
Data Engineering Weekly #250
The Weekly Data Engineering Newsletter


The Scaling Data Teams Guide
Building and scaling a data platform has never been more important or more challenging. Whether you’re just starting to build a data platform or leading a mature data organization, this guide will help you scale your impact, accelerate your team, and prepare for the future of data-driven products.
Learn how real data teams, from solo practitioners to enterprise-scale organizations, build.
Thoughtworks: The Model Context Protocol’s impact on 2025
Thoughtworks writes about Model Context Protocol's (MCP) transformative impact on 2025 software development, highlighting its role in accelerating agentic AI adoption by simplifying connections between AI systems and external data sources .The blog identifies emerging techniques including context engineering for systematic LLM information optimization, AI-powered UI testing via Playwright-mcp and mcp-selenium servers, and anchoring coding agents to reference applications to prevent code drift, while cautioning against security vulnerabilities (tool poisoning, cross-server shadowing) and antipatterns like naive API-to-MCP conversion.
https://www.thoughtworks.com/insights/blog/generative-ai/model-context-protocol-mcp-impact-2025
Uber: Powering Billion-Scale Vector Search with OpenSearch

Uber Engineering migrated from Apache Lucene’s HNSW to Amazon OpenSearch for billion-scale vector search, addressing algorithm inflexibility and GPU support limitations when handling 1.5 billion items with 400-dimension embeddings for personalized recommendations and fraud detection. The implementation reduced indexing time by 79% (from 12.5 hours to 2.5 hours) through Spark batch ingestion, optimized flush/merge policies, while achieving 52% lower P99 latency (250ms to 120ms at 2K QPS) via shard-to-node ratio tuning, replica scaling, in-memory KNN graph optimization, and blue/green deployments.
https://www.uber.com/en-IN/blog/powering-billion-scale-vector-search-with-opensearch/
Andrew Hoblitzell: QConAI NY 2025 - Designing AI Platforms for Reliability: Tools for Certainty, Agents for Discovery
The blog narrates the QCon AI NYC 2025 presentation on treating agentic AI as an engineering problem requiring deterministic boundaries around probabilistic components, arguing that reliability improves when models handle interpretation and classification while deterministic systems execute actions and enforce constraints. The speaker outlined practical patterns including reducing schema complexity to limit query generation errors, using role-specialized agents, constraining tool catalogs to prevent "paradox of choice" degradation, and anchoring agents to deterministic runbooks for repeatable operations rather than allowing runtime process invention.
https://www.infoq.com/news/2025/12/qcon-nvidia-platform/
Sponsored: The data platform playbook everyone's using

We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating undering a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Monday: The Power of Structured Data: Inside monday.com’s Data Entities
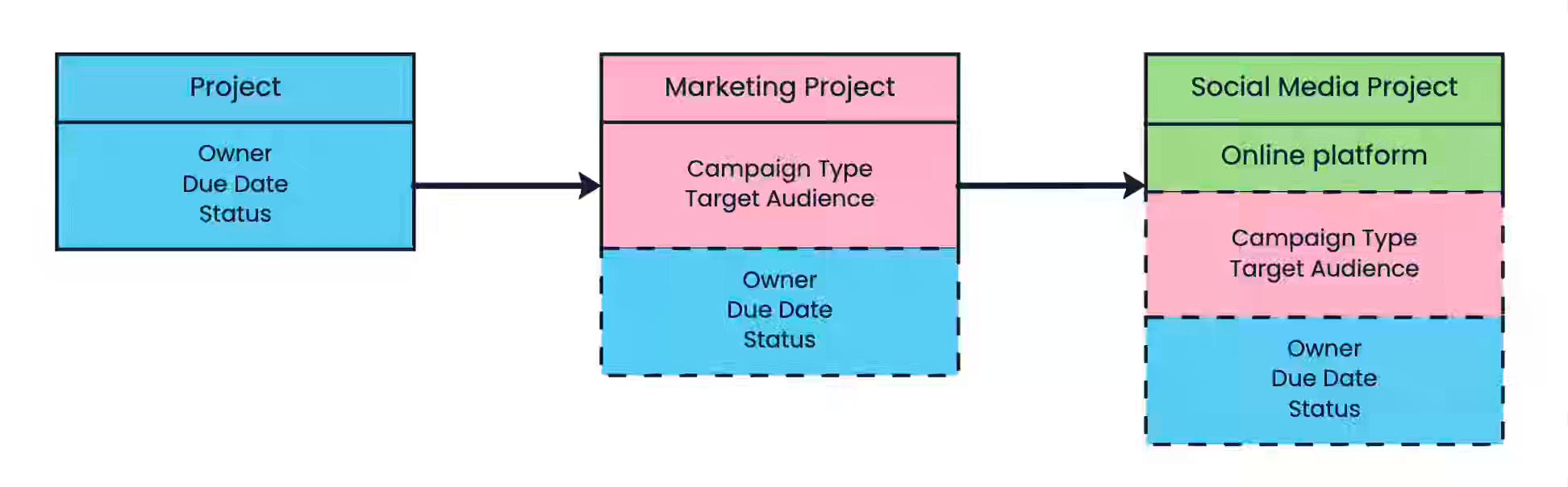
Monday.com writes about Data Entities as a semantic layer to address fragmentation caused by boards functioning as unstructured spreadsheets, where business objects like projects, tickets, and deals lacked standardized definitions that hindered cross-board reporting and AI agent context understanding. The implementation uses field-and-policy-based models with hierarchical inheritance, Managed Columns for field standardization, and a new "data-entity" app feature in monday's open platform that enables entity-level updates to propagate across all associated boards.
https://engineering.monday.com/the-power-of-structured-data-inside-monday-coms-data-entities/
Meta: Python Typing Survey 2025: Code Quality and Flexibility As Top Reasons for Typing Adoption
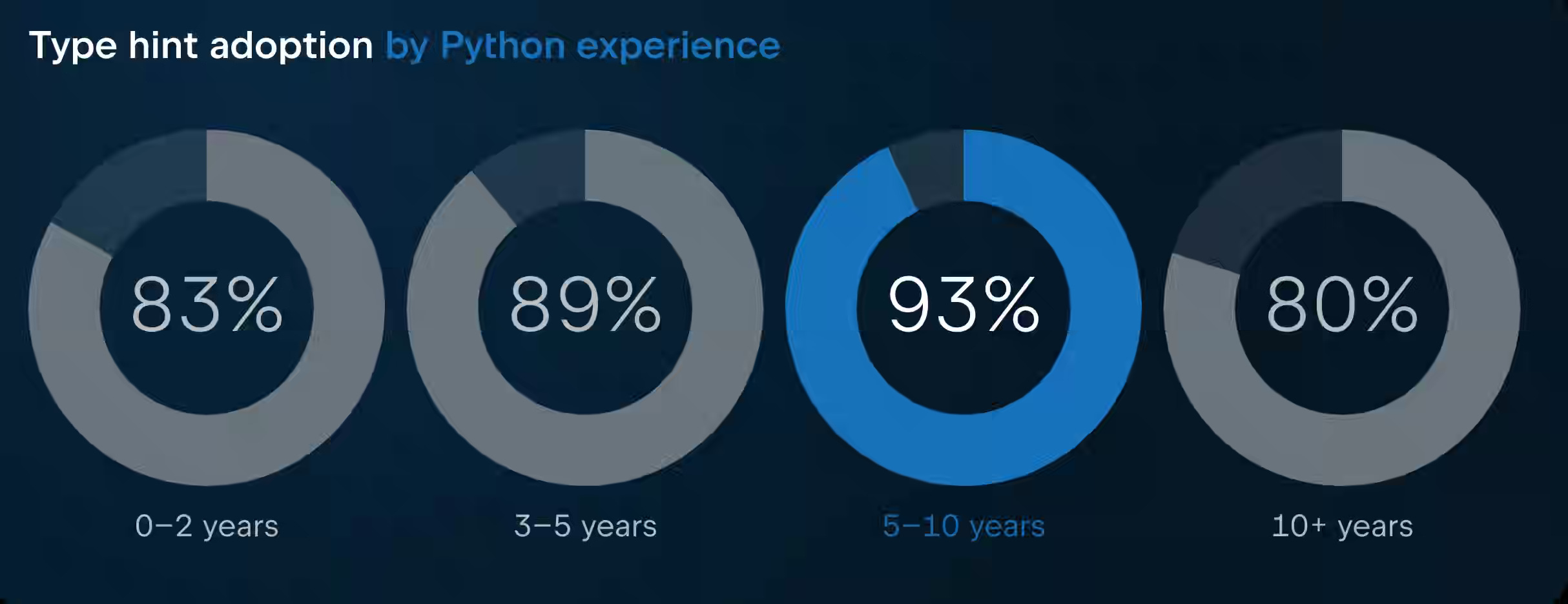
Python becomes the defacto langiage for data programming, and have a strong typing system brings more reliability to the codebase. The 2025 Typed Python Survey reveals that 86% of Python developers regularly use type hints, with adoption highest among developers with 5-10 years of experience (93%). Key challenges include third-party library support gaps (NumPy, Pandas, Django), complexity of advanced features (generics, TypeVar, decorators), tooling fragmentation between type checkers (Mypy at 58% usage, emerging Rust-based checkers at 20%), and lack of runtime enforcement.
Alibaba: Say Goodbye to Manual Tracking! An In-Depth Analysis of Non-Intrusive Data Collection for Android Apps
Data tracking a critical data engineering skill which the industry won’t talk or write about a lot. I’m glad to see this in-depth analysis on data collection from Alibaba. Alibaba writes about a non-intrusive Android monitoring solution using Gradle plugins, AGP API, and ASM bytecode instrumentation to automate APM data collection without manual SDK initialization or code modifications. The implementation uses dynamic AGP version adaptation, conflict-prevention strategies (blacklists for system packages and third-party APM tools, whitelist filtering, idempotent instrumentation), and defensive programming in injected agents (SDK initialization checks, exception isolation, silent returns when uninitialized), while supporting diverse collection scenarios including user behavior tracking via proxy listeners, network monitoring through OkHttp/HttpURLConnection hooks.
PyTorch: Deploying Smarter: Hardware-Software Co-design in PyTorch
People who are really serious about software should make their own hardware." — Alan Kay
Even if we don’t often build software and hardware together, it is vital to understand the software behaviour under certain hardware configurations. Arm released a collection of Jupyter notebook tutorials demonstrating hardware-software co-design techniques in PyTorch for efficient on-device AI, addressing the limitations of traditional post-training quantization that applies uniform precision across all neural network layers.
https://pytorch.org/blog/deploying-smarter-hardware-software-co-design/
DuckDB: Iceberg in the Browser
DuckDB introduced browser-based access to Iceberg REST Catalogs through DuckDB-Wasm, enabling users to query and edit Iceberg tables directly from a browser tab without installing software or managing infrastructure. The implementation unified DuckDB's HTTP networking layer across native and WebAssembly environments through three changes: redesigning the core HTTP interface for consistent extension access, creating a JavaScript network wrapper for DuckDB-Wasm, and routing all Iceberg networking through this common layer, with initial Amazon S3 Tables support where all computations run locally in the browser.
https://duckdb.org/2025/12/16/iceberg-in-the-browser
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
#250 - what a number. Congratulations!