
Data Engineering Weekly #252
The Weekly Data Engineering Newsletter


Best practices for LLM development
LLMs are transforming software development, but integrating them into real projects can be tricky when models don’t understand your codebase, pipelines, or conventions.
Join Dagster on January 27th for a practical look at data engineering best practices, common pitfalls, and live demos of LLM developments.
Foundation Capital: AI’s trillion-dollar opportunity: Context graphs
Agents are cross-system and action-oriented. The UX of work is separating from the underlying data plane. Agents become the interface, but something still has to be canonical underneath.
This will be a core construct of the next evolution of data engineering. A scalable data infrastructure that gives a unified view of the system of records and the analytical data, past decision traces, and a system of record that accepts high concurrent modifications. The promise of agents holds, but I don’t think our underlying infrastructure is ready for it.
https://foundationcapital.com/context-graphs-ais-trillion-dollar-opportunity/
ThoughtWorks: How to build the organizational muscle needed to scale AI beyond PoCs
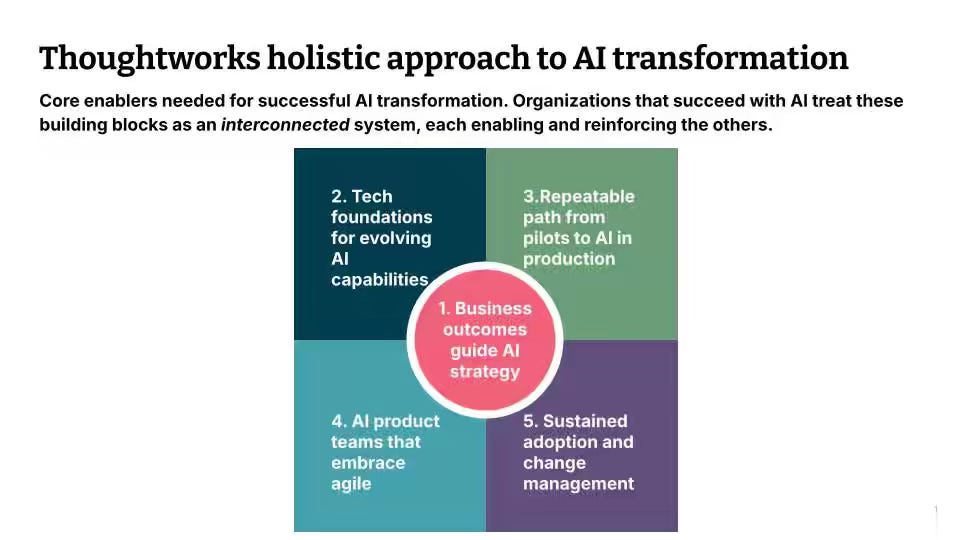
Thoughtworks argues that AI initiatives fail to scale beyond pilots because organizations hit compliance hurdles, data silos, and lack stakeholder engagement—problems that require building "organizational muscle" rather than buying technology solutions. The article recommends a "thin slice" approach that addresses five building blocks simultaneously for a single use case: starting with clear business outcomes instead of technology, building tech platforms incrementally based on concrete needs, creating repeatable MLOps paths to production through cross-functional product teams, and investing in AI literacy and human-collaborative tool design to drive sustained adoption.
https://www.thoughtworks.com/insights/articles/how-to-build-organizational-muscle-needed-to-scale-AI
Sharon Campbell-Crow: Multi-Agent Systems: The Architecture Shift from Monolithic LLMs to Collaborative Intelligence
Developers are moving away from monolithic LLM “God Prompts” toward multi-agent systems because single models suffer from context limits and lack built-in self-critique. Multi-agent systems use specialized, sometimes adversarial agents, improving factual accuracy by up to 23%.
The article describes four architectures—LangGraph for graph-based control and auditability, AutoGen for event-driven distributed agents, CrewAI for role-based content workflows, and OpenAI Swarm for stateless, high-scale routing—along with production patterns such as planner–executor separation, memory streams for relevance, and deferred execution to manage cost and latency.
https://www.comet.com/site/blog/multi-agent-systems/
Sponsored: The Scaling Data Teams Guide

Building and scaling a data platform has never been more important or more challenging. Whether you’re just starting to build a data platform or leading a mature data organization, this guide will help you scale your impact, accelerate your team, and prepare for the future of data-driven products.
Learn how real data teams, from solo practitioners to enterprise-scale organizations, build.
Ly: Building a multi-agent pipeline for NL-to-SQL analytics
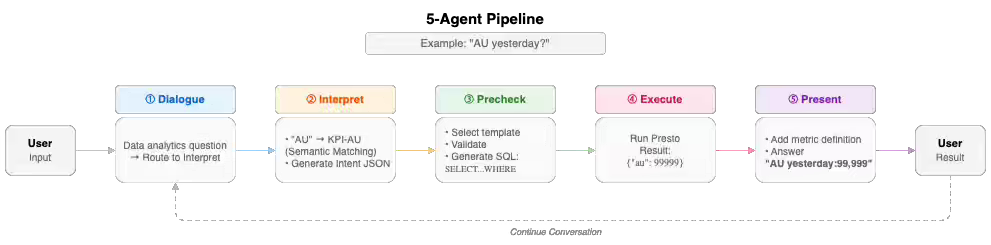
LY Corp writes about migrating from a monolithic MCP-based NL-to-SQL system to a five-agent pipeline after encountering execution coupling, single-point-of-failure debugging, and oversized prompt contexts.
The new design adopts a Swarm-style orchestration model in which specialized agents handle routing, intent parsing, validation, SQL generation, query execution, and result presentation, using strict JSON interfaces and a tightly scoped context.
Preprocessed domain-specific data marts with normalized action units further reduce hallucinations by helping agents reliably map intents to the correct tables and columns.
https://techblog.lycorp.co.jp/en/building-a-multi-agent-pipeline-for-nl-to-sql-analytics
Vinted: Building a Global, Event-Driven Platform: Our Ongoing Journey
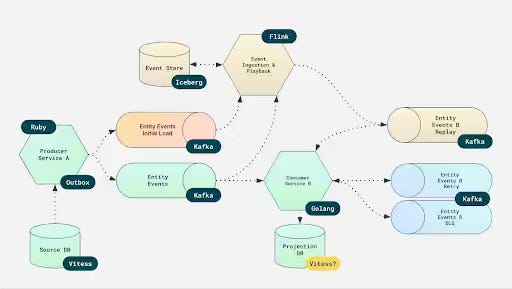
Vinted Engineering describes migrating from a monolithic system handling 150k requests per second to a global, event-driven platform processing over 300k requests per second. The redesign applies Domain-Driven Design across nearly 300 domains and uses Saga-based orchestration to coordinate multi-step workflows, centralizes writes, and globally replicates read-only projections via event streams. Separating read and write paths enables low-latency features such as feeds and search to be close to users, but requires teams to design for eventual consistency, retries, and out-of-order events rather than assuming immediate consistency.
https://vinted.engineering/2026/01/09/building-global-event-driven-platform-part-1/
https://vinted.engineering//2026/01/09/building-global-event-driven-platform-part-2/
Lyft: Lyft’s Feature Store: Architecture, Optimization, and Evolution
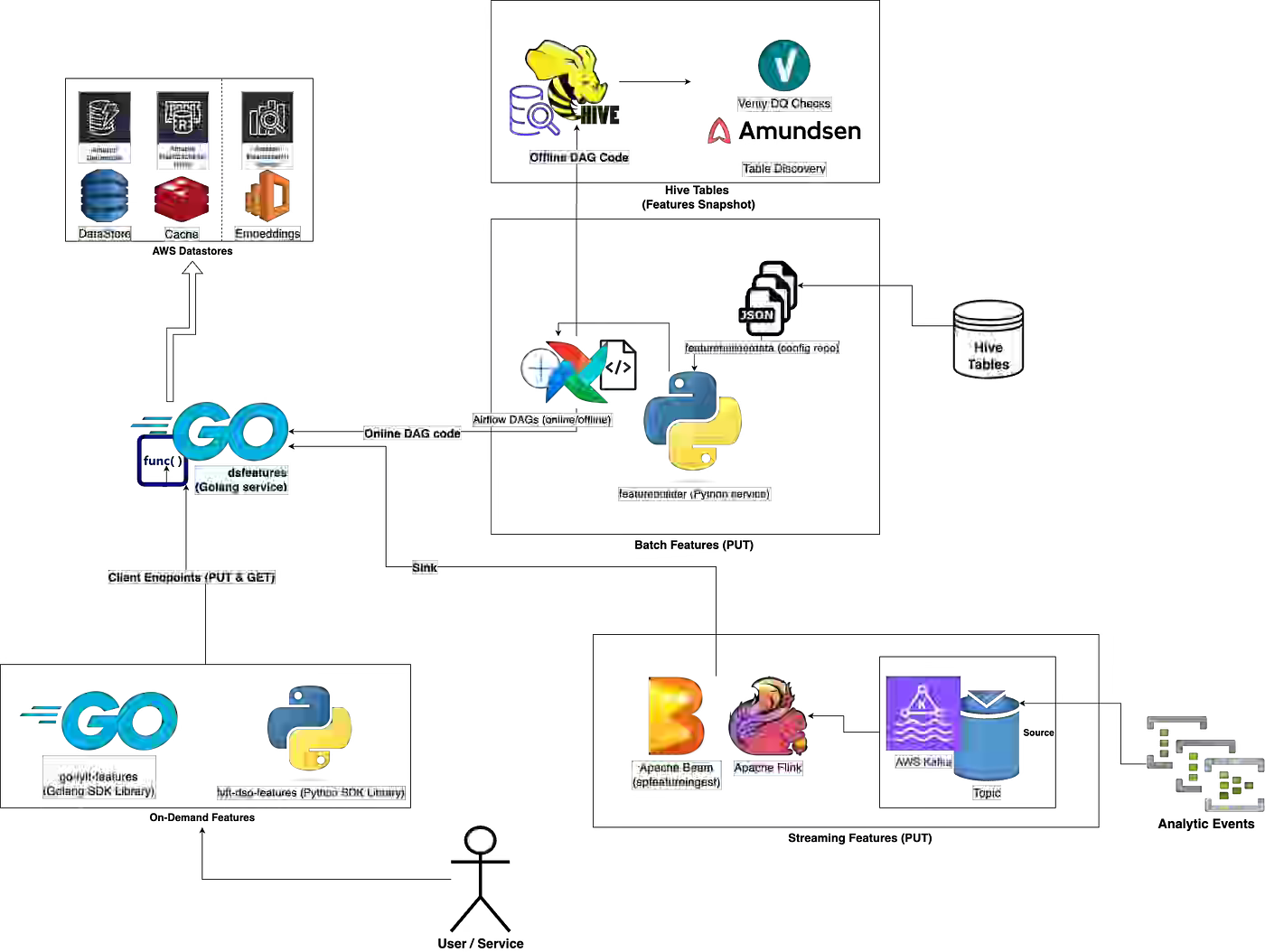
Lyft writes about a centralized Feature Store that maintains consistency between offline training and online inference across batch, streaming, and real-time serving. Batch features run on Spark SQL with auto-generated Airflow DAGs and Hive storage, streaming features use Apache Flink with Kafka and Kinesis, and online serving relies on DynamoDB with a ValKey write-through cache for low-latency access.
https://eng.lyft.com/lyfts-feature-store-architecture-optimization-and-evolution-7835f8962b99
Zeta Global: Zeta’s Lakehouse Journey: A Composable, Scalable, and Federated Architecture
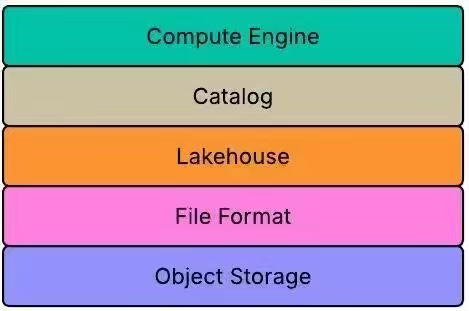
Zeta Global writes about moving to a composable, federated Lakehouse architecture to integrate a highly heterogeneous data landscape that traditional warehouses could not unify. The platform standardizes on object storage with Apache Iceberg for transactional guarantees. It uses AWS S3 Tables with AWS Glue as the control plane, allowing Spark, Snowflake, and Trino to operate on shared datasets.
Google: Developer’s guide to multi-agent patterns in ADK
Similar to the typical Enterprise Integration Pattern, the multi-agent integration pattern is emerging as agent architecture becomes more widely adopted. Google lists about 8 patterns emerging in multi-agent systems.
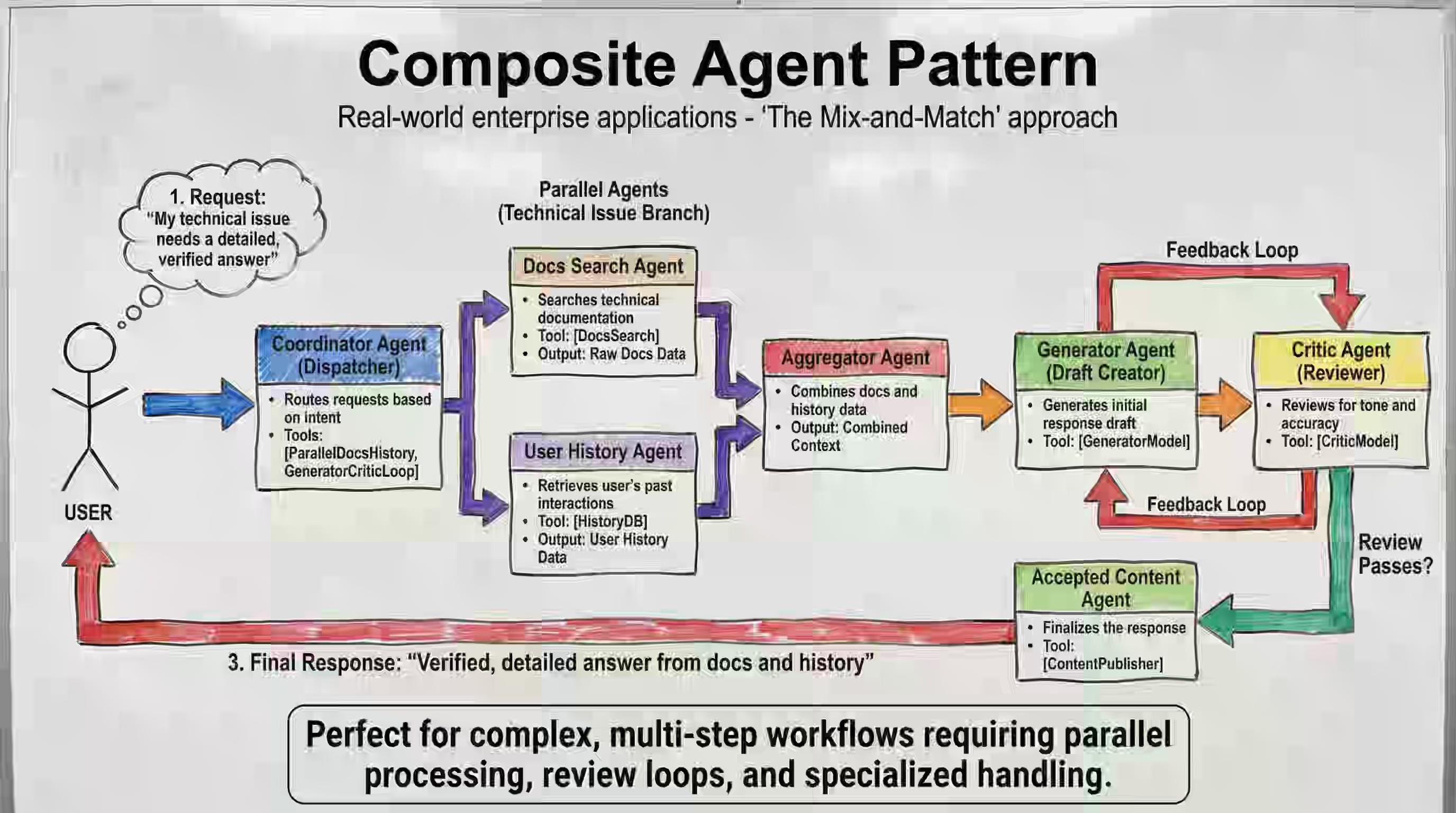
Sequential Pipeline
Coordinator/Dispatcher
Parallel Fan-Out/Gather
Hierarchical Decomposition
Generator and Critic
Iterative Refinement
Human-in-the-loop
Composite Patterns
https://developers.googleblog.com/developers-guide-to-multi-agent-patterns-in-adk/
Ashpreet B: Memory: How Agents Learn
Most AI agents do not truly learn because they reset after each session.
The author presents a “GPU-poor continuous learning” approach in which agents store and retrieve successful patterns from databases rather than retrain models, demonstrated using the agno library with SQLite for session context, a memory manager for user data, and vector databases with human review to curate high-quality learned memories.
https://www.ashpreetbedi.com/articles/memory
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.