
Data Engineering Weekly #273
The Weekly Data Engineering Newsletter


How to Build a Data Platform
We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating under a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Fei-Fei Li: A Functional Taxonomy of World Models
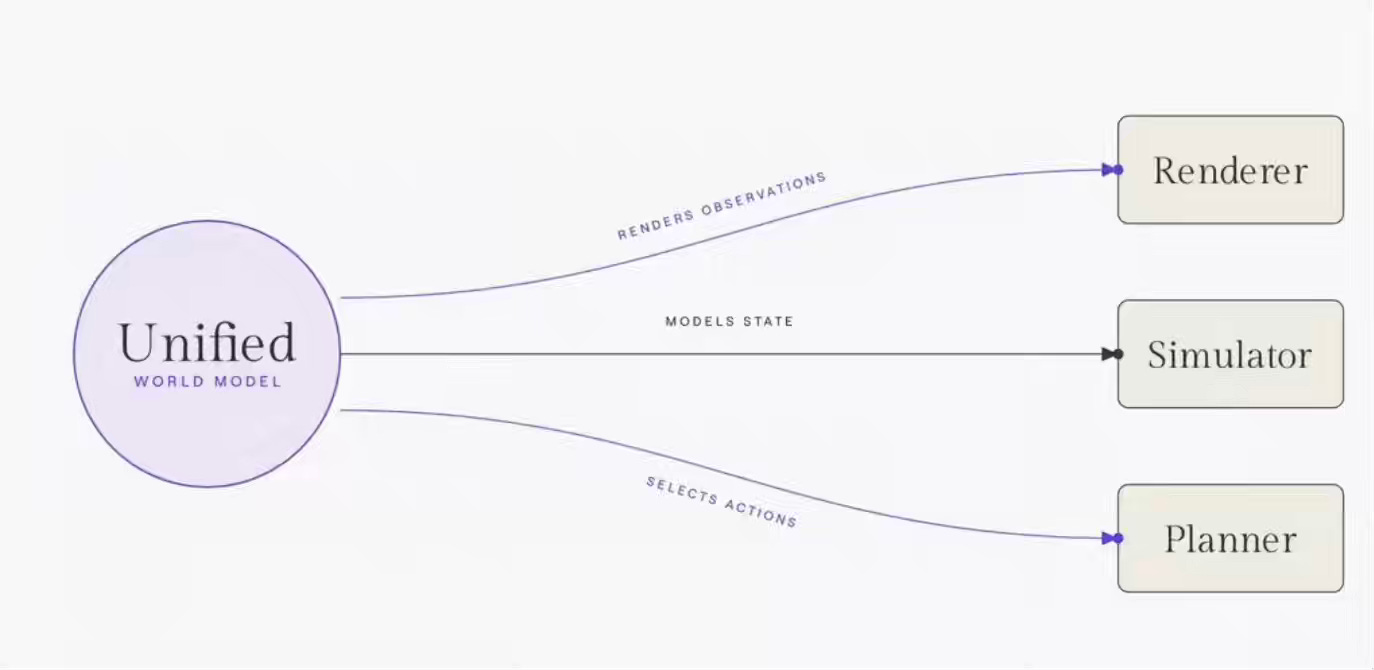
The World Model is one of the most overloaded terms today. The author writes about the taxonomy of the world model into three functions,
Renderer: A renderer outputs observations in the form of pixels meant for human eyes, and the quality that matters most is visual fidelity.
Simulator: A simulator outputs a state: a geometrically, physically, or dynamically faithful representation of the world that humans and computer programs can both compute on and interact with.
Planner: A planner outputs actions.
From a data warehouse perspective, the metric tree is an attempt to build a simpler version of a business simulator. We need to think about extending the simulation of the entire business as it emerges.
https://drfeifei.substack.com/p/a-functional-taxonomy-of-world-models
Gorgias: When Event Time Meets Reality: Lessons from Building Billing on Apache Flink

In real-time pipelines, we assume that the watermark configuration alone preserves ordering, but reprocessing historical data with keyBy operators breaks source-level alignment downstream. The author aligns deduplication and consolidation using the same customer-user key, removes intermediate repartitioning, and extends consolidation by 1 day when event lag exceeds 15 minutes. The combined fix cuts overlapping consolidation windows by 10x without delaying real-time billing, anchored to lag-aware timer registration with explicit cleanup.
Cloudflare: Our billing pipeline was suddenly slow. The culprit was a hidden bottleneck in ClickHouse.

Cloudflare writes that Multi-tenant ClickHouse partitioning hides query-planner coupling at scale — the part-list mutex and vector copy serialize across concurrent queries, even when each query reads few parts. Cloudflare patches ClickHouse’s MergeTreeData hotspot with three upstream fixes — replacing the exclusive lock with std::shared_lock, deferring the parts-vector copy, and binary-searching the sorted namespace prefix.
https://blog.cloudflare.com/clickhouse-query-plan-contention/
Sponsored: AI Modernization Guide

AI is reshaping how data teams operate. But legacy pipelines, brittle workflows, and fragmented tooling weren’t designed for this shift.
Learn how leading teams are future-proofing their infrastructure before AI demands overwhelm it.
Helpshift: Migrating from a Monolithic Orchestrator to Apache Airflow
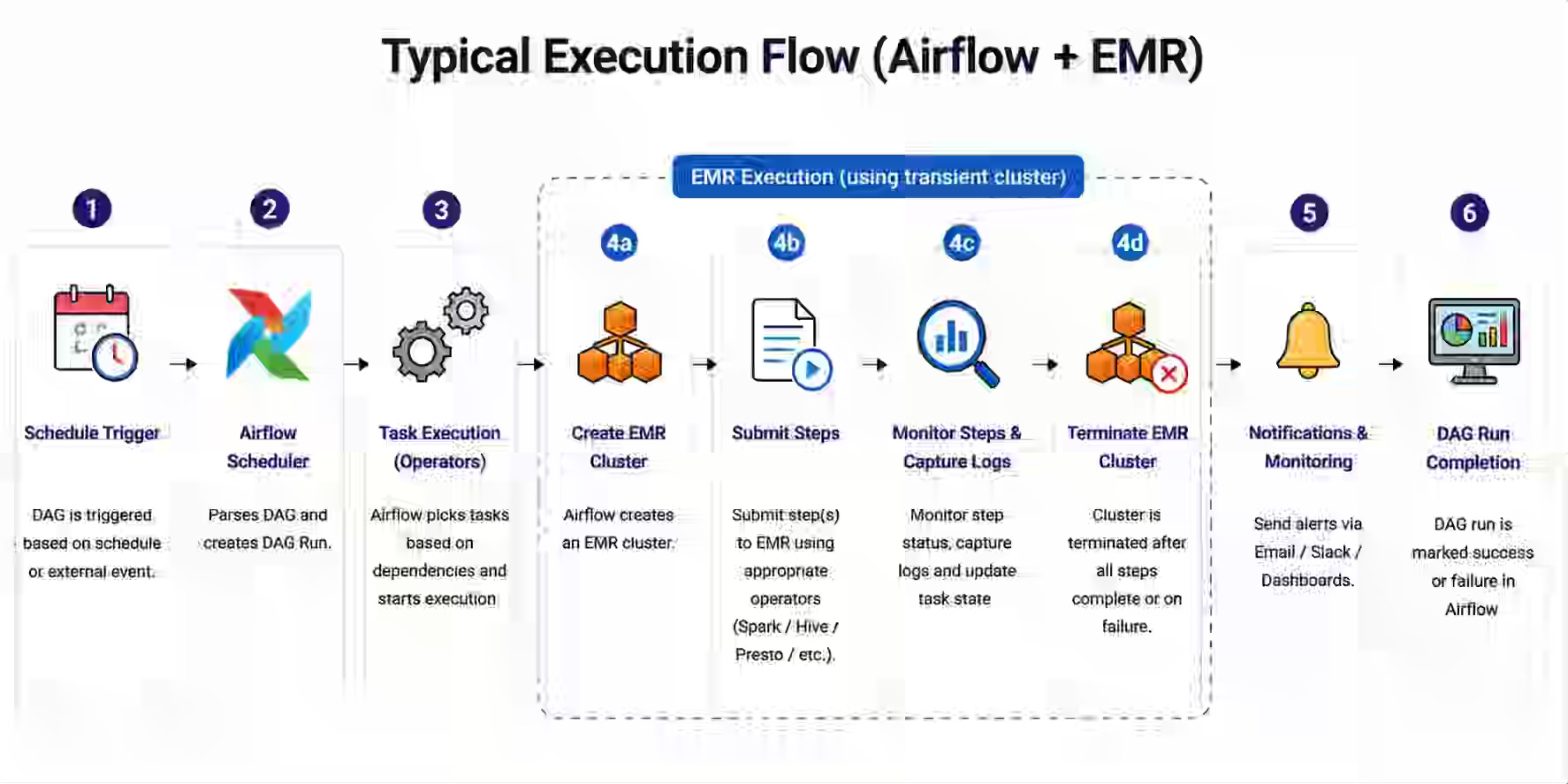
Helpshift writes about migrating a monolithic Clojure-based scheduler system to Apache Airflow. The team writes about its journey and the overall impact on metrics such as reliability, availability, performance, data quality, & the developer productivity.
Indeed: Distilling Long-Tail User Behavior into Scalable Embeddings for Job Search
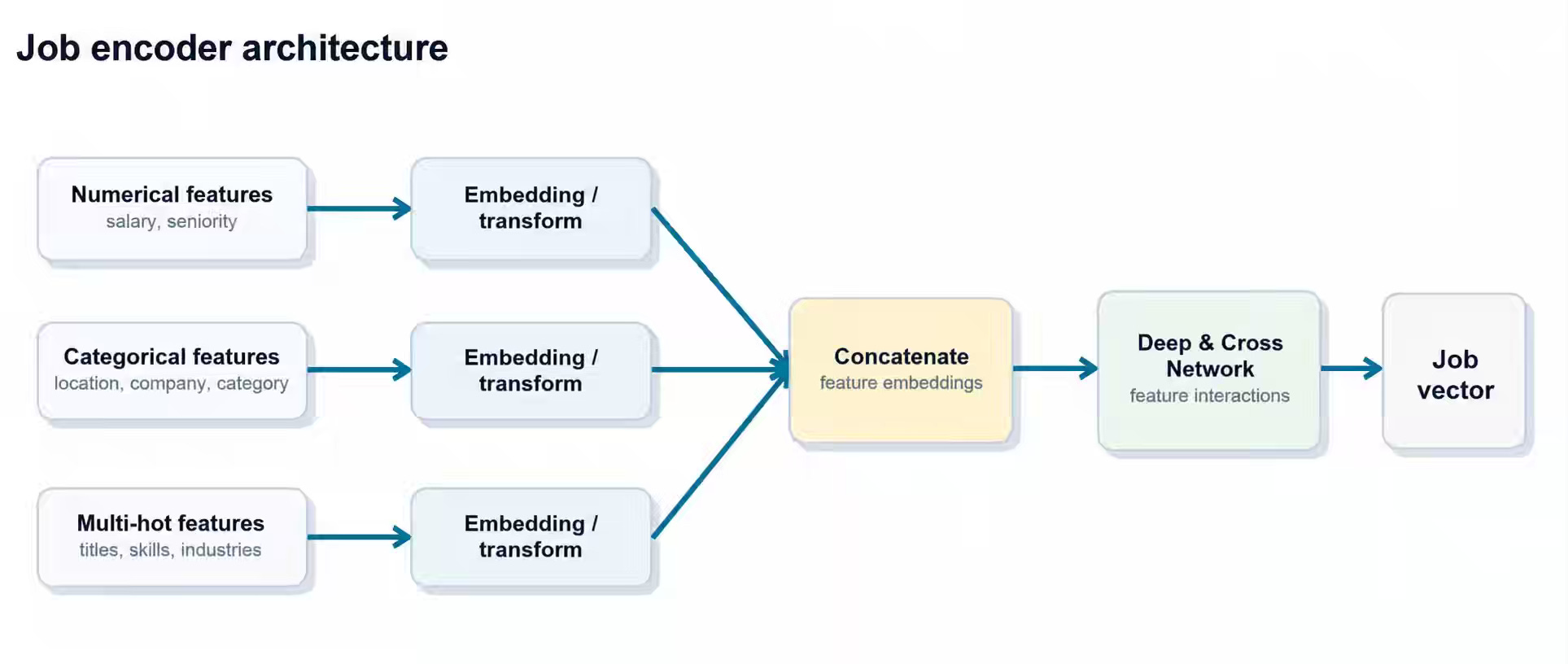
We have long relied on distillation to compress complexity. But while humans reason within finite cognitive dimensions, foundation models now navigate data at an order-of-magnitude greater scale. We are moving from a paradigm of static, structural data modeling to a new era where the embedding model itself has become our primary, high-dimensional data model. - Ananth
This case study perfectly illustrates the thesis: Indeed’s shift from traditional feature engineering to a unified, transformer-based UBM architecture demonstrates the evolution from static, structural data design to the embedding model as the primary, high-dimensional data model for reasoning.
Netflix: Dynamic Repartitioning for Time Series Workloads
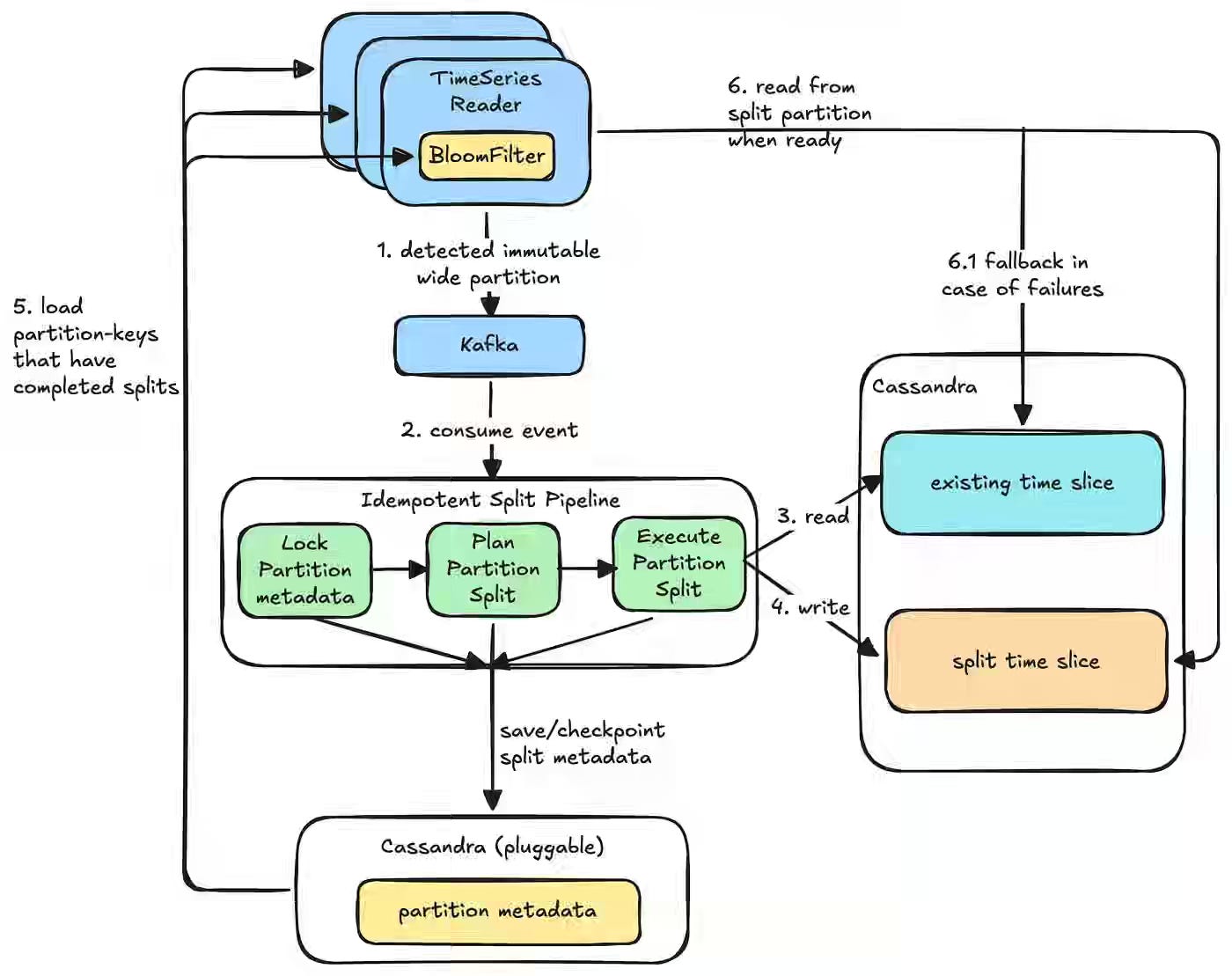
Netflix discusses how static Cassandra partitioning breaks down under evolving time-series workloads when a small percentage of IDs accumulate disproportionate event volumes, driving wide partitions that cause tail-latency timeouts. Netflix layers two runtime adjustments onto its TimeSeries Abstraction — a background worker returning future Time Slice partitions, and per-ID dynamic splitting that routes reads via Bloom filters.
Jack Vanlightly: Broker-Visible vs Client-Local Parallelism
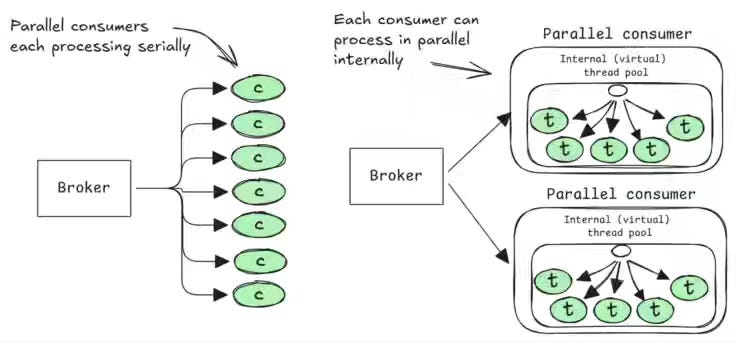
Messaging system parallelism has a hidden cost — where the unit of parallelism lives determines whether scaling stays cheap or explodes into broker-managed TCP connections and state. The author compares broker-visible parallelism with client-local parallelism using virtual threads, showing that the latter scales a 60K msg/sec workload from 60,000 consumers down to 60. Client-local parallelism shifts coordination cost off the broker but adds client complexity, leaving share groups in need of a parallel-processing library layer, anchored to per-message acknowledgment semantics.
https://jack-vanlightly.com/blog/2026/6/3/broker-visible-vs-client-local-parallelism
Criteo: Introducing CLEPR, our model for semantic understanding
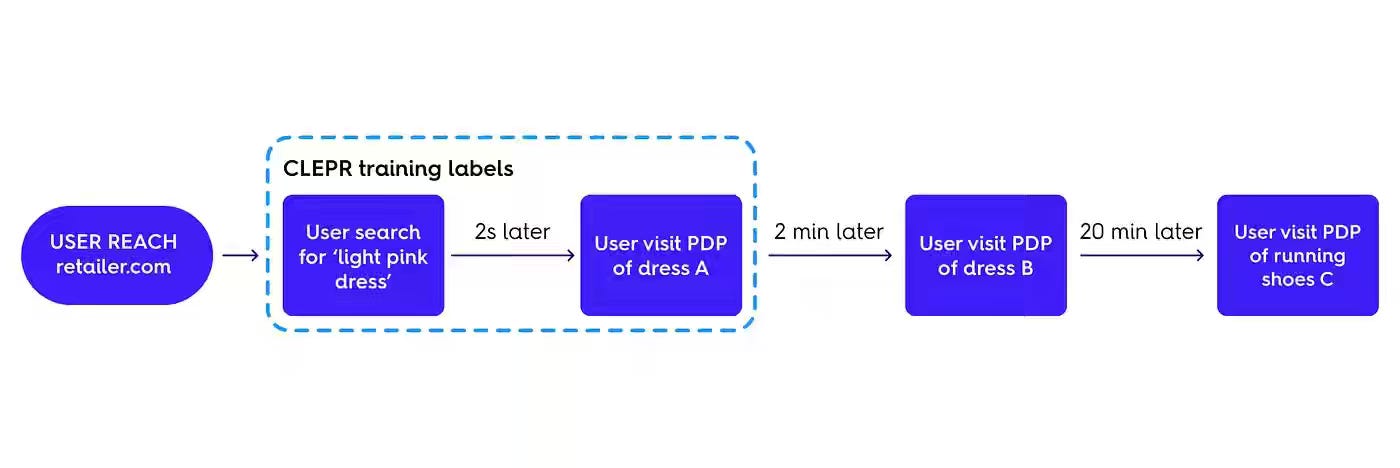
Criteo writes about building CLEPR, a two-tower contrastive embedding model with separate keyword and product encoders — training on session-stitched pseudo-clicks and deduplicating repeated pairs to strip popularity bias. CLEPR scores 10 billion keyword-product pairs daily as a semantic guardrail before performance ranking, lifting CTR by 6%, anchored to embeddings that generalize to human-judged relevance.
WMG: Why we shrank our TimescaleDB chunks from 30 days to 7
Storage configuration choices made when a database is small calcify silently as ingest grows, turning yesterday’s reasonable defaults into compression failures and backfill storms. WMG Lab shrinks TimescaleDB chunk intervals from 30 days to 7 across its hot hypertables — using set_chunk_time_interval to retune future chunks only, without rewrites or locks. The smaller chunks let compression finish cleanly and reduce backfill to a single 7-day decompression instead of a month, anchored to the 25% active-chunk memory rule.
https://tech.wmg.com/why-we-shrank-our-timescaledb-chunks-from-30-days-to-7-07cab8afefc5
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.