
Data Engineering Weekly #259
The Weekly Data Engineering Newsletter


AI is moving fast. Is your data platform ready?
AI is reshaping how data teams operate. But legacy pipelines, brittle workflows, and fragmented tooling weren’t designed for this shift.
Learn how leading teams are future-proofing their infrastructure before AI demands overwhelm it.
Download the AI Modernization Guide
underCurrent: A one-day conference for data engineers and architects

Confluent is hosting a free one-day conference with a catch: there’s no catch. It’s a single-track event with no sponsors and no product pitches—just technical talks for data engineers and architects.
🎙️ Speakers include Joe Reis, Holden Karau, and Max Beauchemin
🚫 No vendors. No sales pitches
✨ 100% free to attend
📍 San Francisco 📅 March 26
🎟️ Limited to 100 seats — register for free here
Netflix: DataJunction as Netflix’s answer to the missing piece of the modern data stack
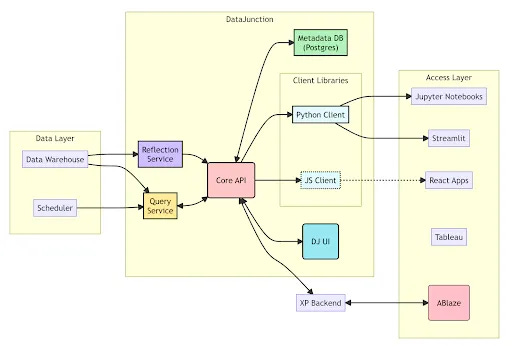
Metric inconsistency and definition sprawl across distributed teams create onboarding bottlenecks and fragment analytics workflows. Netflix built DataJunction, an open-source semantic layer that decouples metric definitions from compute through a graph-based metadata model and SQL generation engine. This standardizes metrics across the experimentation platform, reducing onboarding from weeks to hours, while enabling expansion across all business verticals and LLM integration for auditable metric lineage.
Benoit Pimpaud: Specs Should Be Equations, Not Essays
As AI automates code generation, the engineering bottleneck shifts from writing implementation to defining precise specifications. the author argues that natural language specifications create compounding ambiguity when parsed by LLMs and proposes layered specifications that combine text, diagrams, and mathematical notation as constraint definitions for AI iteration. Mathematical specs eliminate interpretation drift, enabling AI agents to generate correct programs by satisfying invariants rather than reconstructing intent from prose.
https://fromanengineersight.substack.com/p/specs-should-be-equations-not-essays
Notion: Balancing cost and reliability for Spark on Kubernetes
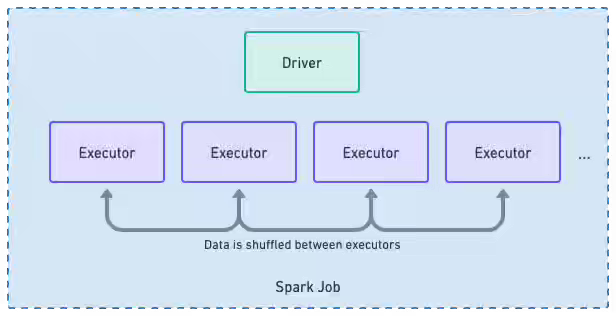
Spark clusters on Kubernetes face a fundamental tension between aggressive cost optimization through spot instances and job reliability during capacity interruptions. Notion reduced compute costs by 60–90% through EKS migration with Karpenter bin-packing, then open-sourced Spot Balancer—a Kubernetes webhook that enforces stable spot-to-on-demand ratios per job, preventing cascade failures during AWS termination windows. Spot Balancer abstracts infrastructure trade-offs into developer-friendly stability tiers, enabling teams to optimize costs without sacrificing job completion rates.
https://www.notion.com/blog/balancing-cost-and-reliability-for-spark-on-kubernetes
Sponsored: Building a Cross-Workspace Control Plane for Databricks

As Databricks deployments scale, a familiar pattern emerges: multiple workspaces, multiple teams, and no reliable way to manage the dependencies between them.
In this hands-on deep dive, we'll show you how to build a cross-workspace control plane using Dagster on top of your existing Databricks environment. Demo-heavy and practitioner-focused, you'll leave with working patterns you can apply to your own platform the same day.
Apache Iceberg: Introducing the Apache Iceberg File Format API
It is indeed an exciting development in Iceberg to support a plugable file format API spec. As we increasingly handle unstructured data, this will significantly enhance data management practices through unified governance and compliance. Interestingly, Apache Hudi’s RFC-100 is, in fact, the feature request to support the Lance File Format.
https://iceberg.apache.org/blog/apache-iceberg-file-format-api/
Delta Lake: The next evolution of Delta - Catalog-Managed Tables
We went through the full cycle, from exposing the files directly through Hadoop to Snowflake-style cloud data warehouses, to Iceberg-style direct file access, back to catalog-managed tables.
Nonetheless, it will be interesting to watch DuckLake-style catalog-managed tables vs object-store-style managed tables.
https://delta.io/blog/2026-02-02-delta-catalog-managed-tables/
Microsoft Fabric: Under the hood: an introduction to the Native Execution Engine for Microsoft Fabric
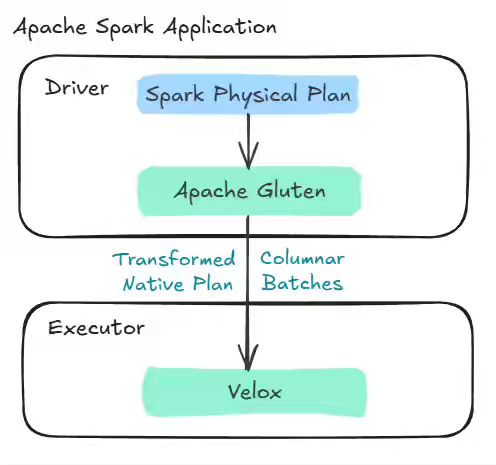
The Apache Gluten project is continually making an impact on the Spark ecosystem, bringing unique optimization and efficiency. Microsoft Fabric writes an under-the-hood story of adopting Apache Gluten in its Fabric platform.
Pinterest: Piqama - Pinterest Quota Management Ecosystem
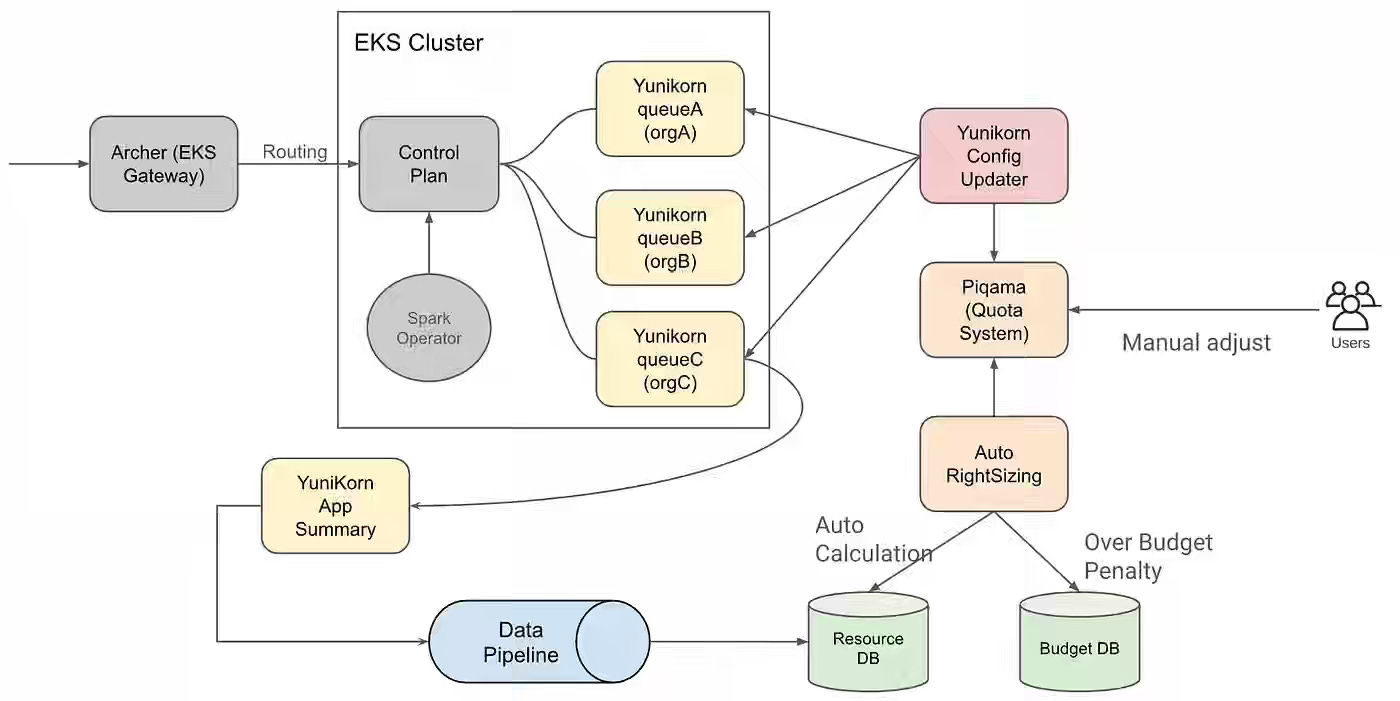
As companies scale, manual and static quota systems become bottlenecks, forcing engineers to choose between over-provisioning resources and managing brittle enforcement logic. Pinterest developed Piqama, a unified quota platform that dynamically right-sizes limits using historical data stored in Apache Iceberg, then applies custom enforcement strategies across batch schedulers and online services. Piqama centralizes resource governance across hardware and service metrics, enabling teams to optimize capacity allocation while linking consumption directly to financial costs.
https://medium.com/pinterest-engineering/piqama-pinterest-quota-management-ecosystem-dc7881433bf5
LinkedIn: Engineering LinkedIn’s job ingestion system at scale
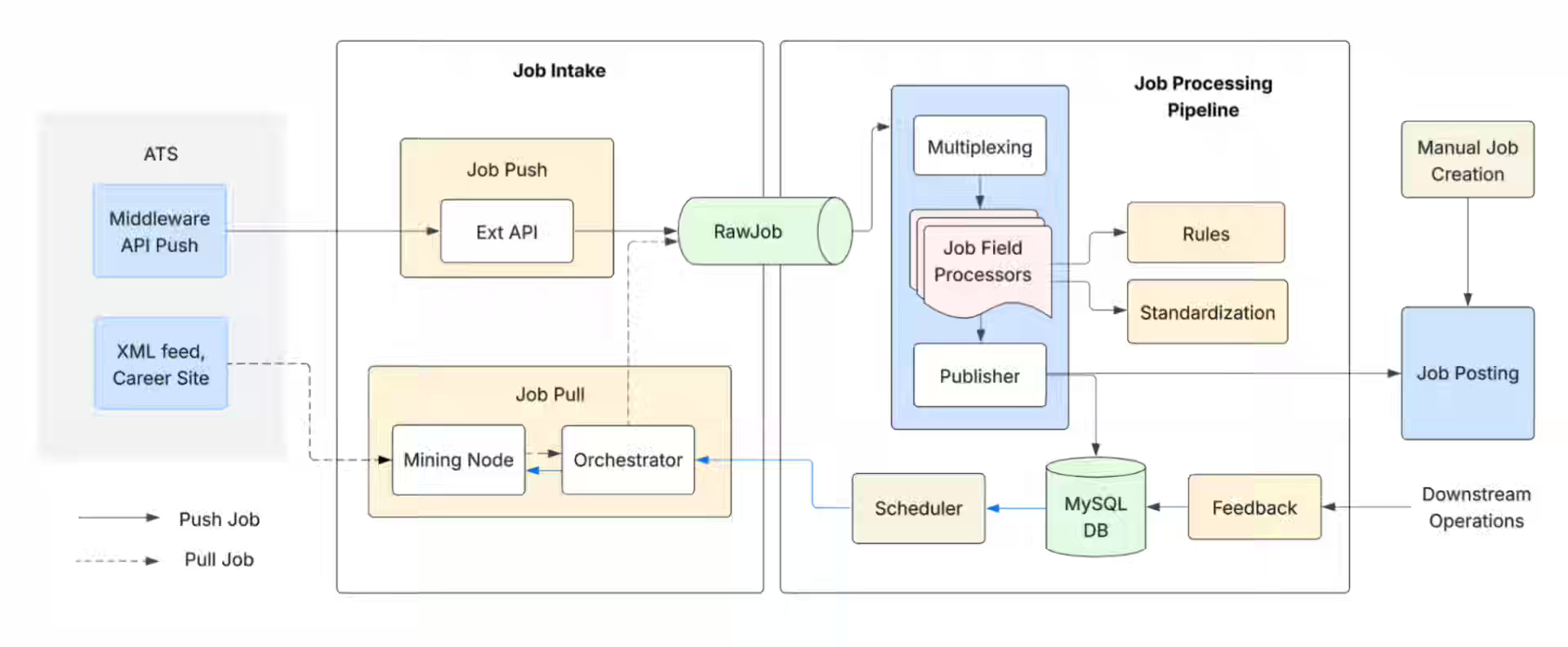
Ingestion systems struggle to scale source onboarding—hard-coded extraction logic creates engineering bottlenecks that slow integration of new data partners. LinkedIn shifted extraction logic from code to configuration files called Sitemaps, enabling AI tools and browser plugins to onboard sources without engineering deployments. At the same time, a transactional state machine enforces precise failure boundaries across parallel mining tasks. The configuration-driven approach reduces onboarding time from weeks to hours, allowing LinkedIn to ingest 20TB daily across thousands of global sources.
Shopify: The generative recommender behind Shopify’s commerce engine
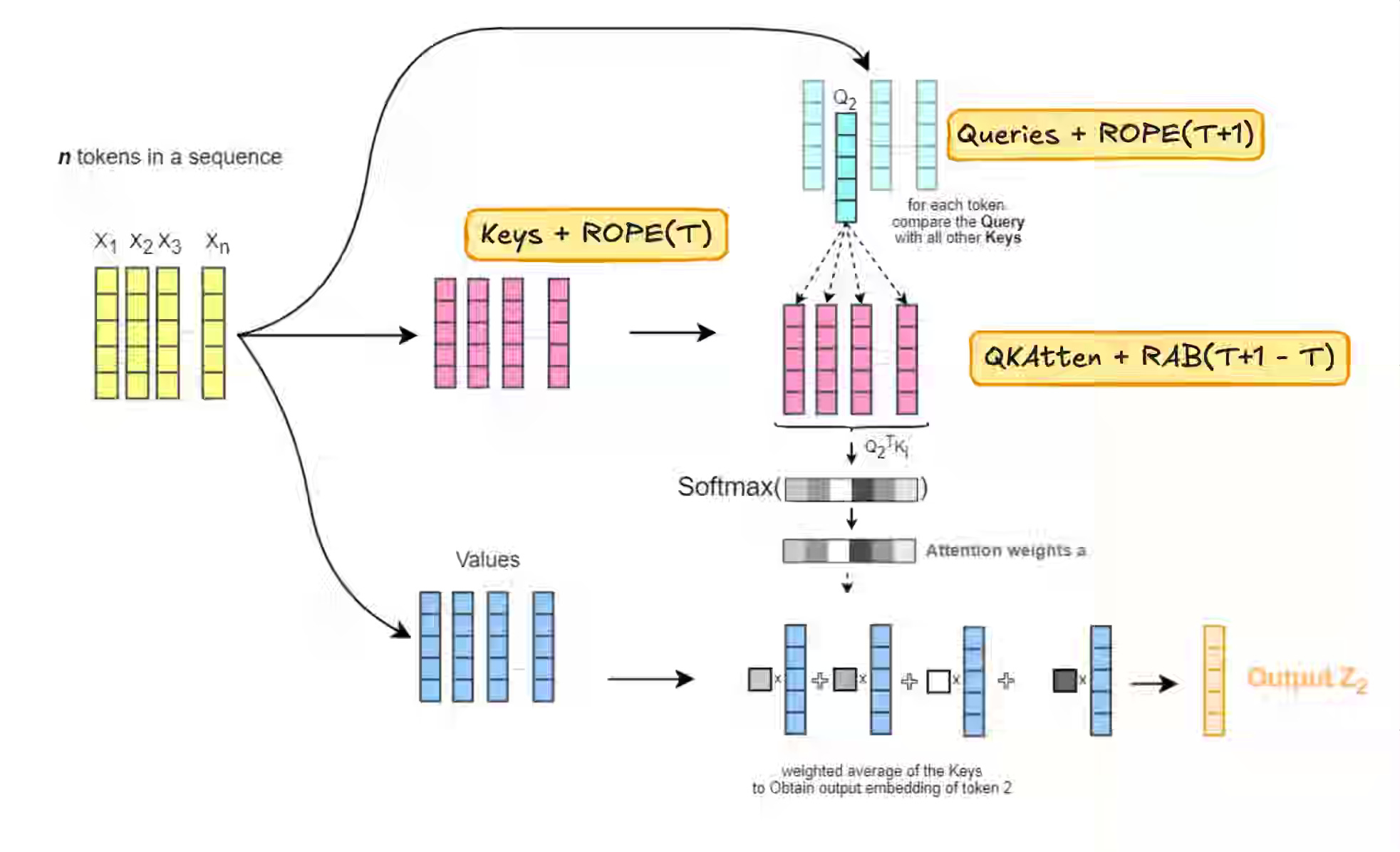
Recommendation systems traditionally treat purchases as isolated events, missing the temporal and causal structure that shapes buyer journeys across millions of products. Shopify transitioned to an autoregressive sequence model that treats commerce journeys as token sequences, implementing RoPE-inspired rotary encoding combined with relative attention bias to capture temporal gaps and seasonality across its catalog. The time-aware attention mechanism drove +0.94% order growth and +0.71% conversion lift while achieving 7.3x training speedup through optimized CUDA kernels, enabling Shopify to integrate richer context into a unified generative framework.
https://shopify.engineering/generative-recommendations
Alibaba: PostgreSQL Blink-tree Implementation
As we increasingly use AI to code, understanding database internals is more critical than ever. Alibaba Cloud engineers break down how PostgreSQL utilizes the Blink-tree architecture to achieve massive concurrency. By adding link pointers to sibling nodes and high keys to mark boundaries, PostgreSQL allows searches to proceed without lock-coupling. This enables the system to gracefully handle concurrent page splits—following links when data exceeds old boundaries—and significantly outperforms the more rigid lock-subtree approach used in MySQL’s InnoDB.
https://www.alibabacloud.com/blog/postgresql-blink-tree-implementation_602913
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.