
Data Engineering Weekly #258
The Weekly Data Engineering Newsletter


AI is moving fast. Is your data platform ready?
AI is reshaping how data teams operate. But legacy pipelines, brittle workflows, and fragmented tooling weren’t designed for this shift.
Learn how leading teams are future-proofing their infrastructure before AI demands overwhelm it.
Download the AI Modernization Guide
Garry Tan: Half the AI Agent Market Is One Category. The Rest Is Wide Open
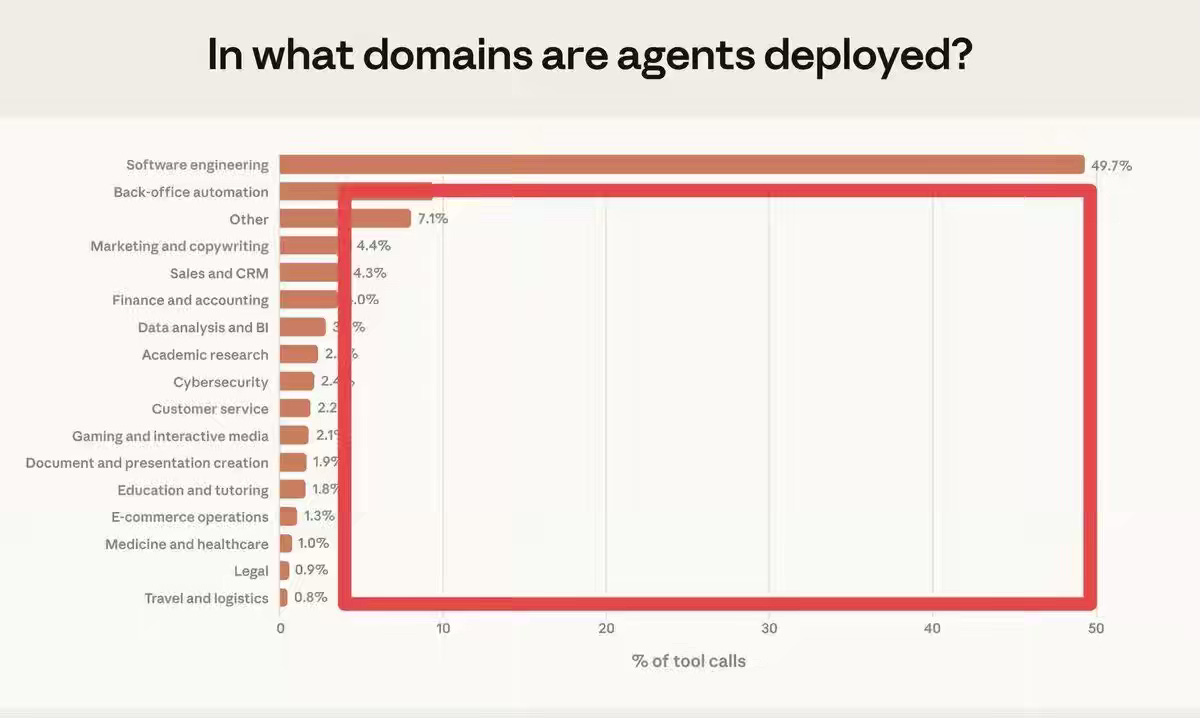
AI Agents thrive in RL environments with a verifiable target and quick feedback. Software manufacturing is a perfect model for such an environment, but the challenge persists in other categories. It will be an exciting decade for software engineering as we build new infrastructure that we never imagined.
https://garryslist.org/posts/half-the-ai-agent-market-is-one-category-the-rest-is-wide-open
LangChain: How to Use Memory in Agent Builder
Agents fail to improve over time when they treat every conversation as stateless and discard learned preferences or workflows. The article explains how LangChain’s Agent Builder implements short-term and long-term memory as a filesystem of Markdown files, enabling persistent instructions and reusable skills. Explicit memory updates, modular skill loading, and direct file editing enable agents to reliably evolve behavior without increasing core prompt complexity.
https://blog.langchain.com/how-to-use-memory-in-agent-builder/
LinkedIn: Scaling LLM-Based ranking systems with SGLang at LinkedIn

LLM-based ranking systems face strict latency and concurrency constraints because they score thousands of items per query without requiring text generation. The article explains how LinkedIn optimized SGLang for prefill-only ranking through batching improvements, scoring-only execution paths, prefix KV reuse, and Python runtime parallelization.
Sponsored: The Scaling Data Teams Guide

More datasets. More pipelines. More AI demands. The old way of doing things doesn’t work at this scale.
This free eBook walks through how teams actually scale sustainably with roles, responsibilities, automation, and patterns that work.
Spotify: Our Multi-Agent Architecture for Smarter Advertising
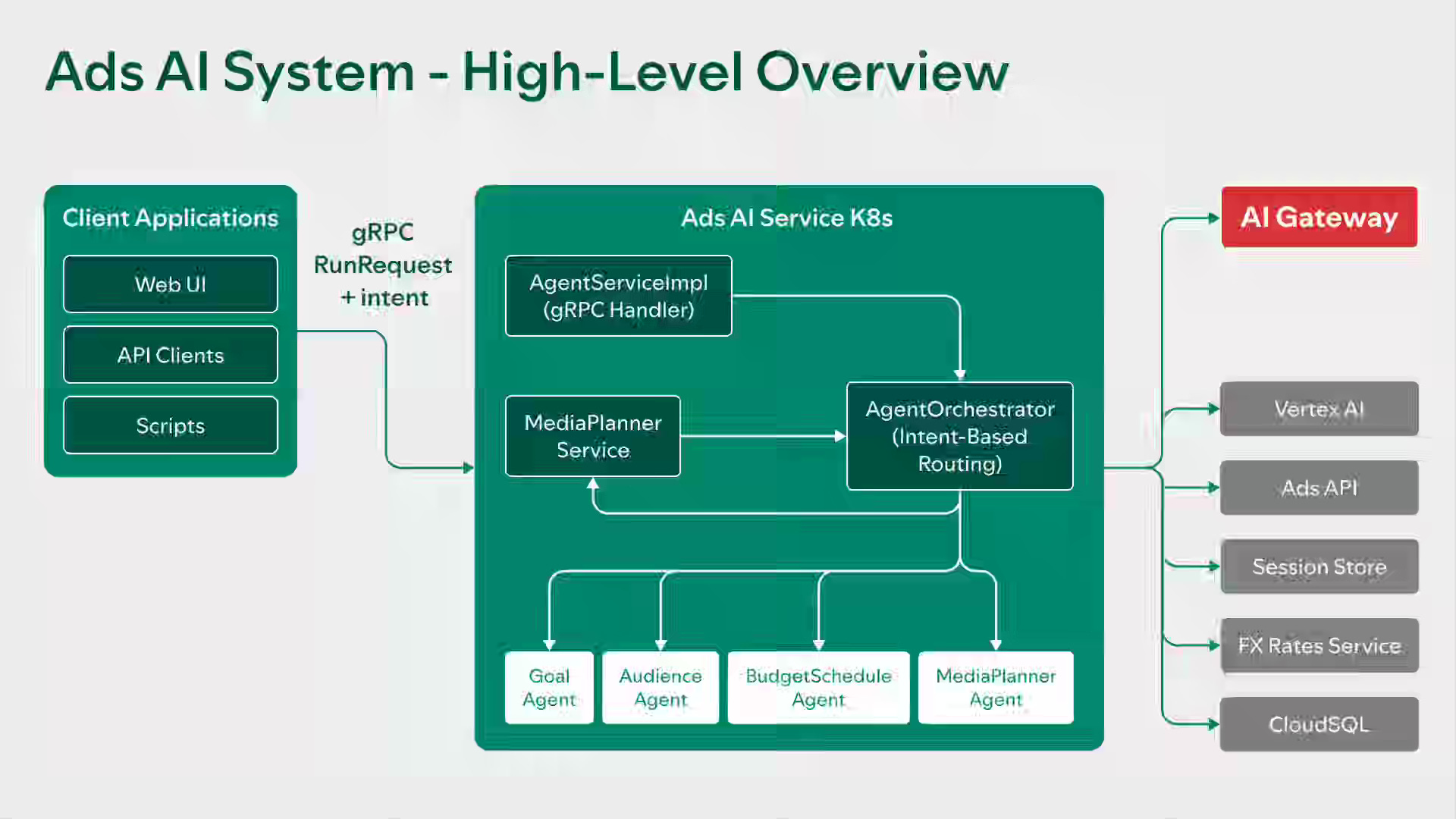
Fragmented decision logic across buying channels prevented Spotify from translating high-level campaign goals into unified execution plans. The article explains how Spotify built Ads AI, a multi-agent orchestration layer with intent routing, specialized resolution agents, and data-grounded media planning using real-time tool integration. The architecture reduced campaign setup time from minutes to seconds, simplified user inputs, and grounded recommendations in historical performance data.
https://engineering.atspotify.com/2026/2/our-multi-agent-architecture-for-smarter-advertising
Uber: Database Federation: Decentralized and ACL-Compliant Hive™ Databases
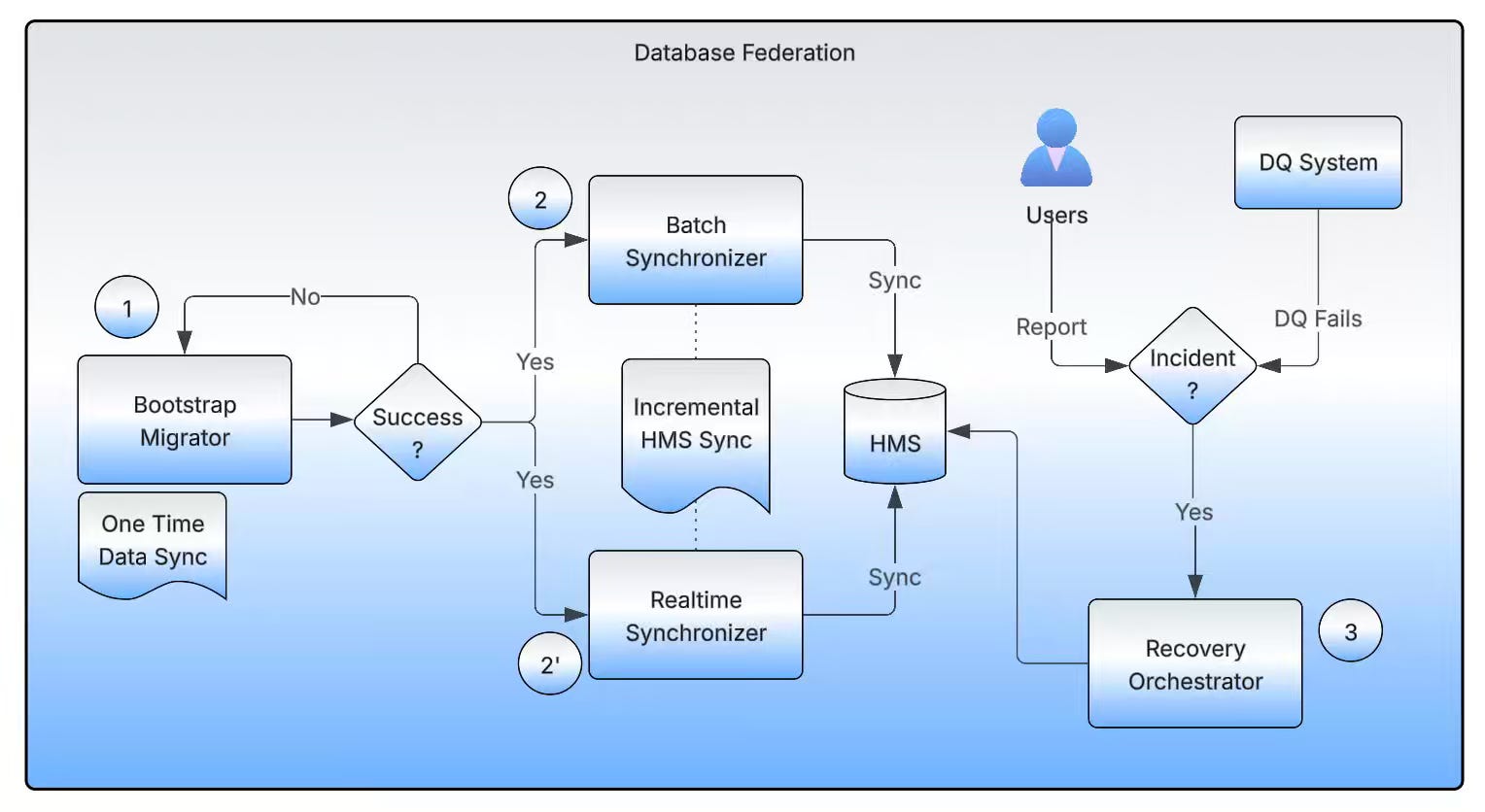
Monolithic Hive warehouses create shared-fate outages, resource contention, and weak governance when thousands of datasets share a single database. The article explains how Uber implemented database federation by reorganizing datasets into domain-specific units, updating Hive Metastore pointers to avoid data duplication, and deploying both real-time and batch synchronizers to maintain consistency. The decentralized architecture improves ACL compliance, strengthens resource isolation, and reclaims storage while enabling zero-downtime migration at the petabyte scale.
https://www.uber.com/en-IN/blog/database-federation/
Anton Borisov: AutoMQ: Shared Storage Architecture Deep Dive
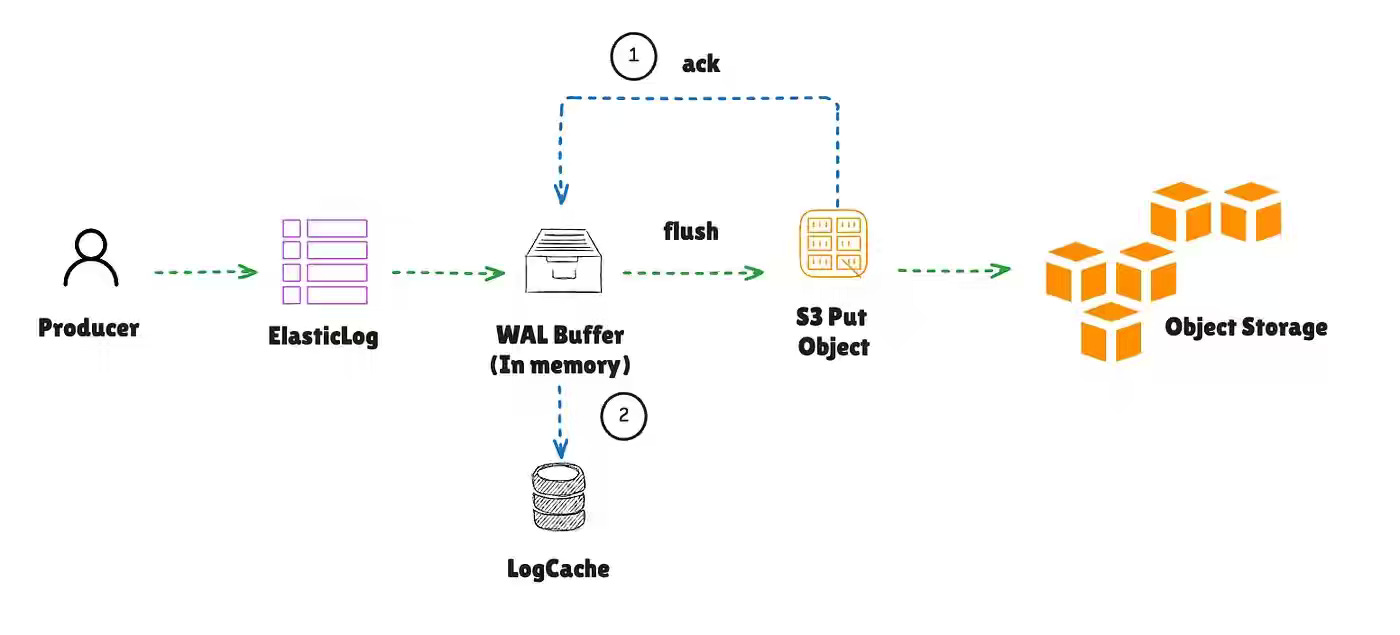
Kafka’s shared-nothing architecture imposes high replication costs, slow failover, and tight coupling between storage and compute. The article explains how AutoMQ replaces local disk replication with S3-backed shared storage, using layered abstractions, WAL batching, metadata-driven ownership, and epoch fencing to enable stateless brokers and zero-copy failover. AutoMQ design eliminates the 3x replication tax and simplifies scaling to “add compute,” while accepting higher cold-read latency from object storage.
https://medium.com/fresha-data-engineering/automq-shared-storage-architecture-deep-dive-043c5226847e
Pinterest: Drastically Reducing Out-of-Memory Errors in Apache Spark at Pinterest
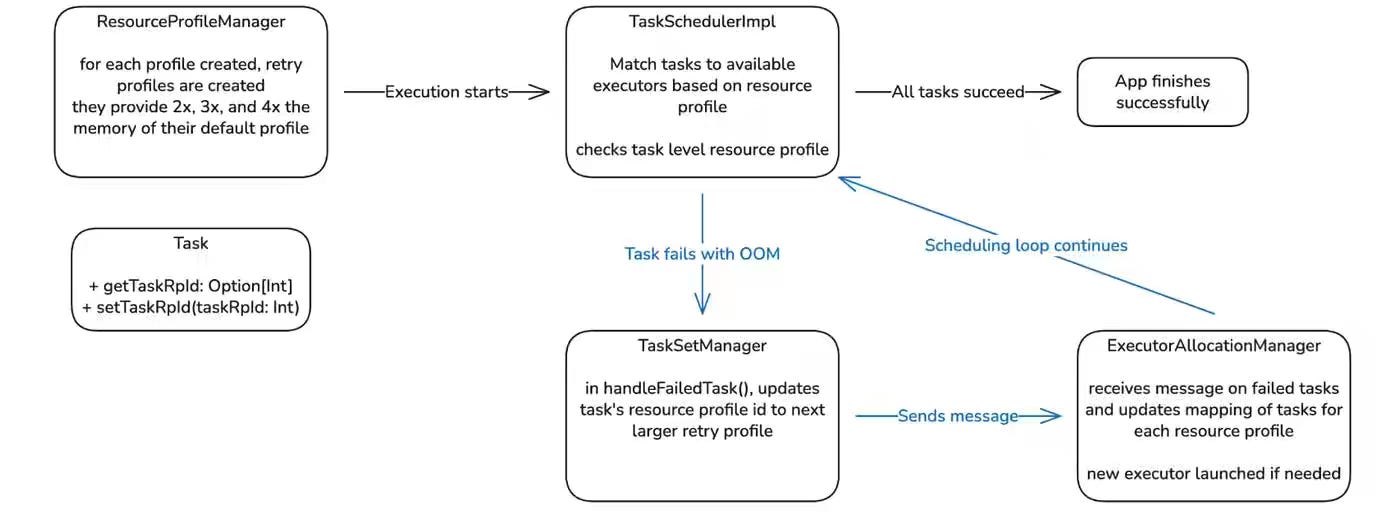
OOM in Spark jobs is an infamous issue across data processing, creating operational overhead and inefficient cluster utilization. The article explains how Auto Memory Retries dynamically adjusts executor resources by retrying failed tasks with higher CPU allocation or larger executors through modified Spark resource profiles. The elastic strategy reduced OOM failures by 96%, lowered infrastructure costs by avoiding over-provisioning, and improved overall pipeline reliability.
StarTree: Consistent, Scalable Compaction for Real-Time Upserts in Apache Pinot
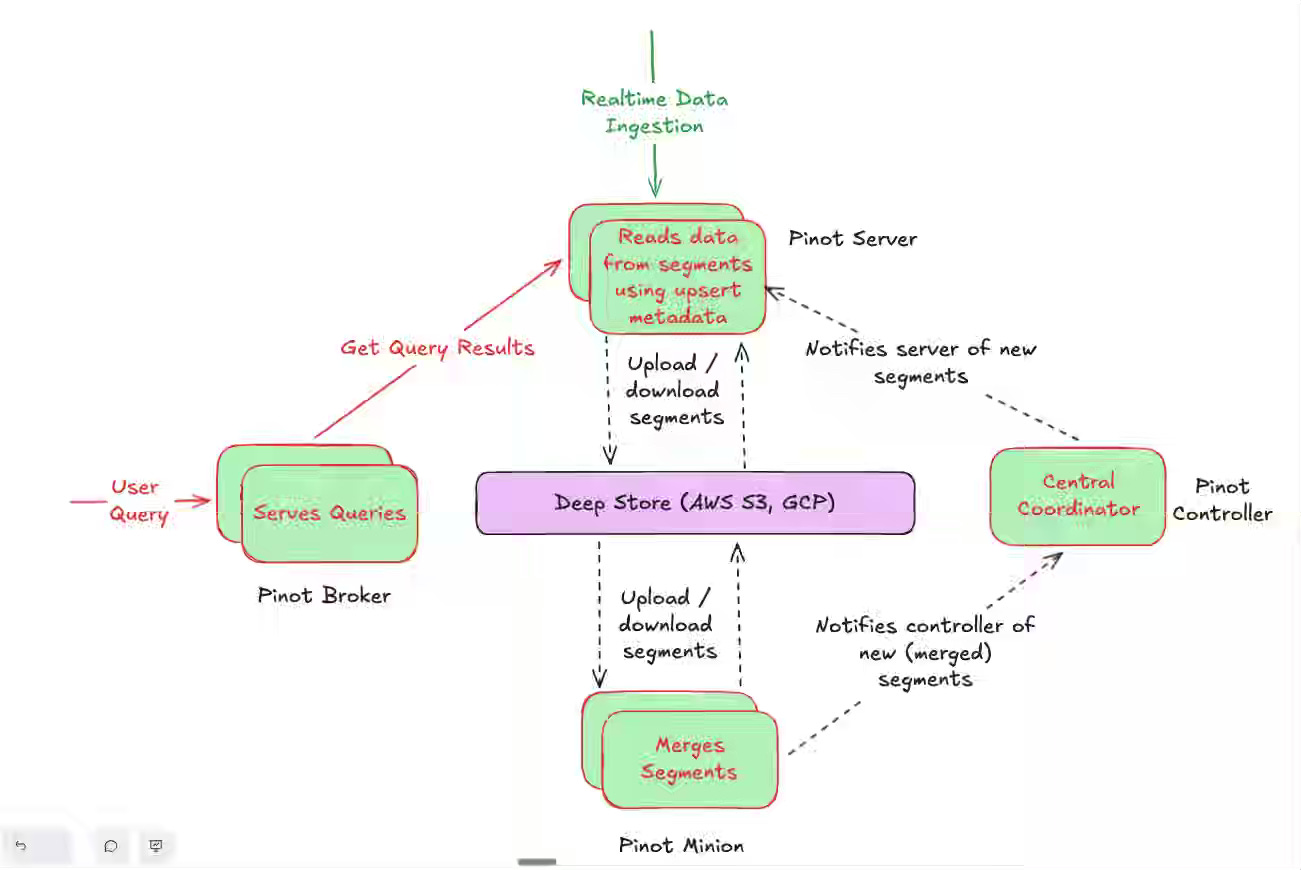
Near-Real-Time upsert is my favorite subject to study, and I've worked with many OLAP engines. Apache Pinot always stands out for its flexible indexing and fast upsert capabilities. The article explains how StarTree’s SegmentRefreshTask compacts segments in the background by merging only valid records and ensuring atomic visibility with bitmap-based consistency controls. The approach reduces storage costs, supports sustained high ingestion rates, and maintains predictable query latency at a billion-key scale.
https://startree.ai/resources/upserts-compaction-in-apache-pinot-startree/
Zepto: Debezium at Scale: An Open Source CDC Story from Zepto
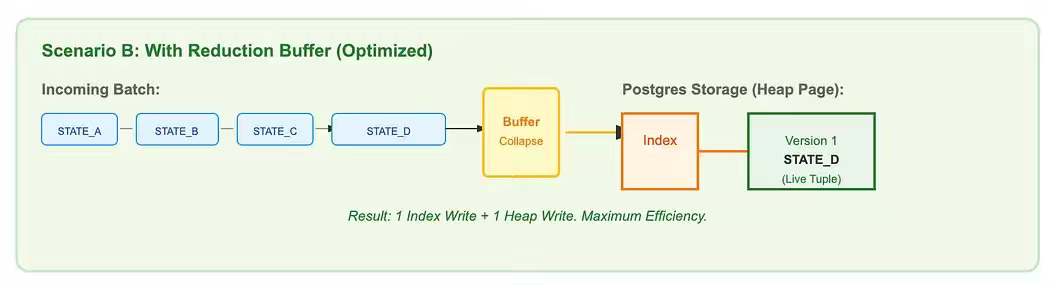
High-velocity CDC pipelines can overwhelm downstream databases due to redundant updates and MVCC-induced write amplification. The article explains how Zepto optimized Debezium by introducing an in-memory reduction buffer to collapse duplicate updates and a Postgres UNNEST-based batching strategy to reduce parsing overhead. These improvements stabilized CPU and I/O usage, eliminated replication lag during peak traffic, and ensured the database processes only final record states.
https://blog.zeptonow.com/debezium-at-scale-an-open-source-cdc-story-from-zepto-aa4b12e32bf7
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.