
Data Engineering Weekly #254
The Weekly Data Engineering Newsletter


LLMs are transforming software development, but integrating them into real projects can be tricky when models don’t understand your codebase, pipelines, or conventions.
Join Dagster on Tuesday, January 27th, for a practical look at data engineering best practices, common pitfalls, and live demos of LLM developments.
Debate Alert: Ontology vs Context Graphs vs Semantic Layers: What Will AI Need in 2026?
What are Context Graphs, and why are builders, VCs, and operators calling it the next $1T opportunity? Join The Great Data Debate to get answers to questions the data & AI industry is so curious about right now:
Where does context materialize in practice? Who owns context as meaning evolves?
Semantic layers, ontologies, context graphs - what should data teams build in 2026?
Where should that context live: in the warehouse, inside agents, or in a dedicated context layer?
Join Bob Muglia(former CEO, Snowflake), Karthik Ravindran(GM, Microsoft), Tony Gentilcore(Co-founder, Glean), Prukalpa Sankar(Co-founder, Atlan), and Jaya Gupta(Foundation Capital) for an open discussion on what data teams should actually build next.
Register: Feb 5 · Virtual · 11 AM ET
Mark Rittman: Why We’ve Tried to Replace Data Analytics Developers Every Decade Since 1974
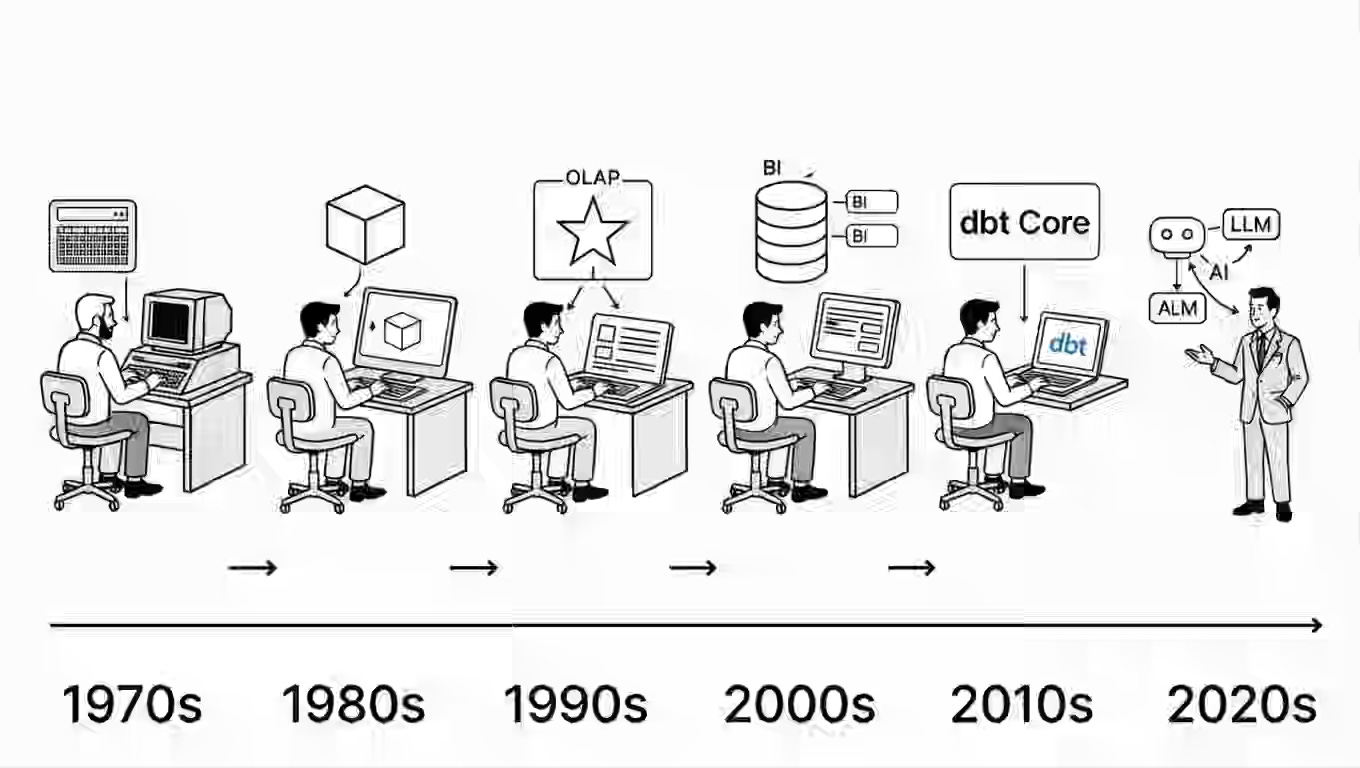
Perhaps the recurring dream of replacing data analytics developers isn’t a mistake. Perhaps it’s a necessary optimism that drives tool creation.
Developers are always hungry for the next big abstractions. The article is an excellent reminder that Semantic layers didn’t make metric definition trivial, but they made it more maintainable. Self-service BI didn’t remove IT from the equation, but it expanded who could explore data.
Alibaba: AI Trends Reshaping Data Engineering in 2026
Alibaba writes that data engineering is evolving from data movement to building intelligent, autonomous systems in which data serves as a continuously learning capability. The field is getting reshaped by unified data–AI platforms, self-healing operations, context engineering for AI agents, real-time and multimodal pipelines, and privacy-first approaches such as synthetic data and federated learning.
https://www.alibabacloud.com/blog/ai-trends-reshaping-data-engineering-in-2026_602816
Thoughtworks: The state of data mesh in 2026: From hype to hard-won maturity
As with any scientific theories, it starts with a half-finished, widely debated theory and matures over time. Data Mesh and Data Contract are two such theories; though widely adopted by many companies internally, they still have much room to mature. ThoughtWorks writes an excellent article about the current state of data mesh adoption.
Sponsored: The AI Modernization Guide

While 75% of enterprises experiment with AI, traditional data platforms are becoming the biggest bottleneck. Learn how to build a unified control plane that enables AI-driven development, reduces pipeline failures, and cuts complexity.
- Transform from Big Complexity to AI-ready architecture
- Real metrics from organizations achieving 50% cost reductions
- Introduction to Dagster Components: YAML-first pipelines that AI can build
Anthropic: Demystifying evals for AI agents
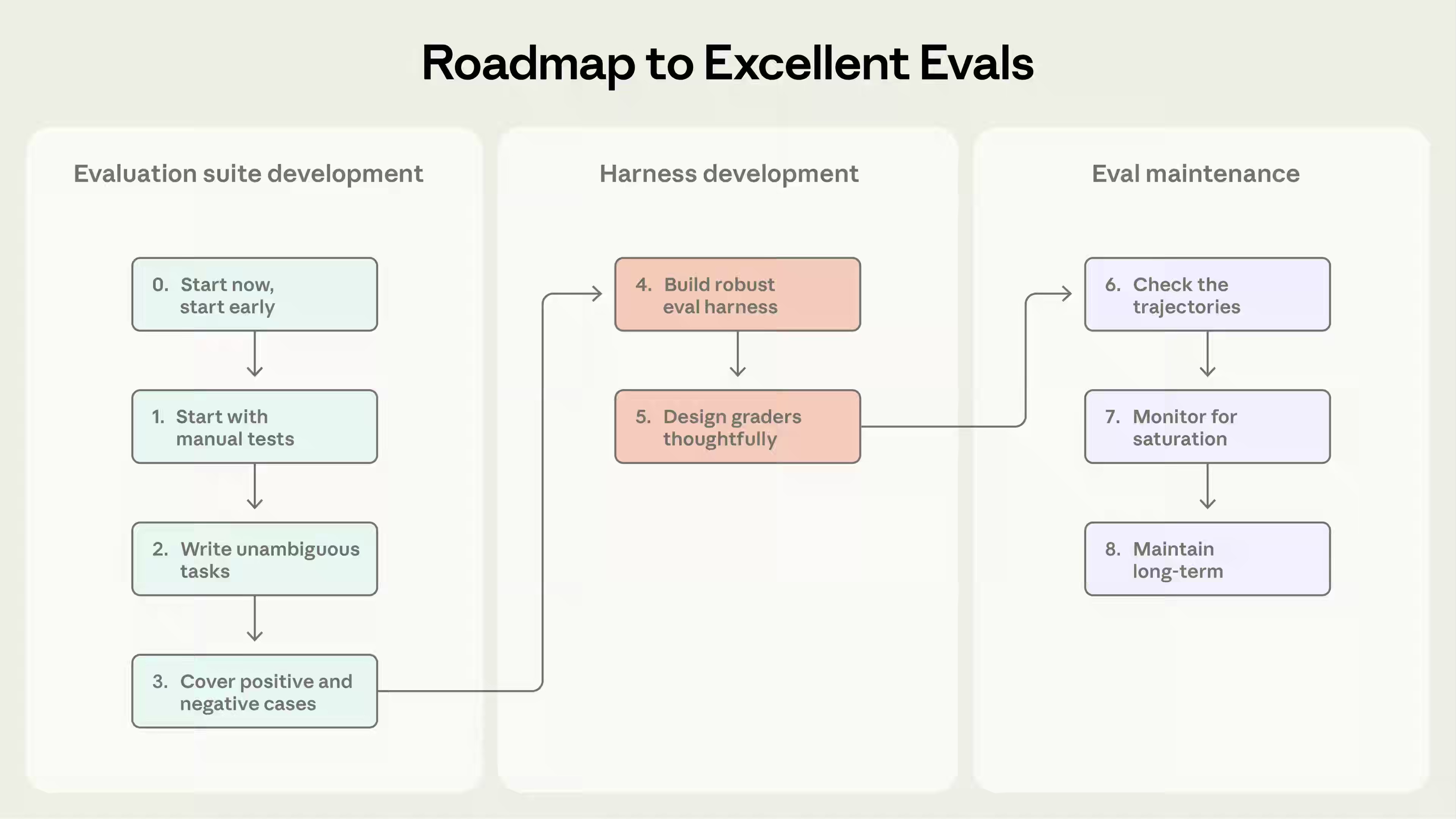
AI agent development faces evaluation gaps as systems evolve from single-turn prompts to autonomous, multi-step tool use. The article defines agent evals around task outcomes rather than transcripts, using repeated trials, hybrid grading methods, and reliability metrics such as pass@k and pass^k to capture non-deterministic behavior. Starting with small, failure-driven task sets and layering automated evals with production monitoring and human review enables teams to iterate faster, adopt new models safely, and maintain consistent agent reliability.
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
Booking.com: AI Agent Evaluation - practical tips at Booking.com
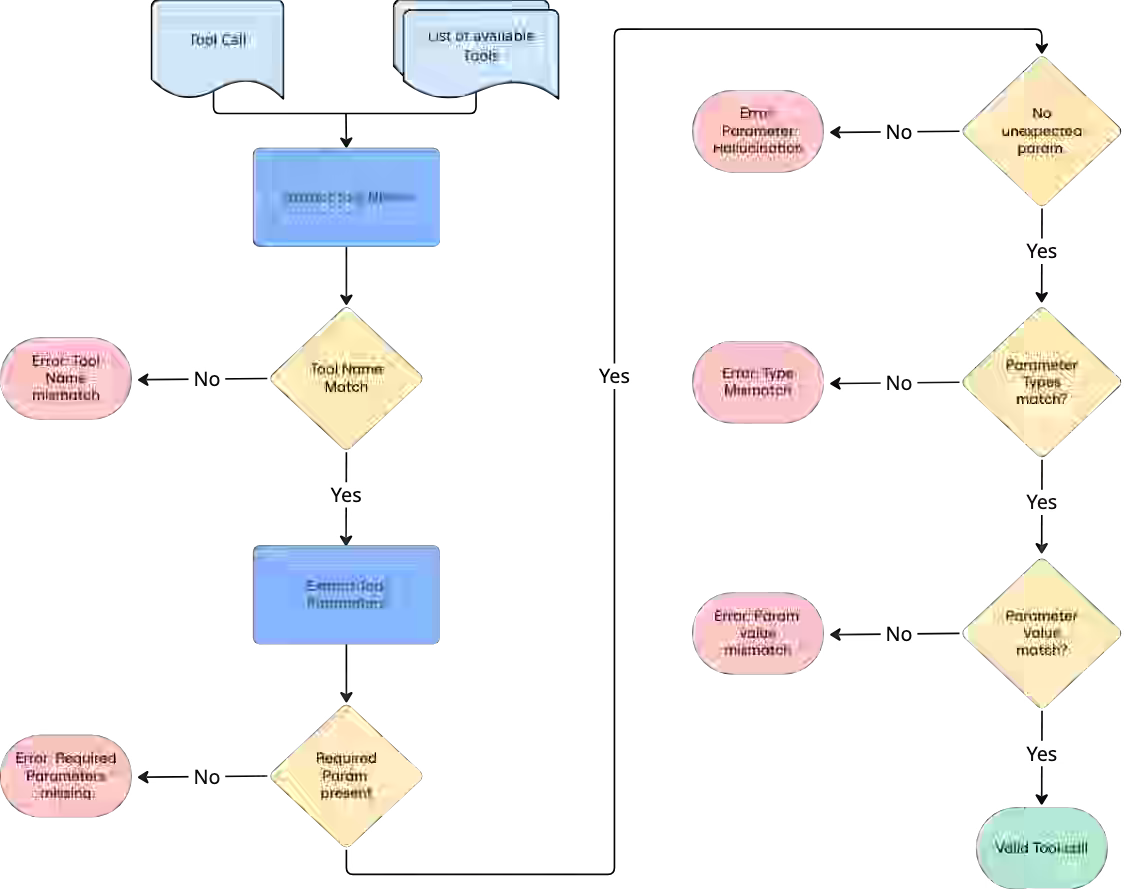
Evaluating autonomous AI agents is challenging because simple prompt-based metrics fail to capture whether user intents are reliably fulfilled. The article presents a dual approach combining black-box evaluation focused on task completion using LLM-as-a-judge with glass-box evaluation that inspects tool selection, syntax, and intermediate agent decisions. Benchmarking agents against simpler baselines and measuring consistency across repeated queries helps teams justify added complexity, control costs, and assess production readiness.
https://booking.ai/ai-agent-evaluation-82e781439d97
LinkedIn: Reimagining LinkedIn’s search tech stack
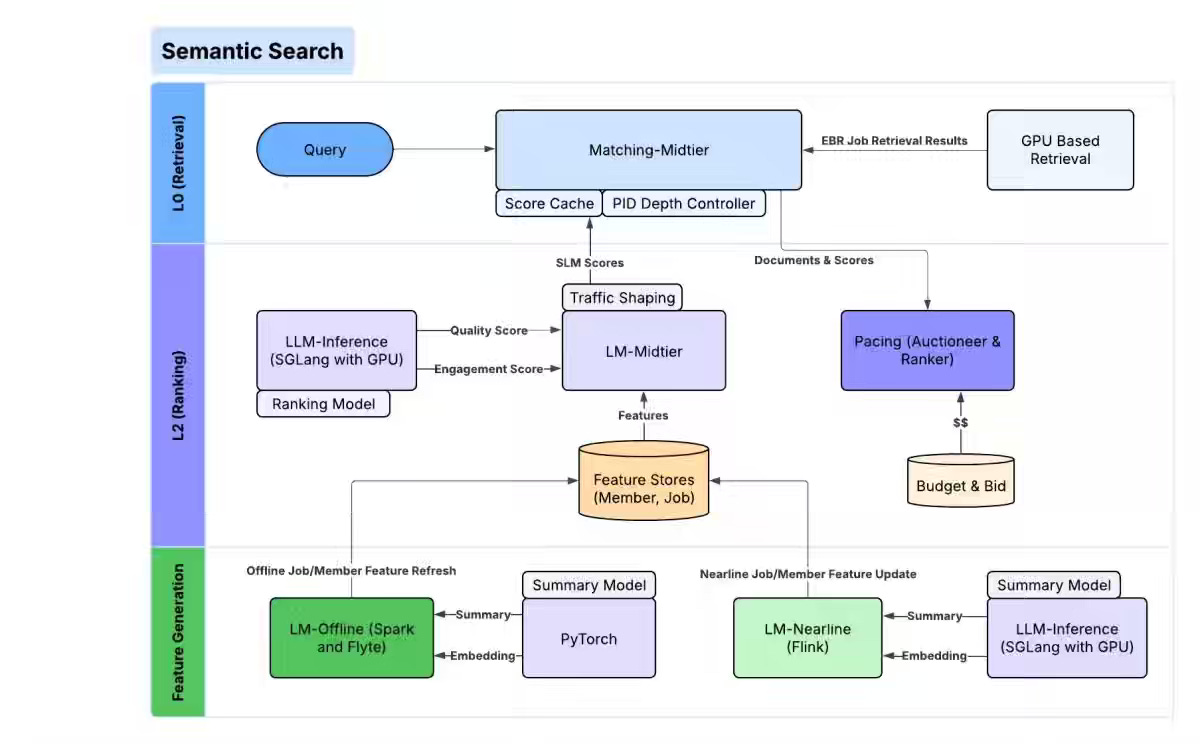
Traditional keyword-based search struggles to understand user intent, handle natural language queries, and bridge vocabulary gaps at scale. The article describes LinkedIn’s shift to a semantic search stack built on LLM-based query understanding, embedding-based retrieval, and small-language-model ranking, supported by LLM judges, model distillation, and continuous relevance measurement.
https://www.linkedin.com/blog/engineering/search/reimagining-linkedins-search-stack
Stefan Kecskes: Kafka Dead Letter Queue Triage: Debugging 25,000 Failed Messages
The DLQ pattern in Event processing is well-known and somewhat widely adopted. However, I’m delighted to read about what happens after a message enters a failed state for the first time. Discard or fix it? The author provides practical tips for analyzing DLQ messages, cautions, and resiliency practices before rebroadcasting the message.
https://skey.uk/post/kafka-dead-letter-queue-troubleshooting-guide/
Teads: The End of the Dashboard as We Know It: Designing for Insight in the Age of AI
Static dashboards fail to support decision-making because they require users to interpret large volumes of data manually. The article argues for AI-driven dashboards that act as proactive, conversational assistants by focusing on scenarios, personalized insights, and transparent recommendations rather than fixed screens. Measuring success by decisions enabled instead of data displayed reframes dashboards as adaptive systems that guide action and improve human–AI collaboration over time.
Flipkart: High-Risk, High-Scale: Guaranteeing Ad Budget Precision at 1 Million Events/Second
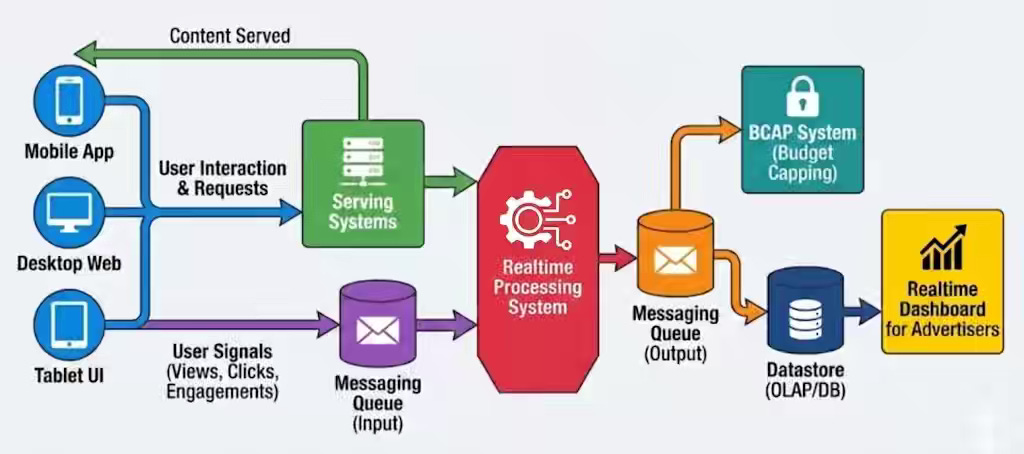
Real-time ad budget enforcement at scale is risky because latency can cause advertiser overspend, revenue loss, and delayed mobile events to be miscounted. The article describes Flipkart Ads’ architecture that separates real-time enforcement from batch settlement using Apache Flink, stateful deduplication with RocksDB, and event-time processing with watermarking. Prioritizing availability over strict consistency enables the system to process nearly one million events per second while ensuring accurate budget capping and final financial reconciliation.
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.