
Data Engineering Weekly #262
The Weekly Data Engineering Newsletter


This week: Orchestrating Databricks across multiple workspaces
In this hands-on deep dive, you'll learn how to build a cross-workspace control plane for Databricks using Dagster — connecting multiple workspaces, dbt, and Fivetran into a single observable asset graph with zero code changes to get started.
Pinterest: Building an MCP Ecosystem at Pinterest
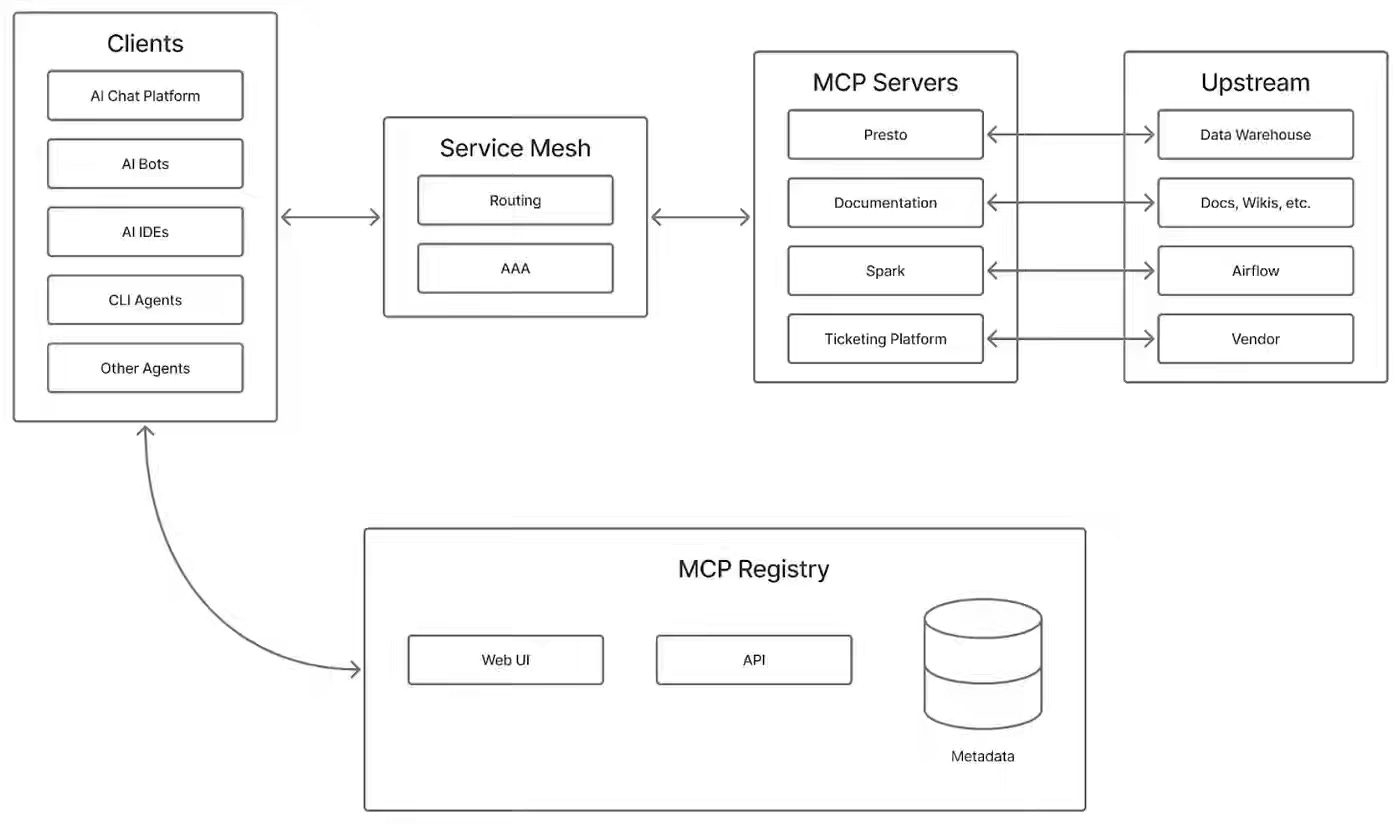
Agent tooling at scale requires decentralizing context across domain-specific servers while maintaining security, discoverability, and governance across production systems. Pinterest’s MCP ecosystem deploys specialized servers (Presto, Spark, Airflow) behind a central registry, routes requests via JWT end-user tokens and SPIFFE mesh identities, and enforces human approval for sensitive actions such as data overwrites. The system handles 66,000+ monthly invocations while saving engineers 7,000 hours monthly, validating decentralized tooling as the production pattern for agentic workflows.
https://medium.com/pinterest-engineering/building-an-mcp-ecosystem-at-pinterest-d881eb4c16f1
Julien Simon: Still Missing Critical Pieces
Tool standardization protocols face re-fragmentation when architectural constraints—token overhead, stateless scaling, weak auth—force enterprises toward custom implementations for production workloads. The author argues that MCP won adoption but lacks enterprise readiness: Cloudflare's native MCP costs 244,000 tokens versus 1,000 in "Code Mode"; sticky routing defeats load balancers; and missing governance leaves security to individual teams. Companies like Perplexity and Cloudflare are abandoning MCP's tool-calling layer in favor of direct APIs and code generation, signaling that production-scale enterprises require deterministic execution patterns that MCP cannot provide.
https://julsimon.medium.com/still-missing-critical-pieces-7a78077235e5
Databricks: Breaking the Microbatch Barrier: The Architecture of Apache Spark Real-Time Mode
Real-time analytics infrastructure traditionally required separate engines for throughput (Spark) and sub-100ms latency (Flink), leading to duplicated tooling and operational complexity. Apache Spark 4.1's Real-Time Mode eliminates this trade-off by using longer epochs with boundary checkpointing, concurrent map-reduce stages, and non-blocking operators that emit results continuously rather than buffering them. The unified engine handles both massive ETL and low-latency fraud detection while preserving Spark's lineage-based fault tolerance, consolidating the data stack for single-engine architectures.
https://www.databricks.com/blog/breaking-microbatch-barrier-architecture-apache-spark-real-time-mode
Sponsored: The AI Modernization Guide

AI is reshaping how data teams operate. But legacy pipelines, brittle workflows, and fragmented tooling weren’t designed for this shift.
Learn how leading teams are future-proofing their infrastructure before AI demands overwhelm it.
Etsy: Making Ads Count: Using MMoE and Auxiliary Tasks to Better Connect Buyers & Sellers
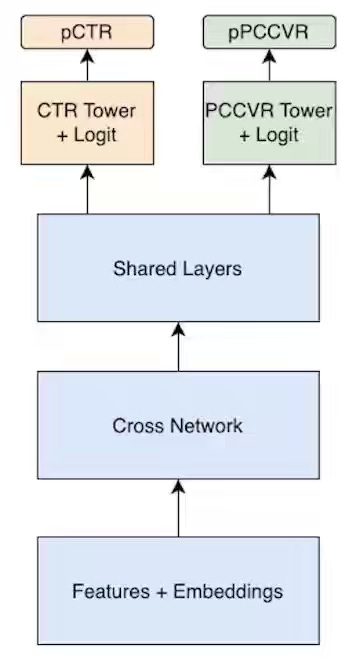
Multi-objective ranking in marketplaces faces metric conflicts—optimizing for clicks often degrades conversions—thereby requiring task-specific expert routing while managing data sparsity across event hierarchies. Etsy's MMoE architecture routes CTR and purchase prediction tasks through specialized experts with gated selection, then bridges sparse purchase signals using auxiliary add-to-cart tasks that correlate strongly with intent. The system achieved a 3.5% lift in purchase AUC and a 1% lift in click AUC while reducing inference cost through model pruning, enabling more accurate auto-bidding for sellers.
Meta: Ranking Engineer Agent (REA): The Autonomous AI Agent Accelerating Meta’s Ads Ranking Innovation
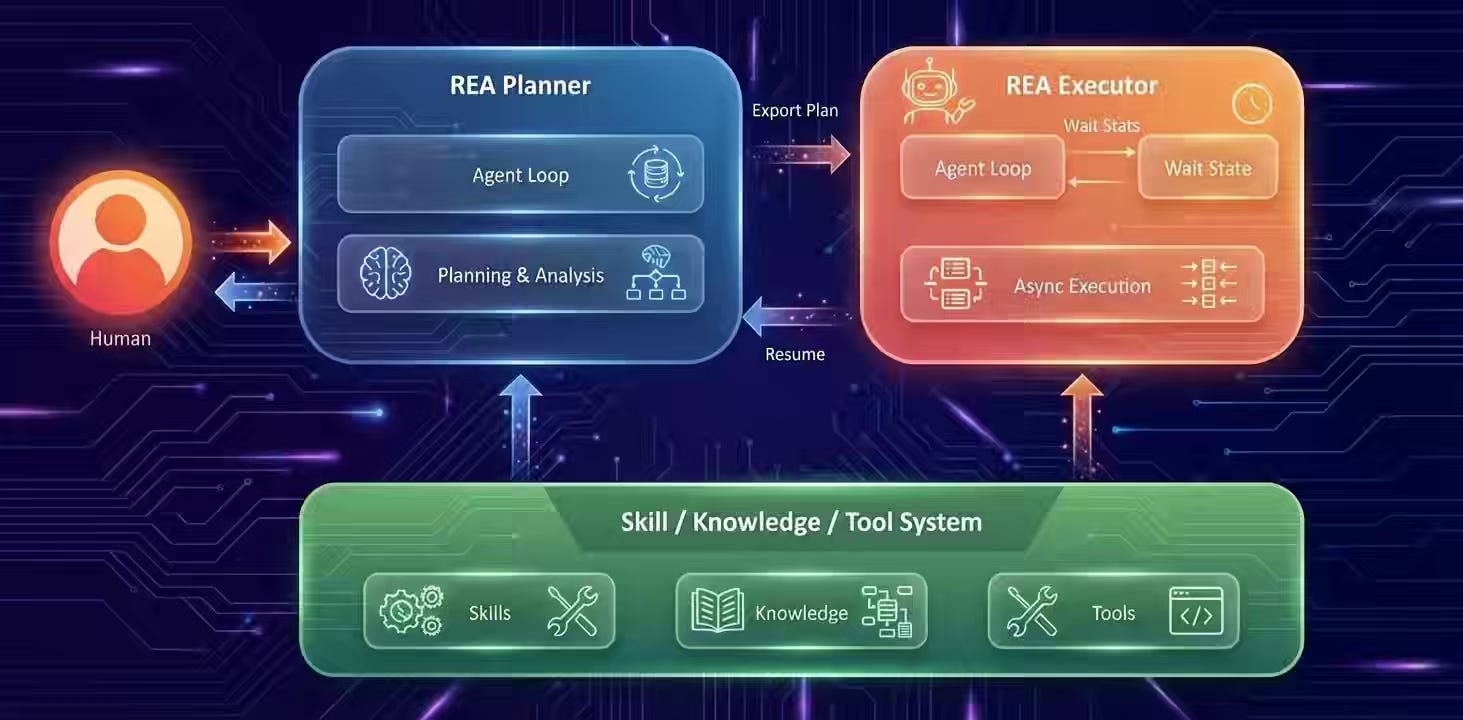
ML model iteration at production scale requires balancing hypothesis generation, resource constraints, and infrastructure resilience across multi-day experiment cycles. Meta’s Ranking Engineer Agent combines a Dual-Source Hypothesis Engine (historical experiments + novel ML research proposals) with autonomous debugging and cost-aware planning to execute long-horizon ranking workflows without human supervision. The system doubled average model accuracy across six models while enabling three engineers to maintain eight production models—a 5x productivity gain over traditional team structures.
Rahul Garg: Context Anchoring
AI-assisted development degrades over long sessions as models lose reasoning context ("why") despite retaining technical choices ("what"), trapping developers in single conversations to avoid context loss. The author proposes Context Anchoring—externalizing decision rationale, rejected alternatives, and constraints into lightweight Feature Documents outside the chat interface. Teams adopting external anchoring achieve warm starts in seconds, reduce token costs by 98%, enable multi-developer alignment, and validate logic through forced documentation, eliminating session anxiety as a design anti-pattern.
https://martinfowler.com/articles/reduce-friction-ai/context-anchoring.html
Dropbox: How we optimized Dash’s relevance judge with DSPy
Relevance scoring at scale faces a model-cost-quality trade-off: premium models like o3 are accurate but expensive, while cheaper open-weight models degrade without model-specific prompt tuning. Dropbox's DSPy-based optimization automates prompt refinement against human judgments using NMSE metrics and GEPA feedback loops, reducing manual tuning from weeks to 1–2 days. The system cut relevance error by 45%, eliminated JSON formatting failures by 97%, and enabled 10–100x data scaling by shifting to cheaper models while maintaining quality through systematic prompt compilation.
https://dropbox.tech/machine-learning/optimizing-dropbox-dash-relevance-judge-with-dspy
Zalando: Search Quality Assurance with AI as a Judge
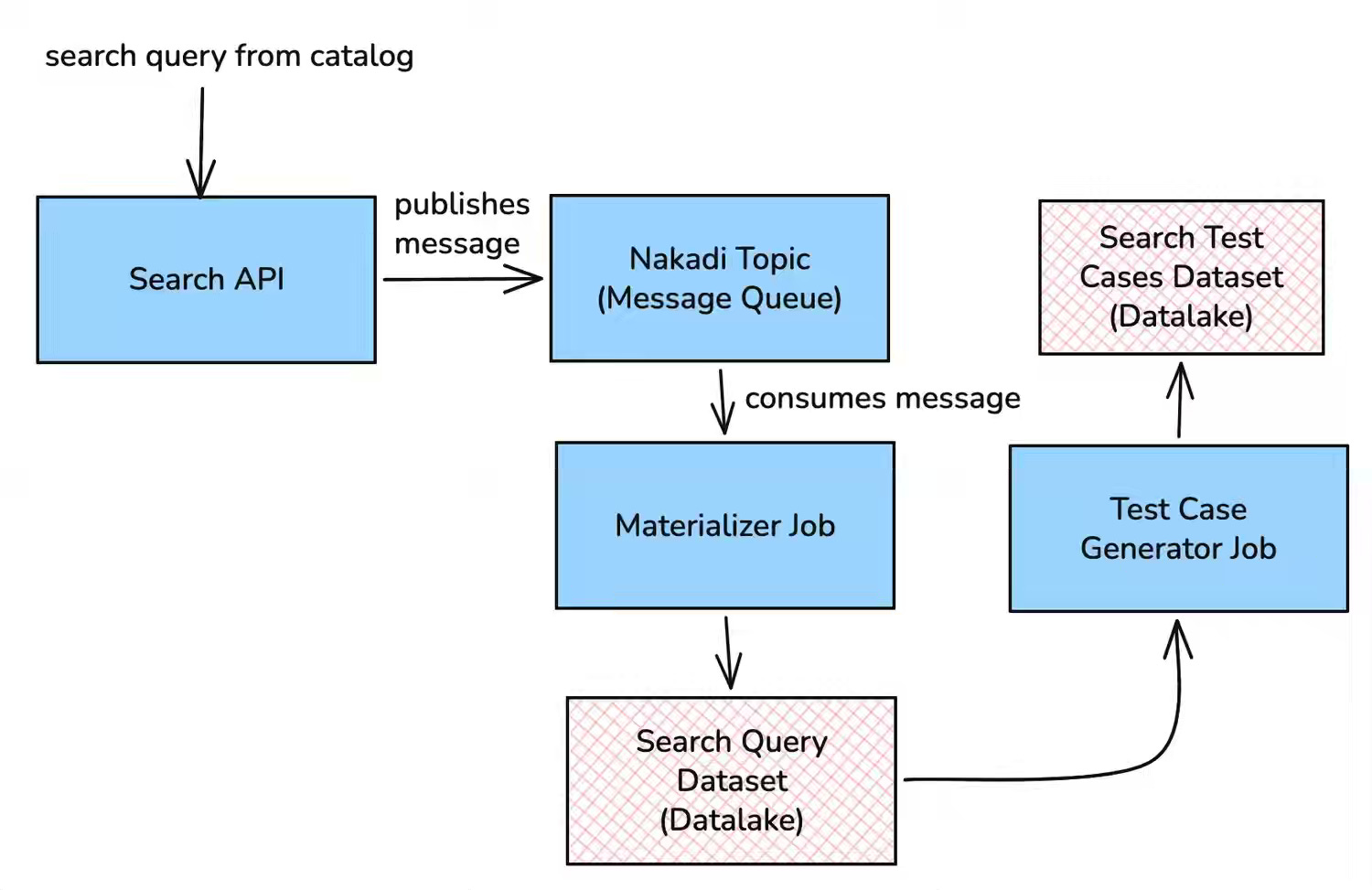
Search quality assurance in a new domain often lacks historical user data, forcing teams to rely on manual testing and reactive fixes post-launch. Zalando's framework automates evaluation by generating NER-clustered queries translated into target languages, then routes the results through GPT-4o as a multimodal judge that assesses product metadata and images against a 0–4 relevance scale. The system evaluates 1,500 search segments (37,500 results) in 3–5 hours for $250, enabling proactive root-cause identification across languages and ensuring Day 1 quality without local market expertise.
https://engineering.zalando.com/posts/2026/03/search-quality-assurance-with-llm-judge.html
Andrey Novitskiy: Volga - A Rust Rewrite of a Real-Time AI/ML Data Engine (DataFusion, Arrow, SlateDB) with a Chronon + OpenMLDB–Style Architecture
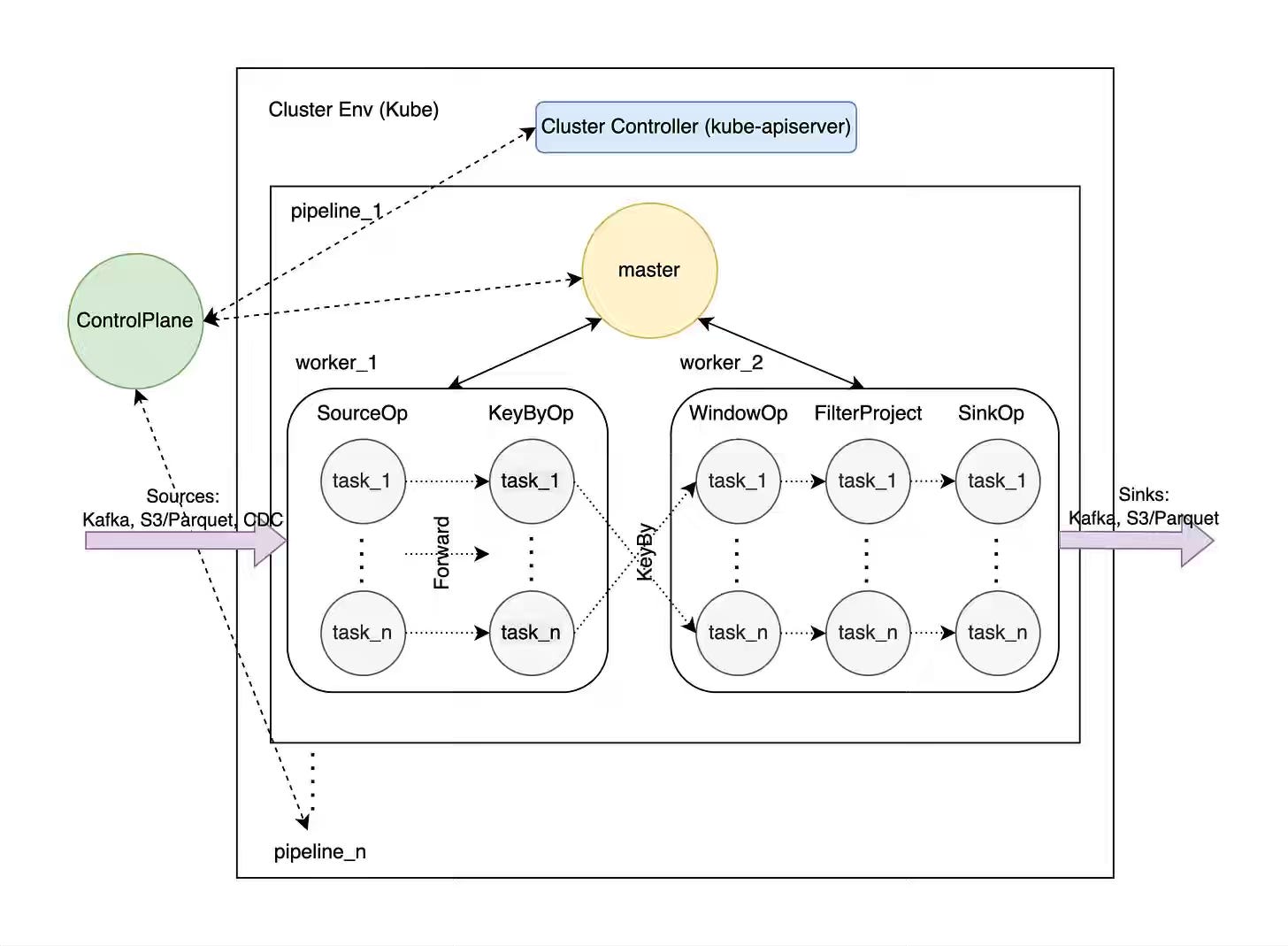
Real-time ML feature computation requires unified streaming-batch execution with low-latency serving, forcing platforms to choose between specialized engines (Flink for latency, Spark for batch, Redis for serving). Volga's Rust implementation pairs DataFusion SQL execution with SlateDB (an embedded LSM on object storage) and Request Mode, embedding serving logic directly into operator state to eliminate external cache round trips. The system handles month-year windows via tiling, includes native ML aggregations (top-k, categorical sums), and achieves compute-storage separation by consolidating the feature pipeline, batch training, and real-time serving into a single Rust binary.
https://volgaai.substack.com/p/volga-a-rust-rewrite-of-a-real-time
Max Halford: Lower your warehouse costs via DuckDB transpilation
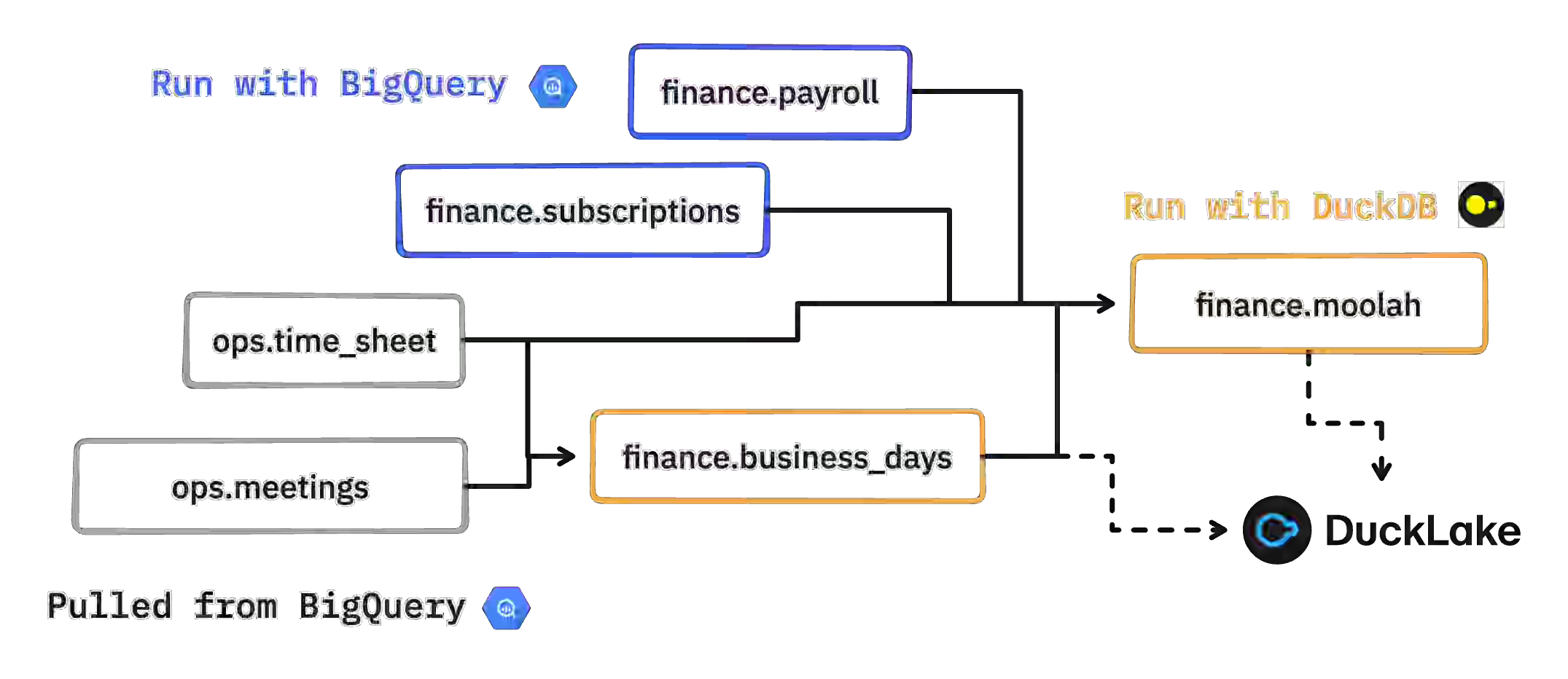
Cloud warehouse compute costs escalate during development and testing cycles, incentivizing hybrid approaches that separate cheap storage from expensive query execution. Max Halford’s “Quack Mode” transpiles warehouse SQL (BigQuery → DuckDB) using SQLGlot, pulls only upstream dependencies into local DuckDB instances, and executes transformations at near-zero cost, optionally pushing results back. The pattern dramatically reduces development compute spend while maintaining warehouse portability, though pulling tables >100GB remains a bottleneck until zero-copy solutions like Iceberg are available.
https://maxhalford.github.io/blog/warehouse-cost-reduction-quack-mode/
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.