
Data Engineering Weekly #265
The Weekly Data Engineering Newsletter

This week: Multi-Tenancy for Modern Data Platforms

Join Brooklyn Data Co. and Dagster Labs for a live deep dive on multi-tenancy for modern data platforms. We’ll cover:
- Code location isolation and project structure patterns
- Managing dependencies across tenants (including AI models)
- Operational strategies that scale with your organization
- Lessons learned from real production implementations
Save your spot for practical guidance that you can apply immediately.
dbt: Semantic Layer vs. Text-to-SQL: 2026 Benchmark Update
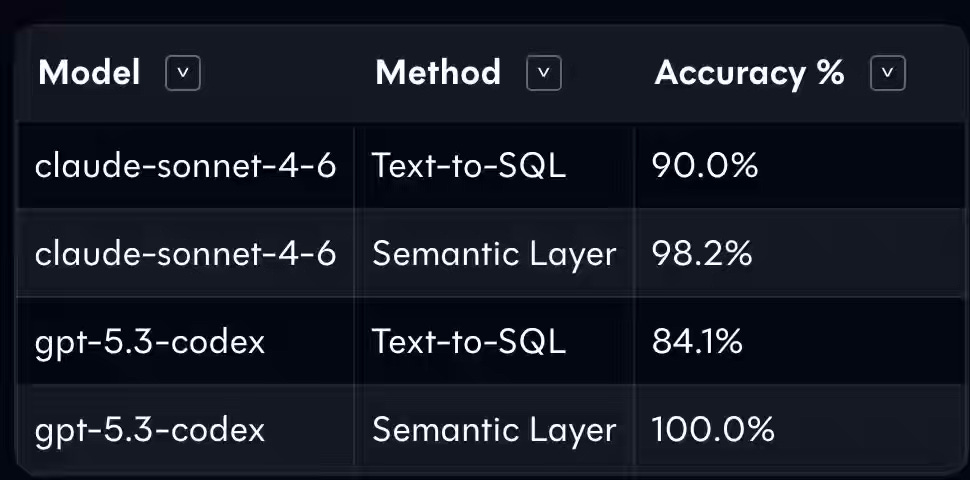
AI will write all the code generated in data engineering. It is the fundamental shift we all have to prepare for. dbt published its benchmark update, claiming GPT-5.3-Codex with Semantic Layer acheives 100.0% accuracy.
https://docs.getdbt.com/blog/semantic-layer-vs-text-to-sql-2026?version=1.10
Rill: Introducing Metrics SQL: A SQL-based semantic layer for humans and agents
Staying on the metrics and the semantic layer, Rill introduces Metrics SQL to define logic once in YAML and expose it through standard SQL, automating aggregations, enforcing row-level security, and serving governed definitions to AI agents via an MCP server without exposing raw schemas. Deterministic metric resolution eliminates inconsistencies across consumers, while a semantic pushdown roadmap targets native MEASURE support in OLAP engines like ClickHouse and Snowflake.
Meta: How Meta Used AI to Map Tribal Knowledge in Large-Scale Data Pipelines
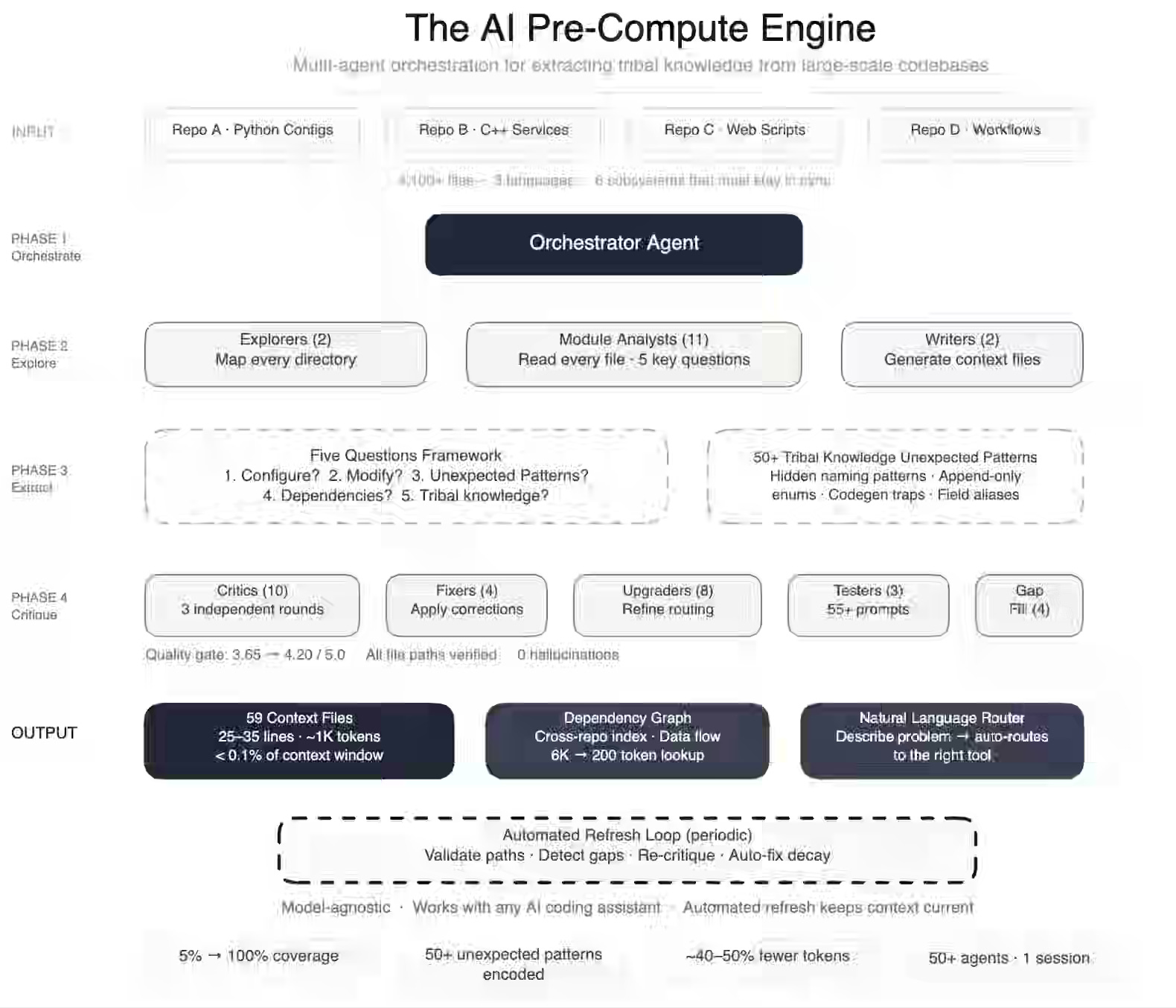
AI coding assistants fail in proprietary codebases because tribal knowledge—implicit design decisions and legacy constraints—remains absent from training data and documentation. Meta Platforms deploys a swarm of 50 specialized agents to map a 4,100-file pipeline into concise context artifacts, using tiered explorer, analyst, critic, and fixer roles with automated decay detection. This system increases context coverage from 5% to 100%, captures over 50 non-obvious patterns, reduces tool-call volume by 40%, and cuts codebase research time from two days to 30 minutes.
Sponsored: The AI Modernization Guide

AI is reshaping how data teams operate. But legacy pipelines, brittle workflows, and fragmented tooling weren’t designed for this shift.
Learn how leading teams are future-proofing their infrastructure before AI demands overwhelm it.
Netflix: Stop Answering the Same Question Twice: Interval-Aware Caching for Druid at Netflix Scale
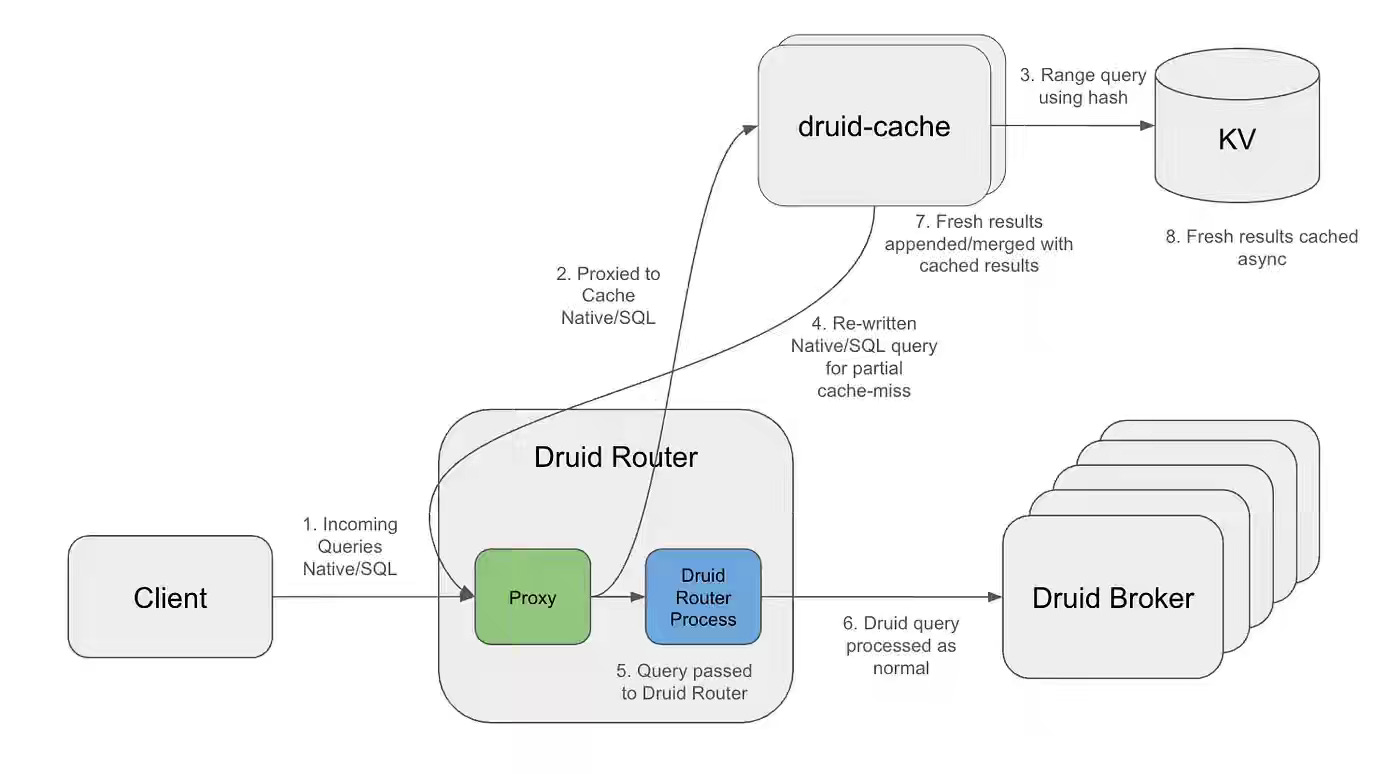
Real-time dashboards with rolling windows invalidate traditional caches because shifting intervals cause repeated misses on otherwise unchanged historical data. Netflix builds an interval-aware caching proxy that decomposes Druid queries into one-minute buckets, serves historical segments from Cassandra, and fetches only the uncached tail from Druid using exponential TTLs ranging from 5 seconds to 1 hour. The system achieves 82% partial cache hit rates, reduces Druid query volume by 33%, improves P90 latency by 66%, and shifts the bottleneck from compute-heavy Druid to low-cost Cassandra storage.
Booking.com: Scaling Experimentation Quality at Booking.com
Underpowered experiments, premature peeking, and inconsistent reporting degrade decision quality as experimentation scales without statistical rigor. Booking.com embeds experimental quality across design, execution, and decision-making through data science ambassadors, peer-review practices, and tooling such as a Quality Tab that enforces power calculations and pre-registered hypotheses in real time. These changes increase the share of high-quality experiments, with the largest gains in design, where proper power improves the reliability of results and decision confidence.
https://booking.ai/scaling-experimentation-quality-at-booking-com-726152ee4ef0
Andros Fenollosa: From zero to a RAG system: successes and failures
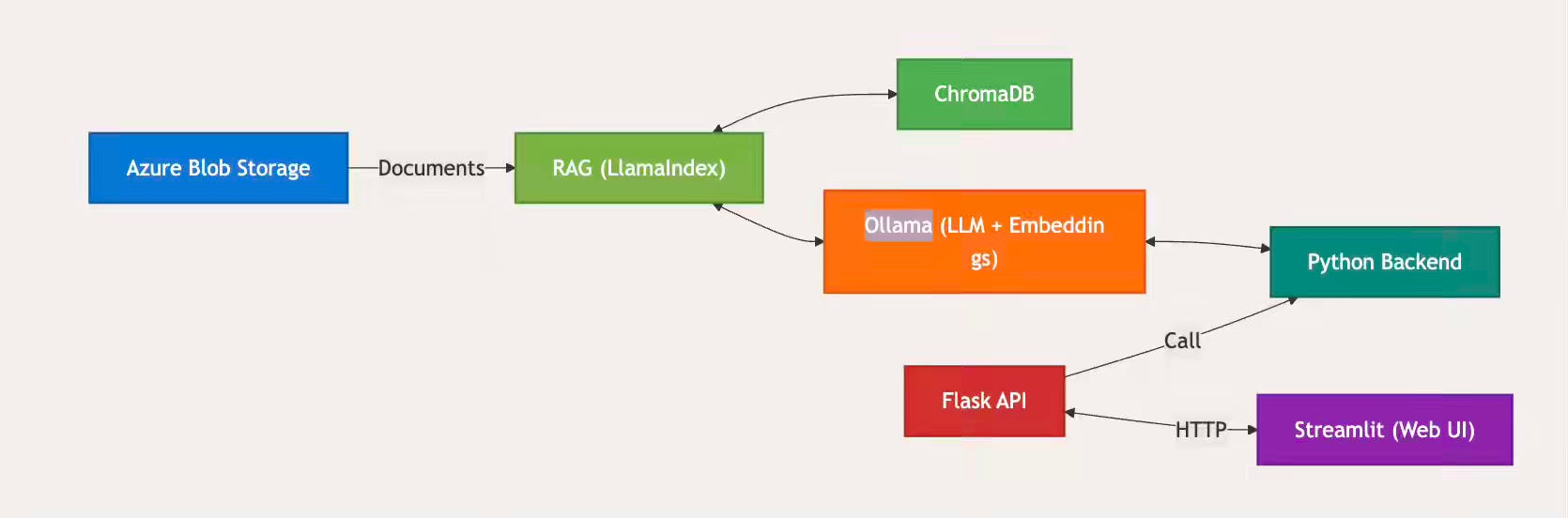
Legacy engineering knowledge locked in unstructured simulation files and technical documents remains inaccessible when confidentiality requirements prohibit sending proprietary data to external LLM APIs. The author writes about building a local RAG system using Ollama, LlamaIndex, and ChromaDB—filtering out non-text files to reduce indexable load by 54% and serving source documents from Azure Blob Storage while staying within a 100GB disk constraint. The architecture delivers confidential retrieval over 1TB of legacy engineering data while establishing batch checkpointing and error-tolerant ingestion as the critical patterns for production RAG deployments at scale.
https://en.andros.dev/blog/aa31d744/from-zero-to-a-rag-system-successes-and-failures/
All Things Distributed: S3 Files and the changing face of S3
The introduction of S3 Files certainly generated a lot of interest on my reading list last week. I’m still studying the impact of S3 files on data pipeline engineering. One thing to note, S3 Files indeed breaks the read-on-write (Write in S3 Files, but read in S3) consistency model. I wonder if the data infrastructure really wants to go back to that world; nonetheless, this is an exciting blog to read to understand the thought process behind S3 Files.
https://www.allthingsdistributed.com/2026/04/s3-files-and-the-changing-face-of-s3.html
Apache Kafka: KIP-848: The Next Generation of the Consumer Rebalance Protocol
Whether you like or dislike Apache Kafka, its KIPs are among the best learning materials for distributed systems. Consumer rebalancing is one of the hottest debated topics in the Kafka world. KIP-848 moves rebalance logic from consumer clients to the Group Coordinator—introducing a ConsumerGroupHeartbeat API, three-layered epochs for group, assignment, and member state, and server-side Range and Uniform assignors that drive incremental partition reconciliation without global synchronization barriers.
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.