
Data Engineering Weekly #249
The Weekly Data Engineering Newsletter


How to scale your data team
Building and scaling a data platform has never been more important or more challenging. Whether you’re just starting to build a data platform or leading a mature data organization, this guide will help you scale your impact, accelerate your team, and prepare for the future of data-driven products.
Learn how real data teams, from solo practitioners to enterprise-scale organizations, build.
Andrej Karpathy: 2025 LLM Year in Review
One year seems a decade in the LLM era. Gemini was still effectively at version 1.5, image models routinely failed at basic text rendering, and credible video generation had not yet arrived. DeepSeek R1 did not exist; o1 was only beginning to introduce test-time inference. The author highlights the significance of 2025 and the paradigm shift that altered the landscape.
https://karpathy.bearblog.dev/year-in-review-2025/
LangChain: State of Agent Engineering
LangChain has published a survey of 1300 professionals on Agent Engineering in the industry. Key highlights for me,
Customer service and productivity products dominate the AI adoption.
Quality of the output is the biggest barrier to entry for AI Agents.
The open-source model has an equal market share between Gemini and Claude.
https://www.langchain.com/state-of-agent-engineering
Google: Introduction to AI Agents
Just like a Data Scientist, Agent Engineering is becoming the hottest job in 2026. If you’re looking to get started in this space, Google publishes an excellent overview of an Introduction to AI Agents.
https://drive.google.com/file/d/1C-HvqgxM7dj4G2kCQLnuMXi1fTpXRdpx/view
Sponsored: The data platform playbook everyone's using

We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating undering a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Ben Lorica: “World Model” is a mess. Here’s how to make sense of it.
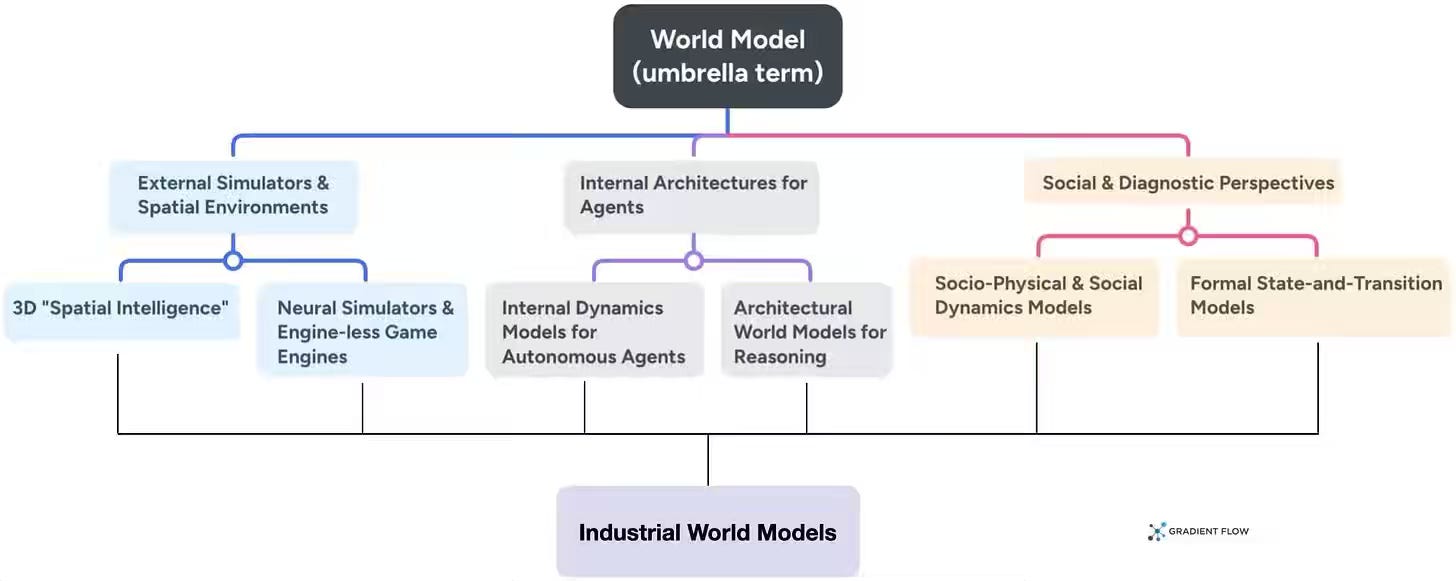
The article examines how the term "world model" has become an overloaded marketing label across AI vendors, encompassing seven distinct interpretations. The analysis highlights that the “world model” term captures a fundamental shift from token prediction to modeling geometry, physics, and long-horizon dynamics, and recommends that teams evaluate specific implementations based on actual inputs, maintained state, and decision-making outputs rather than accepting vendor terminology at face value.
https://gradientflow.substack.com/p/world-model-is-a-mess-heres-how-to
LanceDB: From BI to AI: A Modern Lakehouse Stack with Lance and Iceberg
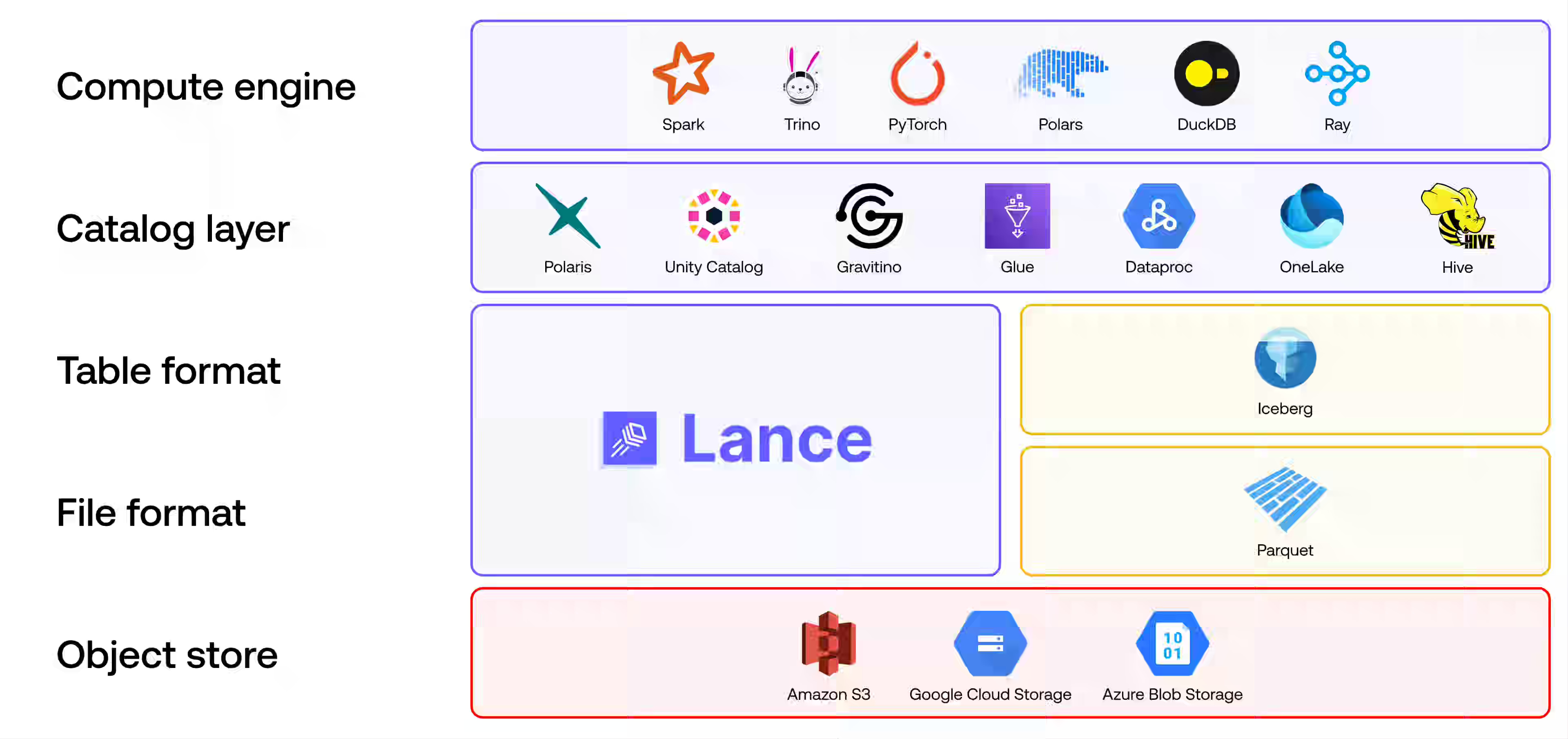
Are Iceberg and LanceDB complementary formats? The blog highlights LanceDB's ability to add new columns without a full table rewrite, native multimodel data storage, built-in text and vector indexing, and the potential to change the BI landscape, bringing it closer to AI.
https://lancedb.com/blog/from-bi-to-ai-lance-and-iceberg/
Dropbox: Inside the feature store powering real-time AI in Dropbox Dash
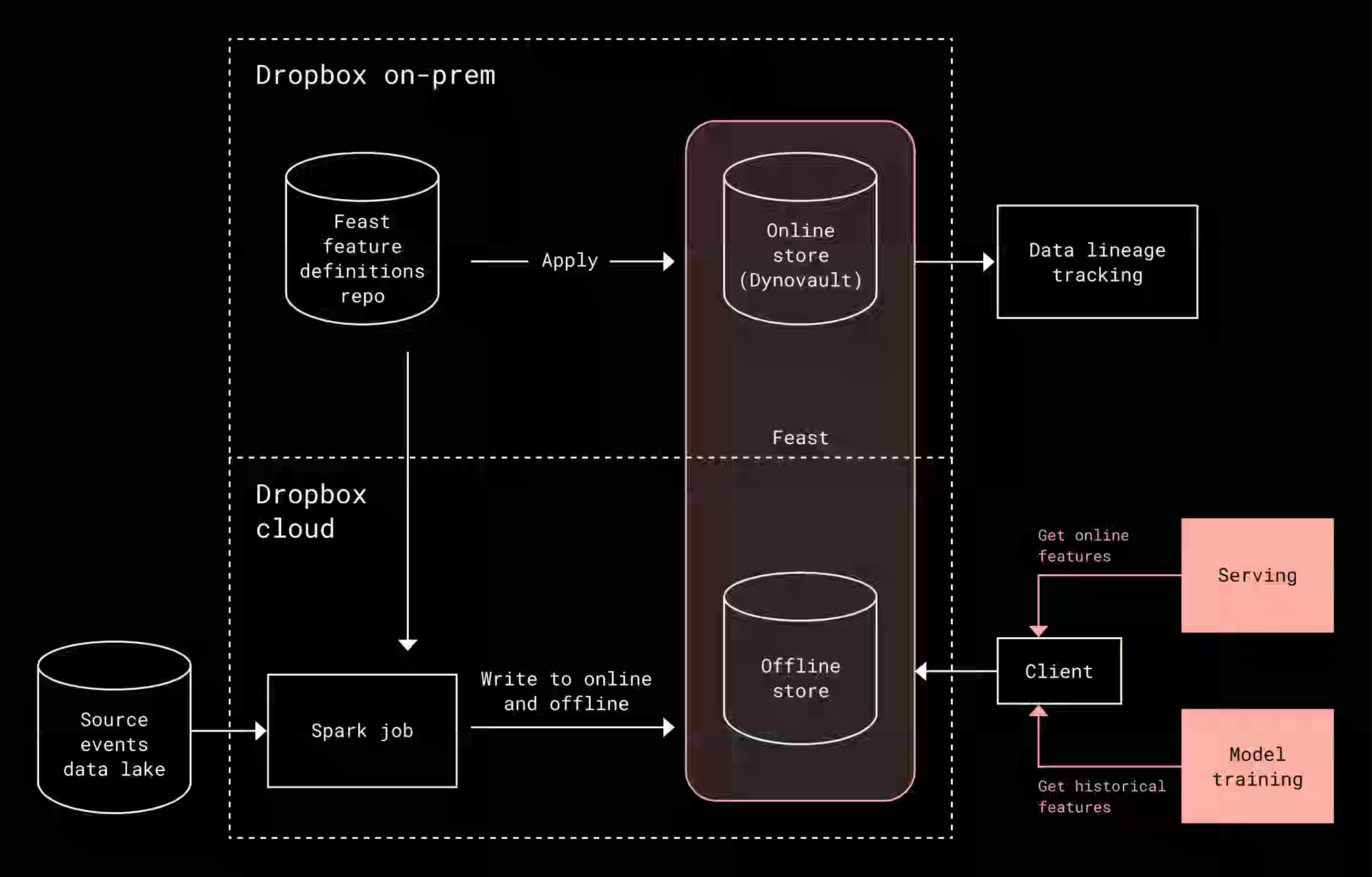
Dropbox describes a hybrid feature store for Dash's real-time AI ranking system, combining Feast for orchestration with a custom Go-based serving layer and Dynovault for storage, achieving sub-100ms latency requirements. The system processes thousands of concurrent feature lookups per search query through a three-part ingestion pipeline—batch processing with intelligent change detection (reducing writes from 100M+ to under 1M records), streaming for real-time signals, and direct writes for precomputed features—delivering p95 latencies of 25-35ms while maintaining feature freshness within minutes of user actions.
https://dropbox.tech/machine-learning/feature-store-powering-realtime-ai-in-dropbox-dash
Uber: How Uber Indexes Streaming Data with Pull-Based Ingestion in OpenSearch™
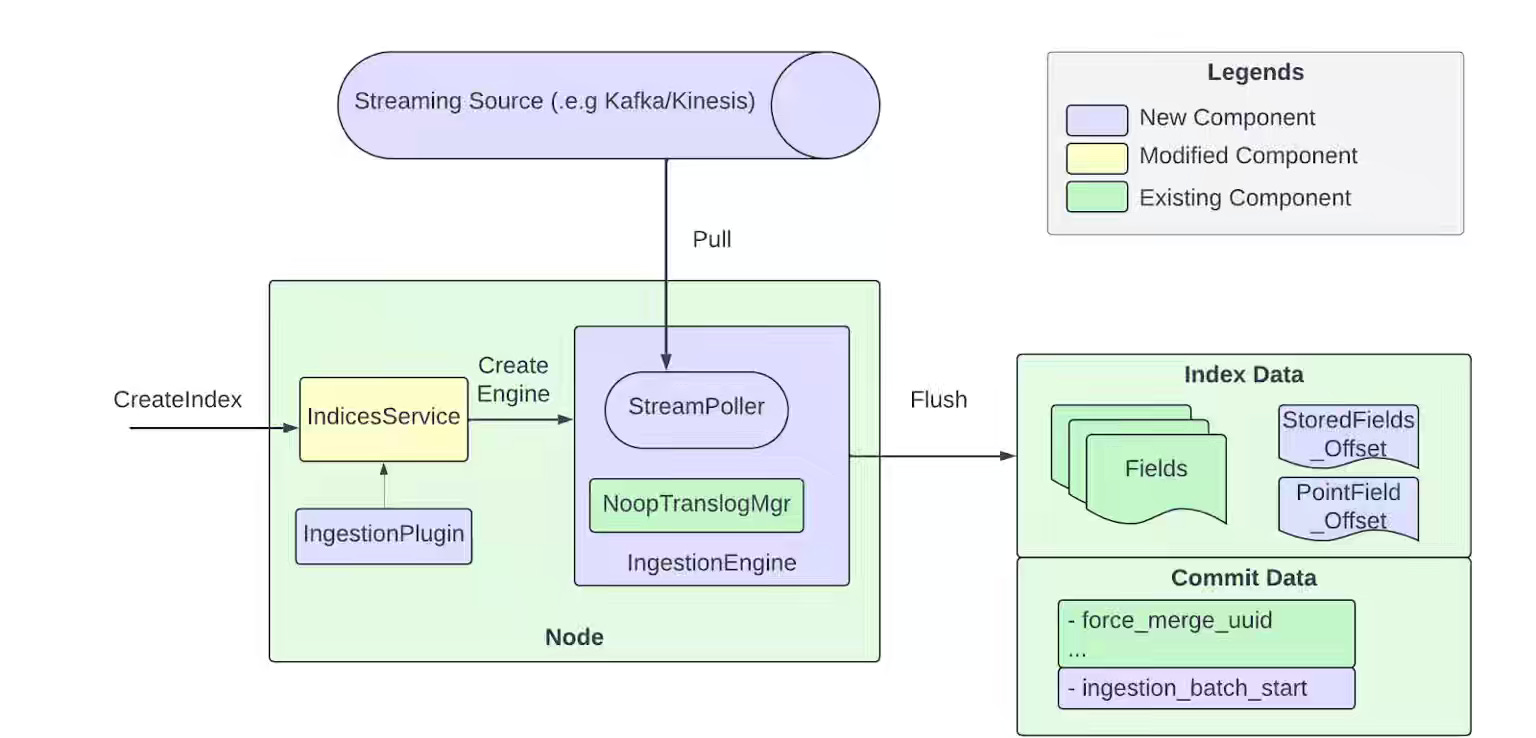
Uber writes about its native pull-based ingestion contribution to OpenSearch 3.0 to power their multi-region search platform, replacing traditional push-based indexing with Kafka-backed streaming ingestion that eliminates translog overhead and enables durable replay for shard recovery. The system maps each OpenSearch shard one-to-one with Kafka partitions, uses a no-op translog by treating Kafka as the source of truth, and supports two ingestion modes—segment replication, where only primaries ingest, and all-active, where all shards consume independently—delivering consistent global views across regions.
Grab: How Grab is accelerating growth with real-time personalization using Customer Data Platform scenarios.
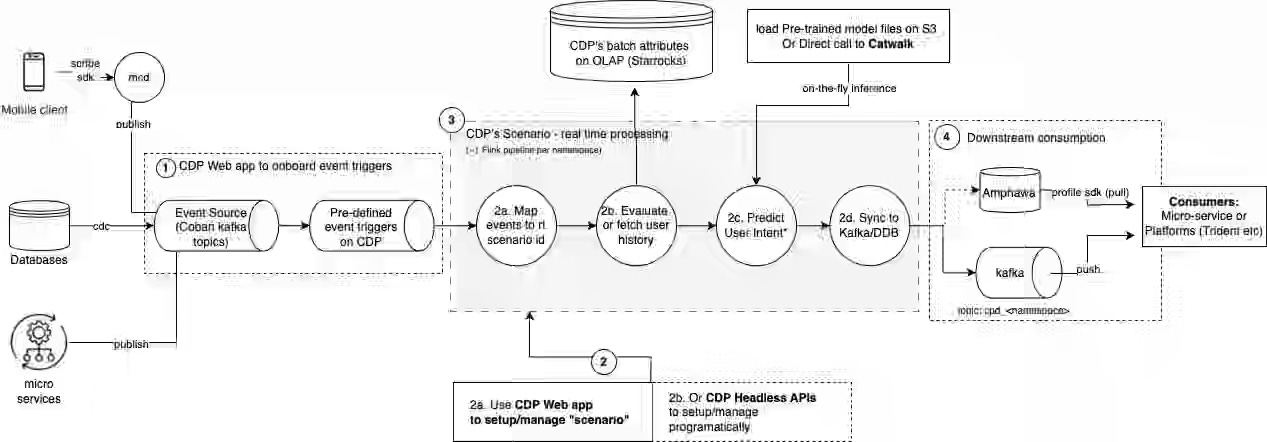
Grab writes about CDP Scenarios, a self-serve real-time personalization platform that processes user-initiated events via Apache Flink pipelines, combined with historical profile data from StarRocks and predictive models, to enable sub-15-second latency targeting. The system powers over 12 production use cases, achieving a 3% uplift in subscriber conversions for the Grab Unlimited signup abandonment scenario by delivering personalized nudges within 15 minutes of users dropping off the registration flow.
https://engineering.grab.com/cdp-scenarios
Decathlon: Polars at Decathlon: Ready to Play?
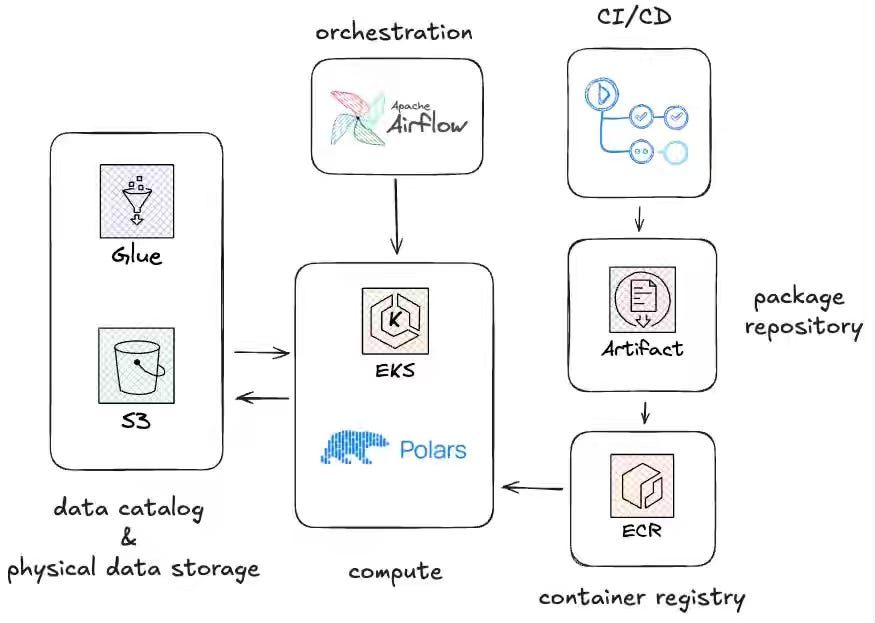
Apache Spark is an undisputed leader in batch processing, and we are starting to see native distributed dataframe processing engines like Polars gaining adoption. Decathlon writes about adopting Polars to process datasets under 50 GiB, replacing Apache Spark for smaller workloads and achieving near-zero infrastructure costs compared to their typical 180 GiB, 24-core Spark clusters.
https://medium.com/decathlondigital/polars-at-decathlon-ready-to-play-6abc4328d06c
Zalando: Contributing to Debezium: Fixing Logical Replication at Scale
Zalando writes about implementing a mechanism to flush LSNs via JDBC keepalives, even when no data changes occur, to prevent disk-exhausting WAL growth in low-traffic databases. By pairing this with a strategy that trusts the replication slot's position over stored Kafka offsets, the design eliminated the "offset mismatch" errors that previously triggered expensive and unnecessary full database re-snapshots.
https://engineering.zalando.com/posts/2025/12/contributing-to-debezium.html
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.