
Data Engineering Weekly #272
The Weekly Data Engineering Newsletter


How to Build a Data Platform
We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating under a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Netflix: High-Throughput Graph Abstraction at Netflix
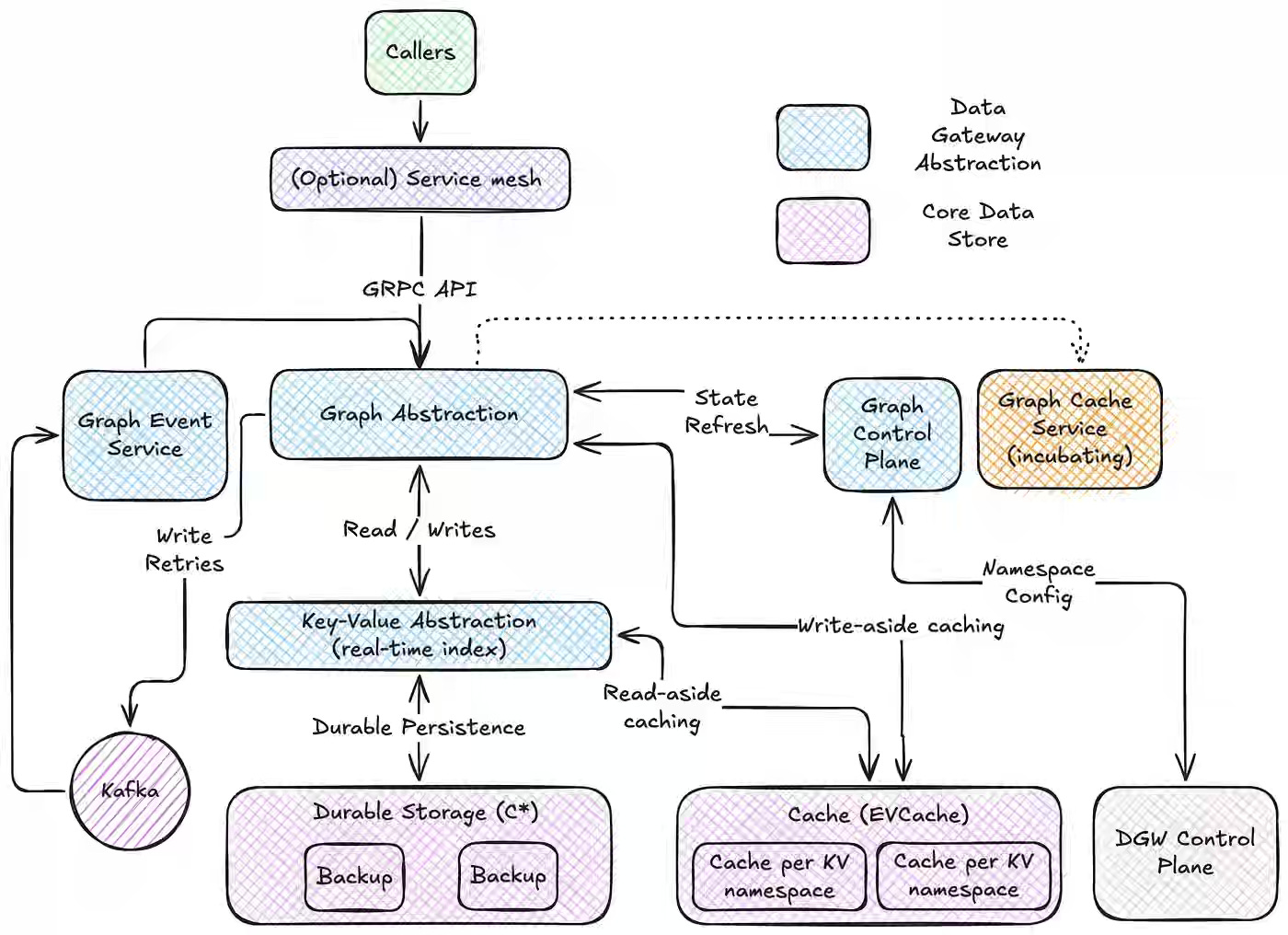
One emerging data model envisions the organization model as a property graph abstraction, though the underlying data may be stored in a relational model, key/value store, or document store. GraphQL is one abstraction, but it leads to many complications while integrating the api. Netflix writes about its high-throughput graph abstraction and explains how it handles read-aside cache and write-aside cache.
https://netflixtechblog.com/high-throughput-graph-abstraction-at-netflix-part-i-e88063e6f6d5
Slack: Slack AI - The Path to Multi-Cloud
Building AI Infrastructure for a multi-tenant stack with enterprise security requirements is challenging in itself. Slack writes about evolving from SageMaker-managed endpoints to Bedrock provisioned throughput, Bedrock on-demand spillover, and a multi-cloud Vertex AI architecture with normalized APIs, model hierarchies, circuit breakers, health-aware routing, and feature-level model selection. The platform focuses on reducing the infrastructure lock-in, enabling same-day model migration, improving the quality of complex reasoning by about 10%, cutting latency for low-token workloads by about 67%, and increasing resilience against regional and provider-wide failures.
https://slack.engineering/slack-ai-the-path-to-multi-cloud/
Sponsored: Agents for Data Engineering

AI agents are transforming data engineering — but they need the right tools to do it reliably.
Altimate Code in an open-source project that gives any agent 100+ deterministic tools for SQL, lineage, dbt, and warehouse connectivity, with a proven #1 ranking on ADE-Bench. One install. Tech-stack agnostic. No hallucinations. Production-ready from day one.
Uber: Solving the Identity Crisis for AI Agents
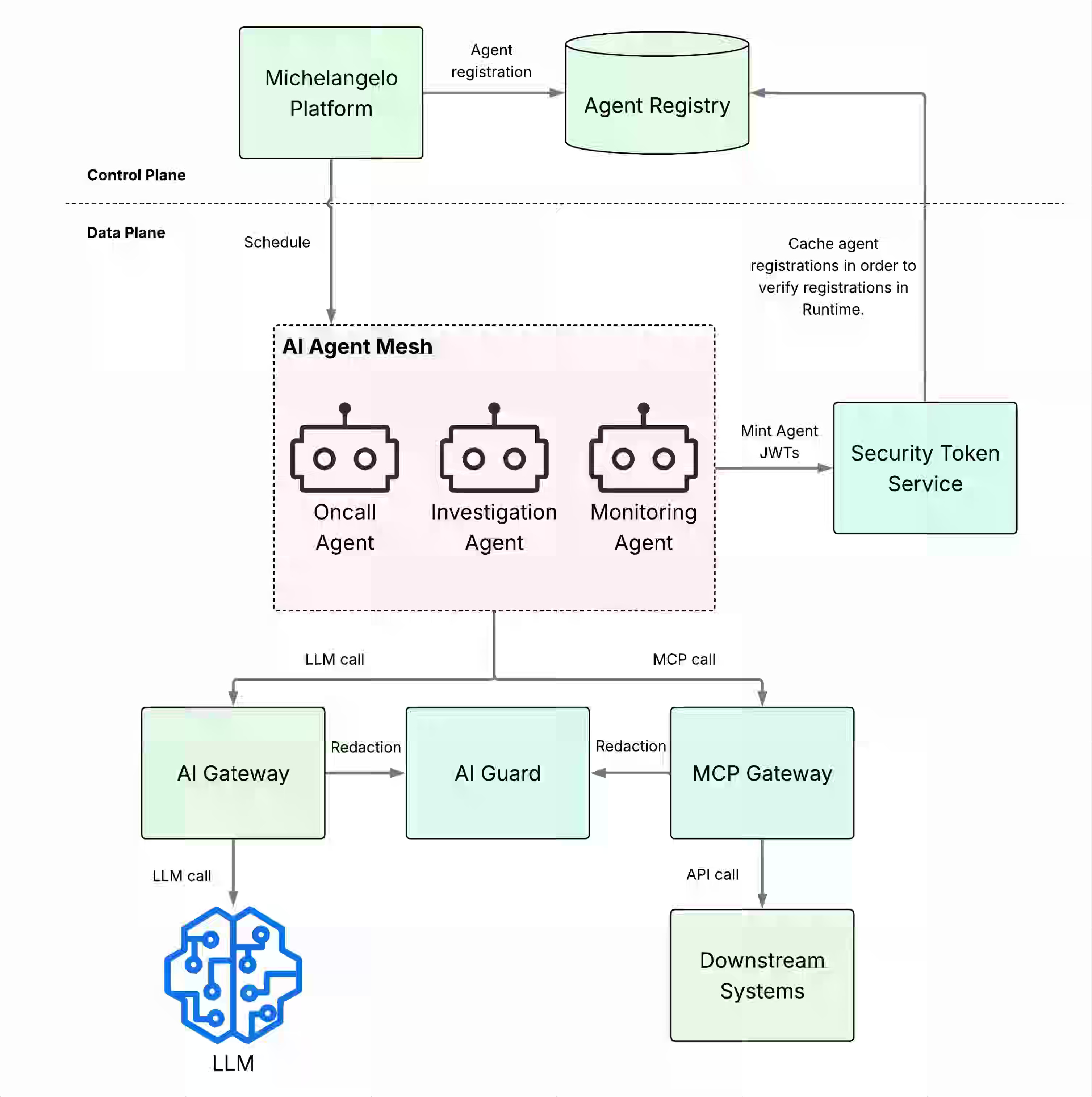
The article seems so timely, as I recently finished a similar design for AI Identity. The conventional way to start the design is to assign the user role to the agent to work on their behalf, but the model soon fails. The services-centric IAM role also fell apart, since the same service can potentially assume multiple roles. Uber provides an in-depth account of how it handles these challenges.
https://www.uber.com/us/en/blog/solving-the-agent-identity-crisis/
Mehul Batra: A field journal on Ray Data and Daft for multimodal data lake
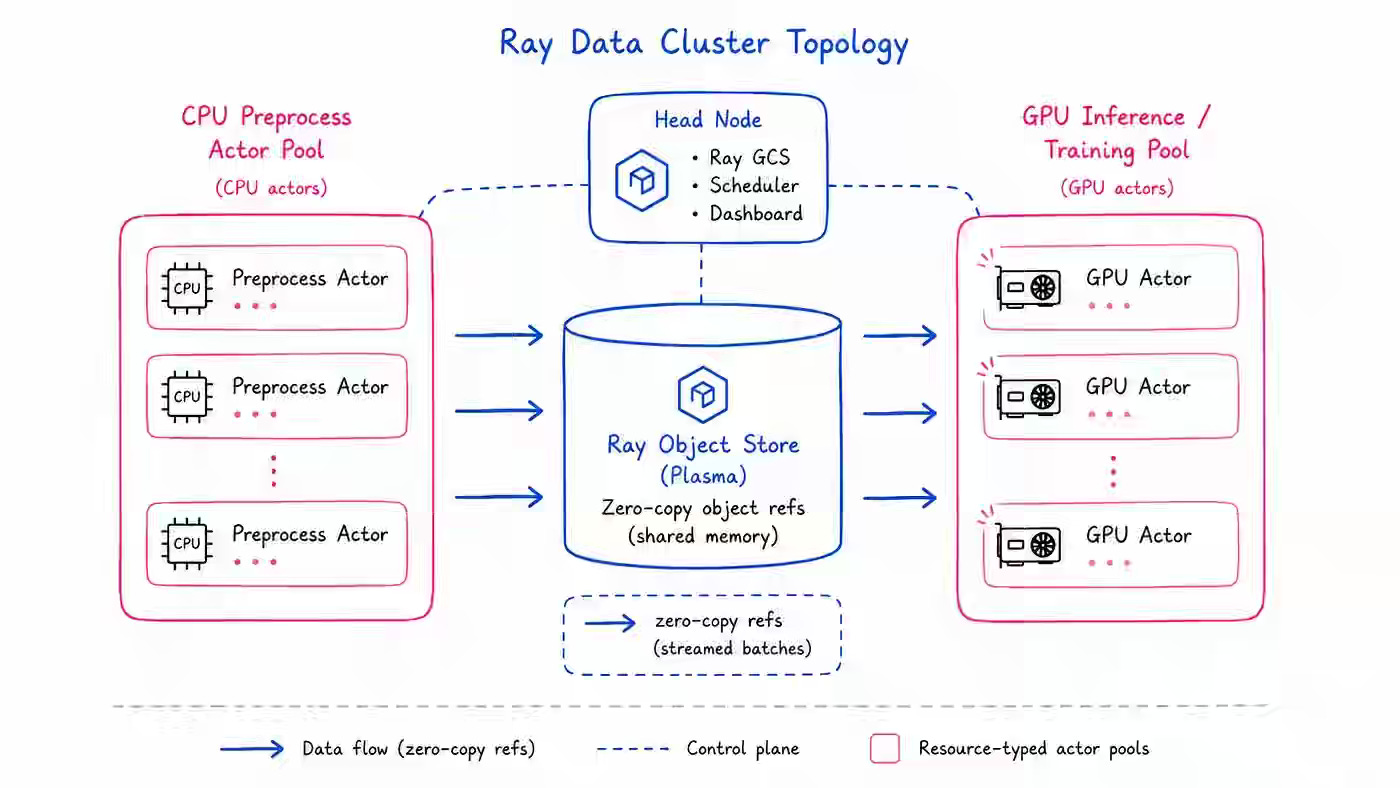
Multimodal data lake pipelines on Kubernetes require engines that can handle mixed CPU, GPU, and async inference workloads, along with cataloging and checkpointing, across text, PDF, image, audio, video, and LLM metadata. The author compares Ray Data 2.55.1 and Daft 0.7.13 on the same KubeRay, DigitalOcean, Gravitino, Iceberg, Lance, and H100 setup, measuring wall time, GPU occupancy, memory, code size, native primitives, concurrency behavior, and completion reliability across eight use cases. Ray Data scored 56 versus Daft’s 47 out of 70 because both engines tied on most multimodal batch workloads, Daft delivered stronger native media ergonomics, and Ray Data won the decisive async LLM inference workload by completing the 50k-email job with enforced concurrency while Daft failed to finish.
Sponsored: AI Modernization Guide

AI is reshaping how data teams operate. But legacy pipelines, brittle workflows, and fragmented tooling weren’t designed for this shift.
Learn how leading teams are future-proofing their infrastructure before AI demands overwhelm it.
LakeOps: Routing Multiple Query Engines with Iceberg
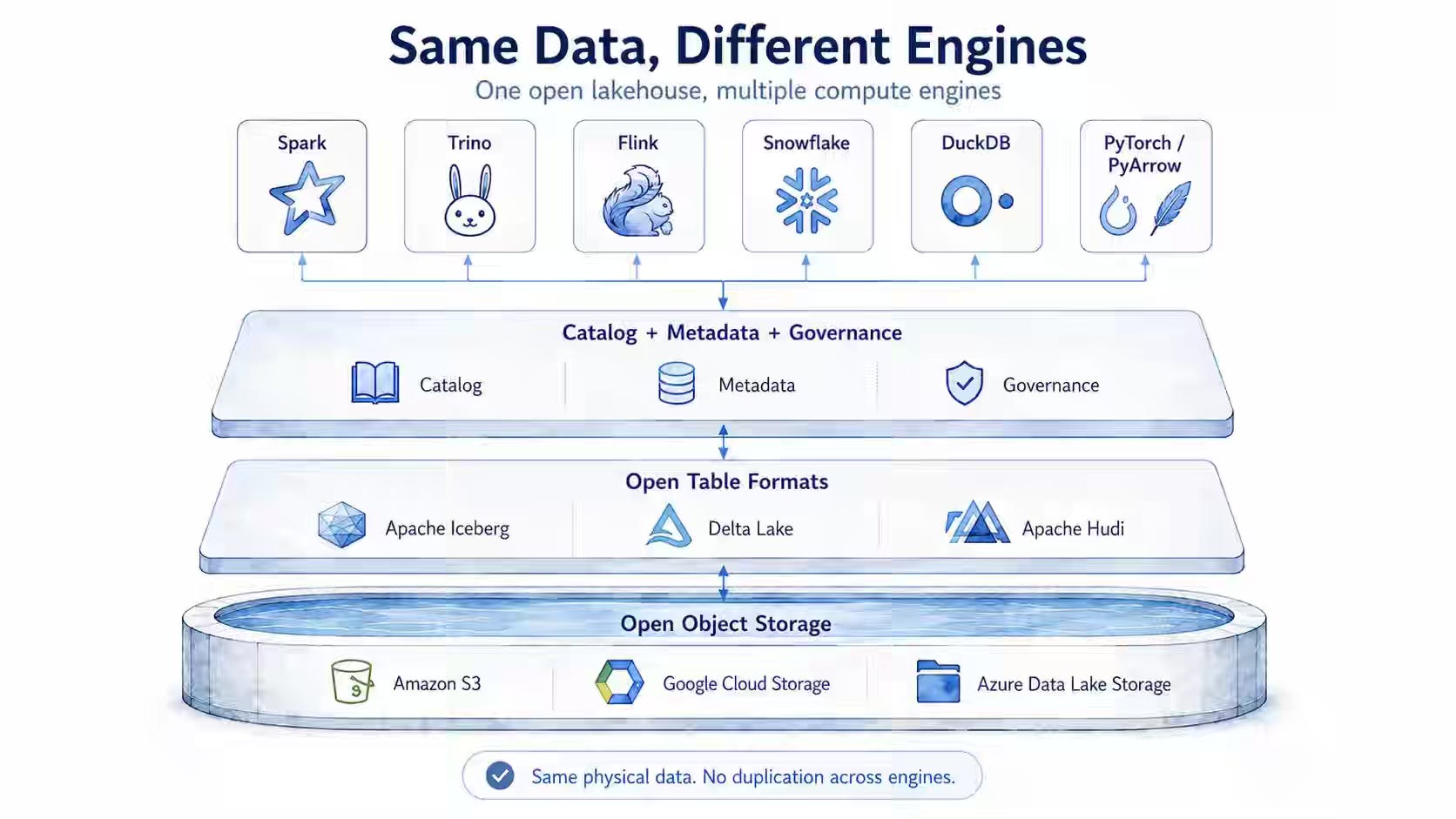
Multi-engine Iceberg deployments let Spark, Trino, Flink, DuckDB, Athena, Snowflake, and StarRocks share the same tables. Still, they leave query placement, cost control, dialect compatibility, and workload isolation to each client team. LakeOps writes about QueryFlux, a Rust-based SQL routing proxy that supports existing database protocols, selects engine groups via routing rules, translates SQL dialects with sqlglot, enforces concurrency limits, and dispatches queries based on cost, latency, throughput, or health.
https://lakeops.dev/blog/routing-multiple-query-engines-with-iceberg
Rion Williams: Prepare for Launch: Enrichment Strategies for Apache Flink
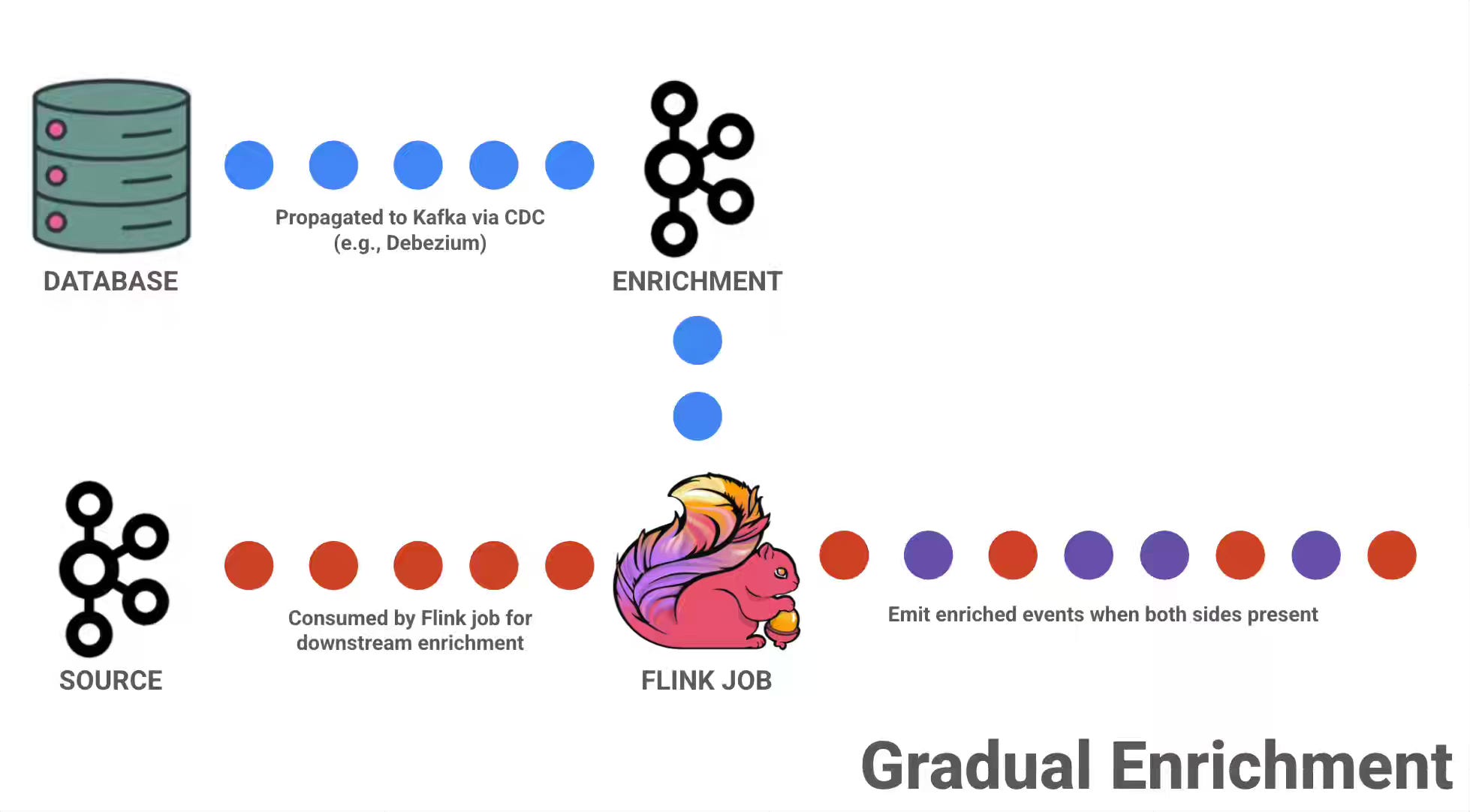
Flink enrichment jobs become fragile when they depend on referential data that is not already present in state, forcing teams to choose between slow per-record lookups, incomplete early results, or complex state preloading. The article compares external enrichment, CDC-backed gradual enrichment, State Processor API–based two-phase bootstrapping, and gated enrichment as ways to manage the launch-time pain of warming the state before live traffic depends on it.
https://rion.io/2026/01/27/prepare-for-launch-enrichment-strategies-for-apache-flink/
Agoda: How Agoda Simulates Booking Flows to Test Flight Integrations
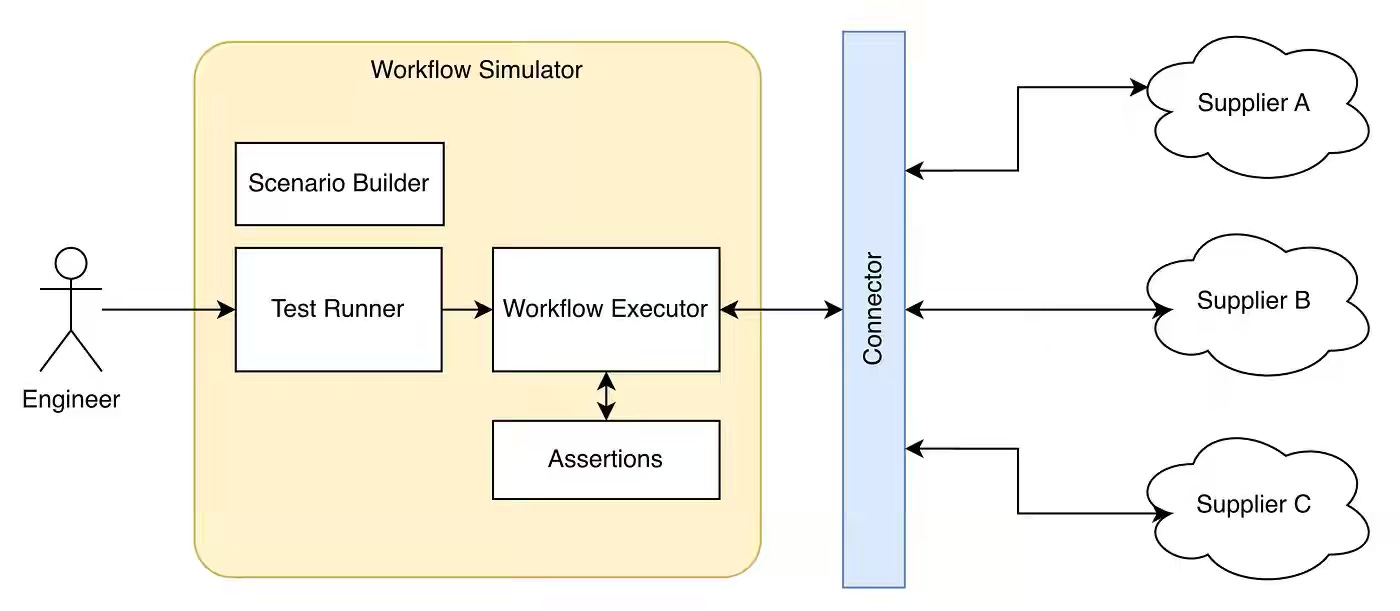
Agents perform relatively well when there is a faster feedback loop to tune, but unfortunately, in many business cases, the transactions are sensitive. Simulation is the most critical aspect of engineering components, not only for testing but also as an RL environment for Agents. Digital twins are emerging as a critical component of simulation. Agoda describes a simulation system for booking flows to test flight integrations.
Databricks: Introducing Arrow UDFs in PySpark: A Faster, Leaner Replacement for Pandas UDFs
PySpark Pandas UDFs improved Python execution with Arrow serialization and batching, but still incur Pandas/Arrow conversion costs, add memory copies, and struggle with complex data types. Databricks writes about the introduction of native Arrow UDFs, Arrow aggregate functions, Arrow UDTFs, and DataFrame-level mapInArrow and applyInArrow APIs that operate directly on PyArrow arrays, record batches, and tables. Arrow UDFs preserve columnar execution end-to-end, run about 10% faster than Pandas UDFs, use about 40% less memory, and support complex datatype and table-in/table-out transformations with familiar Python and SQL interfaces.
https://www.databricks.com/blog/introducing-arrow-udfs-pyspark-faster-leaner-replacement-pandas-udfs
Giannis Polyzos: When Tables Became the Language of Time
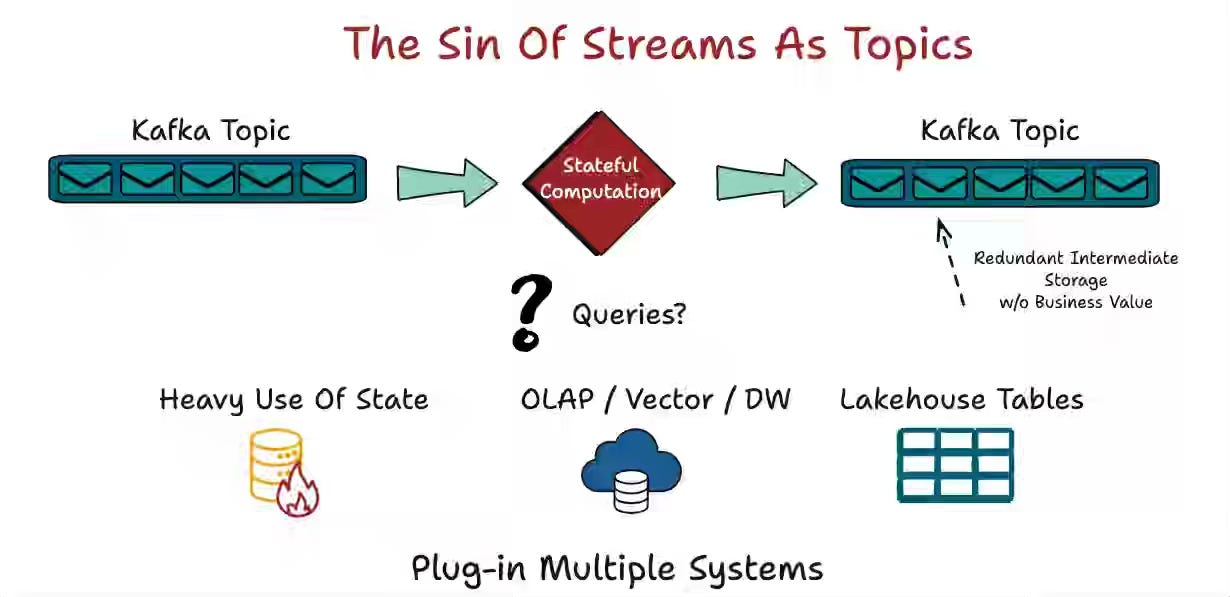
Batch and streaming architectures create duplicated logic, fragmented corrections, and inconsistent state when systems treat logs as the source of truth instead of modeling how data changes over time. The author reframes streams and tables as two views of the same history, using Flink for streaming-first compute, lakehouse commits for durable memory, and Apache Fluss as table-first streaming storage with native updates, deletes, schemas, snapshots, and columnar access. Table-centric streaming collapses batch jobs, replays, late corrections, and real-time dashboards into different temporal views of evolving state, making unification an architectural consequence rather than a glue layer.
https://ipolyzos.substack.com/p/when-tables-became-the-language-of
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.