
Data Engineering Weekly #248
The Weekly Data Engineering Newsletter


The Scaling Data Teams Guide
The latest eBook in our popular series is now available.
Building and scaling a data platform has never been more important or more challenging. Whether you’re just starting to build a data platform or leading a mature data organization, this guide will help you scale your impact, accelerate your team, and prepare for the future of data-driven products.
Learn how real data teams, from solo practitioners to enterprise-scale organizations, build.
Jason Gorman: The Gorman Paradox: Where Are All The AI-Generated Apps?
I had this very conversation recently. A friend of mine claimed that it is now easy to build a CRM and that everyone will build their own, thereby making all SaaS companies obsolete in the near future. It’s cheaper to manufacture software now, but SaaS companies don’t win on manufacturing. They win on distribution, trust, and operational burden. Building a CRM, perhaps commodized; operating one as a durable product is not.
https://codemanship.wordpress.com/2025/12/14/the-gorman-paradox-where-are-all-the-ai-generated-apps/
Gunnar Morling: You Gotta Push If You Wanna Pull
Balancing between Query over Data (pull) at Rest and Query (push) over a Stream is often a challenging part of system design. The author points out that the balance is that push is an efficient way to keep the state fresh through incremental data processing, making pull more efficient.
https://www.morling.dev/blog/you-gotta-push-if-you-wanna-pull/
LangChain: Agent Engineering - A New Discipline
Data Scientist → Analytical Engineer → Agentic Engineer. As the technology landscape evolves, we see new roles emerging that require specific skill sets. The blog lays the foundation of the emerging agentic engineering discipline in software engineering.
https://blog.langchain.com/agent-engineering-a-new-discipline/
Sponsored: The data platform playbook everyone’s using

We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating undering a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Mark Rittman: An Homage to Oracle Warehouse Builder, 25 Years Ahead of its Time in all its Java Thick-Client Glory
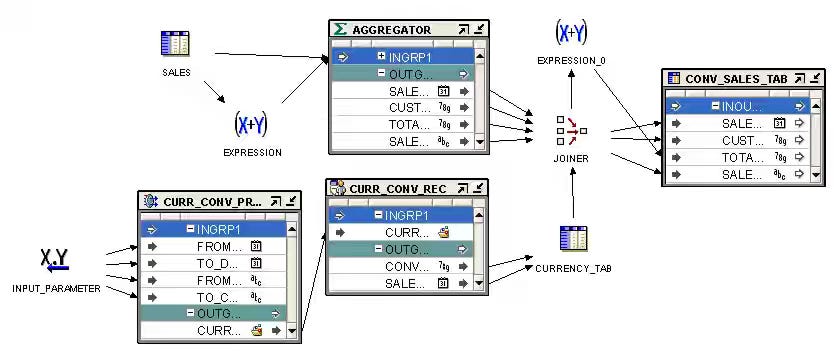
What goes around… Comes around is so true in data engineering. The blog is an excellent reminder of the quote, and, in fact, the author is making a subtle point: Oracle Warehouse Builder is still way ahead of modern data tools.
Julien Le Dem: Column Storage for the AI Era
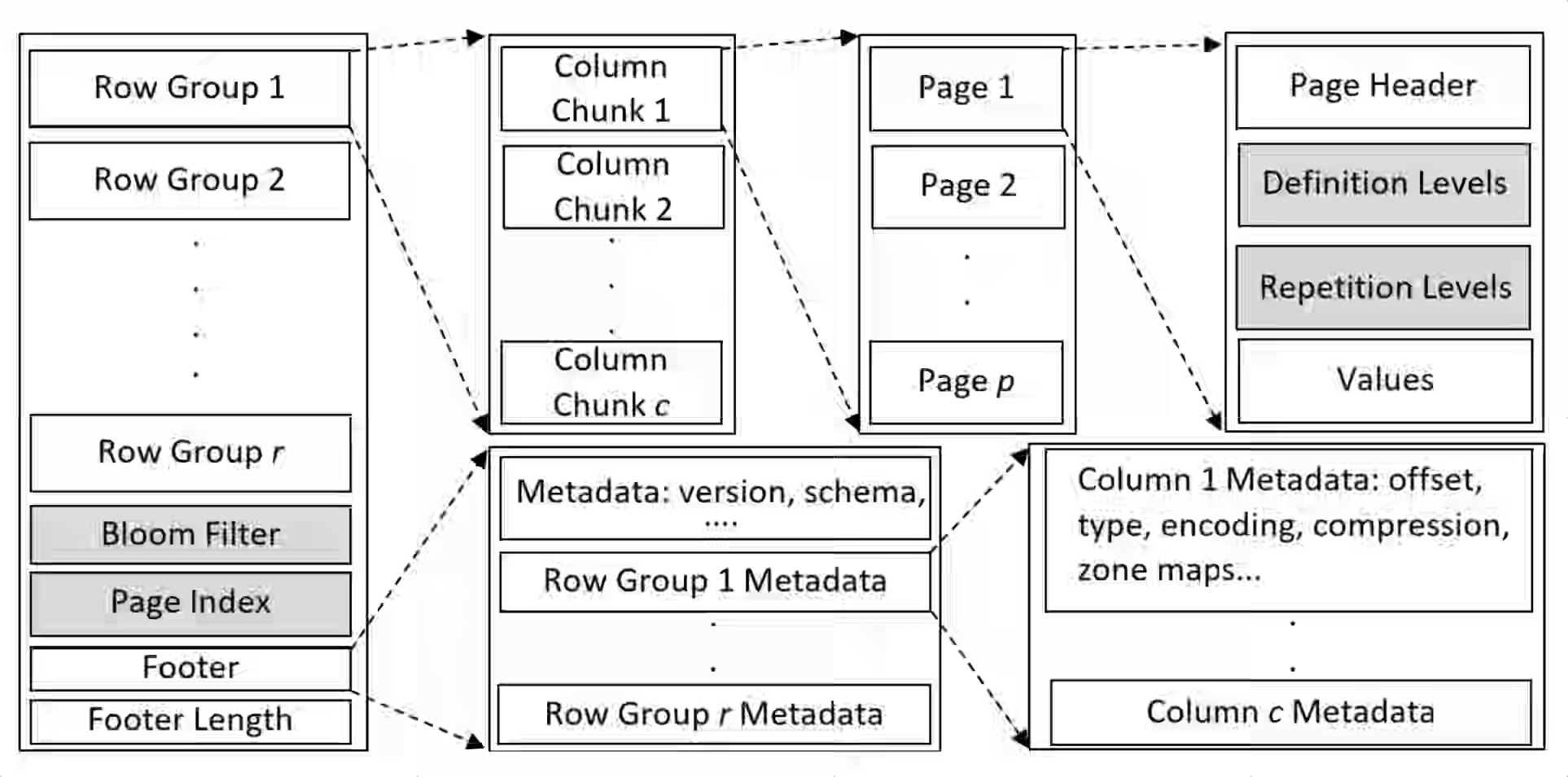
Apache Parquet is the de facto file format in data engineering. The blog offers an excellent, pragmatic view of Parquet, from its origins and the format's wins and adoption over the years, to some of its shortcomings, such as the underlying storage and compute semantics, and what the future holds for Apache Parquet. One of my favorite quotes in the blog is
The cheapest data to transfer is still the data you skip entirely.
https://sympathetic.ink/2025/12/11/Column-Storage-for-the-AI-era.html
Uber: Blazing Fast OLAP on Uber’s Inventory and Catalog Data with Apache Pinot™
Uber writes about adopting Apache Pinot to power real-time analytics on over 10 billion catalog entities across their INCA (Inventory and Catalog) system, replacing slow batch processing with sub-second query latencies. The blog narrates how it leveraged Pinot’s upsert capabilities, handling hundreds of thousands of updates per second, combined with optimizations such as UUID primary key compression, Java 17 runtime upgrades, and the Small Segment Merger minion task, to achieve 75% latency reduction and 40% storage savings.
Pinterest: LLM-Powered Relevance Assessment for Pinterest Search
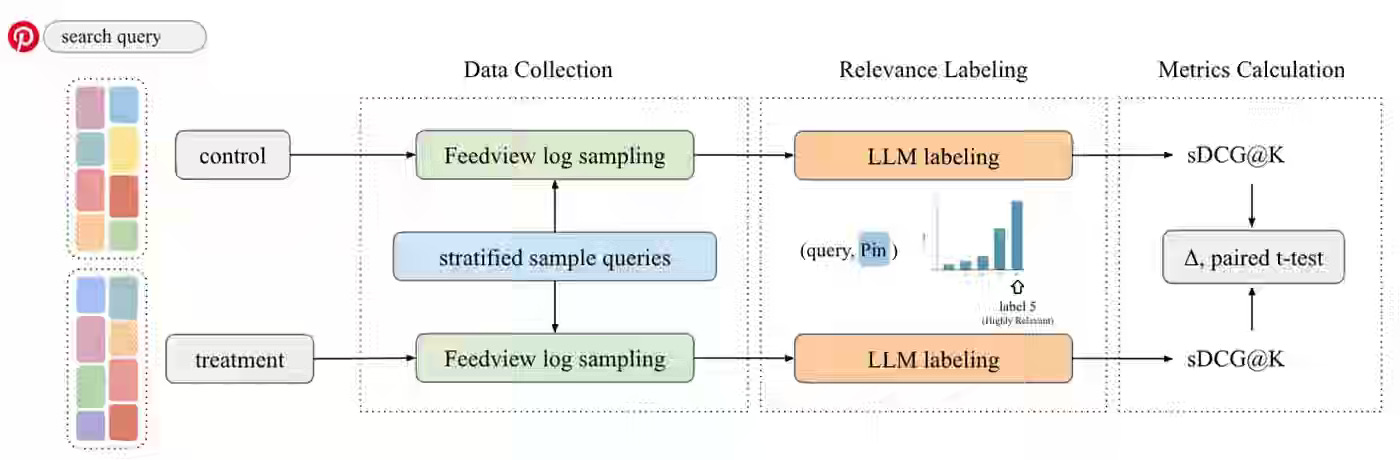
Pinterest writes about fine-tuned open-source multilingual LLMs (XLM-RoBERTa-large) on human-annotated data to automate search relevance assessment, replacing costly manual labeling that previously limited measurement capabilities. The LLM-based system, which processes Pin text features through a cross-encoder architecture and employs stratified sampling by query interest and popularity, reduced minimum detectable effects from 1.3-1.5% to ≤0.25% while achieving 73.7% exact match with human labels and enabling 150,000 relevance predictions in 30 minutes on a single A10G GPU.
Agoda: How Agoda Enhanced the Uptime and Consistency of Financial Metrics
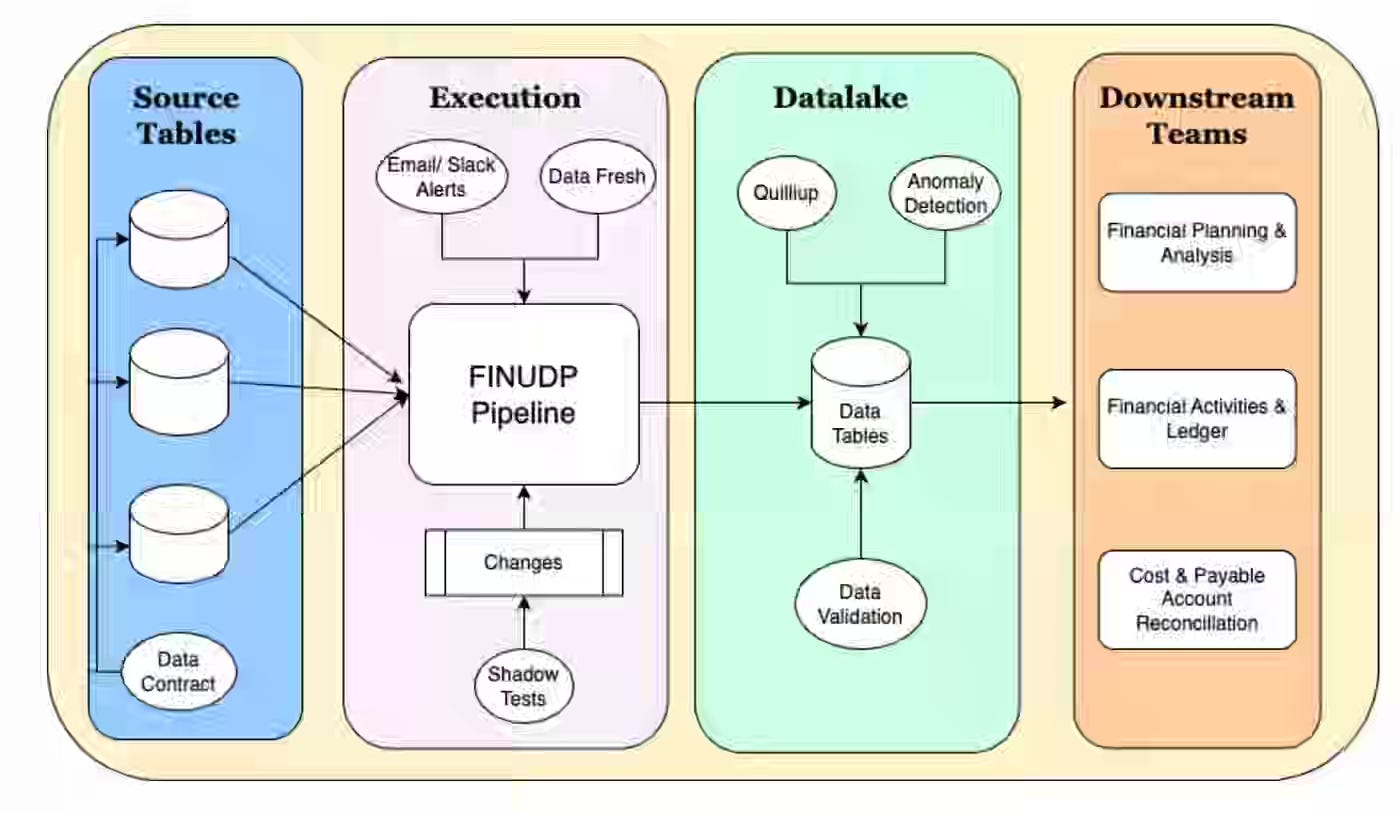
Agoda writes about consolidating multiple fragmented financial data pipelines into a centralized Financial Unified Data Pipeline (FINUDP) built on Apache Spark to eliminate inconsistencies caused by duplicate sources, conflicting transformation logic, and inconsistent data quality controls across teams. The unified pipeline, which processes millions of daily booking transactions, achieved 95.6% uptime through three-tier alerting (email, Slack, GoFresh monitoring), shadow testing in merge requests, automated data quality checks, data contracts with upstream teams, and ML-based anomaly detection, while reducing end-to-end runtime from five hours to 30 minutes through query optimization and infrastructure adjustments.
Flipkart: Apache Spark Optimisations
If you’re deep into data pipeline optimization, the blog is an excellent resource. The author identifies frequent patterns that can cause Spark performance issues and proposes an approach to address them.
https://blog.flipkart.tech/apache-spark-optimisations-c3464f71bd38
McDonald’s: Built to Scale: How a Config-Driven ETL Engine Is Powering Environmental, Social, and Governance Data Innovation
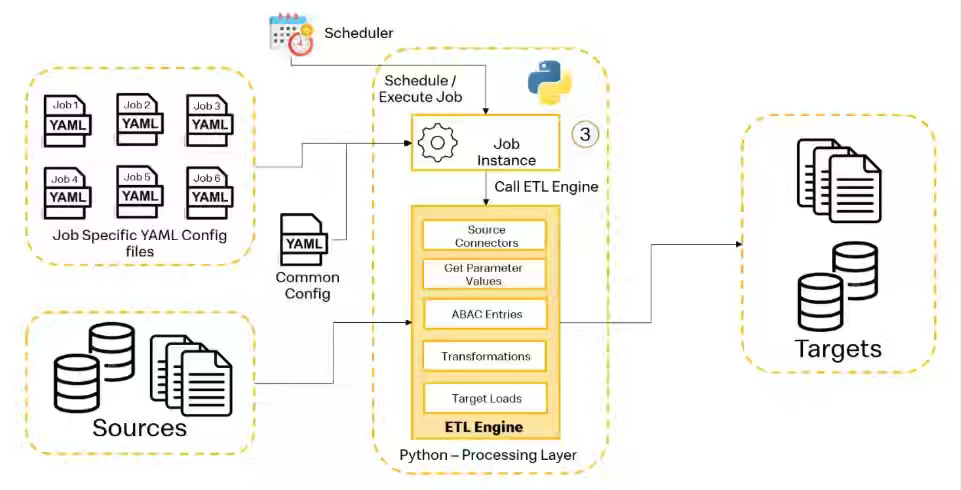
McDonald’s writes about building a reusable, config-driven ETL/ELT engine to address scalability and performance limitations in traditional manual ETL development, which couldn’t keep pace with growing ESG data requirements. The Python-based framework, which uses YAML configuration files instead of custom code and includes a Visual YAML Configuration Generator web tool, enables teams to build pipelines across multi-cloud environments with support for diverse transformations (column renaming, type conversion, aggregations, SQL functions), automated notifications, and comprehensive auditing while significantly reducing development time compared to traditional ETL methods.
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.