
Data Engineering Weekly #241
The Weekly Data Engineering Newsletter


The data platform playbook everyone’s using
We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating undering a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Netflix: Data as a Product: Applying a Product Mindset to Data at Netflix
Many organizations struggle to extract consistent value from their data because it’s treated as an afterthought rather than a managed asset. Netflix reframes this challenge by applying a product management mindset to data — defining clear purpose, ownership, lifecycle management, usability, and reliability for every dataset, metric, and model. The article demonstrates how the “data as a product” approach builds trust, reduces data debt, and ensures data consistently drives meaningful business outcomes and innovation across the company.
Meta: Introducing OpenZL: An Open Source Format-Aware Compression Framework
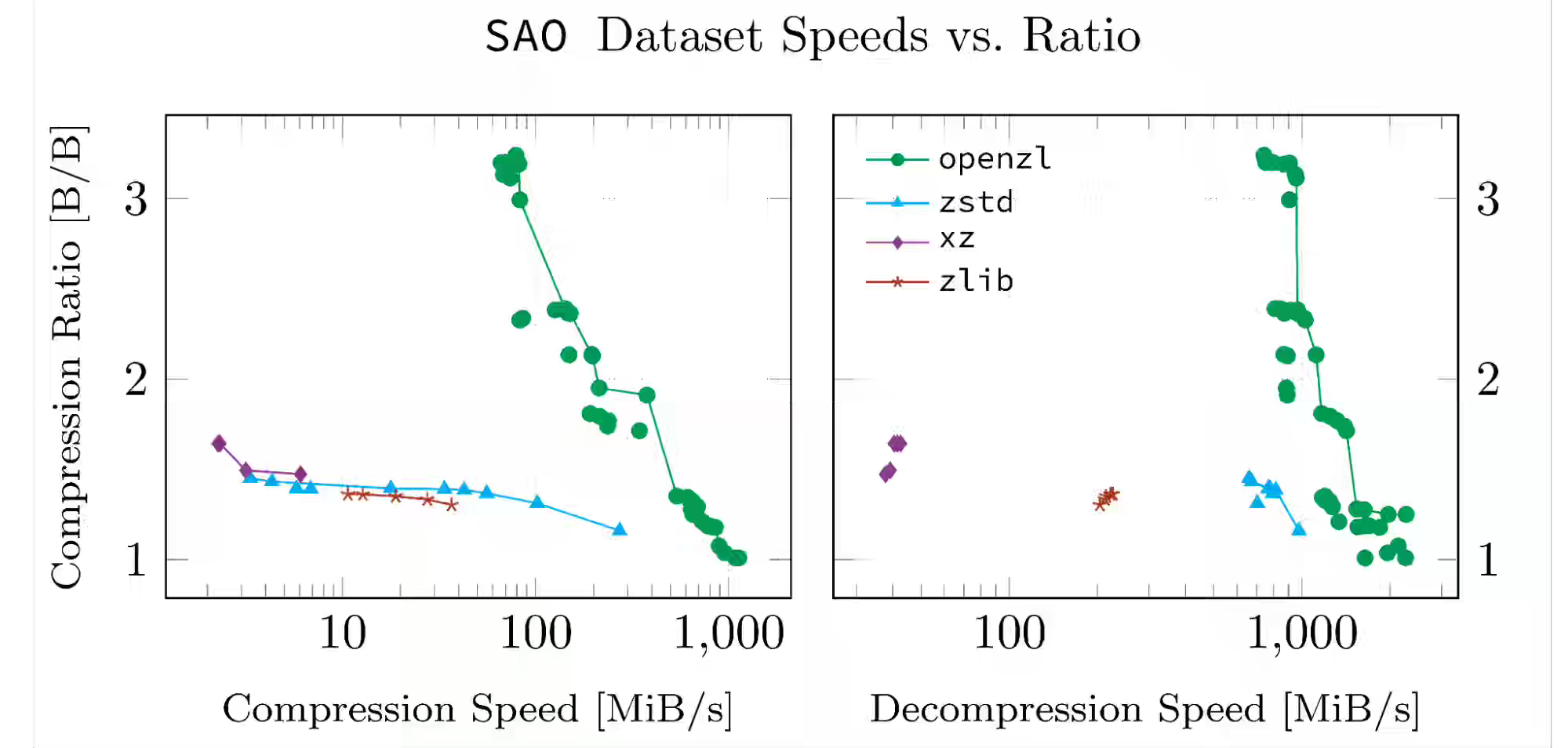
Compression frameworks often struggle to balance the efficiency of format-specific codecs with the simplicity of universal tools. Meta introduces OpenZL, a format-aware, open-source compression framework that learns a data’s structure through configurable transforms and offline training, achieving domain-specific efficiency with a single universal decoder. The benchmark shows the approach delivers higher compression ratios and faster speeds for structured data while maintaining operational simplicity, security, and backward compatibility across evolving datasets.
Jack Vanlightly: Beyond Indexes: How Open Table Formats Optimize Query Performance
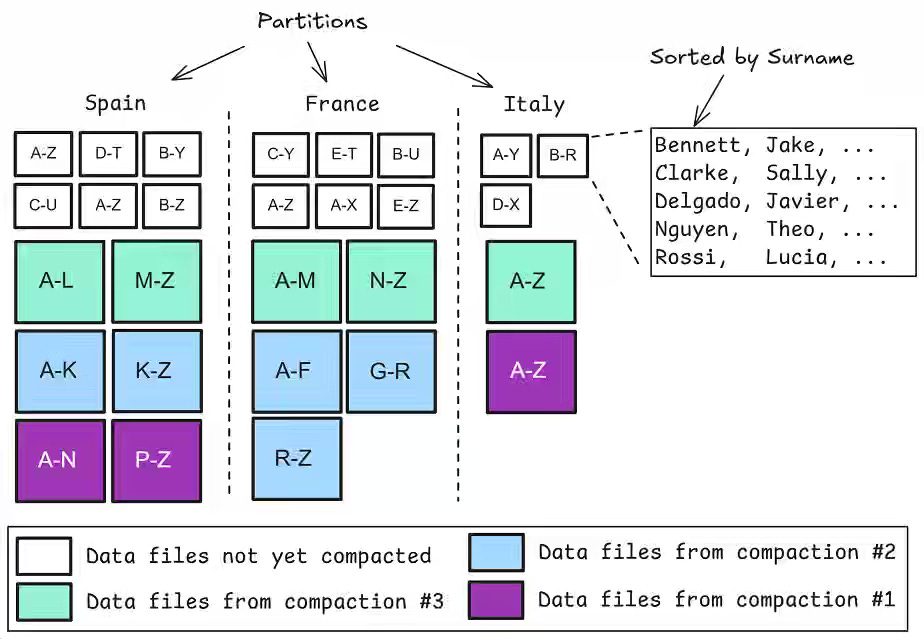
Many teams misapply OLTP “index” thinking to Iceberg/Delta/Hudi and wonder why analytical queries still scan too much data. The article shows that open table formats win performance through layout and pruning—partitioning, sorting, compaction, Parquet row-group stats, Bloom filters, and platform features such as materialized views—rather than through secondary indexes. The author explains by designing tables and models (e.g., star schemas) for data skipping and augmenting with auxiliary structures, teams cut I/O, accelerate scans, and gain a clear path to future gains via richer standardized metadata and disciplined maintenance.
Sponsored: From Chaos to Real-Time Insights for Manufacturing

In this Deep Dive, Supplyco’s CTO Claudia Richoux will reveal how they built a pipeline in Dagster that processes 100,000+ data streams in real time — while ensuring 99.99% uptime. You’ll see their DAG architecture in action, learn how they built observability into every layer, and how they treat “data as code” to ship fast and smart.
Sebastian Raschka: Understanding the 4 Main Approaches to LLM Evaluation (From Scratch)
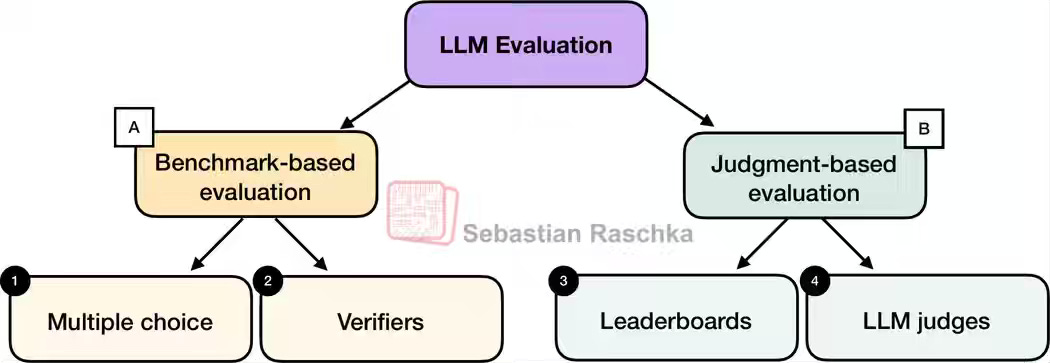
Evaluating large language models remains complex, as no single metric captures reasoning, correctness, and user preference equally well. The author outlines four main approaches: multiple-choice benchmarks like MMLU for knowledge recall; verifiers for objectively scoring free-form outputs in math or code; leaderboards such as LM Arena that rank models by human preferences; and LLM judges that score responses using rubric-based evaluation by another model. Each balances scalability, objectivity, and realism differently, showing that meaningful LLM assessment requires combining complementary methods aligned with real-world use cases.
https://magazine.sebastianraschka.com/p/llm-evaluation-4-approaches
NYT: Scaling Subscriptions at The New York Times with Real-Time Causal Machine Learning
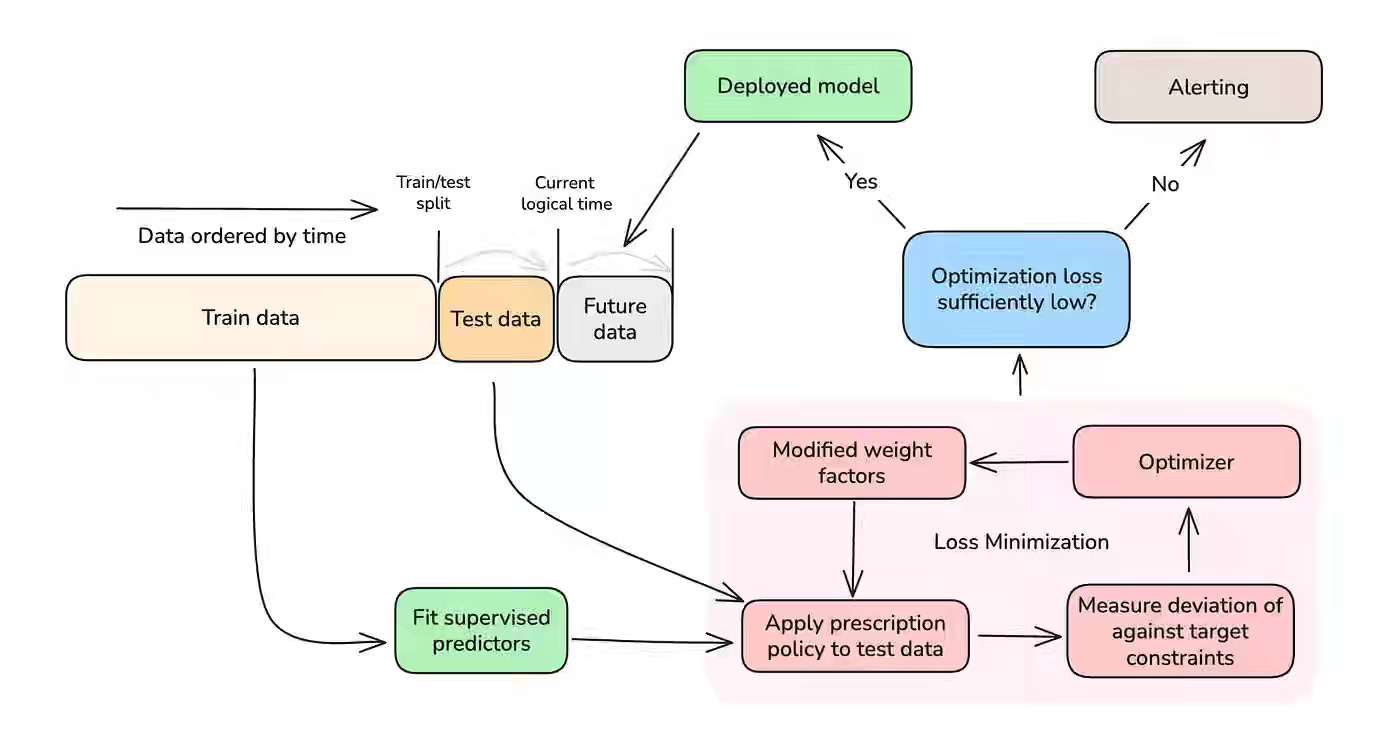
Every subscription-based business struggles to balance engagement, registration, and subscription goals when static paywalls blunt discovery and conversion. The New York Times writes about replacing its batch “Dynamic Meter” with real-time, causal ML: always-on RCTs train S-learner predictors per action (paywall, reg wall, open), a multi-objective optimizer tunes action weights under business constraints (re-tuned daily), and IPW estimates plus A/B tests validate lift. The system makes millisecond decisions that outperform random policies, resulting in raising subscription and registration rates while holding wall-show rates within targets.
Sponsored: 🚀 Data pipelines are breaking. Trust is the new uptime.

At Sifflet Signals 2025: Trust by Design, leaders from dbt Labs, Penguin Random House, and The Fork explore what it takes to build observability that scales - across pipelines, products, and people.
If your org still treats data quality as an afterthought, this is your wake-up call.
👉 Join us Nov 17–20 for 4 days of talks, debates, and demos.
📍 Virtual. Free to attend.
https://www.siffletdata.com/signals-2025
Booking.com: How to estimate correlation between metrics from past A/B tests
Experimentation teams often rely on fast-moving proxy metrics, but naive correlations between proxies (like clicks) and goals (like bookings) can be badly misleading. Booking.com shows that observed experiment correlations mix true causal effects with correlated measurement noise, potentially creating false positives in A/A tests. By applying the Total Covariance Estimator—subtracting the noise covariance from observed effects—they recover the true correlation between metrics, revealing when proxies are directionally misaligned. This bias-corrected approach prevents the shipment of misleading “successful” experiments and underpins a standardized framework for trustworthy metric selection across the company.
https://booking.ai/how-to-estimate-correlation-between-metrics-from-past-a-b-tests-0a5d99e5a11d
Milvus: From Word2Vec to LLM2Vec: How to Choose the Right Embedding Model for RAG
RAG lives or dies by embedding quality: pick the wrong model, and you amplify noise and hallucinations rather than retrieving grounding context. The article maps the landscape—from sparse, dense, and hybrid (BGE-M3) to LLM-based embeddings (LLM2Vec, NV-Embed)—and lays out eight practical selection levers (context window, tokenization, dimensionality, vocabulary, training data, cost, MTEB, domain fit) plus stress tests, then prescribes a workflow: shortlist via MTEB, validate on your data, check database compatibility, and plan for long-document chunking.
https://milvus.io/blog/how-to-choose-the-right-embedding-model-for-rag.md
Shopify: Beyond classification: How AI agents are evolving Shopify’s product taxonomy at scale
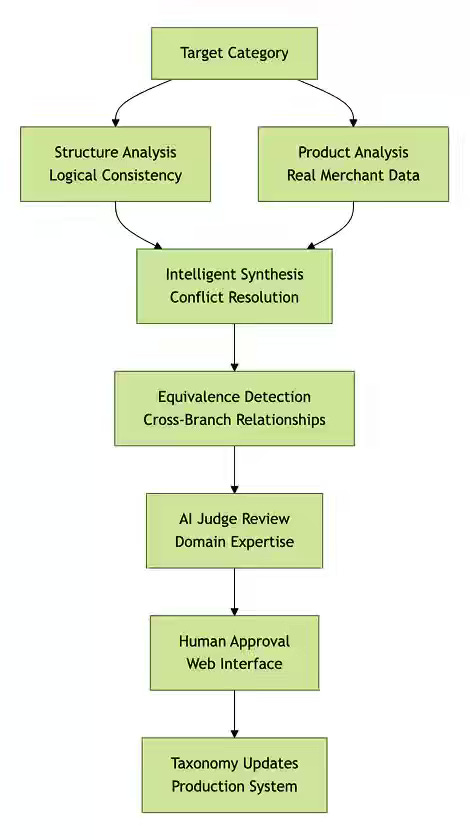
E-commerce taxonomies drift as products, attributes, and naming conventions evolve faster than manual curation can keep up, degrading search, filters, and classifier accuracy at scale. Shopify writes about deploying a multi-agent system that jointly analyzes taxonomy structure and real merchant data, detects equivalences (e.g., category = broader category + attribute filters), and routes proposals through domain-specific AI judges for automated QA before human review.
https://shopify.engineering/product-taxonomy-at-scale
Helpshift: How Data Powers Agent Productivity
Helpshift writes about support agents' productivity by building custom engagement, idle, and anomaly metrics based on real browser interaction events. The blog is a classic example of how instrumentation and measurements go hand in hand. By capturing focus, blur, and ticket activity signals, maintaining state across windows, and computing derived metrics via Spark, the team turned fragmented behavioral data into actionable insights that now power staffing, performance, and operational decisions for customers.
https://medium.com/helpshift-engineering/how-data-powers-agent-productivity-f310f414872d
Agoda: Why We Bet on Rust to Supercharge Feature Store at Agoda
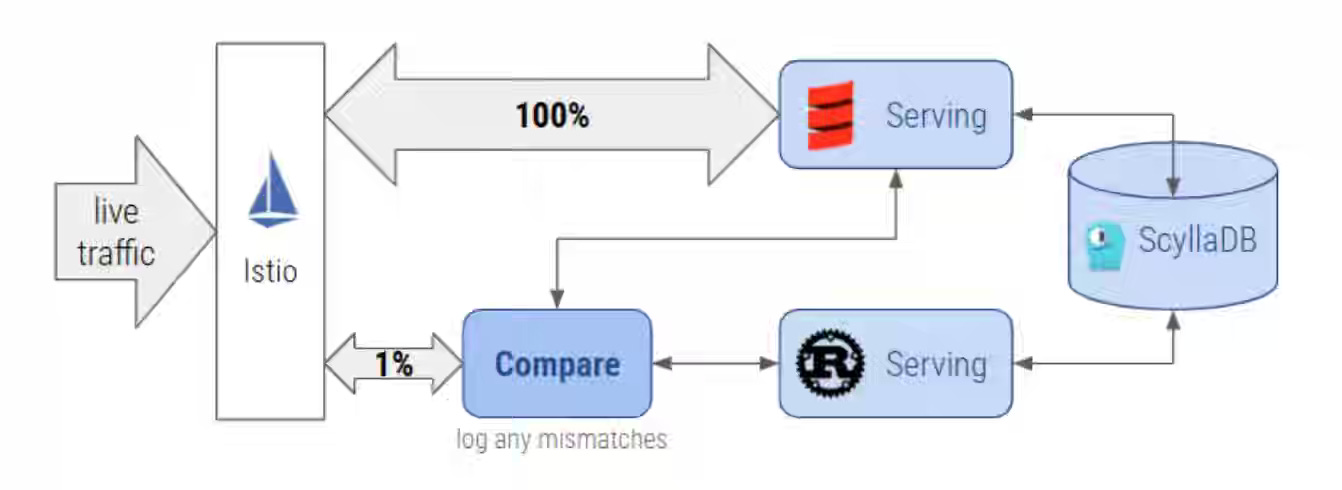
Rust is making a prominent impact on data infrastructure. Agoda writes about rebuilding its feature-serving service in Rust, leveraging the compiler’s safety guarantees, async efficiency, and AI-assisted development to overcome a steep learning curve. The result: 5× higher traffic capacity with only 40% of prior CPU use, 84% lower compute costs, and stable sub-10 ms latencies—proving Rust’s reliability and performance gains far outweigh migration complexity for critical, low-latency systems.
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.