
Data Engineering Weekly #268
The Weekly Data Engineering Newsletter


Free Course: AI-Driven Data Engineering
AI coding agents are changing how data engineers work. This Dagster University course shows how to build a production-ready ELT pipeline from prompts while learning practical patterns for reliable AI-assisted development.
This course is designed for engineers exploring agentic coding workflows and engineers who want to learn Dagster or become Dagster power users
Event Highlight: Don't Miss AI Council

- The technical conference for humans who ship
Join the people actually building AI & data infrastructure - and hear them share what’s working, what broke in prod, and what’s coming next. May 12–14 in San Francisco.
Speakers include: The co-inventor of ChatGPT. Creator of DuckDB. Creator of Codex. Engineers from ClickHouse, Databricks, Datadog, and LangChain.
→ Save 20% on your ticket with code DATAEW20 through 5/5
Grab: Data Mesh at Grab Part II: The Foundational Tools behind Certification
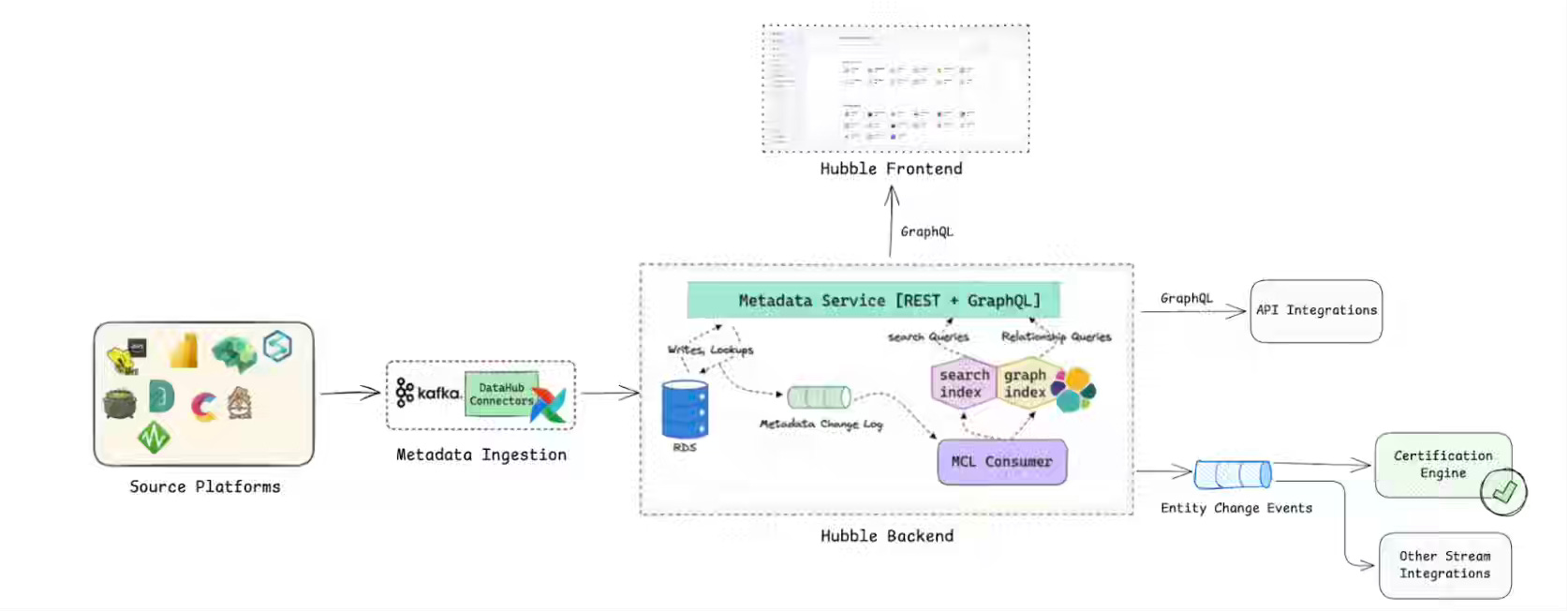
Scaling a data mesh across hundreds of thousands of assets demands enforceable trust, consistent governance, and reliable quality without centralized bottlenecks. Grab operationalizes certification through three integrated platforms — Hubble for metadata and event-driven certification, Genchi for continuous quality validation, and a Data Contract Registry enforcing producer-consumer agreements. The system converts data mesh principles into a metadata-driven workflow, reducing dataset sprawl and driving convergence toward certified, reusable assets anchored to analytics and AI workloads.
https://engineering.grab.com/data-mesh-2
Doug Turnbull: Can agents replace the search stack?
Search APIs depend on layered pipelines for query understanding, retrieval, and reranking, creating complexity that struggles to adapt across heterogeneous user intents. The author writes about testing GPT-5 and GPT-5-mini agents with basic BM25 and e5 embedding tools on Amazon ESCI, lifting NDCG from 0.289 to 0.453 — exploration prompts and duplicate-query rejection further closed the gap on smaller models. The findings reframe retrieval for product-style “finding things” workloads as an agent-driven loop. However, knowledge-gap tasks like MSMarco still favor traditional embedding stacks anchored in dense-retrieval quality.
https://softwaredoug.com/blog/2026/04/28/search-apis-replaced-by-agents
Pinterest: Optimizing ML Workload Network Efficiency (Part I): Feature Trimmer
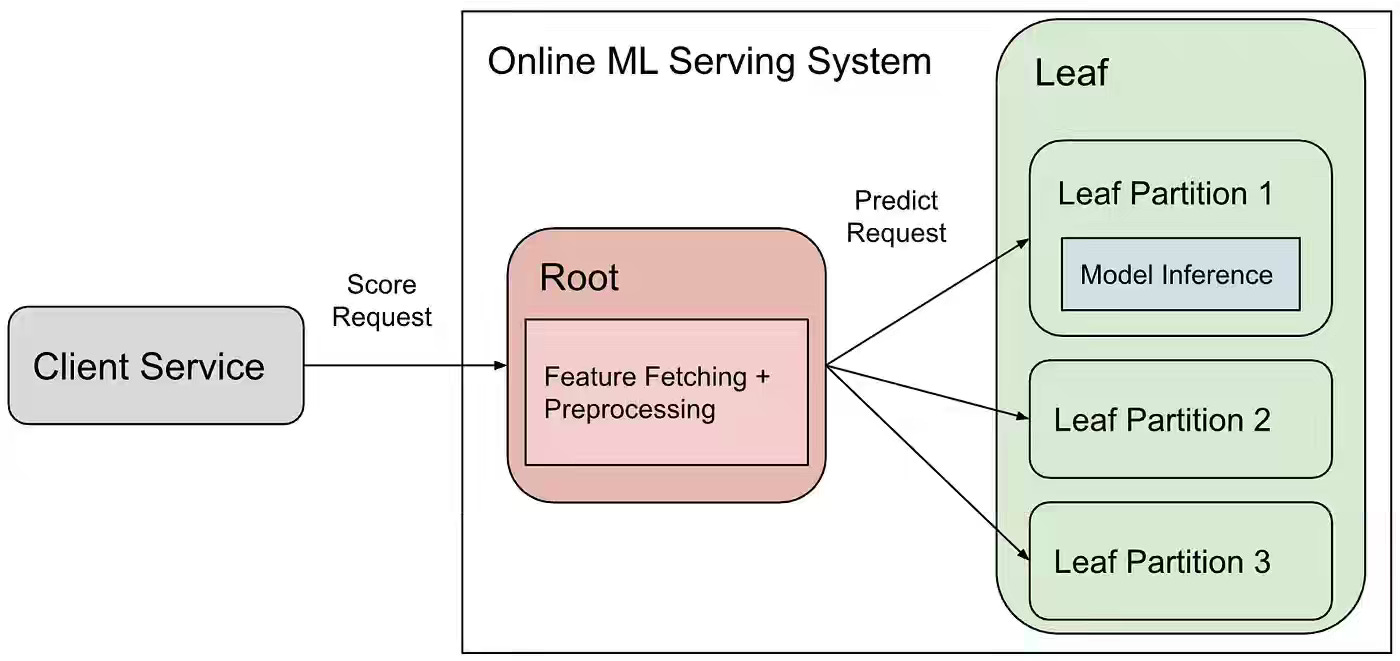
Root-leaf ML serving architectures unlock GPU specialization but bottleneck on network bandwidth when fanning out feature payloads to partitioned model inference. Pinterest writes about building Feature Trimmer, a “Send What You Use” system that treats the model signature as the source of truth — version-aware allowlists sync with bundle deployments through the same staged rollout, fallback, and concurrency safeguards as model configs.
Sponsored: The AI Modernization Guide

Will your data platform accelerate your AI initiatives or become their biggest bottleneck? Learn how to build a data platform that's ready for AI:
- Transform from Big Complexity to AI-ready architecture
- Real metrics from organizations achieving 50% cost reductions
- Introduction to Components: YAML-first pipelines that AI can build
Pinterest: From Clicks to Conversions: Architecting Shopping Conversion Candidate Generation at Pinterest
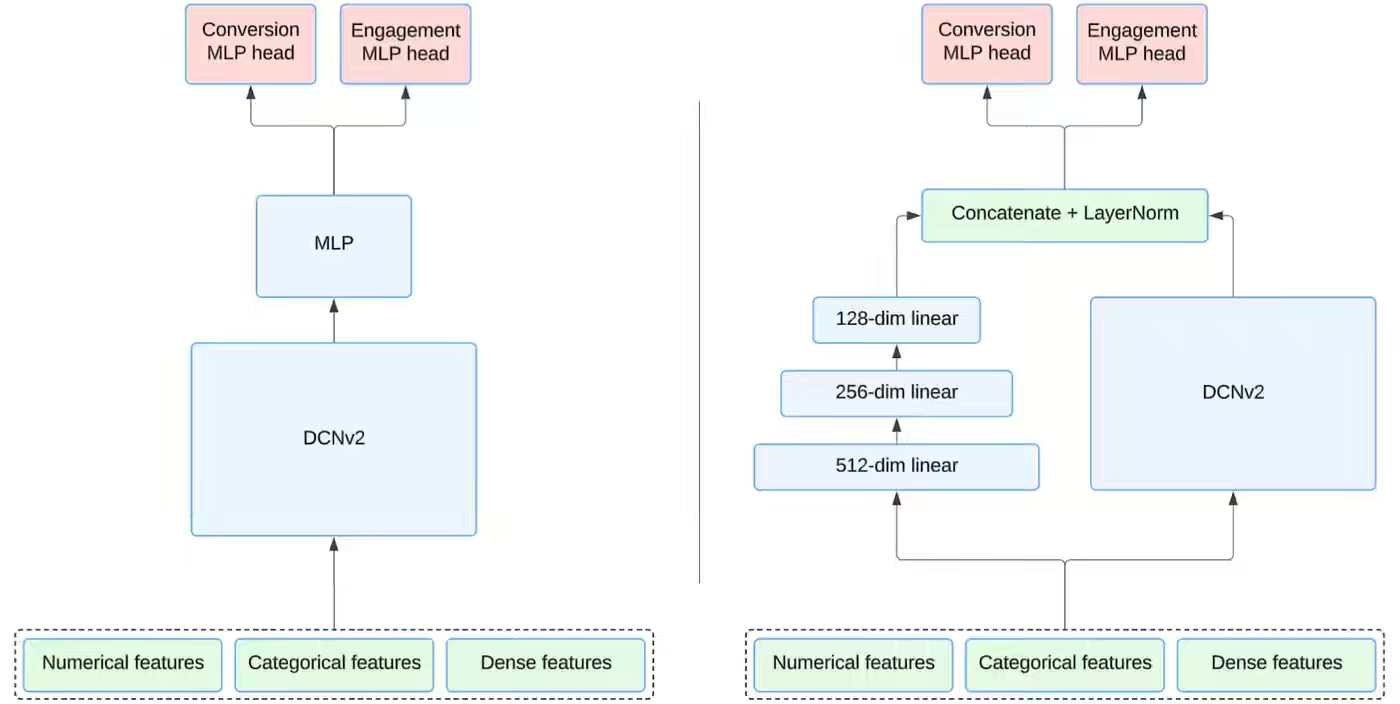
Optimizing ad retrieval for offsite conversions requires modeling sparse, noisy, delayed signals that engagement-based candidate generators were never designed to surface. Pinterest writes about built a two-tower shopping conversion retrieval model that unifies conversions and click-duration-weighted engagement under a single multi-task head, paired with a parallel DCN v2 and MLP cross-layer architecture, and an advertiser-level loss to stabilize sparse Pin-level supervision.
FiveTran: How we accelerated transpilation by compiling SQLGlot with mypyc
Fivetran writes about compiled SQLGlot with mypyc, transpiling type-annotated Python into C extensions, contributing five upstream string primitives, and inlining hot paths like sentinel tokens, native i64 integers, and pre-built dispatch dictionaries — all while preserving the pure Python install path. The compiled sqlglot[c] package accelerates parsing by 5x, SQL generation by 2.5x, and optimizer passes by 2-2.5x, anchored to a dual-distribution model that keeps SQL transpilation portable across multi-engine data lake architectures.
https://www.fivetran.com/blog/how-we-accelerated-transpilation-by-compiling-sqlglot-with-mypyc
Robin Moffatt: Materialized Tables in Apache Flink
Streaming SQL frameworks split table definitions from the population logic, leaving INSERT jobs orphaned across restarts and forcing operators to manage schema evolution and lifecycle as separate concerns. The author walks through Flink 2.2’s Materialized Tables, which bind the refresh query to the table definition and support CONTINUOUS or FULL refresh modes, partition-scoped reloads, suspend/resume via savepoints, and unified batch-streaming semantics through a single FRESHNESS parameter. The construct collapses three legacy patterns — CREATE/INSERT, CTAS, and external schedulers — into a single durable object. However, catalog support beyond Paimon and the embedded scheduler remains anchored in early-stage maturity gaps.
https://rmoff.net/2026/04/28/materialized-tables-in-apache-flink/
Alexey Makhotkin: 5NF and Database Design
Traditional database normalization tutorials present 5NF through contrived table-splitting exercises that obscure the underlying business logic and leave practitioners unable to apply it in practice. The author reframes 5NF design around two logical patterns — the AB-BC-AC triangle for independent M: N relationships across three anchors, and the ABC+D star pattern, where a fourth entity binds three 1:N links — thereby driving table construction directly from business requirements rather than from post hoc decomposition. The approach replaces 5NF reasoning with a deterministic logical-to-physical workflow, anchored to anchor-link modeling that produces normalized schemas without invoking decomposition theorems.
https://kb.databasedesignbook.com/posts/5nf/
ultrathink: SQLite in Production: Lessons from Running a Store on a Single File
Single-file embedded databases promise operational simplicity, but their filesystem-level locking model breaks down when modern container orchestration introduces concurrent writers across overlapping deploys. Ultrathink writes about running a production e-commerce store on Rails 8 with four SQLite databases on a shared Docker volume, diagnosing lost orders through sqlite_sequence after eleven rapid Kamal blue-green deploys caused overlapping containers to corrupt WAL writes despite successful Stripe charges.
https://ultrathink.art/blog/sqlite-in-production-lessons
Capital One: Spark tuning: executor optimization for performance
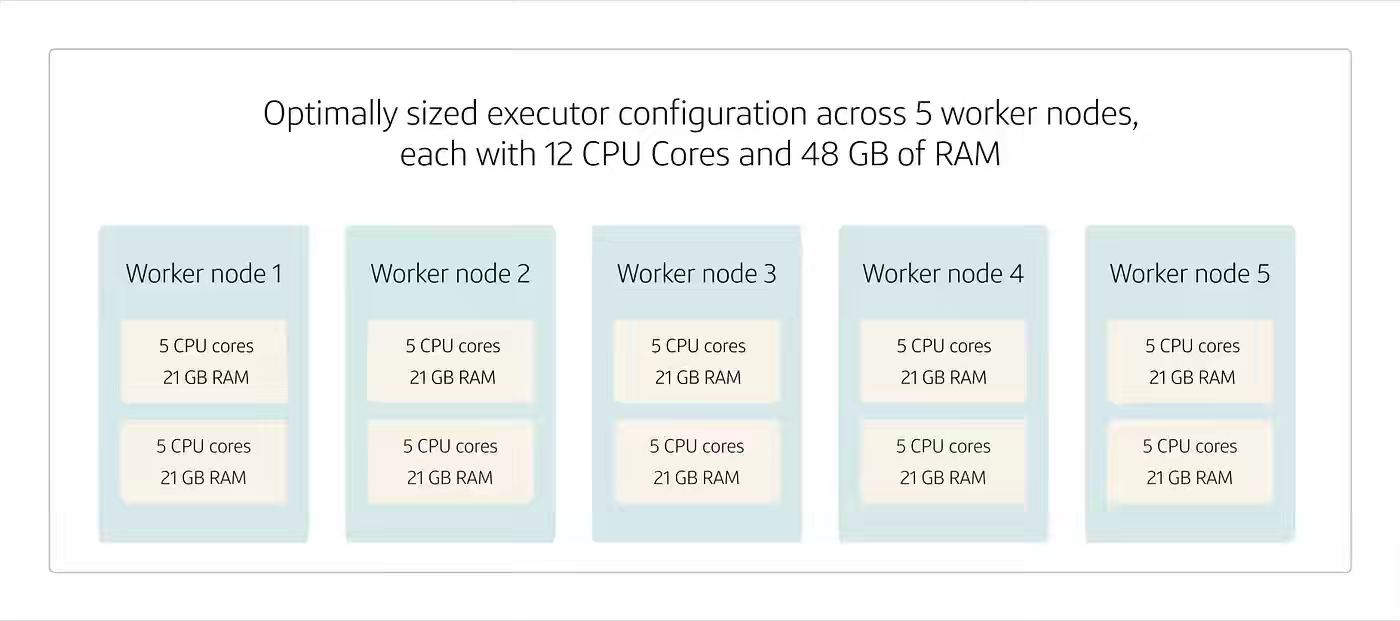
Spark applications often underperform when executors are configured by default, leaving CPU cores and memory underutilized while introducing fault-tolerance risks and network overhead across worker nodes. Capital One Tech walks through executor sizing trade-offs — fat executors maximize data locality but concentrate failure risk, thin executors improve parallelism but flood the network — and codifies an optimal configuration recipe reserving cores and memory for OS overhead, capping executors at 3-5 cores, and accounting for the 384 MB or 10% memory overhead. The framework converts executor tuning from guesswork into a deterministic sizing exercise, anchored to balanced parallelism, fault tolerance, and resource utilization across distributed Spark clusters.
https://medium.com/capital-one-tech/spark-tuning-executor-optimization-for-performance-c757b39f0efe
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.