
Data Engineering Weekly #251
The Weekly Data Engineering Newsletter


Best practices for LLM development
LLMs are transforming software development, but integrating them into real projects can be tricky when models don’t understand your codebase, pipelines, or conventions.
Join Dagster on January 27th for a practical look at data engineering best practices, common pitfalls, and live demos of LLM developments.
Editor’s Note: The Edition of Predictions!! Well, Mostly
It is always exciting to read the predictions and look back on 2025. I put a lot of effort into collecting some of these predictions and bundling them in this edition. At DEW, we also reached a few existing milestones. We just published our 250th edition and reached 50,000 Substack followers. It is remarkable growth, considering how lazy I am on LinkedIn and how little I promote DEW. I’m looking to improve on it, and over the holidays, I tried a bit of Agent building on top of DEW, which I’m hoping to launch soon. I wish all the DEWers a prosperous 2025 and thank you for your continued support.
Ananth Packkildurai: DEW - The Year in Review 2025
Why not start with our own year-in-review and a bit of predictions? Agent Engineering is undoubtedly becoming a discipline of its own in engineering, similar to the rise of data scientists. Both, funny enough, run into data inconsistency issues, and everyone does data engineering eventually. (Hello Context Engineering)
I wrote a bit about how the catalog becomes the new database as the adoption of Apache Iceberg and Knowledge Engineering increases. I’ve a lot of concern about the Iceberg Rest Catalog, which I will write about as a separate blog this week. Stay tuned.
https://www.dataengineeringweekly.com/p/dew-the-year-in-review-2025
Sebastian Raschka: The State Of LLMs 2025: Progress, Problems, and Predictions
The State of LLMs 2025 examines how DeepSeek R1's breakthrough demonstrated that reasoning models can be trained for approximately $5 million using Reinforcement Learning with Verifiable Rewards (RLVR), fundamentally shifting industry cost assumptions and development approaches. The field has pivoted from pure pre-training scale to inference-time scaling—where models allocate more compute during generation for complex tasks—while grappling with "benchmaxxing," which undermines evaluation reliability, and recognizing that LLMs enhance rather than replace human expertise in coding and writing.
https://magazine.sebastianraschka.com/p/state-of-llms-2025
Ian Cook: 10 Predictions for Data Infrastructure in 2026
The article forecasts the maturation of open standards like Apache Arrow and ADBC replacing legacy protocols (ODBC/JDBC) while Apache Iceberg transitions from hype to mainstream adoption. Organizations are shifting from monolithic data warehouses to composable, multi-engine architectures built on open formats and components like DuckDB and DataFusion, enabling analytical systems to power operational applications and provide AI agents with fast, governed access to structured data.
https://columnar.tech/blog/2026-predictions/
Sponsored: The Scaling Data Teams Guide

Building and scaling a data platform has never been more important or more challenging. Whether you’re just starting to build a data platform or leading a mature data organization, this guide will help you scale your impact, accelerate your team, and prepare for the future of data-driven products.
Learn how real data teams, from solo practitioners to enterprise-scale organizations, build.
Ben Lorica: Data Engineering in 2026: What Changes?
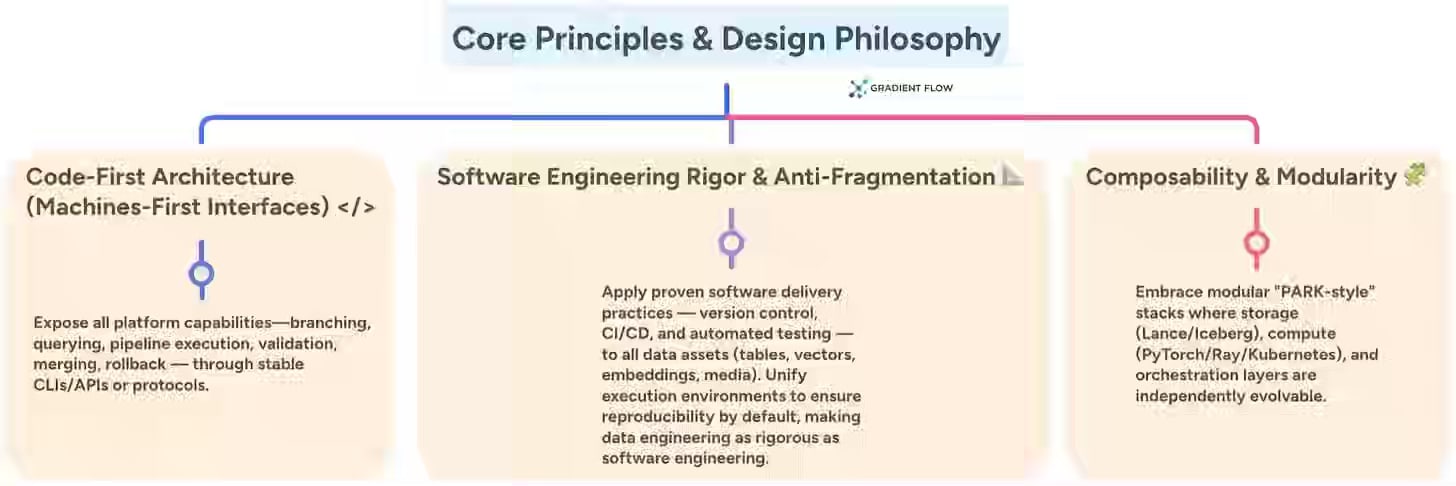
The article argues that agent-native platforms must move beyond tabular data to handle multimodal assets like text, images, and video, while treating documentation as versioned, queryable context stores that agents can understand. The platform shift requires pipeline-native safety guarantees, using write-audit-publish patterns in which agents write to isolated branches before merging, fundamentally changing data engineers' roles from manual ETL work to supervising agent fleets and defining governance policies.
https://gradientflow.substack.com/p/data-engineering-for-machine-users
Stanford HAI: Stanford AI Experts Predict What Will Happen in 2026
Stanford experts predict AI will shift from evangelism to evaluation in 2026, with organizations deflating the hype bubble by reporting failed projects and measuring actual Return on Investment rather than chasing AGI. The report highlights breakthroughs in medical AI enabled by self-supervised learning that eliminate the need for expensive expert-labeled data, alongside nations building sovereign infrastructure to reduce dependence on US providers.
https://hai.stanford.edu/news/stanford-ai-experts-predict-what-will-happen-in-2026
HuggingFace: Tokenization in Transformers v5: Simpler, Clearer, and More Modular
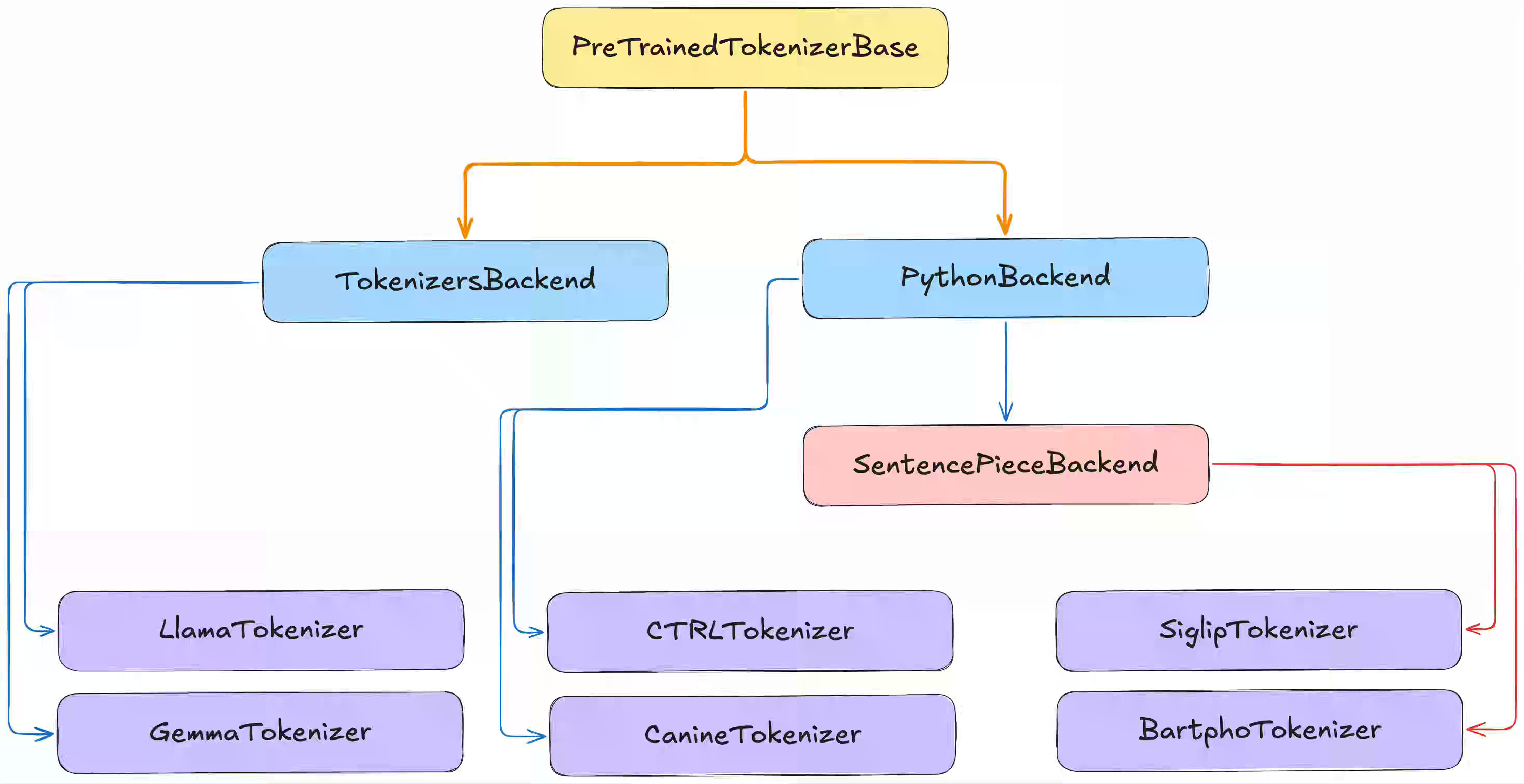
Hugging Face's Transformers v5 redesigns tokenizers by separating the architecture from the trained vocabulary, similar to how PyTorch separates the model structure from the weights. The update consolidates confusing Python and Rust implementations into a single Rust-backed version while allowing users to inspect tokenizer internals directly and train custom tokenizers from scratch on their own data.
https://huggingface.co/blog/tokenizers
Netflix: Towards Generalizable and Efficient Large-Scale Generative Recommenders
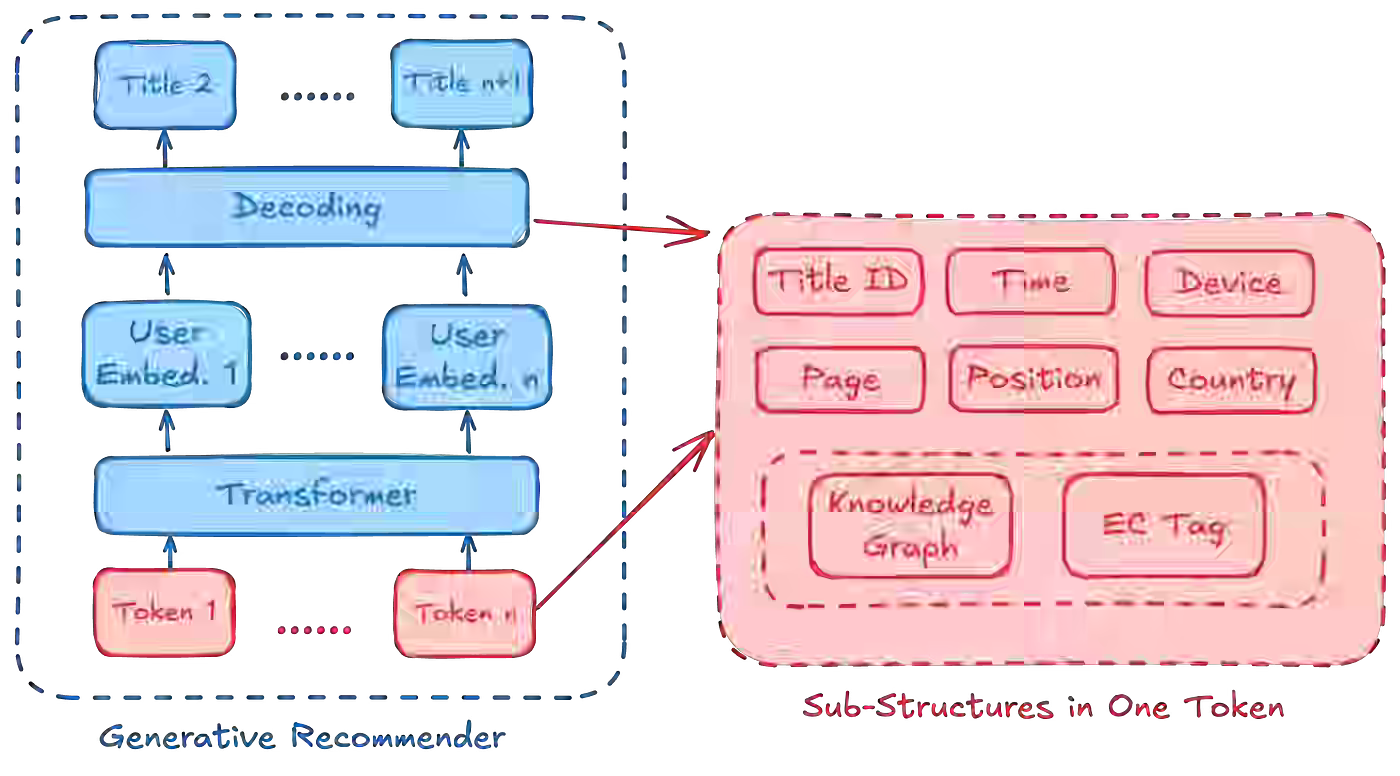
Netflix explains that generative recommendation models scale differently than standard LLMs because each task has an inherent unpredictability limit, which changes how compute should be allocated. The blog explains how it reduced training costs by using sampled softmax and projected output heads to handle extremely large catalogs with millions or billions of items.
Vinted: Orchestrating Success
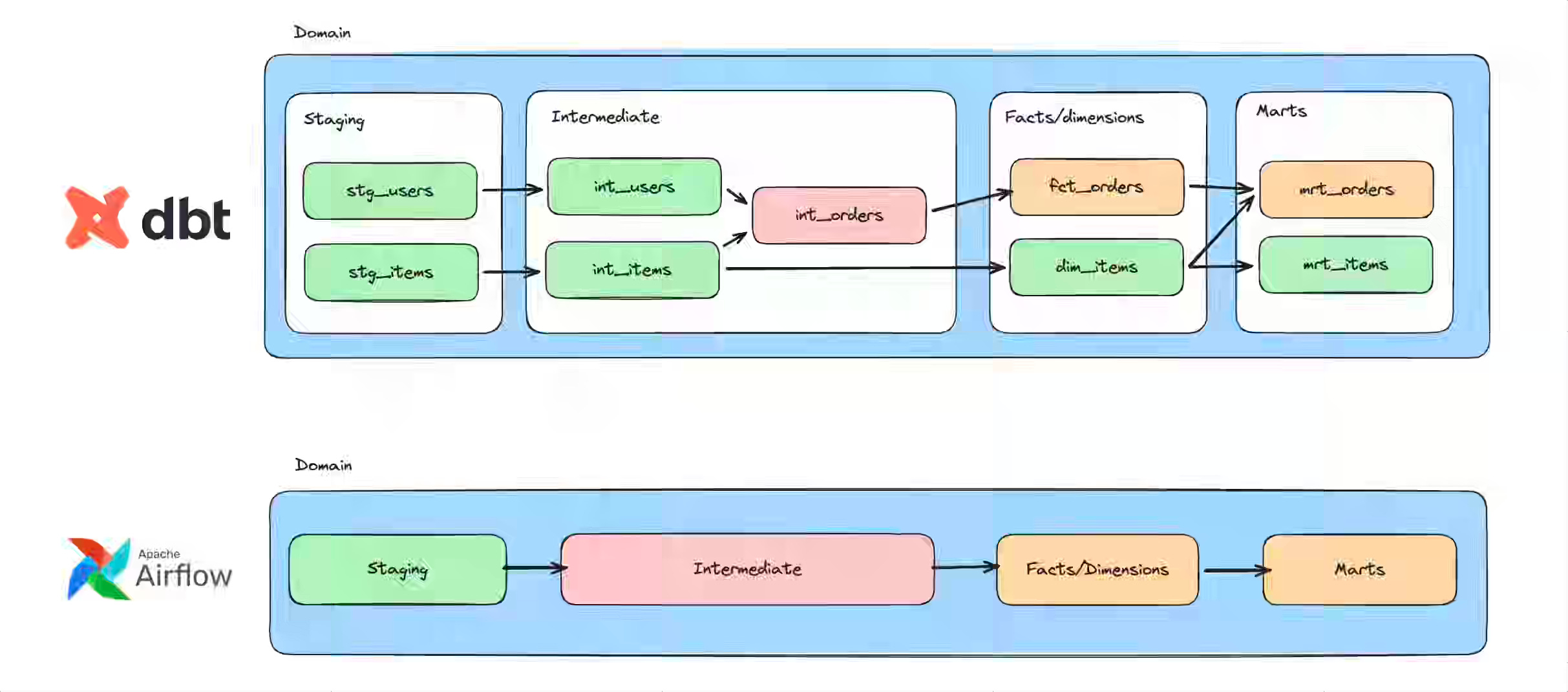
The blog explains how decentralized data pipelines created coordination bottlenecks, shifting dependencies from code to endless meetings, and running dbt layers via Airflow lacked granularity, causing entire layers to fail when a single model broke. The team built an automated DAG generator that reads the dbt manifest to create task-per-model setups in Airflow, paired with an Asset Registry that manages cross-domain dependencies using ExternalTaskSensor and automatically marks waiting sensors as satisfied when upstream tasks finish late, eliminating manual restarts.
https://vinted.engineering//2025/12/29/orchestrating-success/
Tim Castillo: How I Structure My Data Pipelines
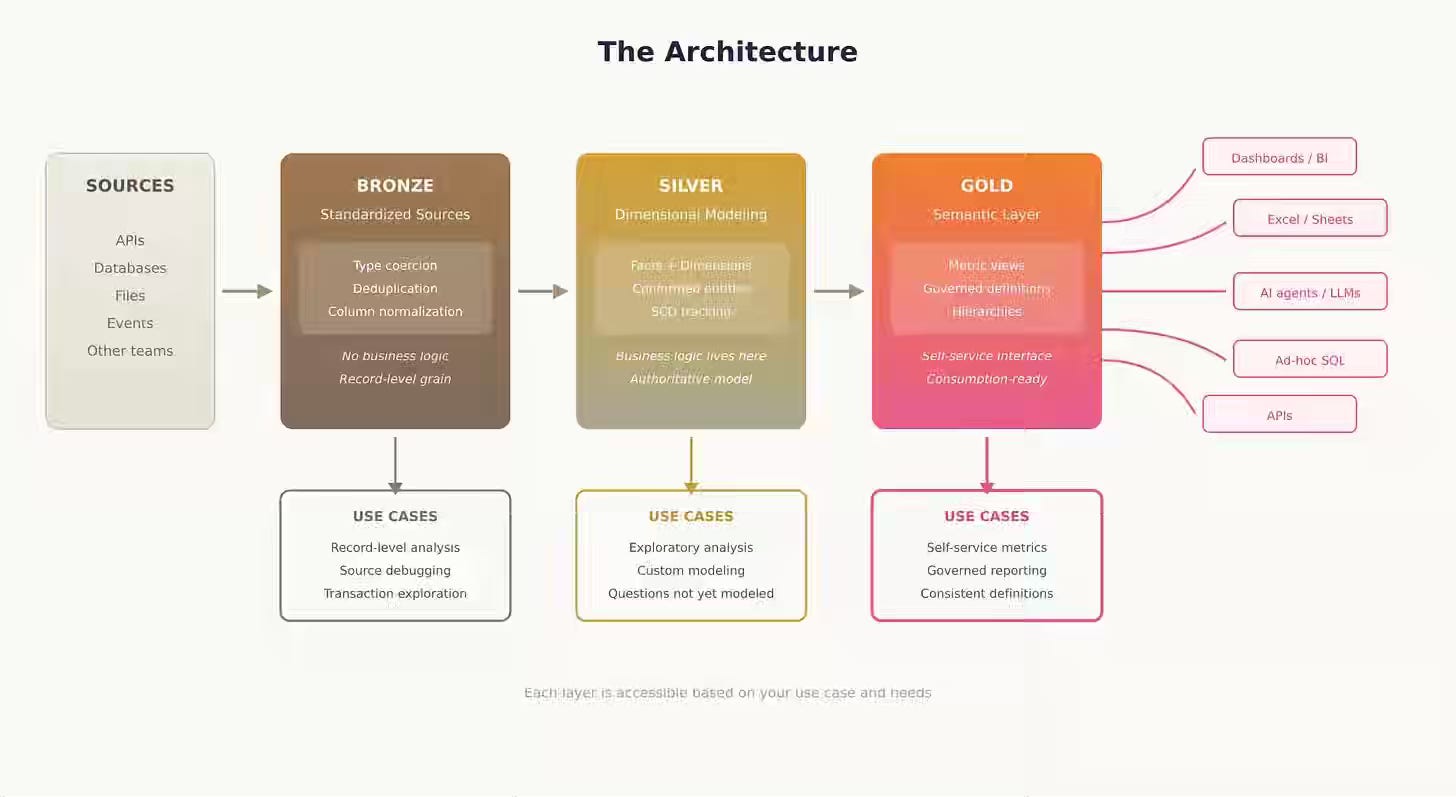
The author proposes resolving Medallion Architecture's ambiguity by strictly combining it with Kimball dimensional modeling and Semantic Layers, mapping each methodology to specific pipeline layers. The approach defines Bronze for mechanical normalization and type casting without business logic, Silver for Kimball Facts and Dimensions representing authoritative business logic, and Gold as a first-class Semantic Layer using governed Metric Views that serve pre-calculated metrics to business users while allowing data scientists direct SQL access to Silver's full-grain data.
https://loglevelinfo.substack.com/p/how-i-structure-my-data-pipelines
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.