
Data Engineering Weekly #270
The Weekly Data Engineering Newsletter


The Data Platform Fundamentals Guide
We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating under a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Airbnb: Viaduct 1.0 and the future of Airbnb’s data mesh
The term Data Mesh focuses on the platform & services, Viaduct aims to be the multi-tenant GraphQL system, unlike the data mesh as we know it in data engineering. However, the first principle of Viaduct is something the data teams should drive towards to bring a more connected experience across the business functions.
One global schema. Independent teams contribute schema and resolvers
https://medium.com/airbnb-engineering/viaduct-1-0-and-the-future-of-airbnbs-data-mesh-6bab4ec98b89
Netflix: Data Projects: Managing Data Assets at Netflix Scale
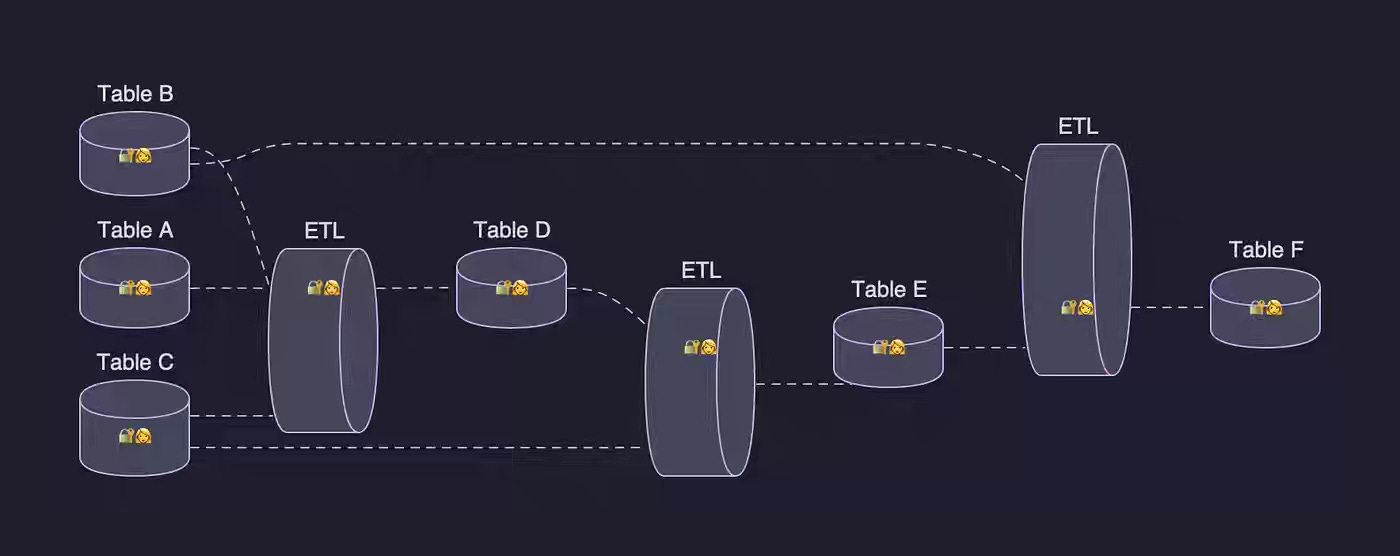
Netflix writes about the operational challenges of enforcing ACLs at the individual user level. When pipelines run under an On-Behalf-Of permission model, access frequently breaks when employees change teams or leave the organization. To address this, Netflix adopts the concept of Data Projects, replacing user-bound identities with durable, team-owned application identities.
https://netflixtechblog.medium.com/data-projects-managing-data-assets-at-netflix-scale-7ca25888591e
Sponsored: Agents for Data Engineering
AI agents are transforming data engineering — but they need the right tools to do it reliably.

Altimate Code in an open-source project that gives any agent 100+ deterministic tools for SQL, lineage, dbt, and warehouse connectivity, with a proven #1 ranking on ADE-Bench. One install. Tech-stack agnostic. No hallucinations. Production-ready from day one.
Meta: Migrating Data Ingestion Systems at Meta Scale
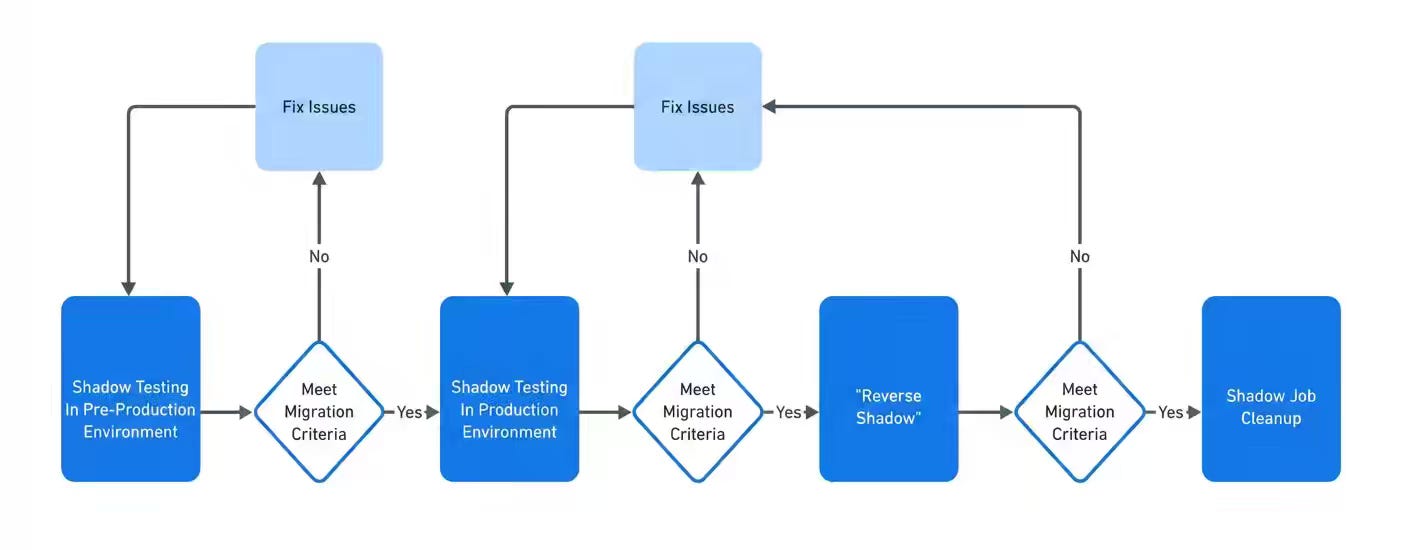
Meta writes about successfully migrating tens of thousands of mission-critical pipelines at the petabyte scale. The blog focused on how it ensures the shadow testing mode to enable end-to-end robustness of the migration process. The partition-level metadata flags are an interesting approach. If a partition was marked as “bad,” the system automatically halted new delta landings and forced merges with older, known-good partitions, stopping the bleeding instantly.
Databricks: The Convergence of Open Table Formats and Open Catalogs: Catalog Commits is Generally Available
The data infrastructure went through a full lifecycle, from Hive metastore to S3 as the primary metastore, and back to catalogs. Databricks writes about the convergence of table formats and the catalogs, with how Unity Catalog and Delta Lake formats interplay.
Sponsored: Free Course - AI-Driven Data Engineering

AI coding agents are changing how data engineers work. This Dagster University course shows how to build a production-ready ELT pipeline from prompts while learning practical patterns for reliable AI-assisted development.
This course is designed for engineers exploring agentic coding workflows and engineers who want to learn Dagster or become Dagster power users
Eric Sun: A Query Proxy for Analytical and Fast Data
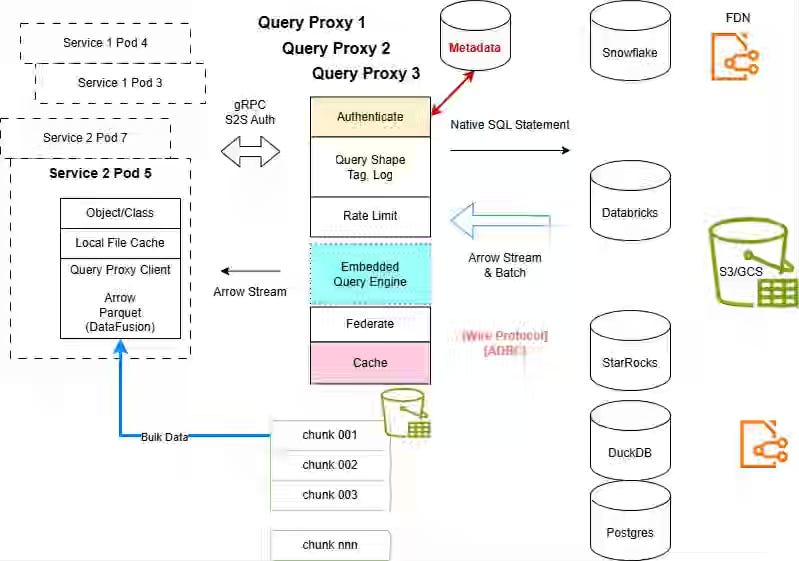
The author writes about the Query Proxy, which fronts Snowflake, Databricks, StarRocks, and Iceberg via gRPC, with service-credential-based RBAC, and returns async query IDs and presigned Parquet URLs to clients. The proxy collapses per-engine clients into a single interface, federates hot Postgres data with warm Iceberg partitions, and tracks query-shape telemetry, all anchored to a stateless gateway model.
https://eric-sun.medium.com/a-query-proxy-for-371907878996
The Craft: How we rebuilt search ranking at Faire with deep learning
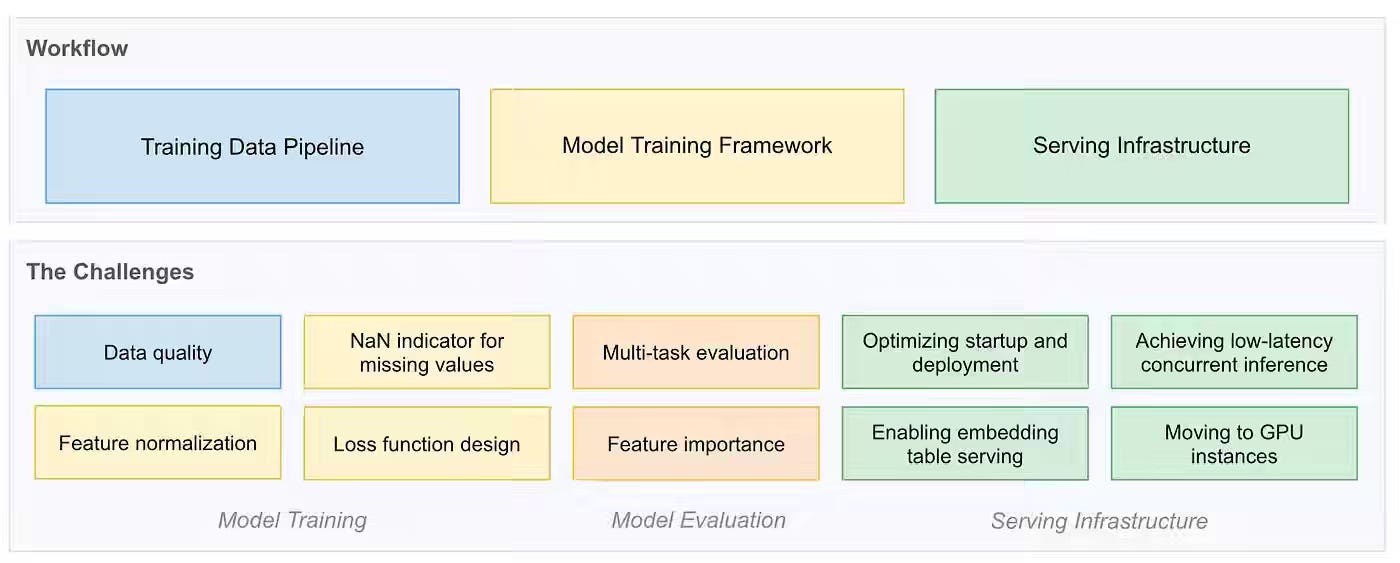
Faire writes about replacing XGBoost with a Deep and Cross Network trained with session-normalized listwise cross-entropy, then accelerates new-ranker development by fine-tuning Brand Page models from Product Search. The rebuild increases Product Search order volume by 2.14% in North America and 1.54% in Europe while cutting new-surface launch cycles by half through a shared multi-task representation.
https://craft.faire.com/how-we-rebuilt-search-ranking-at-faire-with-deep-learning-14f080679c83
Alibaba: When MySQL Meets the Columnar Storage Engine DuckDB in the AI Era
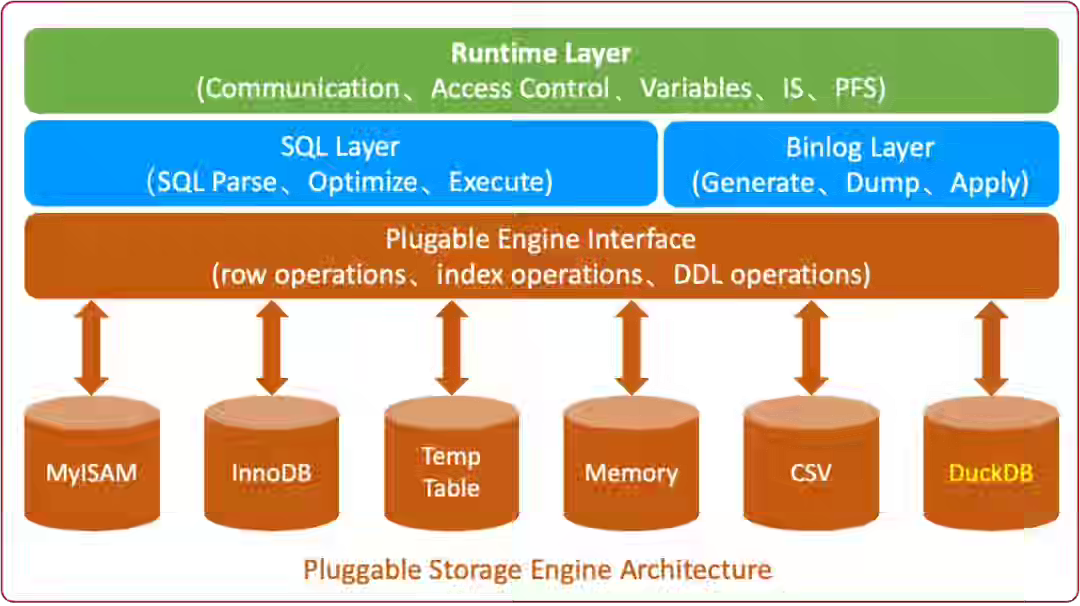
AliSQL writes about integrating DuckDB as a pluggable storage engine, transforming MySQL into a lightweight Hybrid Transactional and Analytical Processing (HTAP) database. Motherduck recently released the client-server protocol DuckDB, as it is slowly moving to a warehouse-style engine on its own.
Marc Bowes: Aurora DSQL: Meet Coupler
The author writes about the design of Coupler, a highly scalable CDC solution for Aurora DSQL. Traditionally, CDC is hard on databases and degrades performance. Because DSQL’s architecture already decouples its read/write paths using a low-latency journal fan-out, Coupler acts as another subscriber, making it highly performant.
https://marc-bowes.com/dsql-coupler.html
Pete: Full-Text Search with DuckDB
The author writes about DuckDB’s Full-Text Search (FTS) extension for data workflows, such as exploratory text mining and document archive analysis. The development is worth watching, as I have always found cases that balance both free-text analytics and typical exploratory analysis. Apache Pinot & ParadeDB are the two systems I know of that try to handle these cases.
https://peterdohertys.website/blog-posts/full-text-search-w-duckdb.html
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.