
Data Engineering Weekly #253
The Weekly Data Engineering Newsletter


Modernize your data platform for the age of AI.
While 75% of enterprises experiment with AI, traditional data platforms are becoming the biggest bottleneck. Learn how to build a unified control plane that enables AI-driven development, reduces pipeline failures, and cuts complexity.
- Transform from Big Complexity to AI-ready architecture
- Real metrics from organizations achieving 50% cost reductions
- Introduction to Dagster Components: YAML-first pipelines that AI can build
Lance Martin: Effective Agent Design
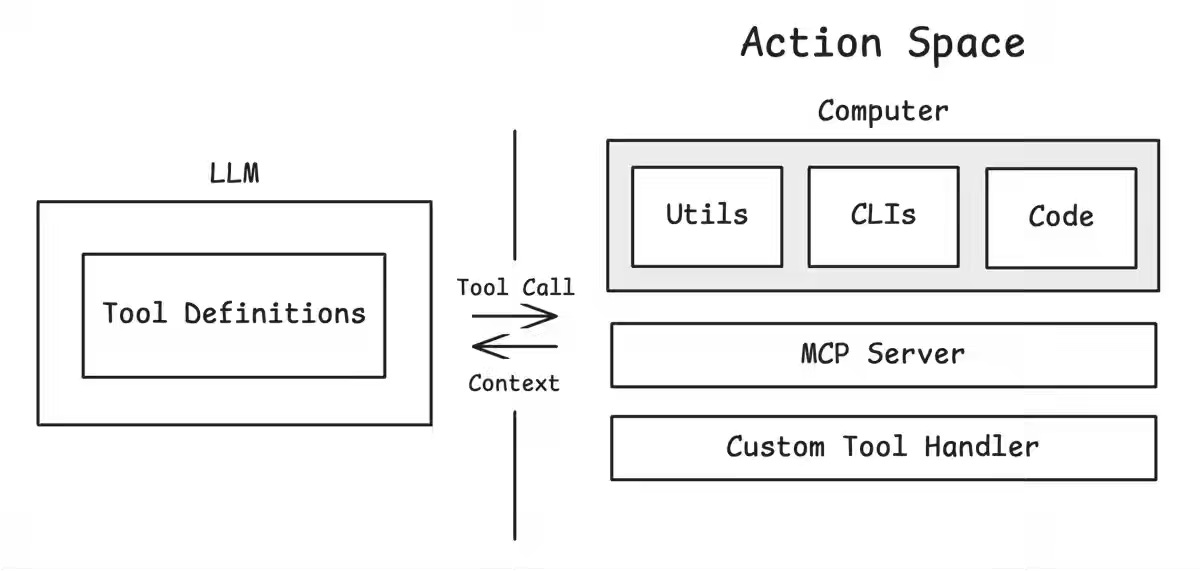
An effective agent design largely boils down to context management. The author proposes design patterns to effectively build an agent, including providing filesystem and shell access to the agents, using a multi-layer action space, and offloading memory to a filesystem rather than keeping everything in the context window.
https://x.com/RLanceMartin/status/2009683038272401719
Médéric Hurier: Architecting the AI Agent Platform: A Definitive Guide

The industry is shifting from simple LLMs and RAG (Retrieval-Augmented Generation) to AI Agents. The author proposes a 7-layer logical container architecture to build an AI agent platform. The 7-layer container architecture organizes the AI agent platform into logical levels—Interaction, Development, Core, Foundation, Information, Observability, and Trust—to manage the complexity of building production-grade systems. The structure enforces a separation of concerns, ensuring that user interfaces, execution engines, data management, and security governance are handled independently yet cohesively.
https://mlops.community/architecting-the-ai-agent-platform-a-definitive-guide/
Tidepool: Stop using natural language interfaces
The user experience of chatbot-driven enterprise application flow is taking center stage in the product design. The author argues that pure natural language interfaces are inefficient due to the high latency of LLMs (often taking tens of seconds to respond). Instead, the author proposes a hybrid approach in which the LLM dynamically generates structured Graphic User Interfaces (GUIs)—such as popups with checkboxes, sliders, and forms—to interact with the user.
https://tidepool.leaflet.pub/3mcbegnuf2k2i
Sponsored: Best practices for LLM development

LLMs are transforming software development, but integrating them into real projects can be tricky when models don’t understand your codebase, pipelines, or conventions.
Join Dagster on January 27th for a practical look at data engineering best practices, common pitfalls, and live demos of LLM developments.
Microsoft: SQL Telemetry & Intelligence – How we built a Petabyte-scale Data Platform with Fabric
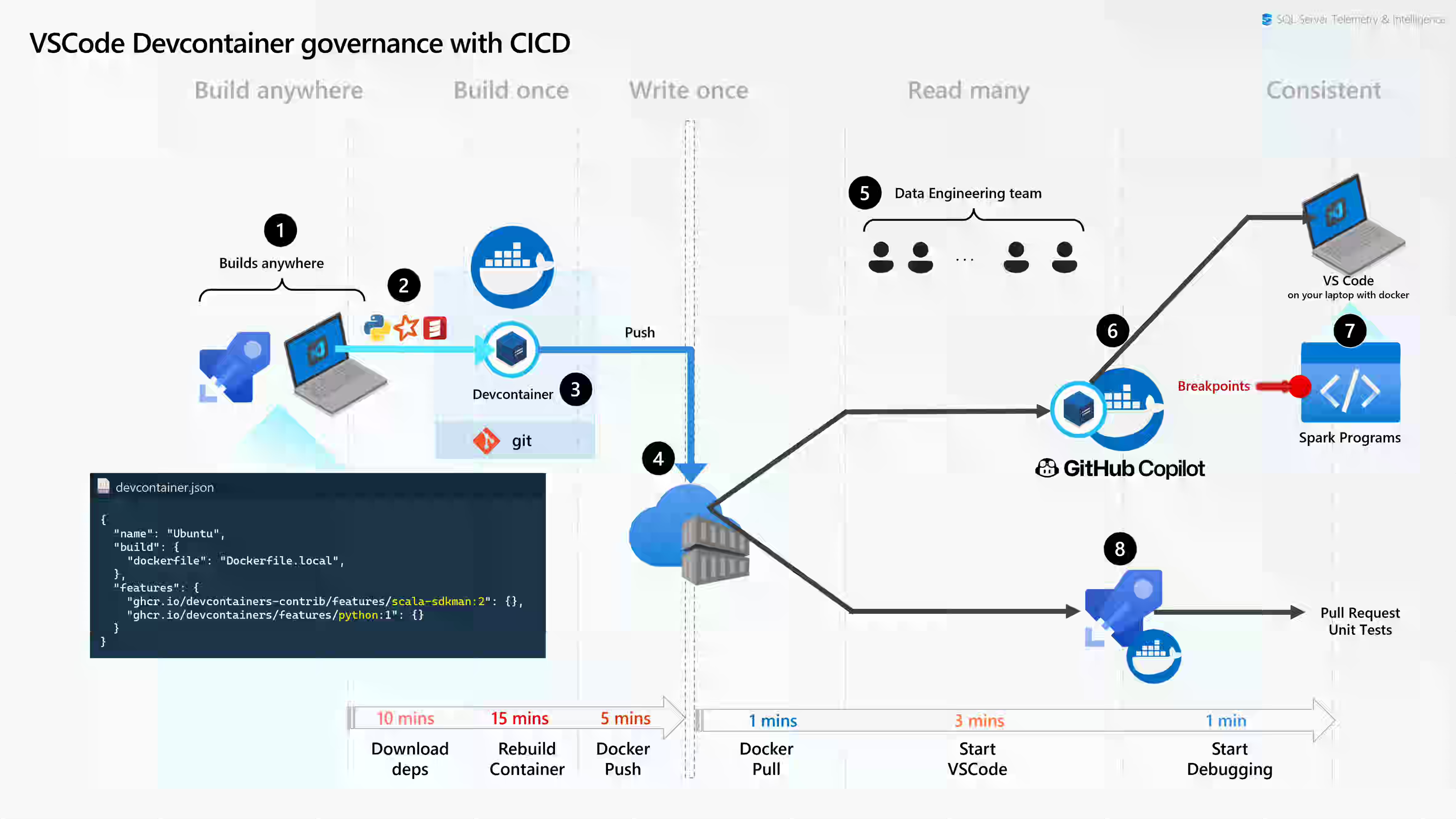
Microsoft writes about how the SQL Telemetry & Intelligence (T&I) team built a 10+ petabyte Data Lake using Microsoft Fabric, processing real-time data from global SQL Server engines. The focus on CI/CD pipelines, testing optimization, local development, and data quality & observability is an interesting system read.
Vikram Sreekanti & Joseph E. Gonzalez: Data is your only moat
The ease of adopting a tool enables data collection, which in turn creates a defensive advantage hard for competitors to replicate. The authors make a solid argument that, for enterprise applications, the moat isn’t just about volume but about specificity. By deeply integrating with a company’s legacy systems, a product gathers data on exactly how that specific customer works. This creates “stickiness”—replacing the tool becomes difficult because a new competitor wouldn’t have that accumulated knowledge of the company’s unique workflows.
https://frontierai.substack.com/p/data-is-your-only-moat
Uber: Apache Hudi™ at Uber: Engineering for Trillion-Record-Scale Data Lake Operations
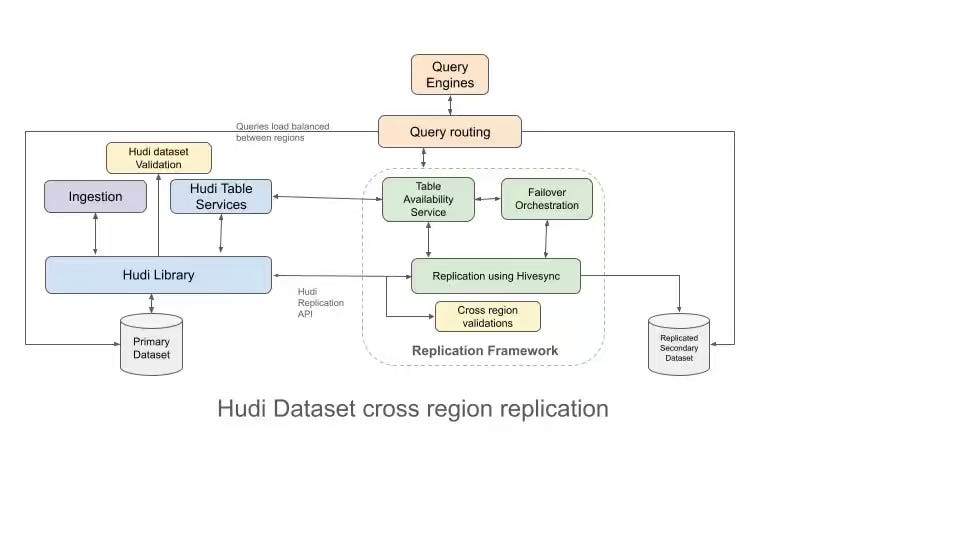
Uber writes about the criticality of Apache Hudi in their overall data lake operations, enabling the management of trillion-record ingestion. Uber highlighted the addition of record indexes, Which Enable O(1) record lookups and allow efficient updates on tables with hundreds of billions of rows. Personally, this is a pretty cool feature from Apache Hudi.
https://www.uber.com/en-IN/blog/apache-hudi-at-uber/
Etsy: How Etsy Uses LLMs to Improve Search Relevance
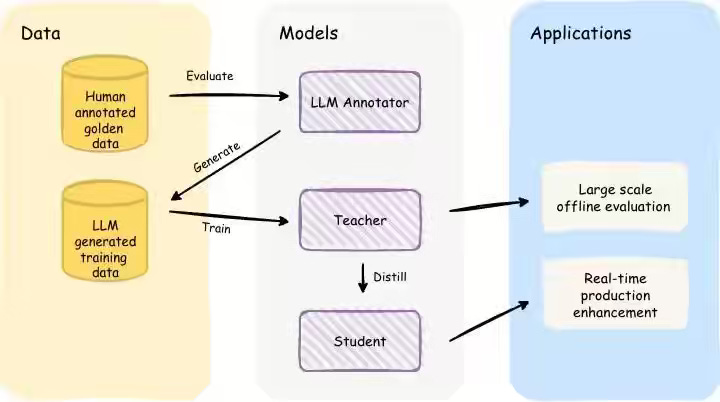
Etsy writes about upgrading its search capabilities by using LLMs to focus on semantic relevance, which prioritizes understanding a buyer's true intent over simple click data. Etsy uses high-quality human and LLM annotations train a lightweight "student" model that runs in real time. This model actively filters and ranks search results, successfully increasing the percentage of fully relevant listings shown to shoppers.
https://www.etsy.com/codeascraft/how-etsy-uses-llms-to-improve-search-relevance
AWS: How Slack achieved operational excellence for Spark on Amazon EMR using generative AI

Slack writes about reaching operational excellence by replacing manual debugging with a custom monitoring framework that captures over 40 granular metrics from its EMR clusters. Slack exposed this data to generative AI models via Amazon Bedrock and a Model Context Protocol (MCP) server, enabling tools like Claude Code to analyze performance and suggest optimal configurations automatically. This automated system reduced compute costs by 30–50% and slashed developers' time spent tuning jobs by over 90%.
Agoda: How Agoda Enhanced the Uptime and Consistency of Financial Metrics
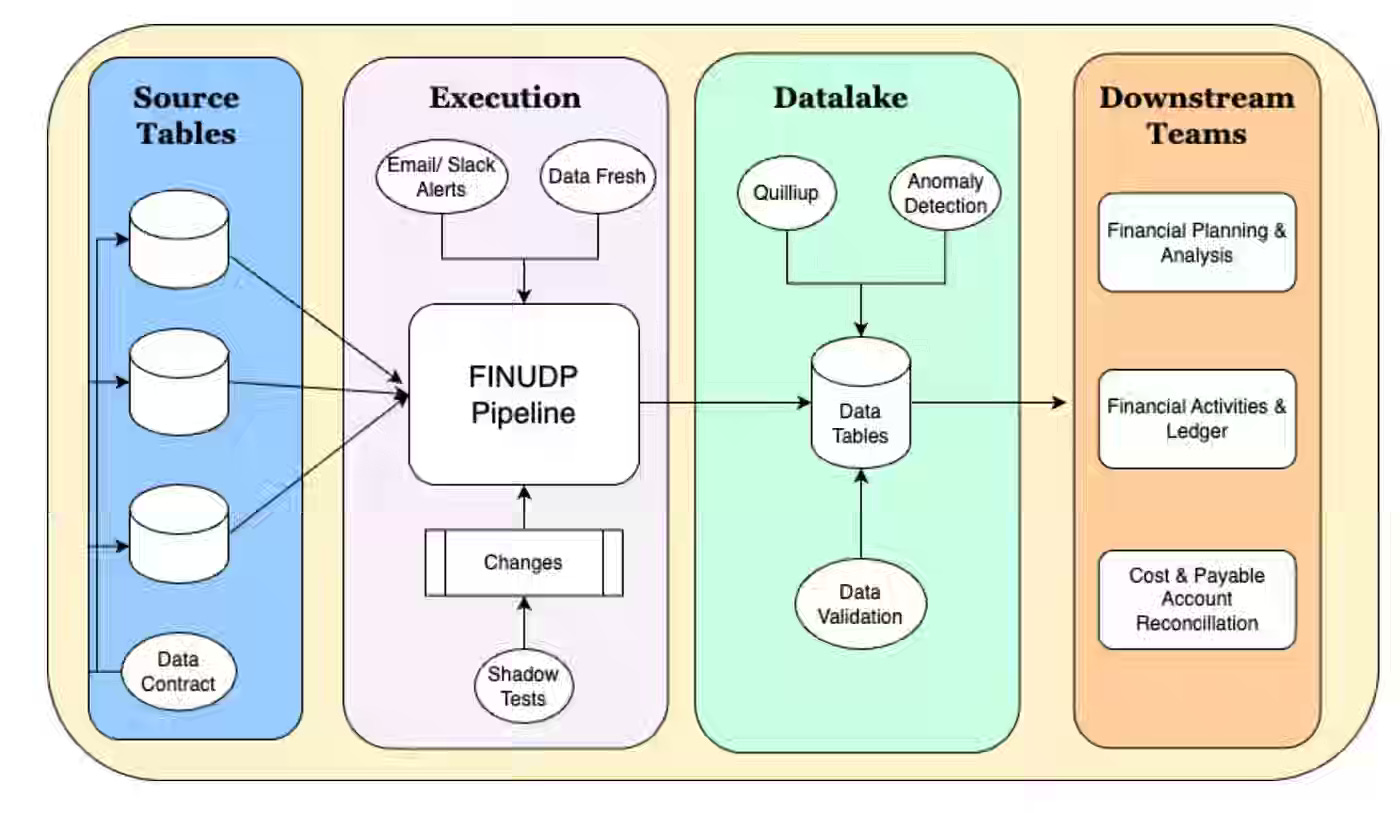
Agoda writes about addressing inconsistencies in its financial reporting by consolidating multiple disjointed data pipelines into a single Financial Unified Data Pipeline (FINUDP) built on Apache Spark. Agoda talks about approaches to ensure reliability and accuracy, including automated freshness monitoring, shadow testing for all code changes, and strict data contracts with upstream providers.
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.