
Data Engineering Weekly #246
The Weekly Data Engineering Newsletter


Meet Compass — Dagster’s new AI data analyst for Slack
Your data team is doing the best they can, but demand for data is limitless. The problem is that getting answers from data means hunting down the right dashboard, figuring out if it’s current, and translating what you see back into the question you asked.
We built Compass to fix this. It’s AI-powered data analysis that lives where you work. Ask a question in plain English, get an answer from your warehouse with charts and context. No dashboards. No tickets. No waiting.
Set up your free account in minutes.
Lak Lakshmanan: What it means to get your data ready for AI
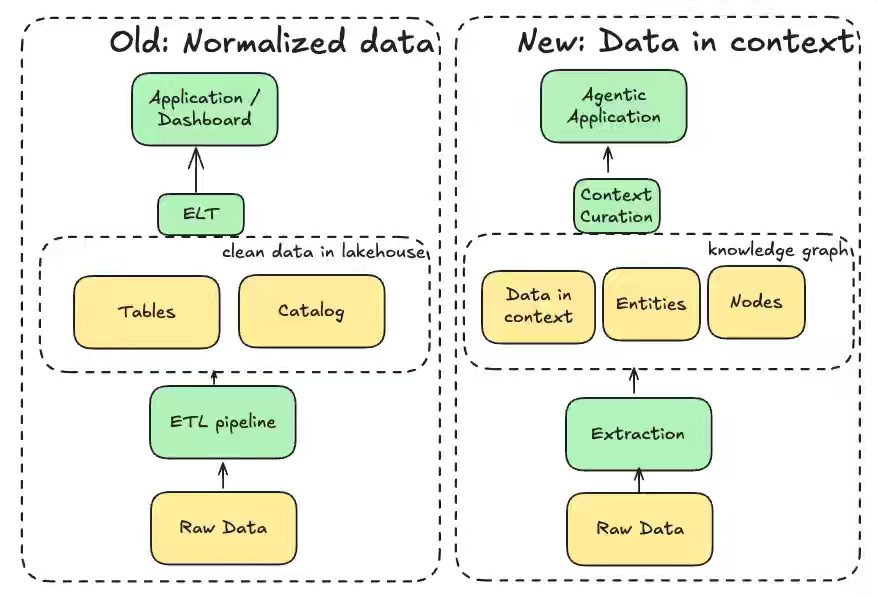
One of the most challenging questions in every data org is the efficient and successful adoption of AI agents to enhance productivity and efficiency. The author outlines five resulting changes: moving from heavy normalization to context-rich data, prioritizing curated exemplars for in-context learning, building agent-ready infrastructure for perception and tool use, treating agent-generated artifacts as first-class data, and connecting observability to continuous model retraining. These shifts reposition data engineering toward enabling flexible, context-aware AI systems, changing the role from building rigid pipelines to designing environments where agents autonomously operate and improve.
https://ai.gopubby.com/what-it-means-to-get-your-data-ready-for-ai-518861a8f025
IBM: The 2025 CDO Study - The AI multiplier effect
Only 26% of CDOs are confident their organization can use unstructured data in a way that delivers business value.
IBM publishes the 2025 CDO study. The study identifies five focus areas—strategy, scale, resilience, innovation, and growth—showing that high-ROI organizations align data strategy with business outcomes, give AI agents fast access to high-quality distributed data, build resilient governance for secure agentic access, democratize data across the workforce, and convert proprietary data into differentiated data products.
https://www.ibm.com/thought-leadership/institute-business-value/en-us/report/2025-cdo
Jack Vanlightly: How Would You Like Your Iceberg Sir? Stream or Batch Ordered?
Answer: Bricked to Perfection 🧱
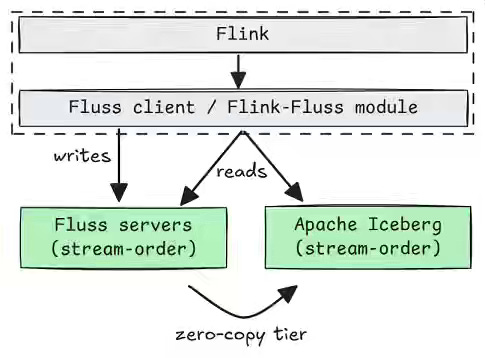
The quest to bridge the Lakehouse storage with the streaming engines is accelerating as the business needs to minimize the friction. The author compares two systems, Apache Fluss and Confluent Kora/ TableFlow, and takes a deep dive into their design approaches.
Sponsored: How to scale your data team

Scaling Data Teams, the latest in our popular eBook series, is now available.
Building and scaling a data platform has never been more important or more challenging. Whether you’re just starting to build a data platform or leading a mature data organization, this guide will help you scale your impact, accelerate your team, and prepare for the future of data-driven products.
Learn how real data teams, from solo practitioners to enterprise-scale organizations, build.
Daniel Beach: 650GB of Data (Delta Lake on S3). Polars vs. DuckDB vs. Daft vs. Spark.
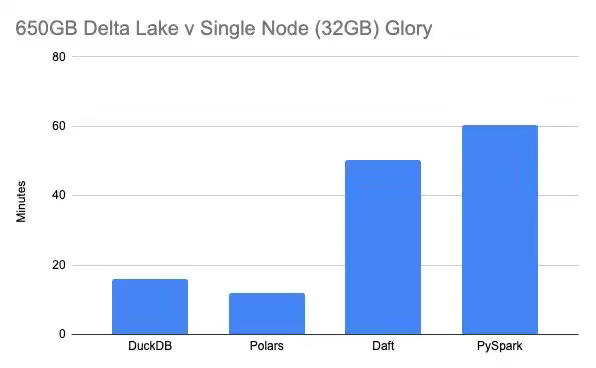
Refactoring the data pipeline to run on a single node can bring efficiency, rather than running a distributed processing framework like Apache Spark. The author highlights the same with the benchmarks of DuckDB, Polars, Daft, and PySpark on a 32 GB / 16-CPU EC2 instance, showing that DuckDB completed the workload in 16 minutes, Polars in 12 minutes, Daft in 50 minutes, and PySpark in over an hour, with all engines able to stream and aggregate the dataset without out-of-memory failures.
https://dataengineeringcentral.substack.com/p/650gb-of-data-delta-lake-on-s3-polars
Alibaba: DuckDB Internals
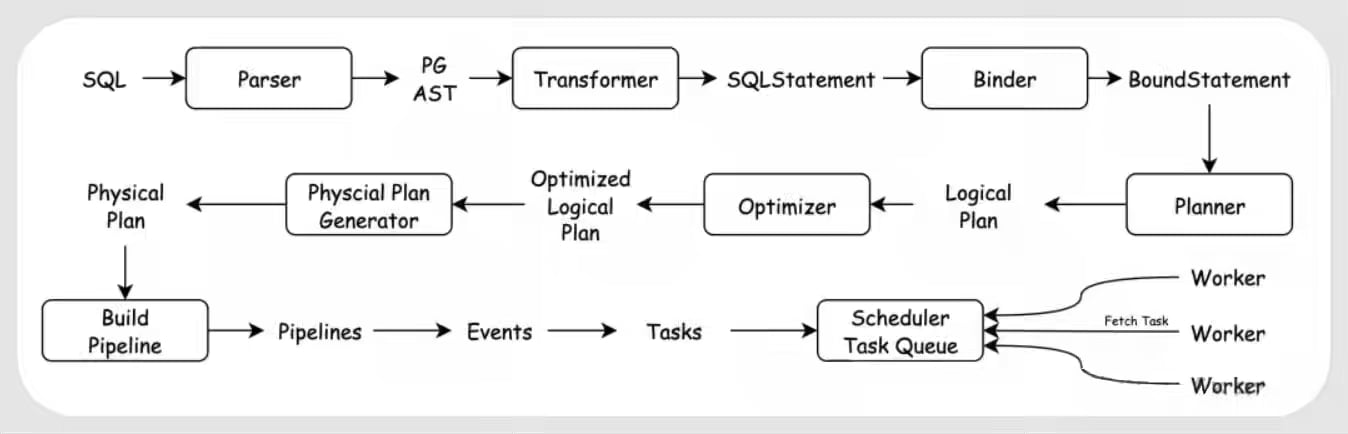
Speaking of the single node execution engines, Alibaba writes an excellent three part series taking an in-depth look at the duckdb internals. The blog writes the code analysis of DuckDB’s fileformat, table storage format and the execution layer.
https://www.alibabacloud.com/blog/duckdb-internals---part-1-file-format-overview_602511
https://www.alibabacloud.com/blog/duckdb-internals---part-2-table-storage-format_602657
https://www.alibabacloud.com/blog/duckdb-internals---part-3-execution-layer-overview_602660
Netflix: Unlocking Entertainment Intelligence with Knowledge Graph
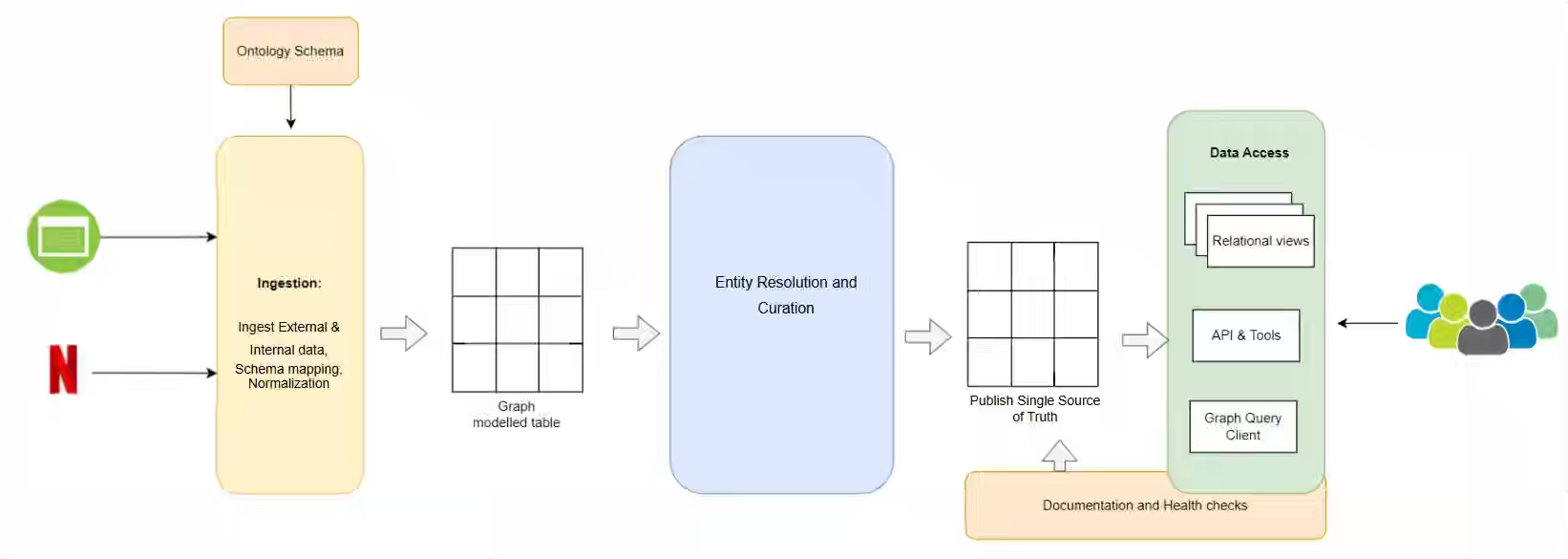
Netflix writes about the challenge of unifying vast, heterogeneous entertainment datasets spread across disconnected silos, rigid schemas, and slow onboarding pipelines that limit analytics and ML effectiveness. The blog narrates builting an ontology-driven, RDF-based Entertainment Knowledge Graph that standardizes entities and relationships, stores them in a unified triple store with lineage and confidence metadata, and provides flexible access patterns and relational projections for downstream users.
Uber: I/O Observability for Uber’s Massive Petabyte-Scale Data Lake
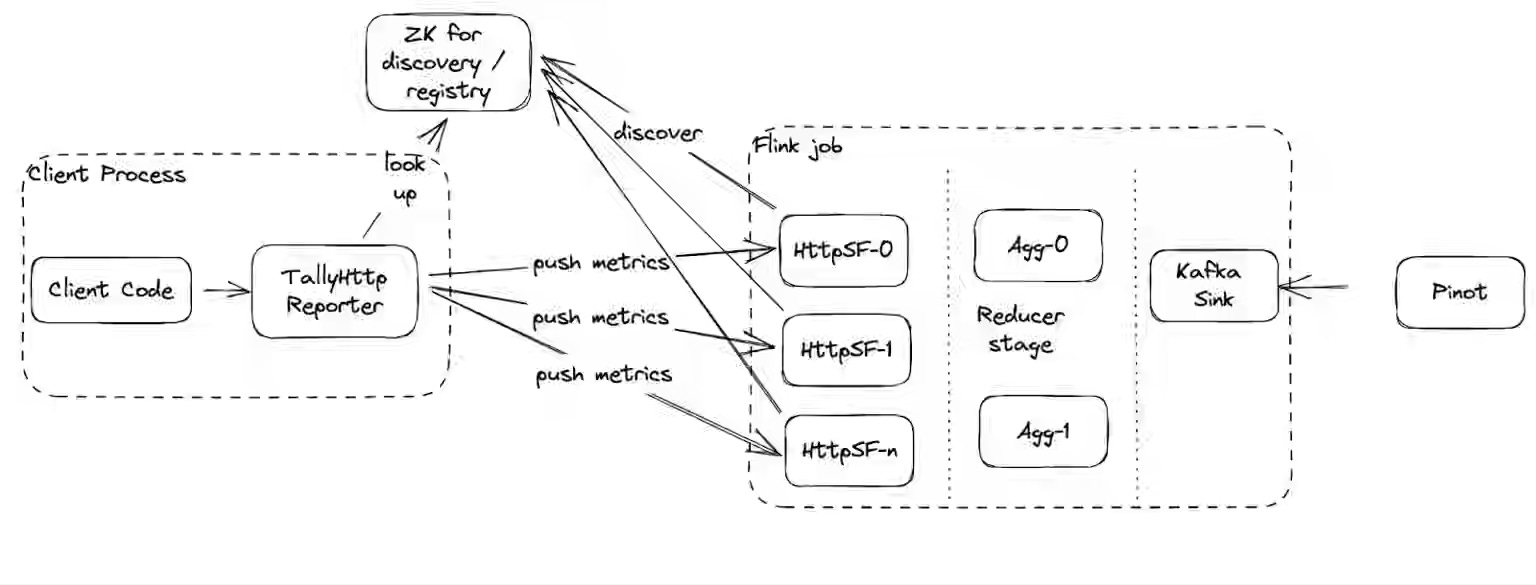
Uber writes about closing a critical gap in data I/O observability as it migrates toward its hybrid CloudLake architecture, where cross-provider network links, workload placement, and cost-efficient tiering demand fine-grained visibility. The blog narrate its HDFS- and GCS-compatible file system clients instrumentations to capture byte-level read/write metrics per dataset and partition with zero job changes, and introduced HiCam, a Flink-backed aggregation layer that reduces billions of high-cardinality events into real-time, queryable metrics.
https://www.uber.com/en-IN/blog/i-o-observability-for-ubers-massive-petabyte-scale-data-lake/
Netflix: How and Why Netflix Built a Real-Time Distributed Graph: Part 2 — Building a Scalable Storage Layer
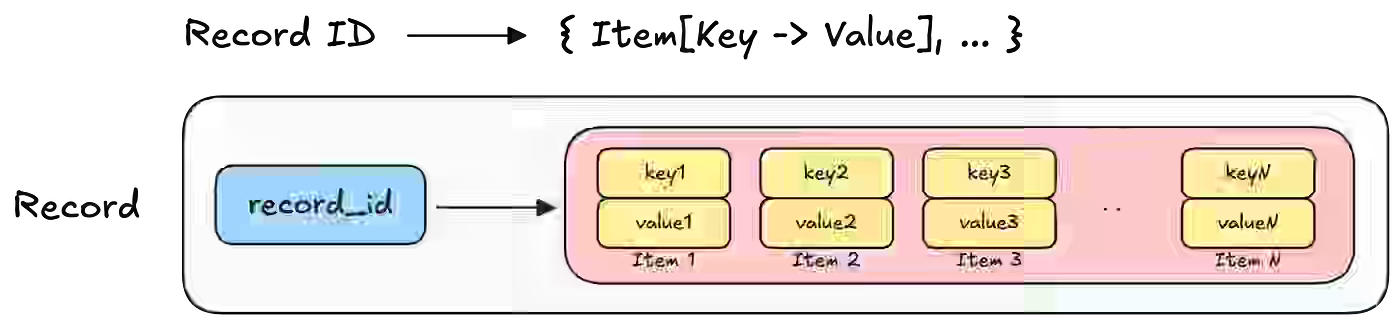
Netflix writes about the challenge of storing a real-time distributed graph with billions of nodes and hundreds of billions of edges while maintaining single-digit millisecond access latencies. The second part of the blog describes how native graph databases like Neo4j and Neptune could not meet Netflix’s horizontal-scale and ingestion requirements, leading the company to adopt KVDAL, a Cassandra-backed key-value abstraction that maps nodes and adjacency lists into isolated namespaces for independent scaling, flexible storage backends, and high-throughput updates.
Expedia: Colocating Input Partitions with Kafka Streams When Consuming Multiple Topics: Sub-Topology Matters!
Expedia to writes about debugging unexpected behavior in a Kafka Streams application where two topics with identical partitioning failed to colocate same-index partitions, breaking a shared in-memory cache intended to avoid redundant external API calls. The root cause was that Kafka Streams built two independent sub-topologies, and partition colocation is only guaranteed when topics are consumed within the same sub-topology. By introducing a shared state store, the team unified the topologies, enabling deterministic colocated partition assignments and restoring cache locality, significantly reducing external API traffic and improving performance.
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
This newsletter hits on a critical theme: data quality and reliability. We recently had a vivid example of this "Upstream Observability" problem. Our analytics dashboard reported a total failure for a new Microsoft Teams app launch: 1 visitor, 1 visit, 1 pageview. It looked like a complete flop.
But we dug into the raw logs (the upstream ground truth) and found a totally different reality: 159 events from 121 unique visitors, with a 31.4% share rate. The dashboard was hallucinating a 12,000% error.
It's a stark reminder: Don't trust the dashboard; trust the pipeline. If you're not observing your data at the source, you're flying blind.
Couldn't agree more! The shift to context-rich data for AI agents you hightlighted is a game-changer. So insightful.