
Data Engineering Weekly #274
The Weekly Data Engineering Newsletter


How to Build a Data Platform
We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating under a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Anthropic: How Anthropic enables self-service data analytics with Claude

Data != Software. The Anthropic blog about enabling the self-serve analytics essentially highlights the same. The key takeaway from the article,
The most important aspect of ensuring analytics agents are accurate is a strong data foundation, which includes the data models, transforms, tests, and tables in a data warehouse, along with the metadata that describes them. Standard data engineering and data quality practices such as dimensional modeling, shift-left testing, freshness, and completeness checks on critical pipelines all still apply (and we won't relitigate these).
https://claude.com/blog/how-anthropic-enables-self-service-data-analytics-with-claude
Airbnb: Scaling beyond one: How Airbnb evolved its data architecture for a multi-product world
Decentralized data ownership breaks down when teams build domain tables without shared conventions, leaving consumers to reconcile inconsistent identifiers and namespaces across the warehouse. Airbnb resolves the trade-off with three principles — no hybrid models, identifier naming tied to the modeling choice, and dedicated namespaces that separate product, global, and team-owned tables. The framework lets product-facing domains pick separate models while cross-cutting concerns like payments and messaging stay monolithic, anchored to centralized principles with decentralized modeling.
Uber: Simplifying Data and Product Integrations with a Data Abstraction Layer
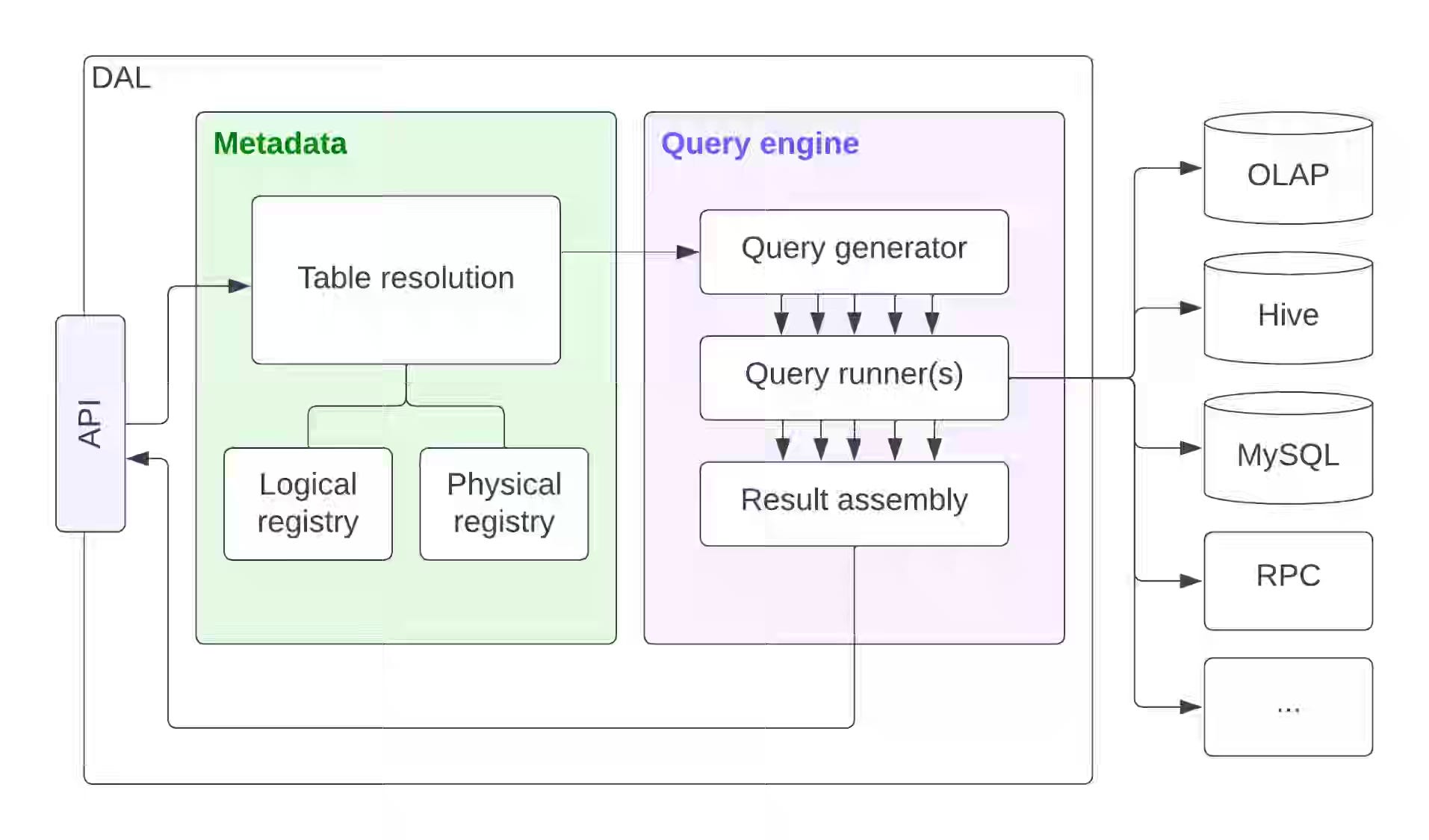
User-facing data products break when queries are tightly coupled to physical schemas, forcing weeks-long migrations every time a table is renamed, split, or moved. Uber builds a Data Abstraction Layer fronting OLAP, Docstore, and Hive — routing requests through schema-eligibility, availability-window, and column-continuity rules to pick physical candidates at query time.
https://www.uber.com/us/en/blog/data-abstraction-layer/
Sponsored: AI Modernization Guide

AI is reshaping how data teams operate. But legacy pipelines, brittle workflows, and fragmented tooling weren’t designed for this shift.
Learn how leading teams are future-proofing their infrastructure before AI demands overwhelm it.
LinkedIn: Semantic Search for AI Agents at Scale: Retrieval and Ranking for LinkedIn’s Hiring Assistant
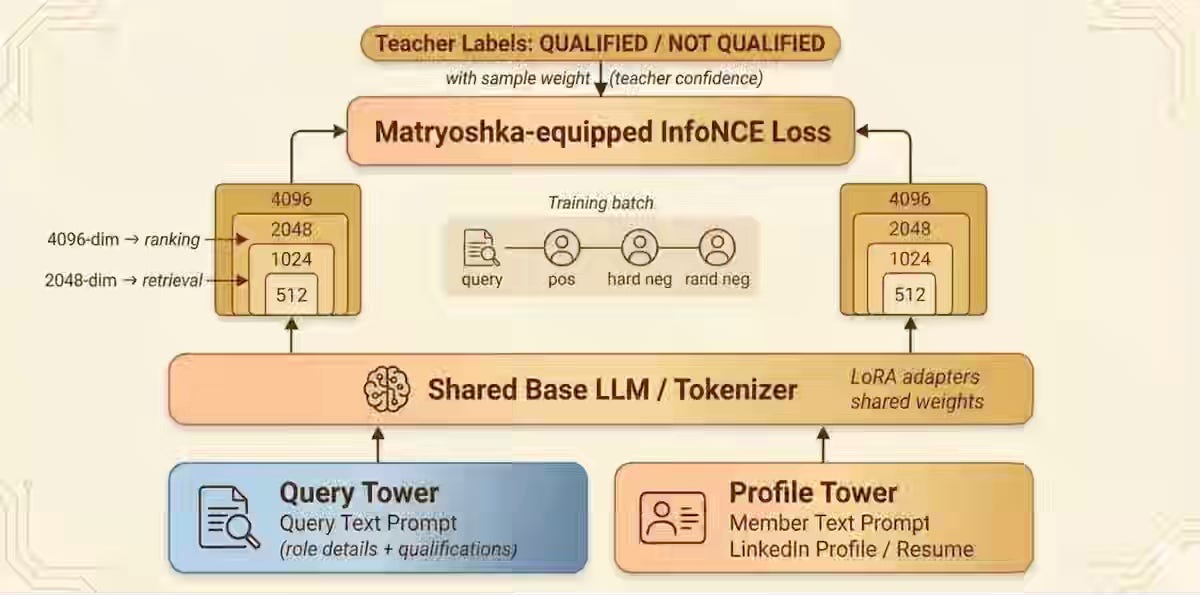
LinkedIn writes about building MUSE, a dual-tower Matryoshka embedding model trained on LLM-Teacher relevance labels — serving 2048-dim truncations to ANN retrieval and 4096-dim vectors to the L2 ranker. The system lifts relevance by 2.7%, and InMail sends by 4.1% on fewer sourced candidates, anchored to embeddings that distill multi-step qualification reasoning into a single cosine score.
Capital One: DataAgents: How we turned 9 months of analysis into 10 days
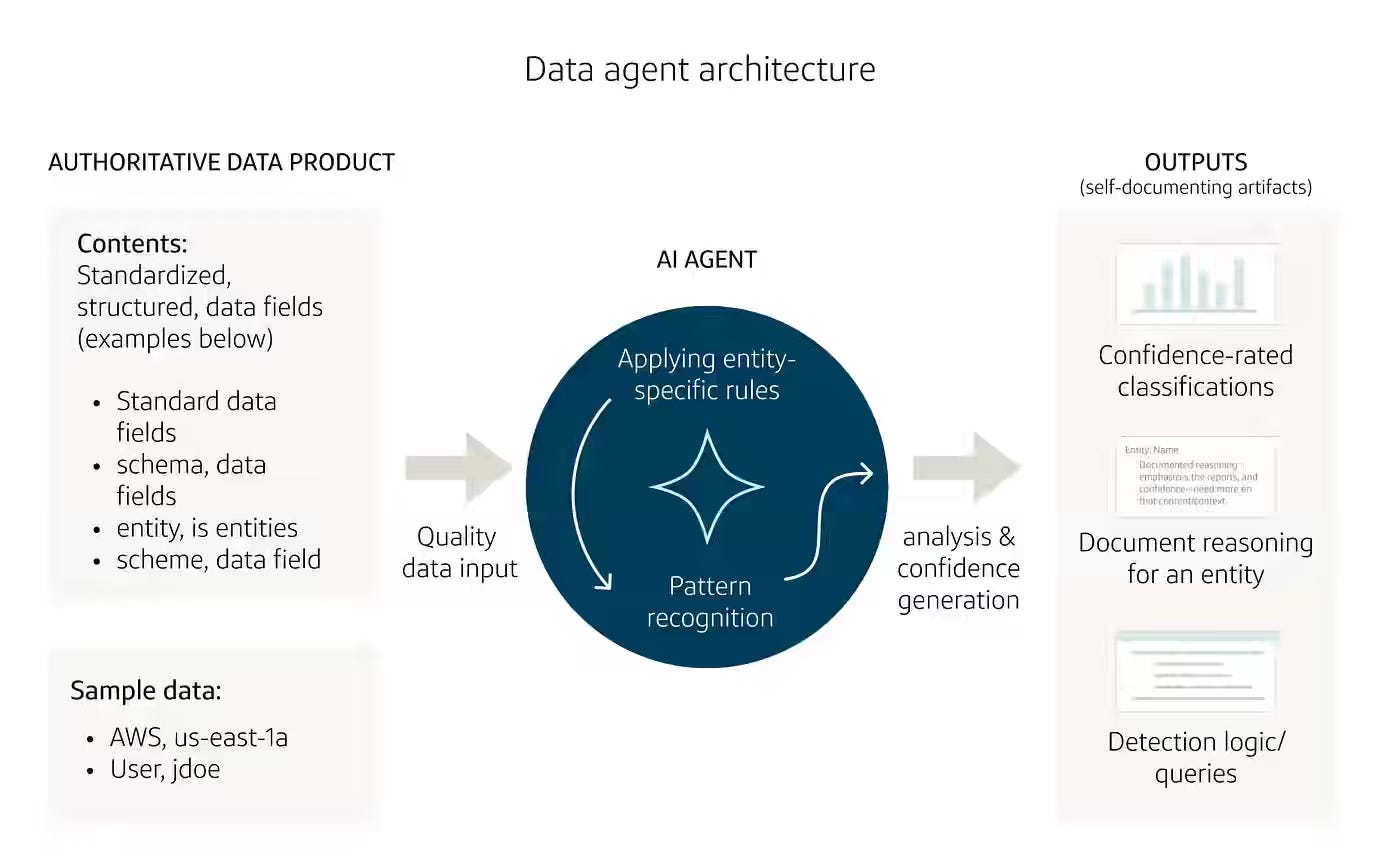
AI agents amplify whatever data foundation they sit on — good data scales insight, bad data scales confusion across hundreds of entities at production speed. Capital One pairs an authoritative cloud-asset data product with a three-phase agent workflow — feasibility assessment, per-entity Spark SQL detection logic, and one-by-one MEDIUM-confidence validation. The pattern compresses a 350-resource-type dormancy analysis from nine months to ten days, anchored to confidence-rated outputs with per-entity-documented reasoning.
John Kutay: Building an AI Database for Agentic GTM Operations
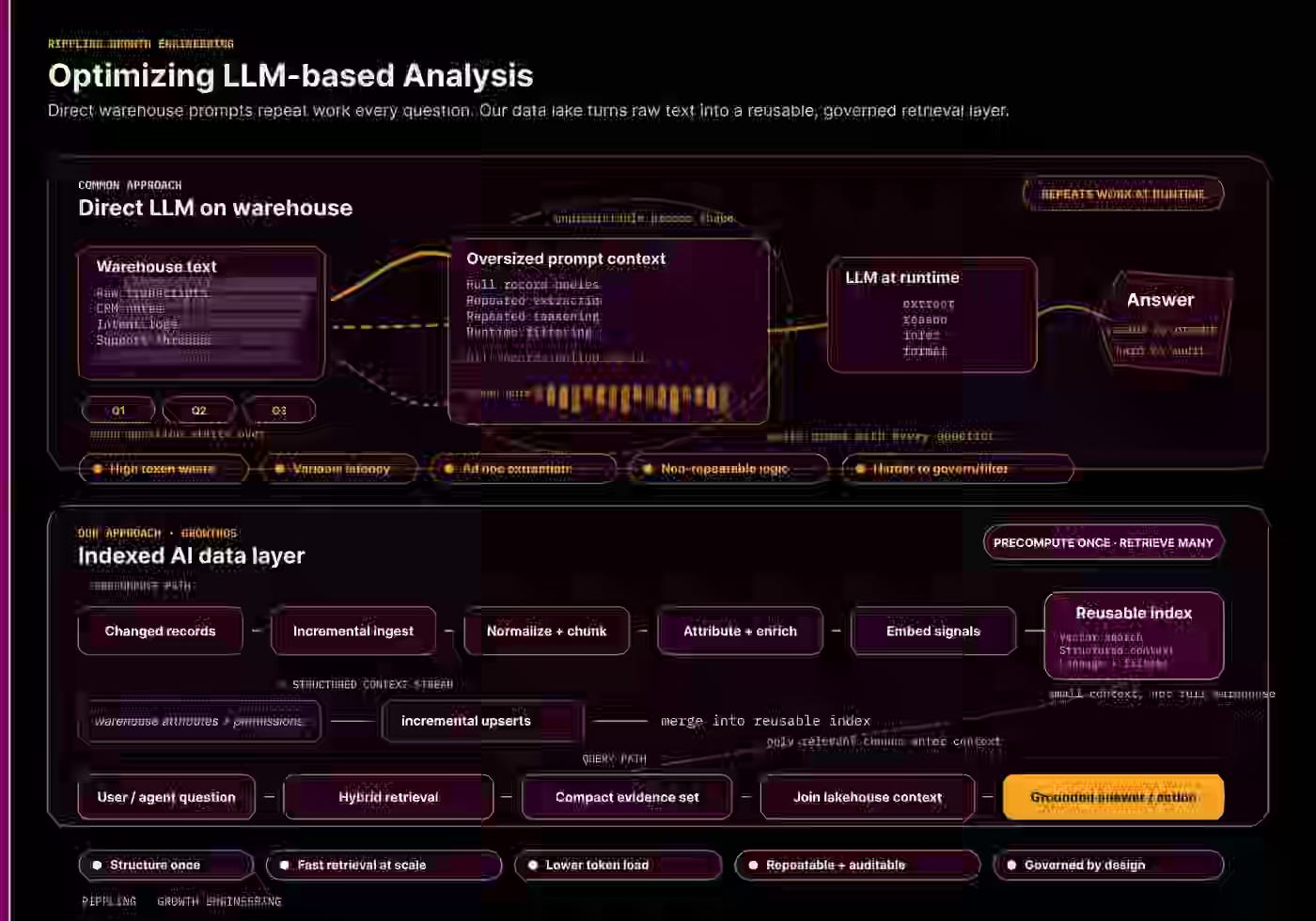
Compute redundancy compounds at scale — re-running enrichment, re-extracting evidence, and re-embedding payloads on every query turns scaling into a cost spiral instead of a leverage curve. Rippling writes about pairing ML entity resolution with a blocking tree to compress the n² candidate space, then applies DRY(E) to precompute embeddings once and refresh only changed conversations.
https://medium.com/@john.kutay/building-an-ai-database-for-agentic-gtm-operations-6a0c86fb8cdc
Naidu Rongali: Why We Moved from Hive-Style Data Lakes to Apache Iceberg?
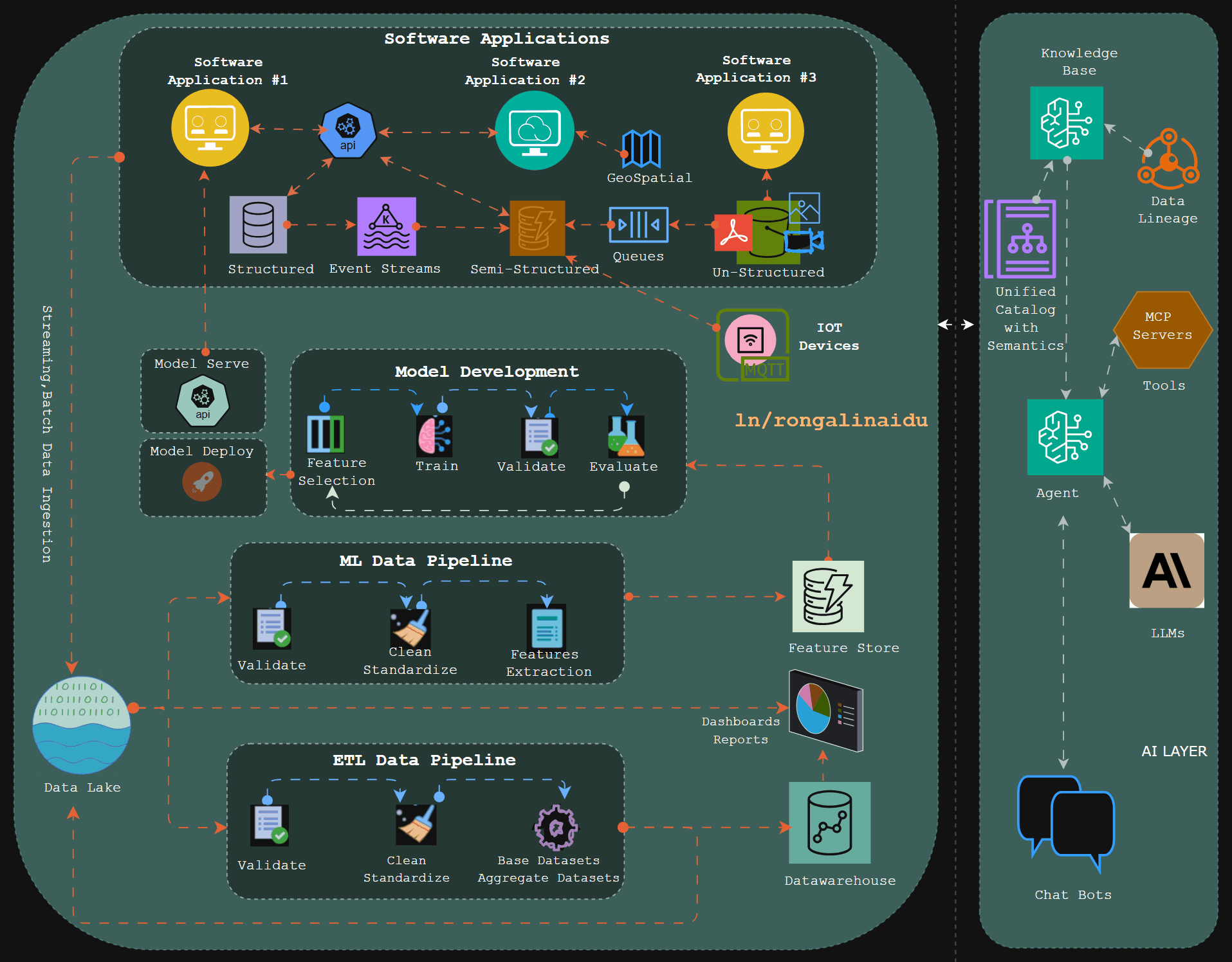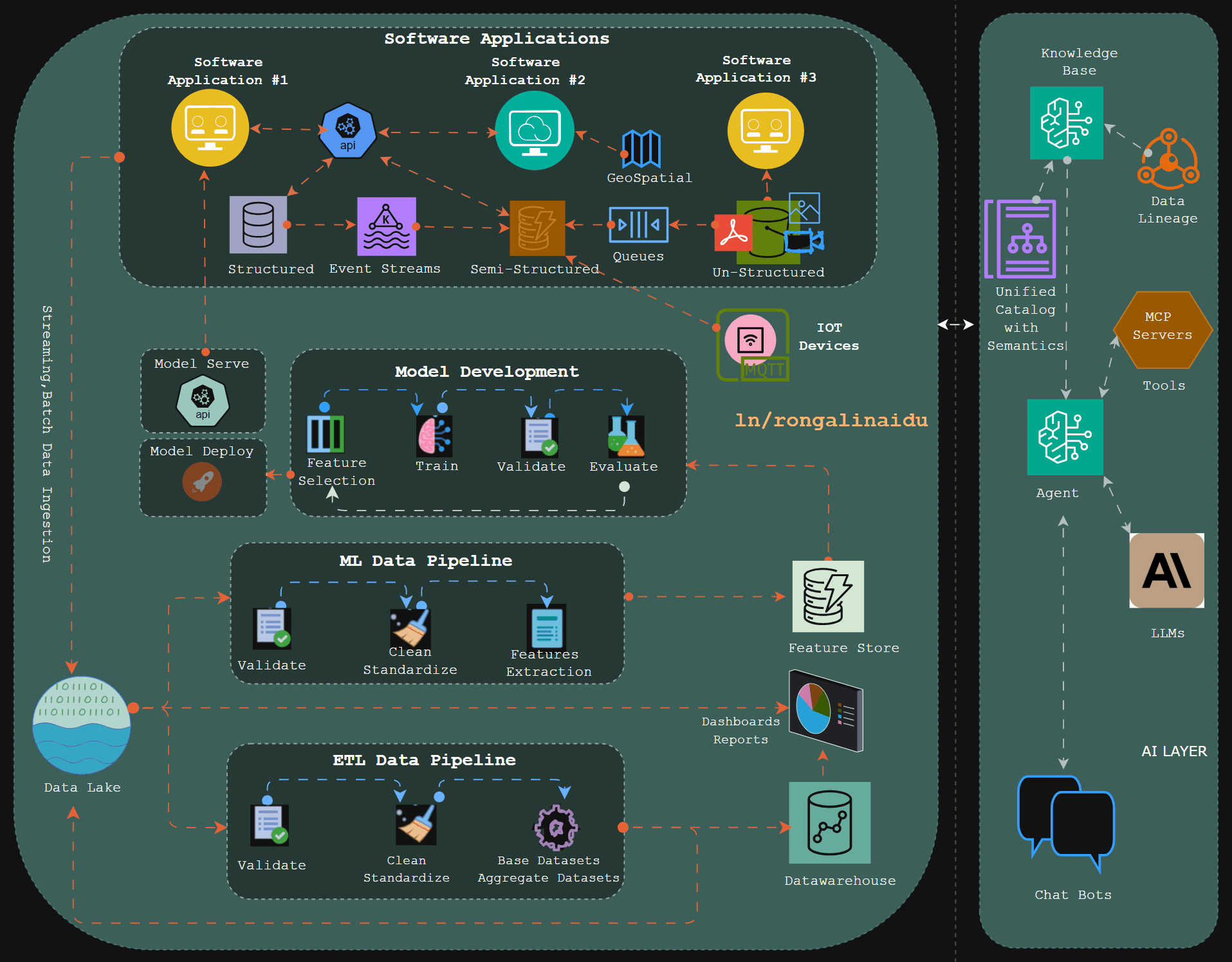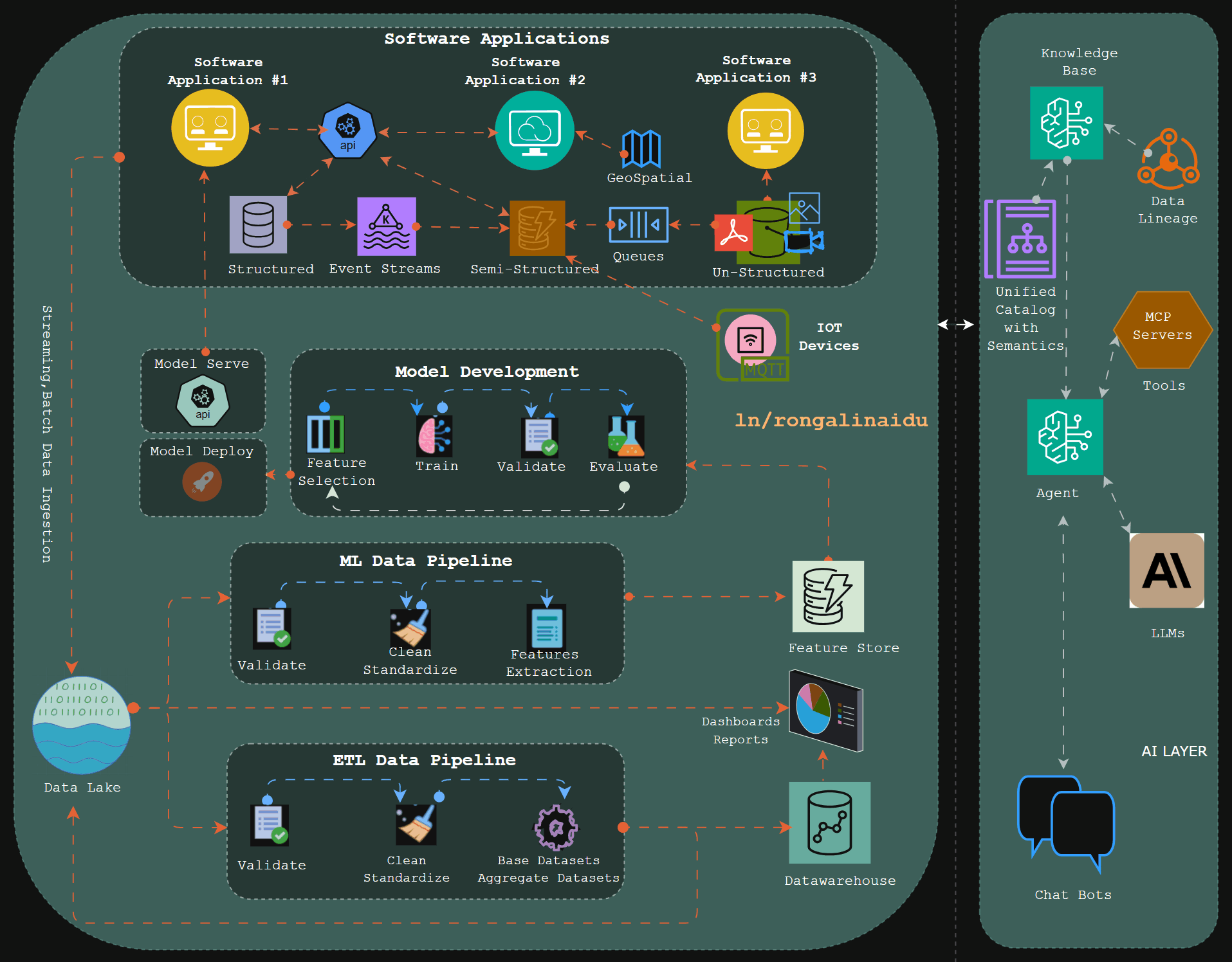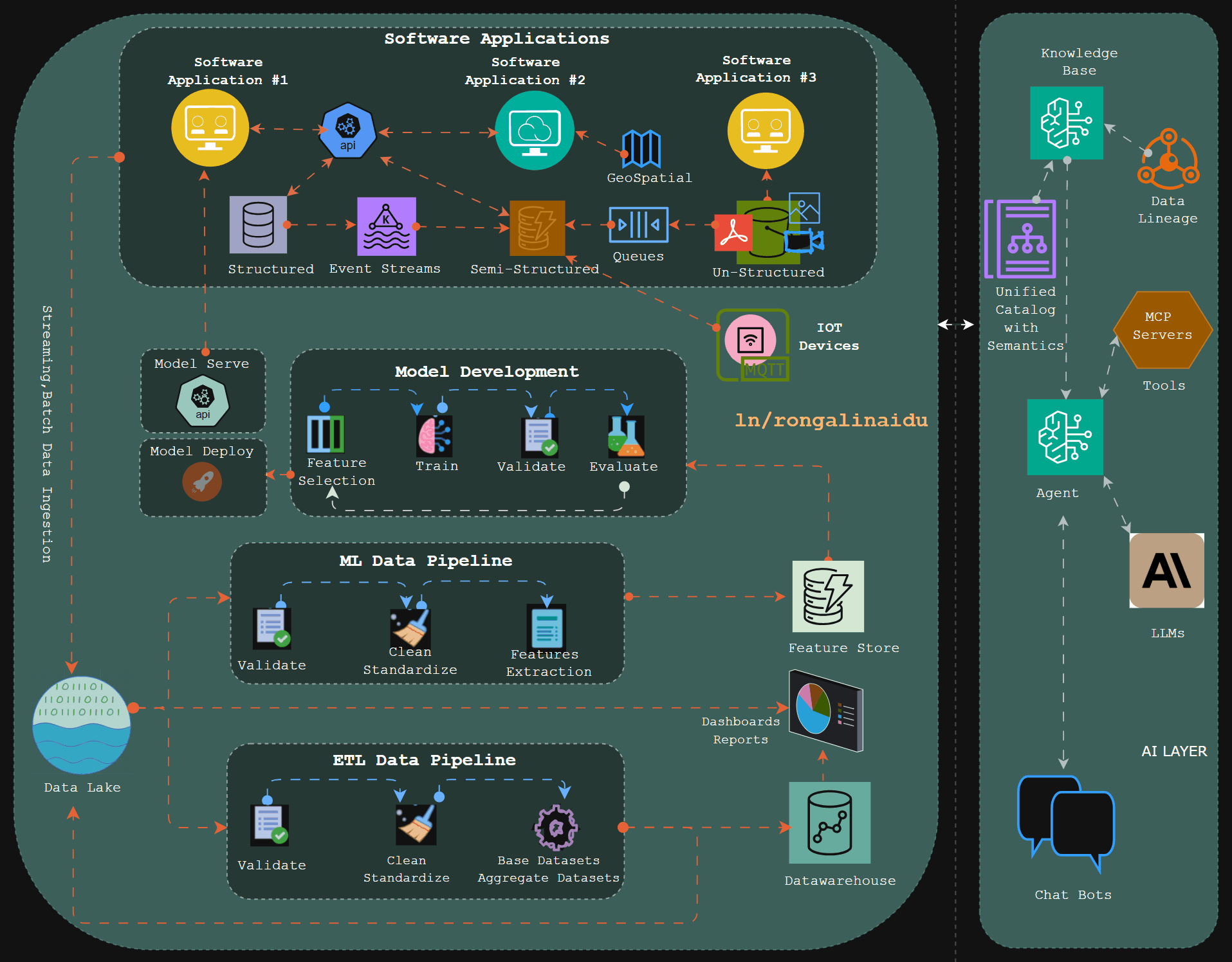
The author walks through Apache Iceberg’s metadata hierarchy — snapshots, manifest lists, and column-ID-tracked manifest entries — replacing directory-based discovery with statistics-driven file pruning. The architecture brings ACID transactions, schema evolution, and time travel into open object storage, anchored to a metadata layer that decouples logical table state from S3 file layout.
Kiran Pothina: Ship Fast, Break Nothing: dbt CI/CD, Monitoring, and Model Health
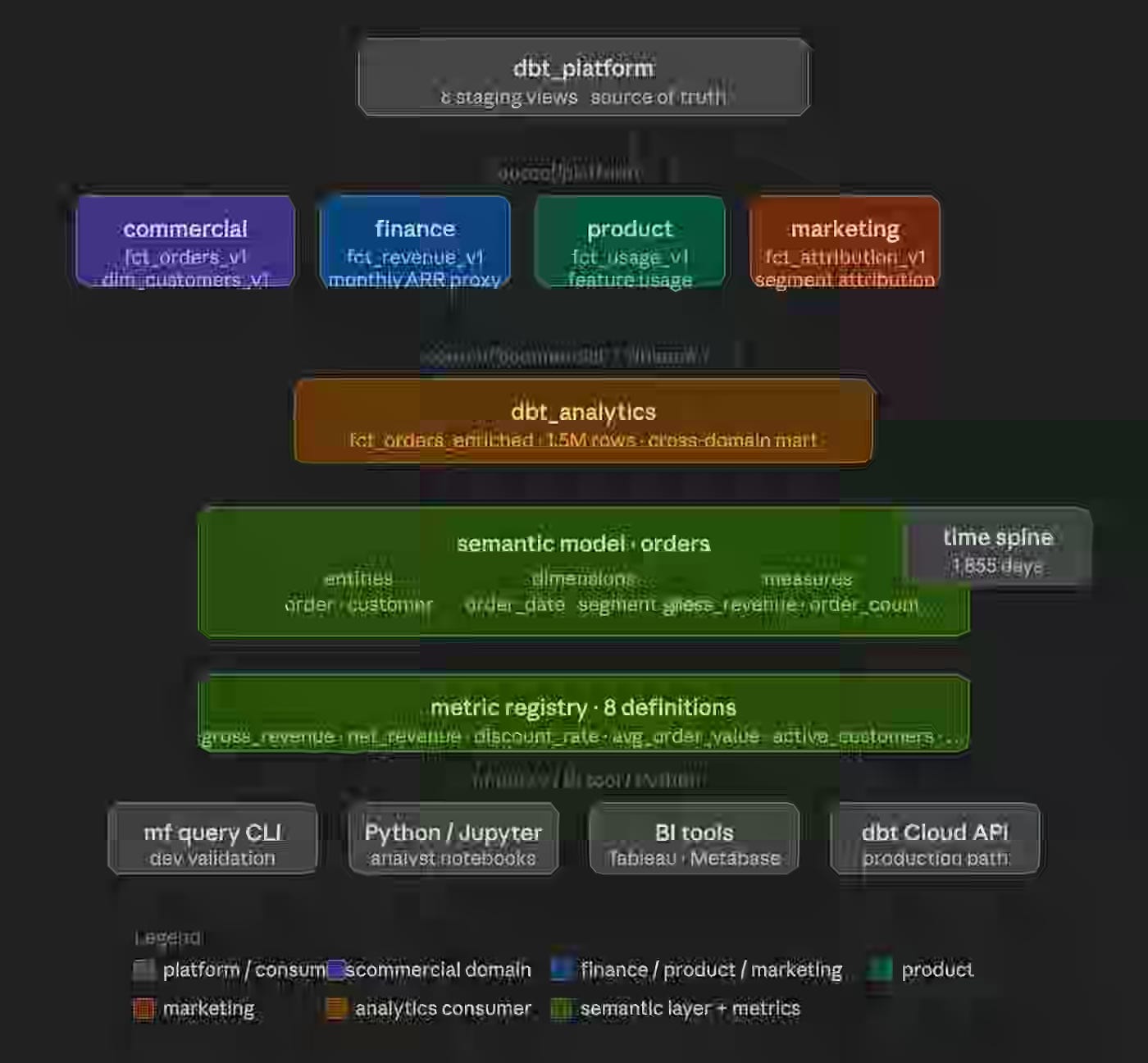
Compute redundancy compounds at scale — CI pipelines that rebuild every model on every PR turn feedback loops into bottlenecks and push engineers to skip review entirely. The author wires four-stage slim CI across six dbt projects, using fresh manifest generation from main and zero-copy incremental clones before a state:modified+ build with --defer.
Andreas Andreakis: Why DBLog Is Snapshot-Equivalent
Streaming abstractions hide physical execution behind informal correctness arguments — “it works” leaves downstream consumers to discover edge cases in production rather than reason from stated guarantees. The author formalizes DBLog’s snapshot-equivalence — interleaving chunk reads with CDC events and applying latest-event-wins replay against a global frontier, machine-checked in Isabelle/HOL. The proof shows that replay output equals the source database at the frontier, restricted to backfill keys, anchored to a virtual cut that requires no lock, write pause, or single-moment read.
https://aandreakis.com/posts/why-dblog-is-snapshot-equivalent
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.