
Data Engineering Weekly #269
The Weekly Data Engineering Newsletter


The Data Platform Fundamentals Guide
We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating under a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Meta: How We Built an AI Second Brain for 60K Knowledge Workers
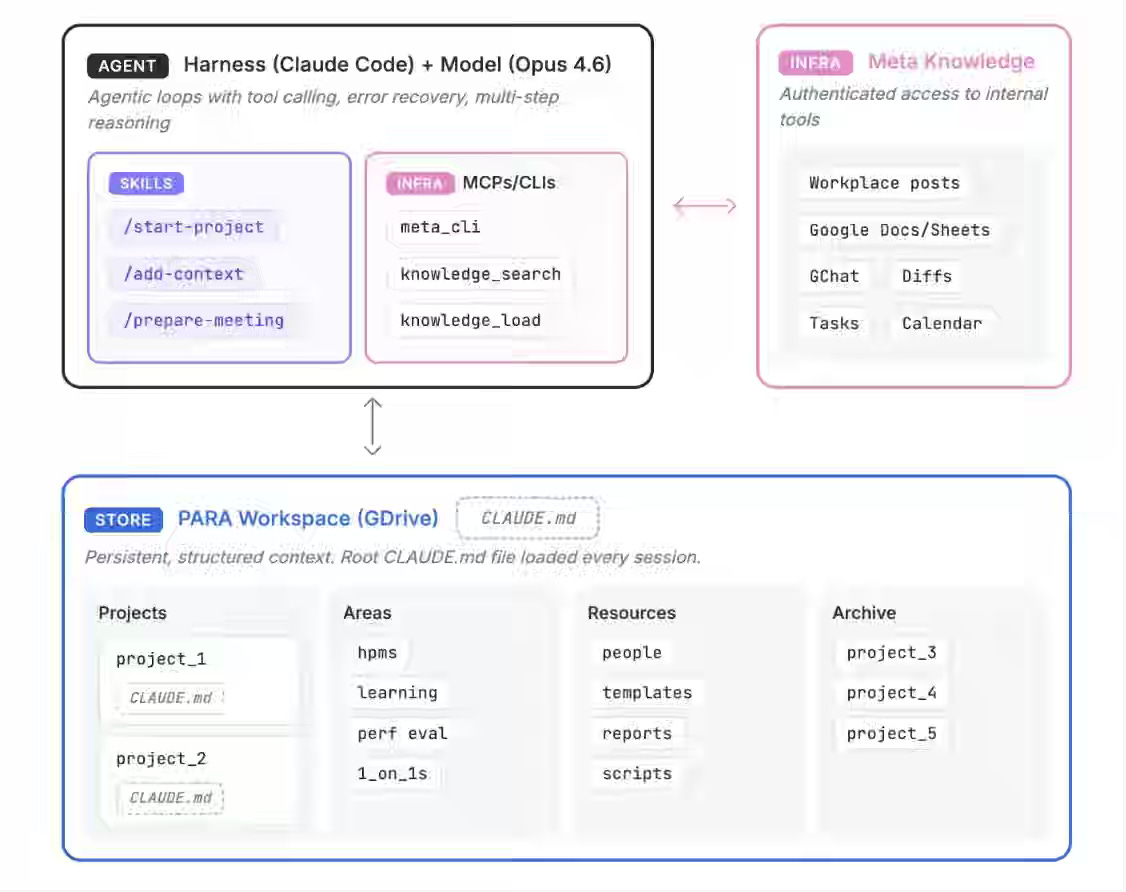
Meta writes about building an AI Second Brain that combines a PARA-based workspace model, authenticated infrastructure access via MCPs and CLIs, agentic execution loops, and reusable markdown-defined skills that continuously organize, retrieve, and act on structured work context across tools and projects. The article is a classic case of data engineering evolving into context engineering, making a broader impact in the industry.
Salesforce: How Informatica Built a Multi-Agent AI System to Reduce Data Workflows from Months to Days
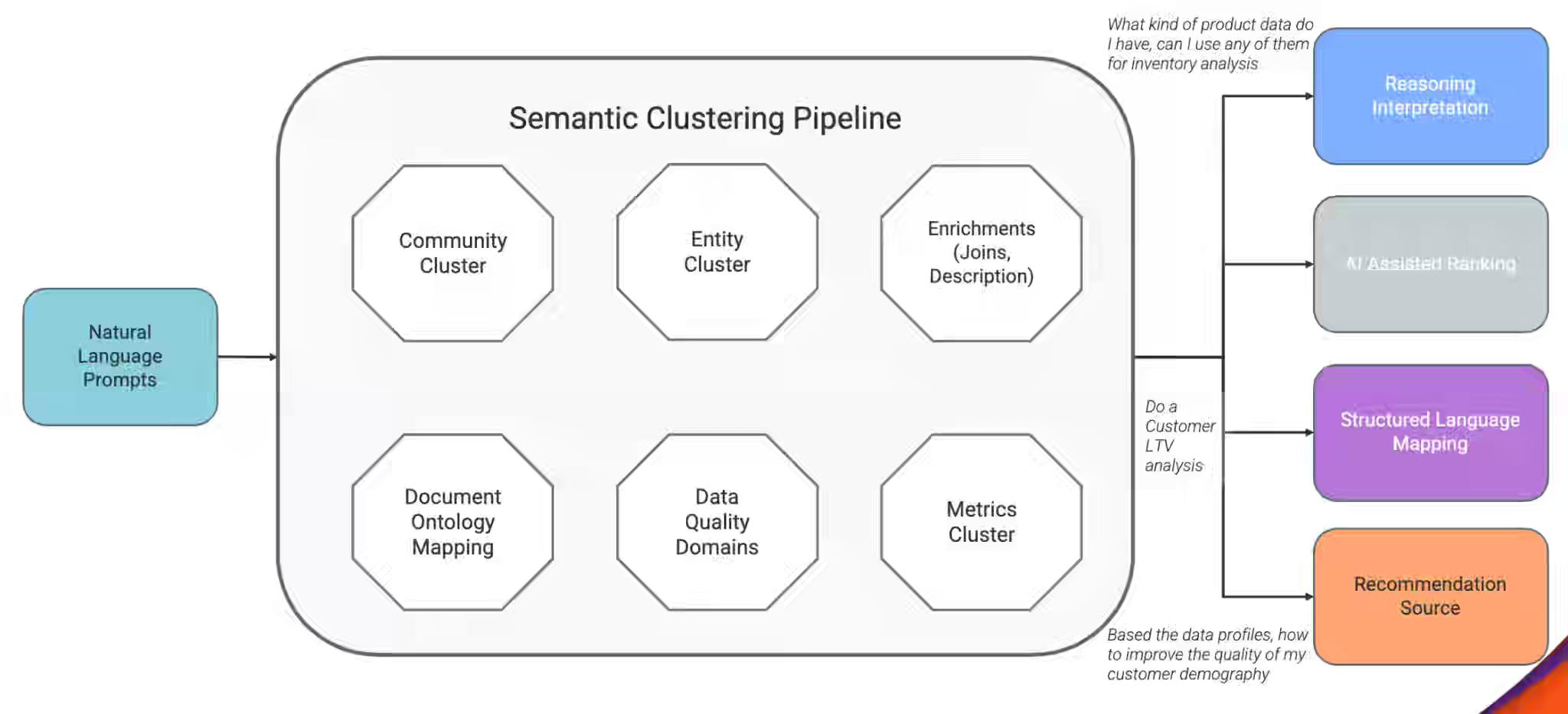
Enterprise data workflows break down when discovery, governance, data quality, and orchestration span disconnected systems, requiring repeated human coordination across tools, teams, and execution stages. Informatica writes about the CLAIRE platform, which addresses fragmentation through a multi-agent architecture that combines orchestration agents, semantic context modeling, deterministic tool routing, and specialized execution agents to coordinate workflows involving 50–60 model calls with validation checkpoints and adaptive planning.
Netflix: Democratizing Machine Learning at Netflix: Building the Model Lifecycle Graph
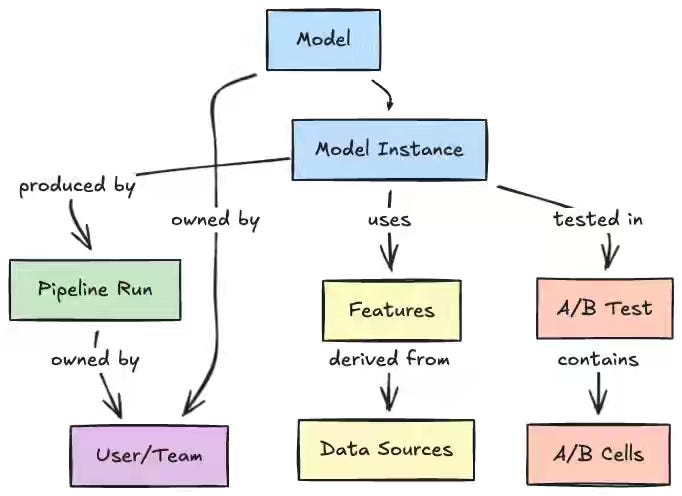
ML platforms fragment across registries, orchestrators, feature stores, and experimentation systems, forcing practitioners to traverse multiple tools to trace lineage or reuse assets across domains. Netflix writes about its Metadata Service, which ingests events via a unified AIP URI scheme and materializes a Model Lifecycle Graph in Datomic, connecting models, features, pipelines, and experiments through asynchronous enrichment. The graph collapses multi-system investigations into a single GraphQL traversal from models to features to pipelines to A/B tests, standardizing cross-domain discovery anchored in a normalized entity model.
Sponsored: Free Course: AI-Driven Data Engineering

AI coding agents are changing how data engineers work. This Dagster University course shows how to build a production-ready ELT pipeline from prompts while learning practical patterns for reliable AI-assisted development.
This course is designed for engineers exploring agentic coding workflows and engineers who want to learn Dagster or become Dagster power users
Confluent: Stream Processing vs. Real-Time OLAP: Flink, ClickHouse & Pinot Compared
Real-time data platforms routinely collapse when teams treat stream processors and OLAP engines as substitutes, exposing dashboards to stateful pipelines or routing continuous ETL through scan engines. Confluent writes about drawing the boundary at computation timing — stream processors evaluate data in motion through event-time windows and watermarks. In contrast, OLAP engines evaluate data at rest through columnar scatter-gather scans.
Kirill Bobrov: The Power of Data Sketches: A Comprehensive Guide
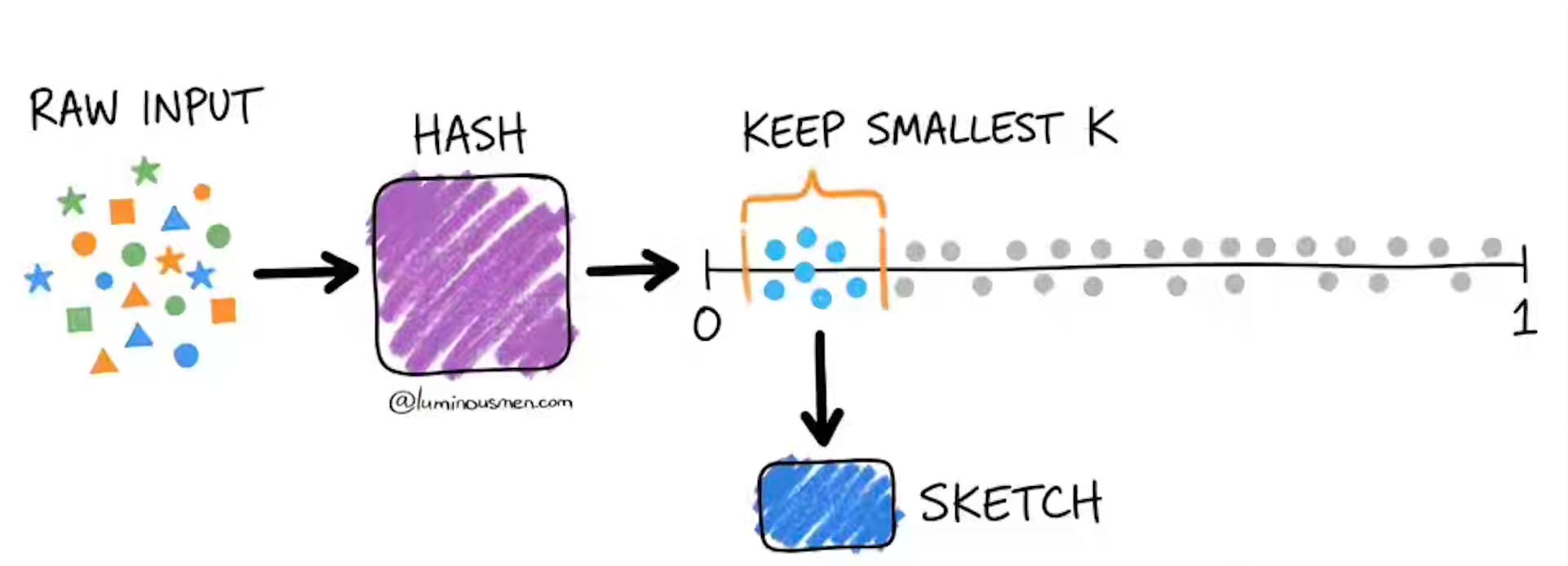
Exact answers to cardinality and quantile queries become infeasible at the billion-event scale because COUNT DISTINCT shuffles every unique value across the cluster rather than aggregating partially. The author walks through Apache DataSketches — Theta, HyperLogLog, CPC, KLL, and Frequent Items — replacing full-data shuffles with kilobyte hash summaries that merge across partitions. Sketches shift analytics from query-time scans to precomputed dimensional cubes, trading bounded approximation for parallel ingestion and late-data merges, anchored in a fixed-memory streaming model.
https://luminousmen.com/post/the-power-of-data-sketches-a-comprehensive-guide/
Whatnot: The ML Feature Pipeline That Got Slower and No One Noticed
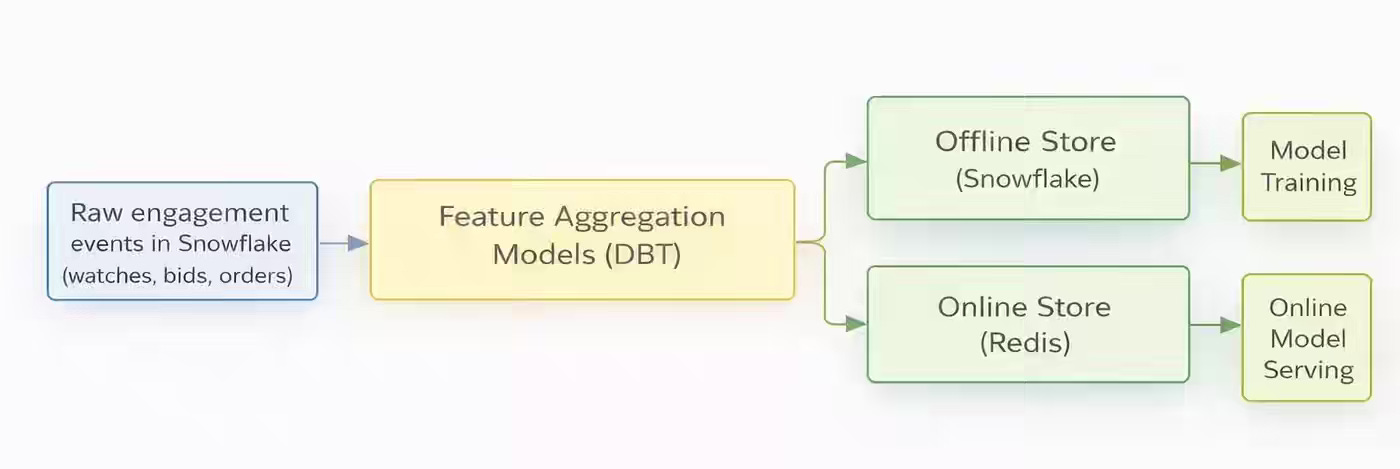
Hourly pipelines leave a shorter window to catch errors, compressing the failure window and exposing silent degradation — zero-row regressions, runtime drift, and cadence slippage that never trigger threshold alerts. Whatnot writes about handling such pipeline failures by splitting monitoring into two tiers — a zero-row signals page on-call, and distribution shifts routed to Slack — backed by a 2-day Redis TTL that absorbs missed updates.
Pinterest: Enhancing Ad Relevance: Integrating Real-Time Context into Sequential Recommender Models
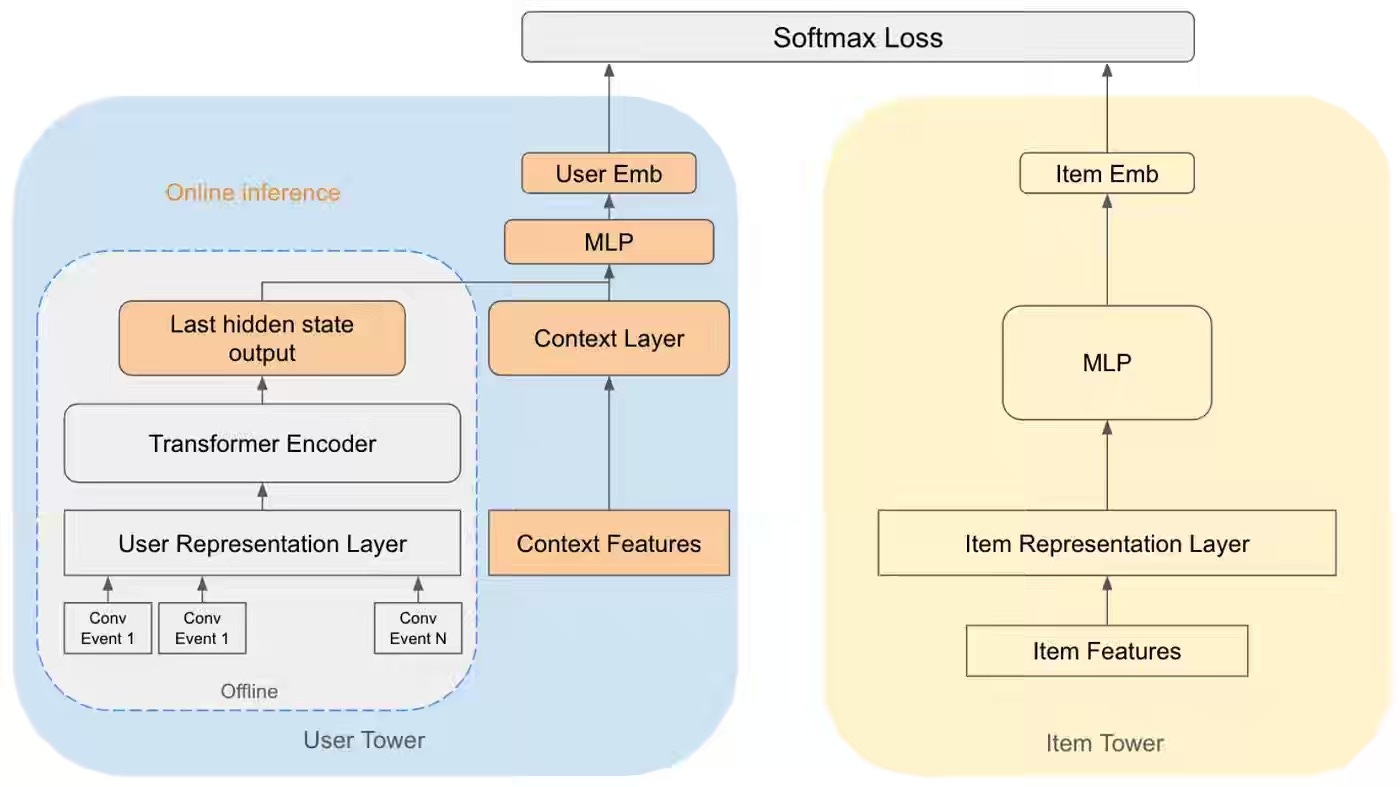
Sequential recommender models trained on offline behavioral history fail on contextual surfaces because the user embedding ignores what the viewer is currently browsing. Pinterest writes about injecting a context layer into the two-tower query tower — concatenating Transformer history with subject-Pin features and training with synthetic context from positive labels. The hybrid flow precomputes the Transformer offline and runs the context layer online, lifting Recall@K by 3-10x and ROAS by 0.7%, anchored to dynamic user embeddings.
Grab: Enhancing Flink deployment with shadow testing.
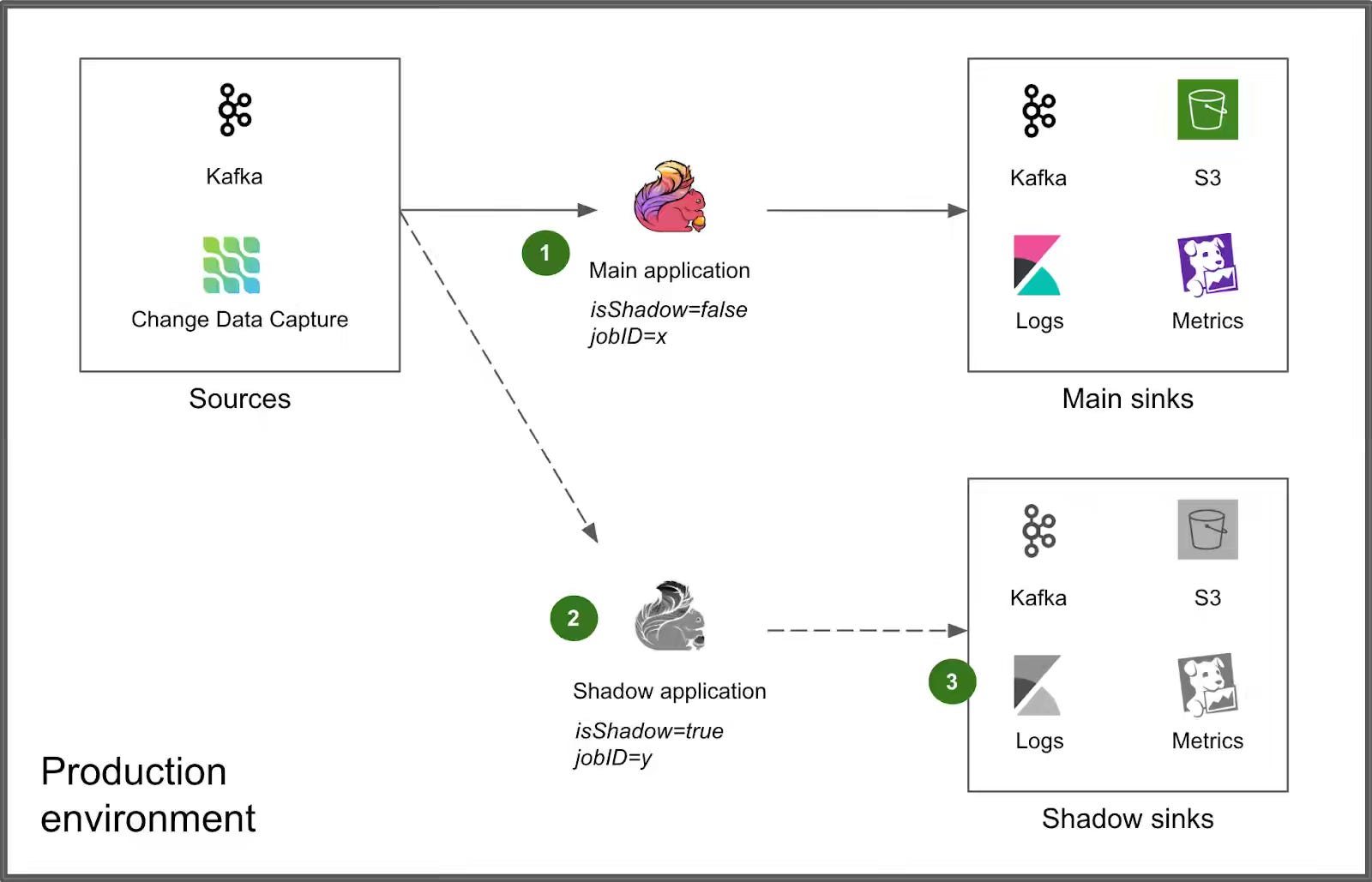
Staging environments cannot reproduce production-specific failure modes in streaming applications — checkpoint incompatibility, traffic shape, and environment drift only surface under live traffic. Grab writes about adding a Shadow Testing stage to its Flink deployment pipeline — running a parallel shadow job in an isolated Kubernetes namespace with prefixed Kafka consumer groups and dedicated shadow sinks. The pre-deployment shadow run absorbs the failure window that caused 10-minute rollback outages, raising Deployment Frequency and cutting Change Failure Rate, anchored to connector-level isolation.
https://engineering.grab.com/enchancing-flink-shadow-testing
Halodoc: Building Self-Healing Data Pipelines at Halodoc

Generic retry-everything pipeline recovery breaks down at scale because CDC restarts, OOM failures, orphaned warehouse queries, and cascading backfills each demand distinct checkpoint logic. Halodoc layers six targeted recovery mechanisms — CDC restart with three-gate eligibility checks, file-size-aware mini-batching, OOM-classified retry scaling, and watermark-based warehouse lock cancellation. The platform cuts CDC recovery to under 5 minutes, drops on-call alerts by 80%, and collapses backfill setup to 15 minutes, anchored to per-failure-mode contracts.
https://blogs.halodoc.io/building-self-healing-data-pipelines-at-halodoc/
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.