
Data Engineering Weekly #260
The Weekly Data Engineering Newsletter


Best practices for orchestrating Databricks at scale
As Databricks deployments scale, a familiar pattern emerges: multiple workspaces, multiple teams, and no reliable way to manage the dependencies between them.
In this hands-on deep dive, we'll show you how to build a cross-workspace control plane using Dagster on top of your existing Databricks environment. Demo-heavy and practitioner-focused, you'll leave with working patterns you can apply to your own platform the same day.
underCurrent: A one-day conference for data engineers and architects

Confluent is hosting a free one-day conference with a catch: there’s no catch. It’s a single-track event with no sponsors and no product pitches—just technical talks for data engineers and architects.
🎙️ Speakers include Joe Reis, Holden Karau, and Max Beauchemin
🚫 No vendors. No sales pitches
✨ 100% free to attend
📅 March 26
📍 San Francisco
🎟️ Limited to 100 seats — register for free here
Vinoth Govindarajan: OpenClaw Architecture
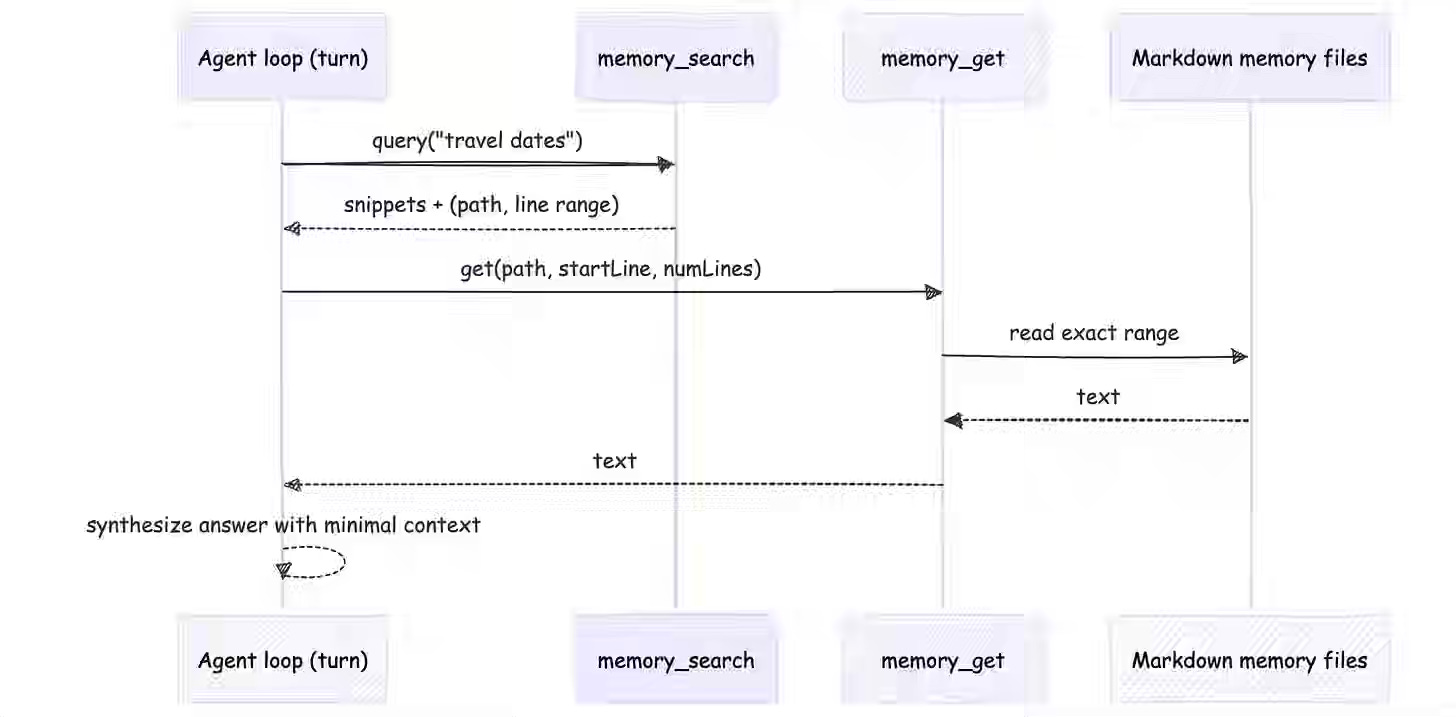
Production AI agents fail at scale because uncontrolled state mutations corrupt execution and create unpredictable behavior. In “The Agent Stack,” Vinoth Govindarajan outlines OpenClaw’s architecture, in which isolated execution contexts and strict invariants prevent state leakage, while sessions enable async pause-resume semantics. The pattern standardizes how teams decouple short-term context from persistent state, ensuring agents reliably rehydrate their mental model and enforce authorization boundaries that gate tool access to user privilege levels.
Part 1, Part 2, Part 3.1, Part 3.2, Part 4
Pinterest: Unified Context-Intent Embeddings for Scalable Text-to-SQL
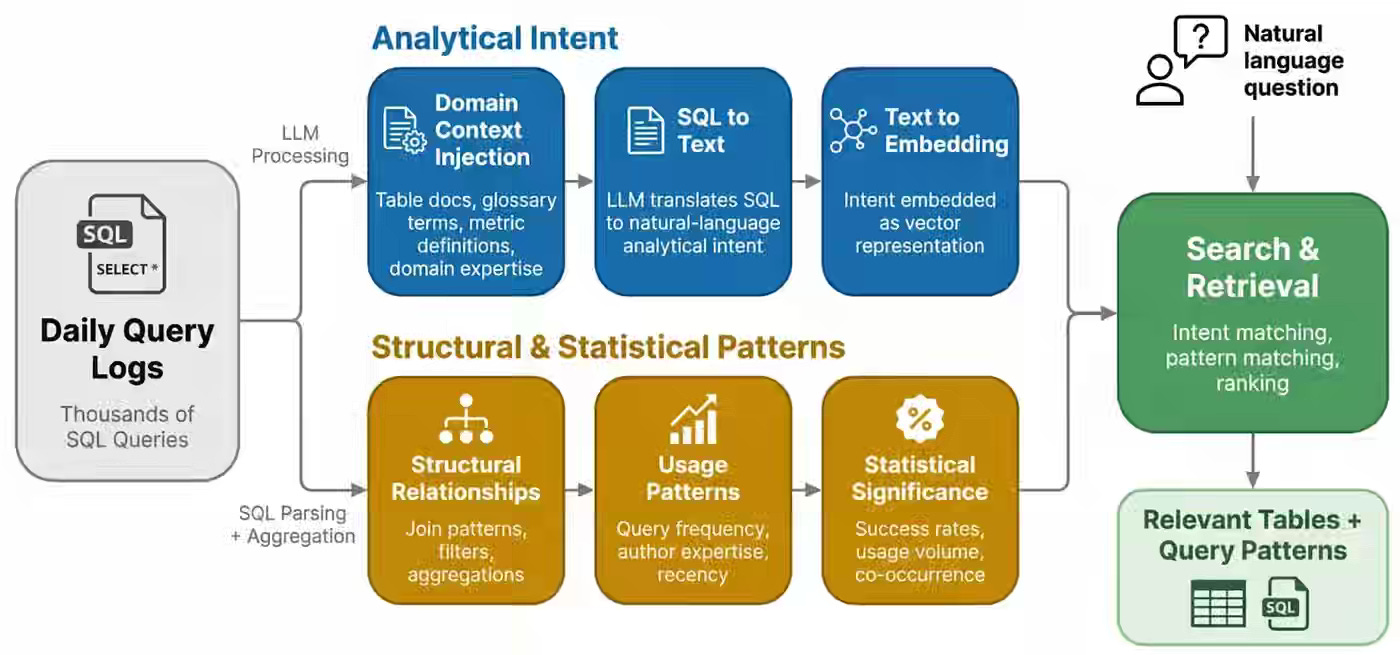
Navigating sprawling data warehouses forces analysts to choose between slow manual exploration and unreliable keyword-based search. Pinterest Engineering built a production Analytics Agent that embeds historical SQL queries as semantic intent signatures, injecting business glossary terms and extracting structural patterns (join keys, filters, usage signals) to retrieve contextually relevant tables at scale. The system reached 40% internal adoption within two months by standardizing discovery through an asset-first pattern, converting years of institutional SQL knowledge into a searchable, governance-aware library.
Francesca Lazzeri: AI evals platforms: A comparative guide for production AI systems
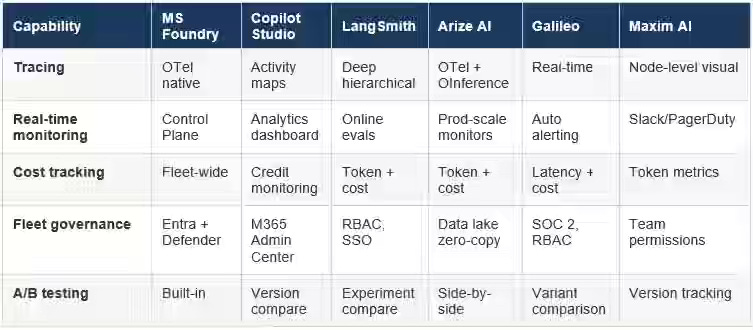
Production AI systems fail silently in ways demos never expose, forcing teams to replace manual testing with automated evaluation as the enterprise LLM market scales toward $71.1 billion by 2034. A comparative analysis of six leading eval platforms reveals a consolidation around open standards (OpenTelemetry, OpenInference) and specialized architectures—Microsoft AI Foundry embeds red-teaming agents into Azure workflows, while Galileo replaces expensive LLM judges with smaller consensus models (Luna) to reduce eval latency. The shift standardizes safety as a structural property of development, enabling teams to catch jailbreaks and data leaks early while choosing platform fit based on stack priorities: simulation-first, research rigor, or ecosystem depth.
https://medium.com/data-science-at-microsoft/how-do-you-know-your-ai-actually-works-b1a380a07825
Sponsored: The AI Modernization Guide

AI is reshaping how data teams operate. But legacy pipelines, brittle workflows, and fragmented tooling weren’t designed for this shift.
Learn how leading teams are future-proofing their infrastructure before AI demands overwhelm it.
Netflix: MediaFM - The Multimodal AI Foundation for Media Understanding at Netflix
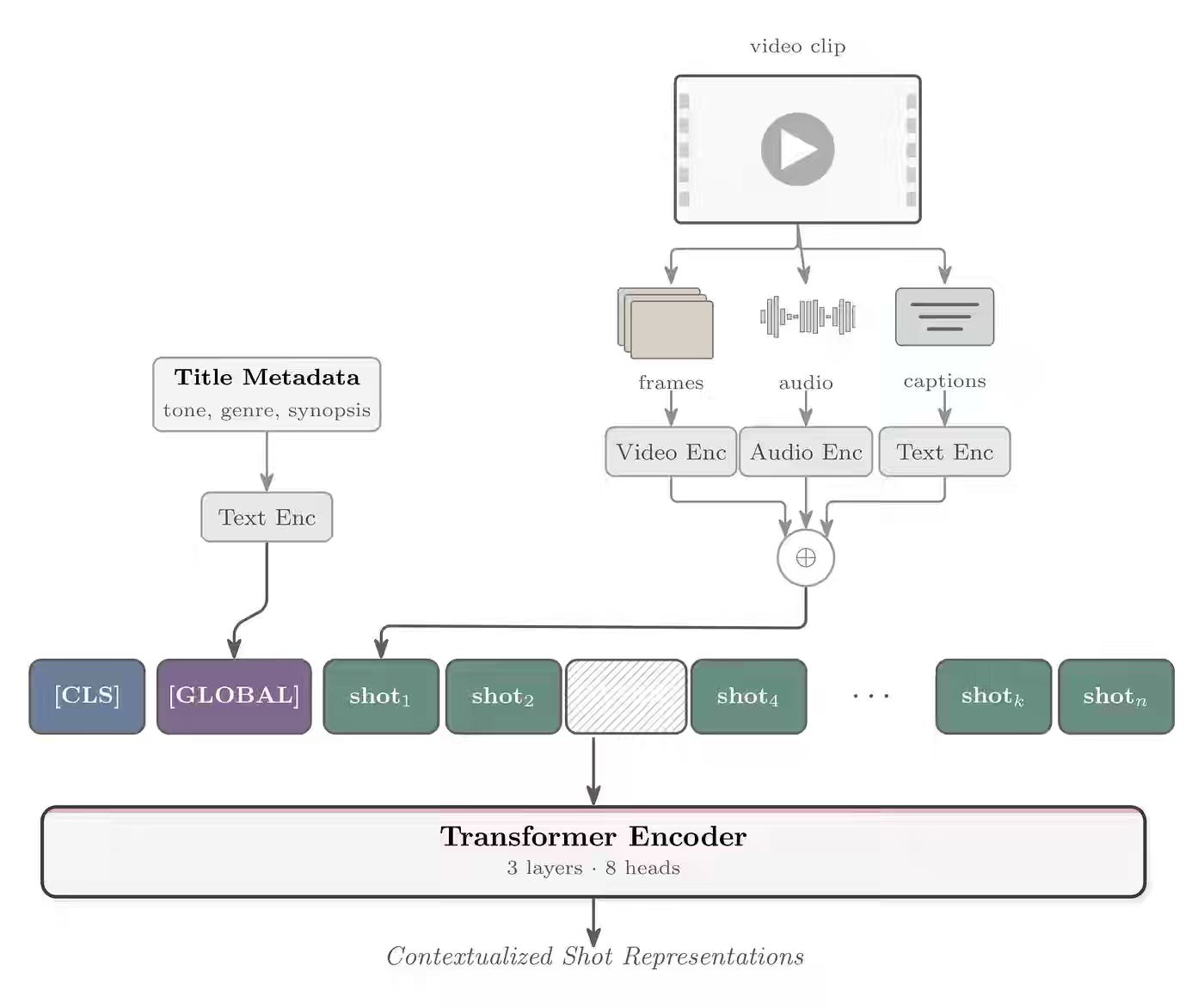
Understanding content at scale requires machine-readable representations that capture narrative structure, not just visual features—a challenge intensified as streaming catalogs exceed tens of thousands of titles. Netflix built MediaFM, a tri-modal transformer that fuses video frames, audio (wav2vec2), and subtitles into shot-level embeddings using Masked Shot Modeling, with a [GLOBAL] token injecting title-level context (synopsis, genre) to ground each segment. The model powers ad placement, clip ranking, content tagging, and cold-start recommendations by contextualizing shots within narrative sequence, outperforming external benchmarks and enabling machine-readable understanding across Netflix's entire catalog.
Nabin Debnath: Building a Least-Privilege AI Agent Gateway for Infrastructure Automation with MCP, OPA, and Ephemeral Runners
AI agents in infrastructure automation bypass traditional guardrails by making runtime decisions without human validation, risking silent resource destruction or credential exfiltration at scale. The author writes about the Agent Gateway to treat the agents as untrusted requesters, layering Model Context Protocol (MCP) for tool discovery, Open Policy Agent (OPA) for intent-based authorization, and ephemeral Kubernetes runners for isolated execution. The pattern enforces least privilege by mediating all API calls through policy code, validates plan integrity against immutable hashes, and surfaces decision reasoning via OpenTelemetry—standardizing agent governance with SLO targets (100ms policy decisions, 5s runner startup) that prevent silent bypasses.
https://www.infoq.com/articles/building-ai-agent-gateway-mcp/
Dropbox: Using LLMs to amplify human labeling and improve Dash search relevance
Enterprise search ranking requires massive labeled datasets, but traditional human annotation is prohibitively slow and cannot scale to sensitive content across billions of internal documents. Dropbox Dash uses LLMs as labeling force multipliers by calibrating a small human-labeled set to generate millions of relevance judgments offline, then training lightweight production models (XGBoost) on synthetic labels at scale. The pattern standardizes judgment consistency by pairing contextual research tools (for acronyms and ambiguous queries) with programmatic prompt optimization (DSPy), enabling continuous ranking improvements while keeping human oversight as the ground truth rather than replacing it.
https://dropbox.tech/machine-learning/llm-human-labeling-improving-search-relevance-dropbox-dash
Zalando: Why We Ditched Flink Table API Joins: Cutting State by 75% with DataStream Unions
Declarative SQL joins in Flink multiply state across operators, forcing teams to choose between snapshot overhead or operational instability—a scaling bottleneck for pipelines enriching millions of real-time product records. Zalando replaced chained Table API joins with a custom KeyedProcessFunction that unions all streams into a single keyed DataStream, storing each product’s enriched state once in RocksDB instead of redundantly across join operators. The shift cut state size by 75% (235GB to 56GB), reduced snapshot time by 77% (11 minutes to 2.5 minutes), and lowered AWS costs by 13%—demonstrating how imperative control over stream topology recovers efficiency when declarative abstractions misalign with physical execution.
Aihua Xu & Andrew Lamb: Variant Type in Apache Parquet for Semi-Structured Data
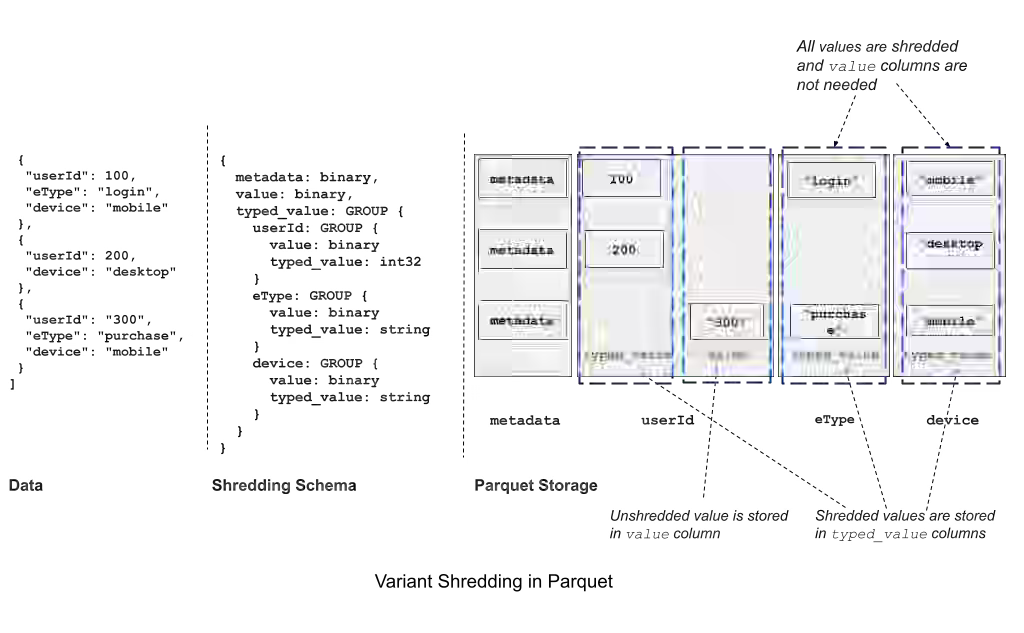
Semi-structured data in columnar formats forces a choice between slow JSON parsing or rigid schemas that block evolution, creating friction in pipelines handling heterogeneous records. Apache Parquet’s new Variant type uses binary-encoded metadata plus value fields, enabling direct nested field access without full-document parsing while preserving native types (timestamps, integers) that JSON loses. The type standardizes schema flexibility through “shredding”—extracting hot fields into strongly-typed columns for predicate pushdown and pruning—allowing heterogeneous records to coexist in one column, reducing migration overhead and accelerating adoption across DuckDB, Spark 4.0, and Snowflake.
https://parquet.apache.org/blog/2026/02/27/variant-type-in-apache-parquet-for-semi-structured-data/
Pranav Mehta: Silent Data Loss in ClickHouse: 3 Reasons Your Distributed Queue Keeps Growing
ClickHouse distributed inserts silently fail when coordination services downtime, execution timeouts, or concurrency limits block the async flush pipeline, leaving data trapped in on-disk queues while clients receive no error signals. The author identifies three failure modes: Keeper/ZooKeeper downtime forcing ReplicatedMergeTree read-only, oversized insert blocks exceeding max_execution_time that cork sequential queue processing, and exhausted user concurrency slots starving background INSERT workers. The pattern demands proactive monitoring of DistributedFilesToInsert (alert at 50+ files), debugging via system.distribution_queue.last_exception, and inode-aware filesystem choice (XFS over ext4) to prevent silent data loss and system crashes from queue explosion.
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.