
Data Engineering Weekly #243
The Weekly Data Engineering Newsletter


How Supplyco Powers Real-Time Manufacturing Intelligence with Dagster
On Tuesday, Supplyco’s CTO Claudia Richoux will reveal how they built a pipeline in Dagster that processes 100,000+ data streams in real time — while ensuring 99.99% uptime.
You’ll see their DAG architecture in action, learn how they built observability into every layer, and how they treat “data as code” to ship fast and scale smart.
Editor’s Note: Re:Govern - The Data & AI Context Summit
Data engineering is evolving, without any clear playbook for the AI era. Yet, some AI-forward data leaders are years ahead by iterating fast and learning even faster.
I’m looking forward to Re:Govern 2025 on November 5, where leaders from Mastercard, GitLab, General Motors, Elastic, and others will share what it really takes to build for this next phase — from investing in new technologies like semantic layers to reimagining new operating models, skills, and roles for the AI era.
Register here. This is one event you don’t want to miss.
Shiyan Xu: Apache Kafka® (Kafka Connect) vs. Apache Flink® vs. Apache Spark™: Choosing the Right Ingestion Framework
The article contrasts Kafka Connect, Flink (incl. Flink CDC), and Spark: Kafka Connect excels at connector-driven CDC and fan-out to sinks, Flink delivers low-latency, stateful stream processing and direct CDC-to-lakehouse writes, and Spark dominates batch/backfills and complex transformations with Structured Streaming for micro-batch use. The takeaway from the author: use Kafka Connect (with Kafka) for broad CDC integrations, Flink for real-time/event-time pipelines, and Spark for batch and heavy transforms—while watching Spark’s idle/scale inefficiencies to control spend.
https://www.onehouse.ai/blog/kafka-connect-vs-flink-vs-spark-choosing-the-right-ingestion-framework
Jack Vanlightly: A Fork in the Road: Deciding Kafka’s Diskless Future
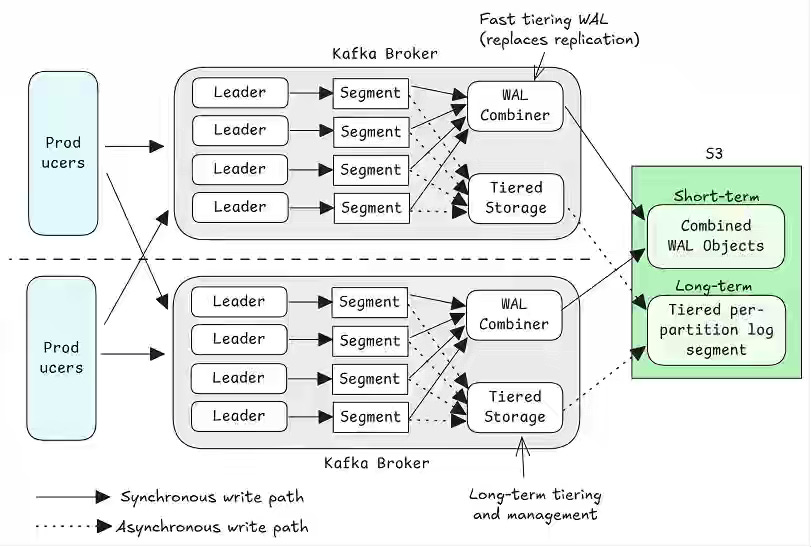
Rising cross-AZ replication costs have pushed the Kafka community to debate a shift toward S3-backed, diskless architectures. The article compares competing KIPs—KIP-1176, Aiven’s Inkless fork, and KIP-1150’s revisions—framing a choice between evolutionary designs that retrofit S3 into Kafka’s leader-follower model and revolutionary designs that rebuild Kafka around stateless, direct-to-S3 brokers. The outcome will define Kafka’s next decade, deciding whether it remains a stateful streaming system or evolves into a cloud-native, elastic platform built on object storage.
https://jack-vanlightly.com/blog/2025/10/22/a-fork-in-the-road-deciding-kafkas-diskless-future
Sponsored: The data platform playbook everyone’s using

We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating undering a single platform. In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Robin Moffatt: flink-watermarks
In stream processing, watermarks play a crucial role in handling out-of-order events and determining when windows can be closed by tracking the progress of event time. The key challenge is striking the right balance between minimizing processing latency and ensuring data completeness—two objectives that are fundamentally at odds. I found the microlearning-style explanation of the watermark to be an excellent way to learn about Flink’s watermark implementation.
Datology: Datology’s distributed pipelines for handling PBs of image data
As AI advances outpace the availability of fresh internet-scale training data, it is critical to rethink how massive datasets are curated rather than expanded. TDatology writes about building a distributed, PB-scale pipeline for deduplication, filtering, and clustering of image-text pairs using custom Spark-based joins, a forked Flyte orchestrator, and a Postgres-backed data catalog to support reproducible, modular research across billions of records.
Sponsored: Trust isn’t a metric. It’s a mindset 💬

That’s the theme of Sifflet Signals 2025: Trust by Design—a four-day digital summit bringing together the people redefining how data teams build reliable systems. No fluff. No vendor-speak. Just real conversations about what works (and what doesn’t) when you scale trust in data.
🎙️ Speakers from dbt Labs, Shopify, Penguin Random House, and more.
📅 Nov 17–21
📍 Virtual. Free to attend.
Register here 👉 https://www.siffletdata.com/signals-2025
DV Engineering: Replaying massive data in a non-production environment using Pekko Streams and Kubernetes Pekko Cluster
Replaying real production traffic at scale is critical for building a testing environment, a challenge I failed multiple times. DV writes about building a Traffic Replay Tool using Pekko Streams to throttle and stabilize replay rates for functional tests and Pekko Cluster to distribute and scale replay workloads for load testing across Kubernetes. By combining backpressure-aware streaming with distributed data replication, DoubleVerify created a consistent, scalable replay framework that mirrors production behavior while safely supporting both performance and integration testing.
Pinterest: Identify User Journeys at Pinterest
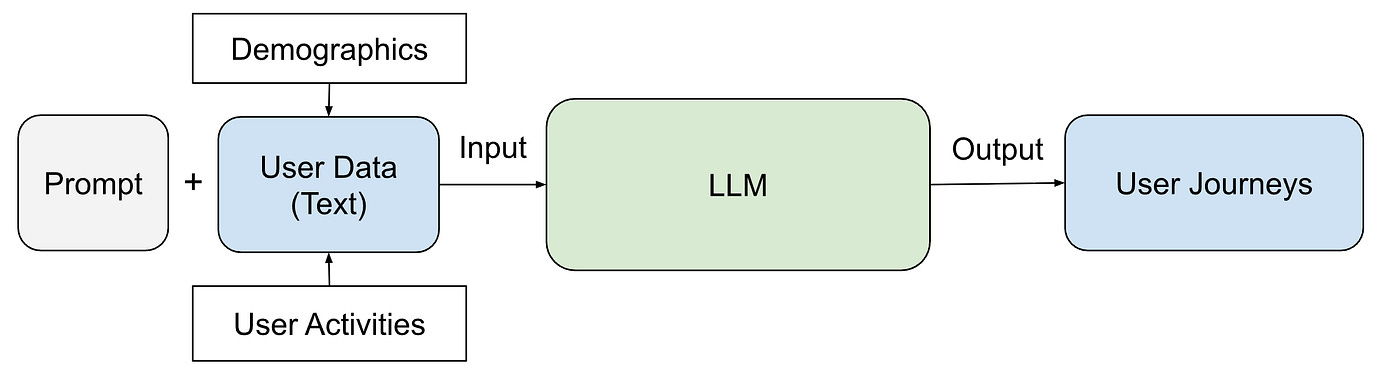
Understanding user intent over time is difficult when recommendation systems focus only on short-term interests. Pinterest writes about building user journeys—clusters of user interactions that capture evolving goals such as “planning a wedding” or “remodeling a kitchen”—using dynamic keyword extraction, clustering, and ranking models, enriched by LLM-based naming and evaluation. This journey-aware system improved click rates by up to 88%, marking a shift from static interest recommendations to long-term, goal-driven personalization.
https://medium.com/pinterest-engineering/identify-user-journeys-at-pinterest-b517f6275b42
Uber: Requirement Adherence: Boosting Data Labeling Quality Using LLMs

Ensuring high-quality labeled data at scale is challenging when quality checks occur only after annotation. Uber writes about building Requirement Adherence, an LLM-powered in-tool validation system in uLabel that extracts labeling rules from client SOPs and enforces them in real time through atomic, parallelized checks. This framework reduced post-labeling audits by 80%, improving turnaround time, cost efficiency, and data quality while setting a foundation for adaptive, feedback-driven prompt optimization.
https://www.uber.com/en-IN/blog/requirement-adherence-boosting-data-labeling-quality-using-llms/
Meta: Scaling Privacy Infrastructure for GenAI Product Innovation
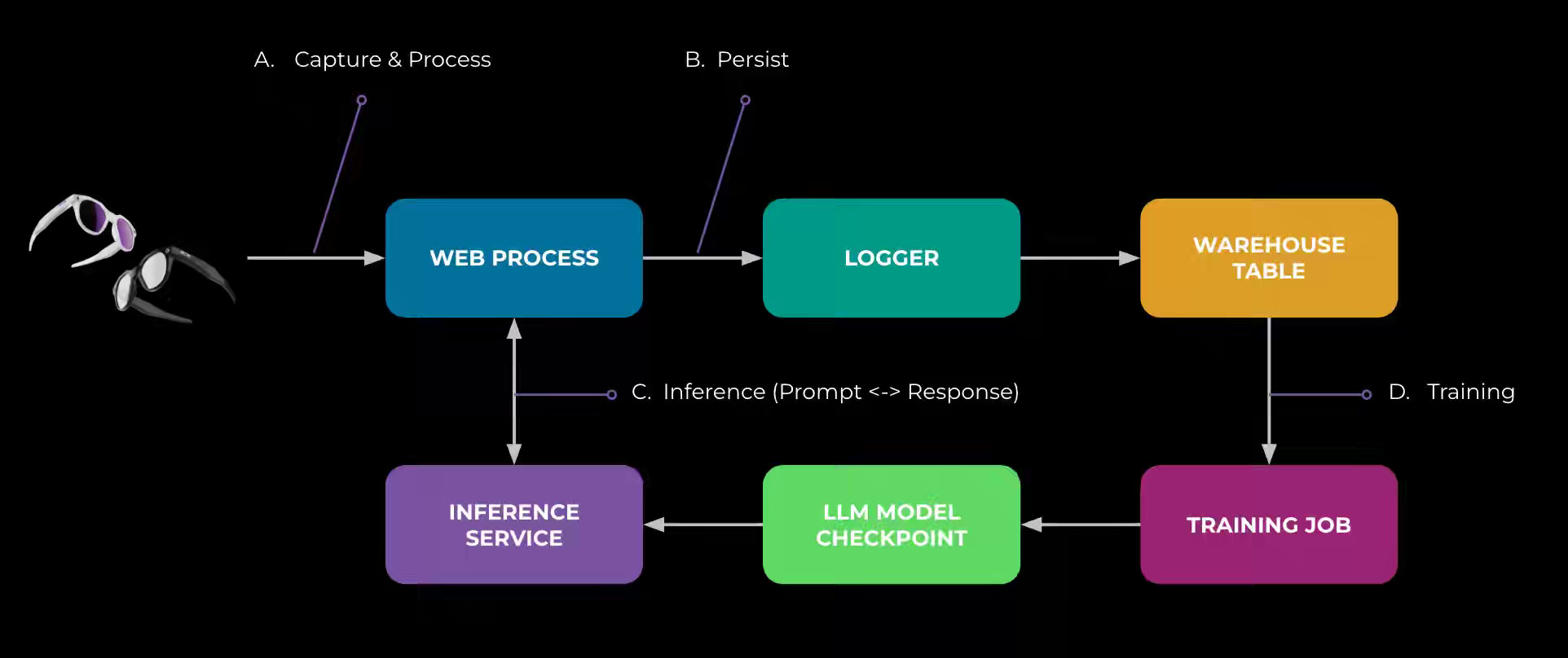
Gen AI introduces complex data flows that demand privacy-by-design infrastructure at a massive scale. Meta writes about its Privacy-Aware Infrastructure (PAI), which embeds automated data lineage, observability, and policy enforcement directly into GenAI product development—illustrated through its AI glasses use case. By mapping data movement end-to-end and enforcing policy zones across training and inference pipelines, PAI enables rapid GenAI innovation while maintaining verifiable privacy, transforming compliance from a constraint into an accelerator for responsible product development.
Han Fang, Karthik Abinav Sankararaman: Post-training 101
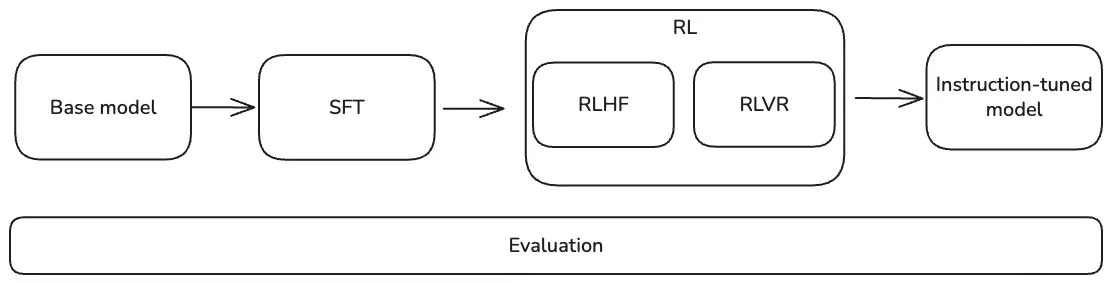
Transforming a pre-trained LLM into an aligned, instruction-following assistant requires careful post-training to balance capability with safety and usefulness. This guide walks through the full lifecycle—from Supervised Fine-Tuning (SFT) for teaching models to follow instructions, to Reinforcement Learning methods like RLHF, RLAIF, and RLVR that optimize for preferences or verifiable outcomes, and finally to robust evaluation frameworks combining ground-truth, LLM-judge, and human assessments.
https://tokens-for-thoughts.notion.site/post-training-101
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.