are rethinking storage: FastLanes brings SIMD/GPU-friendly lightweight compression chains, Lance optimizes NVMe-backed random lookups, Nimble (from Meta) focuses on ML feature stores with extremely wide schemas, and Vortex extends Arrow with compressed arrays for orders-of-magnitude faster access.
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.