
Data Engineering Weekly #242
The Weekly Data Engineering Newsletter


How Supplyco Powers Real-Time Manufacturing Intelligence with Dagster
In our 10/29 deep dive, Supplyco’s CTO Claudia Richoux will reveal how they built a pipeline in Dagster that processes 100,000+ data streams in real time — while ensuring 99.99% uptime.
You’ll see their DAG architecture in action, learn how they built observability into every layer, and how they treat “data as code” to ship fast and scale smart.
Fast.ai: Let’s Build the GPT Tokenizer: A Complete Guide to Tokenization in LLMs
Tokenization is fundamental to how large language models (LLMs) process text. Efficient tokenization improves training speed, context comprehension, and model performance by balancing granularity (precision) with computational efficiency. The blog is the text version of the GPT tokenization video.
https://www.fast.ai/posts/2025-10-16-karpathy-tokenizers.html
Jack Vanlightly: Why I’m not a fan of zero-copy Apache Kafka-Apache Iceberg
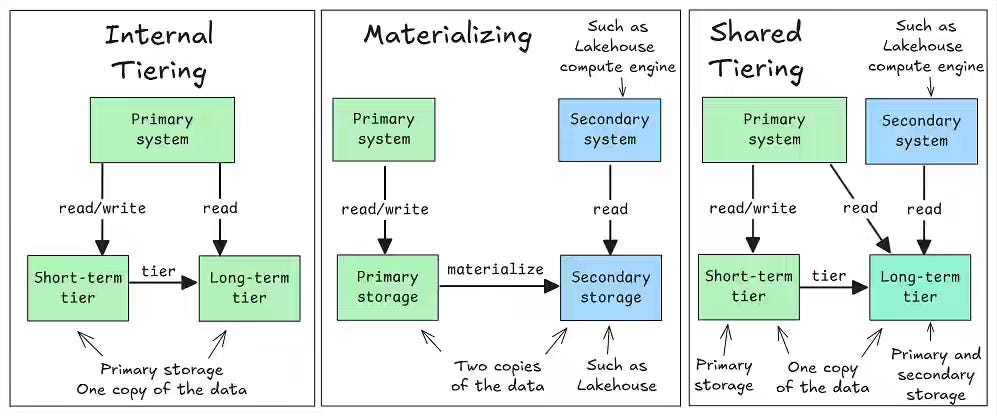
Integrating streaming and analytical systems often tempts engineers to pursue “zero-copy” architectures that promise efficiency by unifying storage layers. The author argues that a zero-copy Kafka–Iceberg design instead introduces heavy compute overhead, schema evolution conflicts, and tight coupling that erodes clear system boundaries. The blog advocates for traditional materialization—maintaining separate but coordinated copies—because it preserves performance isolation, schema flexibility, and operational clarity across Kafka and lakehouse systems.
Netflix: How and Why Netflix Built a Real-Time Distributed Graph: Part 1 — Ingesting and Processing Data Streams at Internet Scale
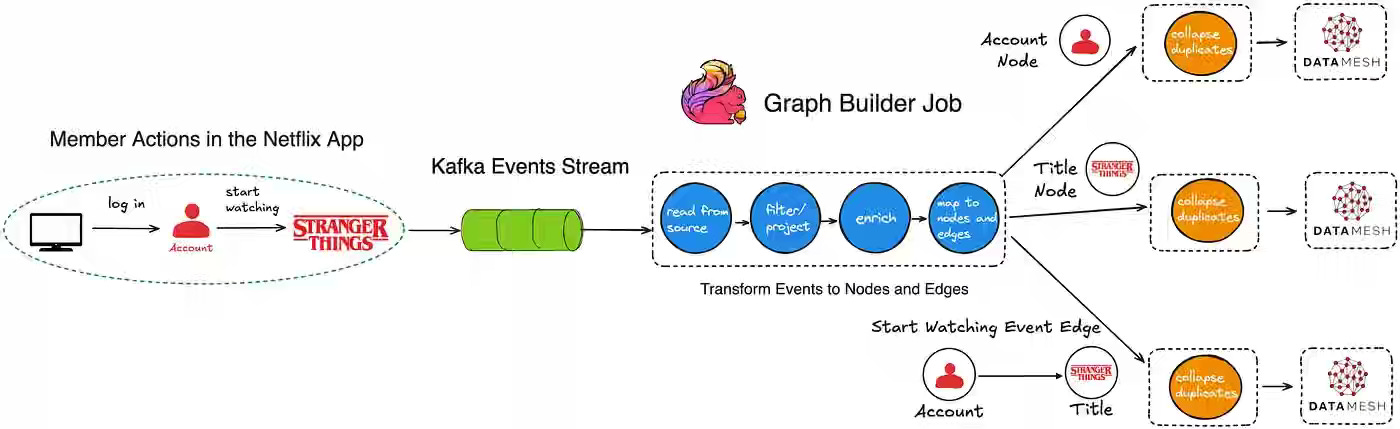
Netflix writes about building a Real-Time Distributed Graph (RDG) to model entities and interactions as connected nodes and edges, enabling instant cross-domain insights. Powered by Kafka for ingestion and Apache Flink for stream processing, the RDG pipeline filters, enriches, deduplicates, and transforms millions of events per second into graph updates—scaling via per-topic Flink jobs that balance throughput, reduce latency, and keep the graph continuously up to date for real-time personalization and analytics.
Sponsored: The data platform playbook everyone’s using

We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating undering a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how to it will help you solve problems more quickly
Milvus: From Word2Vec to LLM2Vec: How to Choose the Right Embedding Model for RAG
Retrieval-Augmented Generation (RAG) systems rely on high-quality embeddings to bridge natural language and vector databases, but choosing the right model is critical for relevance and efficiency. This article traces the evolution from Word2Vec to modern LLM-based embeddings like BGE-M3 and LLM2Vec, outlining key evaluation factors such as context window, dimensionality, domain specificity, and cost. It concludes that while benchmarks like MTEB provide guidance, real-world performance depends on balancing semantic accuracy, compute cost, and system compatibility for grounded, low-latency retrieval.
https://milvus.io/blog/how-to-choose-the-right-embedding-model-for-rag.md
Uber: Rebuilding Uber’s Apache Pinot™ Query Architecture
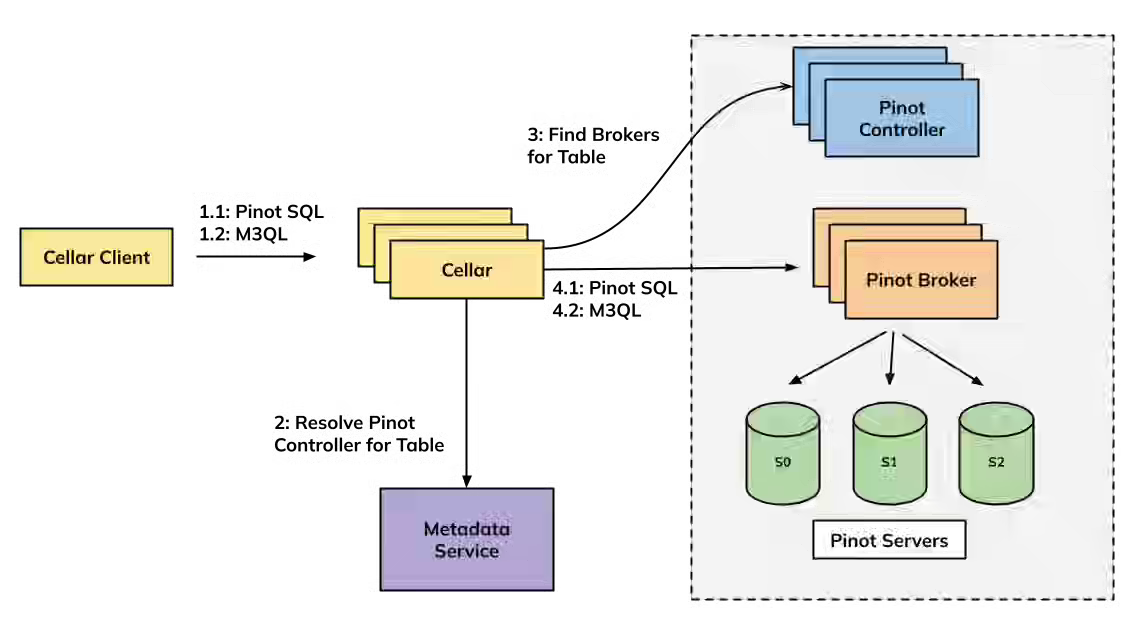
Uber writes about rebuilding this architecture around Pinot’s new Multi-Stage Engine (MSE) Lite Mode and a lightweight passthrough proxy called Cellar, simplifying execution while retaining high performance and flexibility. The new design removes Neutrino’s query proxy layer, enables per-tenant resource isolation, and supports both SQL and time-series queries—reducing latency, improving reliability, and setting the stage for deprecating Neutrino in favor of a unified Pinot-native stack.
https://www.uber.com/en-IN/blog/rebuilding-ubers-apache-pinot-query-architecture/
Sponsored: 🧠 What does “agentic data observability” actually look like in production?

From metadata-driven lineage to AI-assisted root cause analysis, Sifflet Signals 2025: Trust by Design digs into how the next generation of observability tools is changing the way data engineers operate.
Hear from practitioners who’ve scaled trust at Penguin Random House, Saint-Gobain, and Shopify.
🎟️ Reserve your seat now!
📍 Virtual. Free to attend.
https://www.siffletdata.com/signals-2025
LinkedIn: Building the incremental and online training platform at LinkedIn
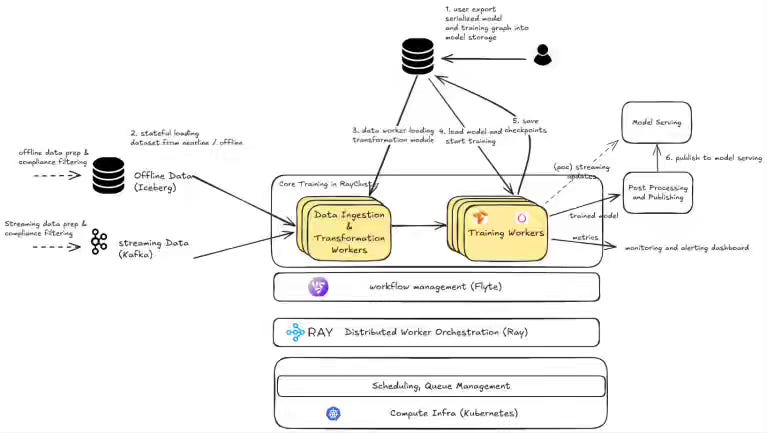
LinkedIn writes about building an incremental/online training platform—nearline feature attribution with Samza/Beam+Flink, Kafka-based streaming ingestion scaled via Ray, static training graphs for TF/PyTorch on Kubernetes orchestrated by Flyte/OpenConnect—to retrain from recent events continuously. The system cuts training cost (up to ~8.9× in benchmarks), boosts freshness to hourly/minute cadences, and drives measurable lifts (>2% Feed interactions, >2% qualified job applications, >4% ads CTR).
Criteo: How RecSys & LLMs Will Converge: Architecture of Hybrid RecoAgents
Modern recommenders optimize KPIs at scale but lack reasoning and transparency, while LLM agents reason and explain but struggle with catalog churn, latency, and performance alignment. The article argues for “Hybrid Reco Agents” that use a RecSys backbone for high-scale retrieval/ranking and an LLM layer for intent parsing, constraint handling, re-ranking, and natural-language explanations—essentially a RAG-style, three-stage loop. This design preserves RecSys performance guarantees while adding conversational trust and control, enabling systems that both move business metrics and justify choices to users.
Fresha: The Good, The Bad, and The AutoMQ
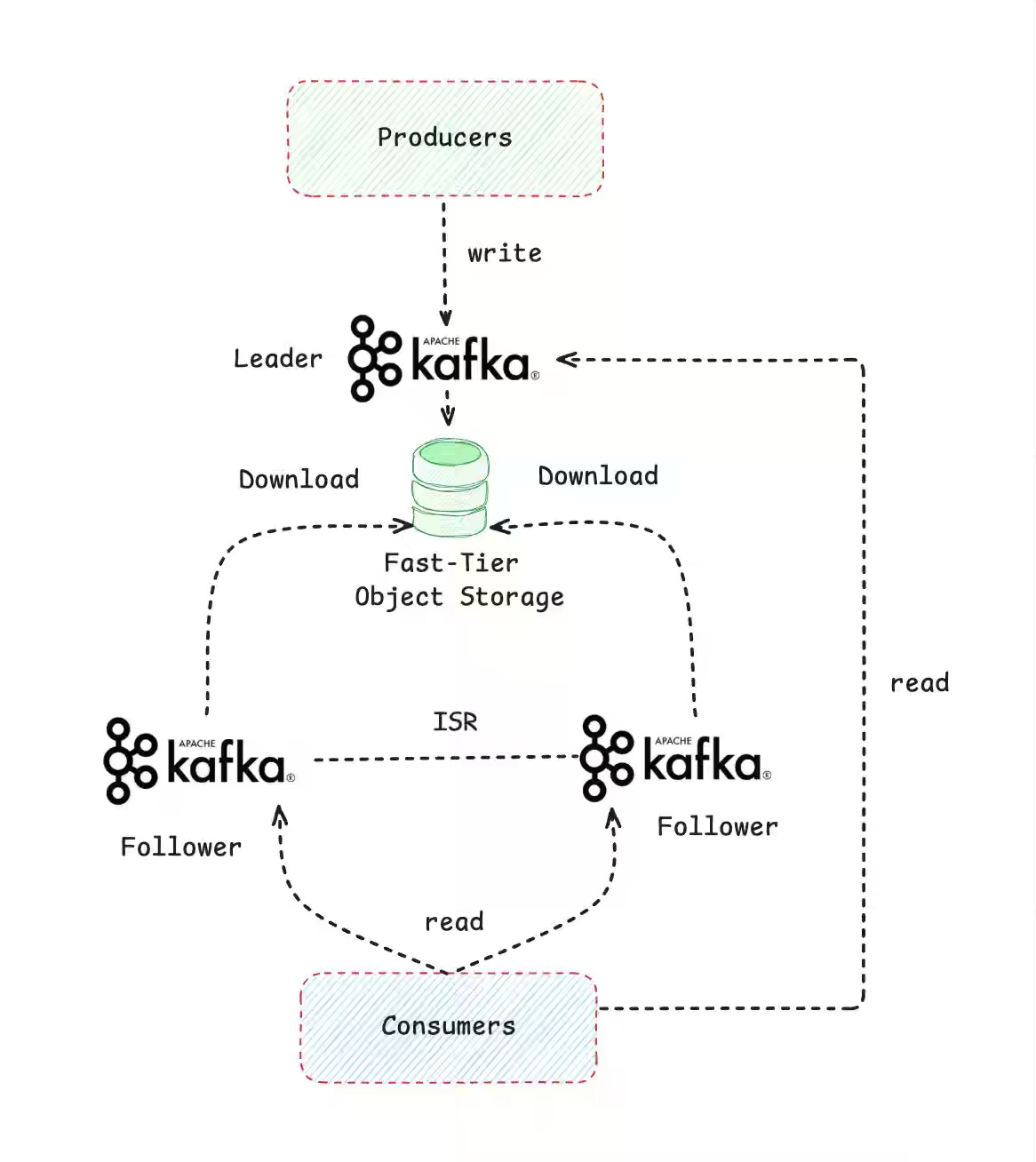
Runaway cross-AZ replication and triple-mirrored disks make classic Kafka expensive to operate in the cloud. The article contrasts three “diskless/shared-storage” paths—KIP-1176 fast-tiering that uploads the active WAL to S3 Express so followers read from object storage, Aiven’s Diskless 2.0 that writes once to a shared WAL and rebuilds ephemeral local caches via Tiered Storage, and AutoMQ’s KIP-1183 that refactors Kafka behind a pluggable shared-storage log engine—highlighting latency, semantics, and operational trade-offs. These designs promise sizable savings (Slack reports ~40%+ egress/cost cuts; Aiven targets up to ~90% lower storage) and elastic operations, but they shift durability to object stores and require cache rebuilds and community alignment before broad, production-safe adoption.
https://medium.com/fresha-data-engineering/the-good-the-bad-and-the-automq-5aa7a8748e71
Pinterest: Tracking Down Mysterious ML Training Stalls
PyTorch upgrades introduced mysterious end-to-end training stalls at Pinterest—>50% throughput loss with periodic stragglers—amid a complex stack spanning Ray, distributed training, and torch.compile. Pinterest writes about the debug process of using Nsight + Linux perf to pinpoint two culprits: a PyTorch dispatch mode (FlopCountMode) that disabled torch.compile for a key transformer block, and Ray’s dashboard agent calling psutil.memory_full_info, which triggered kernel smap_gather_stats every ~2.5–3s and locked page tables across workers.
https://medium.com/@Pinterest_Engineering/tracking-down-mysterious-ml-training-stalls-5290bb19be6d
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.