
Data Engineering Weekly #275
The Weekly Data Engineering Newsletter


How to Build a Data Platform
We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating under a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
MIT CISR: The Case for a Semantic Layer
Data decontextualized from its source loses the business meaning and rules that made it trustworthy, leaving GenAI agents to hallucinate without machine-readable context. MIT CISR frames the semantic layer as the answer — taxonomies, ontologies, and business rules engines encoding usage constraints, illustrated by Healthcare IQ’s Semantic ETL. The semantic layer automated 80% of Healthcare IQ’s hospital onboarding, anchored in shared terminology that lets organizations expand AI without reinventing governance for each use case.
https://cisr.mit.edu/publication/2026_0501_SemanticLayer_LefebvreWixomLegnerVandermeulenBeath
Lyft: Metric Semantic Layer: How Lyft Governs and Scales Key Data Definitions
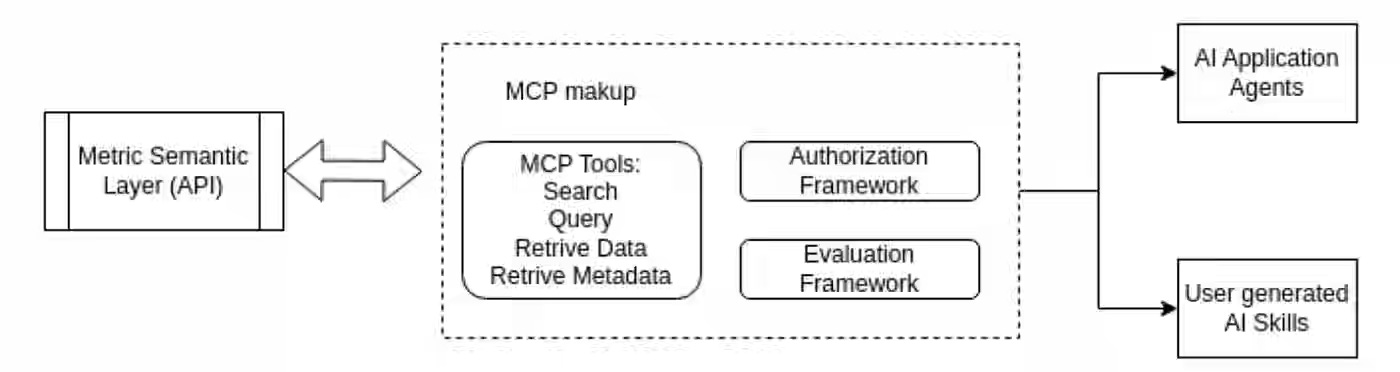
Metric inconsistency and definition sprawl across distributed teams fragment analytics workflows, seeding decisions with conflicting values drawn from the same underlying data. Lyft builds a Metric Semantic Layer as a Python package, encoding Golden Metrics in YAML and Jinja SQL templates, with governance by paired Business and Operational Owners. The layer flows a single update through every downstream dashboard, ML model, and BI tool, anchored in clean YAML that doubles as an MCP knowledge base, reducing agent hallucination.
Mohammed Benaissa: Idempotency in Data Engineering - The Quiet Property That Saves Your Pipelines
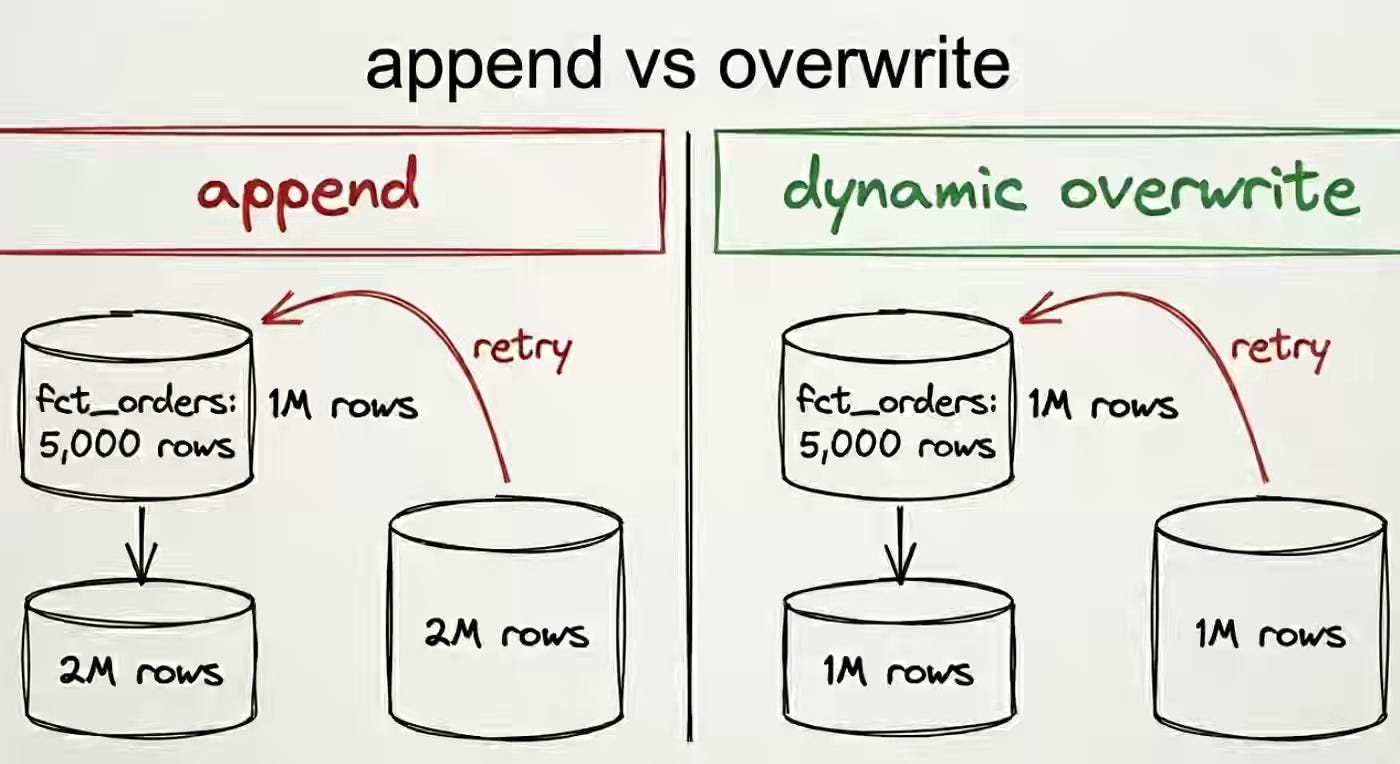
Functional data engineering treats every task as a pure function — same inputs producing the same output — yet most pipelines silently break that contract the moment a retry fires. The author reframes the fix as idempotency — pairing a deterministic key with MERGE or dynamic partition overwrite, proven by a run-twice hash test. The pattern collapses retried loads into harmless no-ops, anchored to writes designed to absorb duplicates instead of delivery guarantees that prevent them.
Sponsored: AI Modernization Guide

AI is reshaping how data teams operate. But legacy pipelines, brittle workflows, and fragmented tooling weren’t designed for this shift.
Learn how leading teams are future-proofing their infrastructure before AI demands overwhelm it.
Netflix: Predicting Risk in Content Launches: How Data-Driven Insights can Transform Launch Planning
Netflix writes about predicting media asset delivery with boosted-tree regression on daily-snapshotted production signals, building a phase-agnostic model that fills schedule gaps without look-ahead bias. The model reaches accuracy 11 weeks sooner than manual schedules and reduces Accumulated Error Days, anchored to serving logic that defers to manual dates where it underperforms.
Helpshift: Building a Centralized Alerting Framework for Data Quality Monitoring and Incident Management
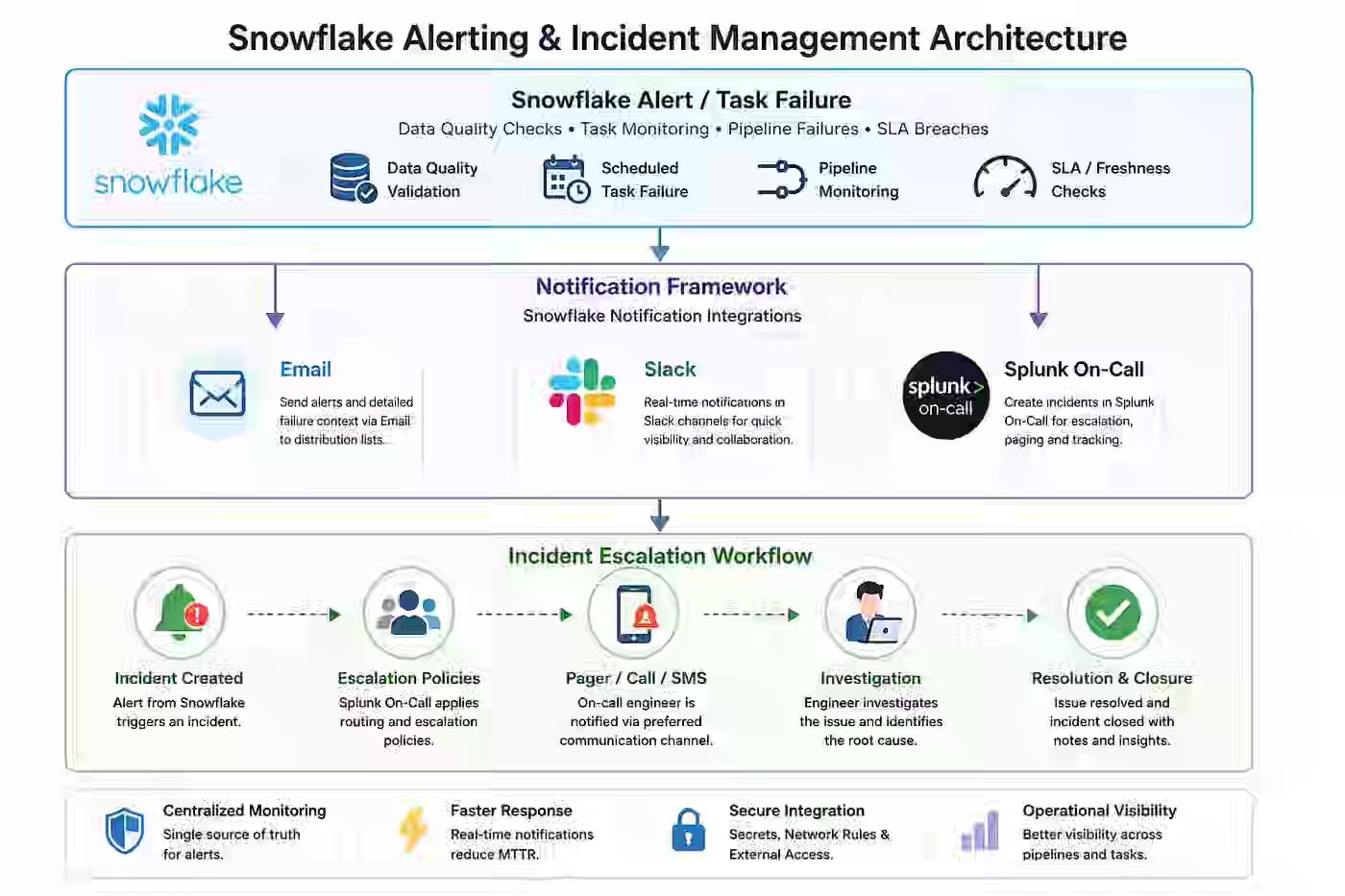
Failure detection is rarely the bottleneck — fragmented monitoring and generic alerts mean issues get found but not acted on, because responders lack context overnight. The author builds a centralized alerting framework in Snowflake, separating detection, notification, and escalation, then pages on-call via Splunk with secure external access. The framework reduces MTTR by using validation-specific context rather than generic messages, anchored to loosely coupled layers that allow new checks and channels to evolve independently.
Instacart: Semantic IDs: Product Understanding at Scale
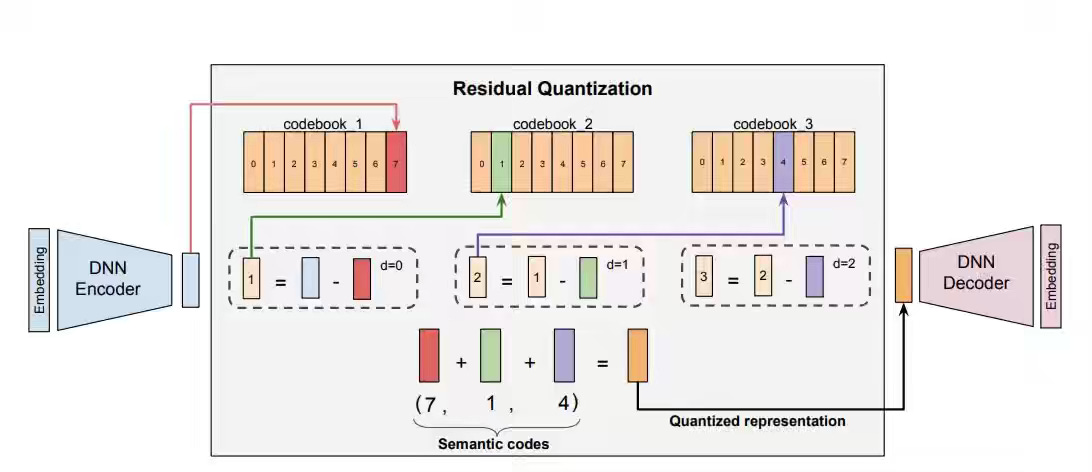
Recommendation models learn from engagement volume, so they skew toward popular staples and leave cold-start and tail products invisible behind a rigid category tree. Instacart compresses product embeddings into hierarchical semantic IDs via an RQ-VAE, regularized with a contrastive loss that uses catalog taxonomy as free supervision rather than engagement data. The shared-prefix codes drove a 34% add-to-cart lift and surfaced 2.7x more emerging brands, anchored to a vocabulary every downstream model reads alike.
https://tech.instacart.com/semantic-ids-product-understanding-at-scale-5283e0288f5a
Salesforce: How Data 360 Segmentation Processes a Quadrillion Records Across Arbitrary Customer Data Models
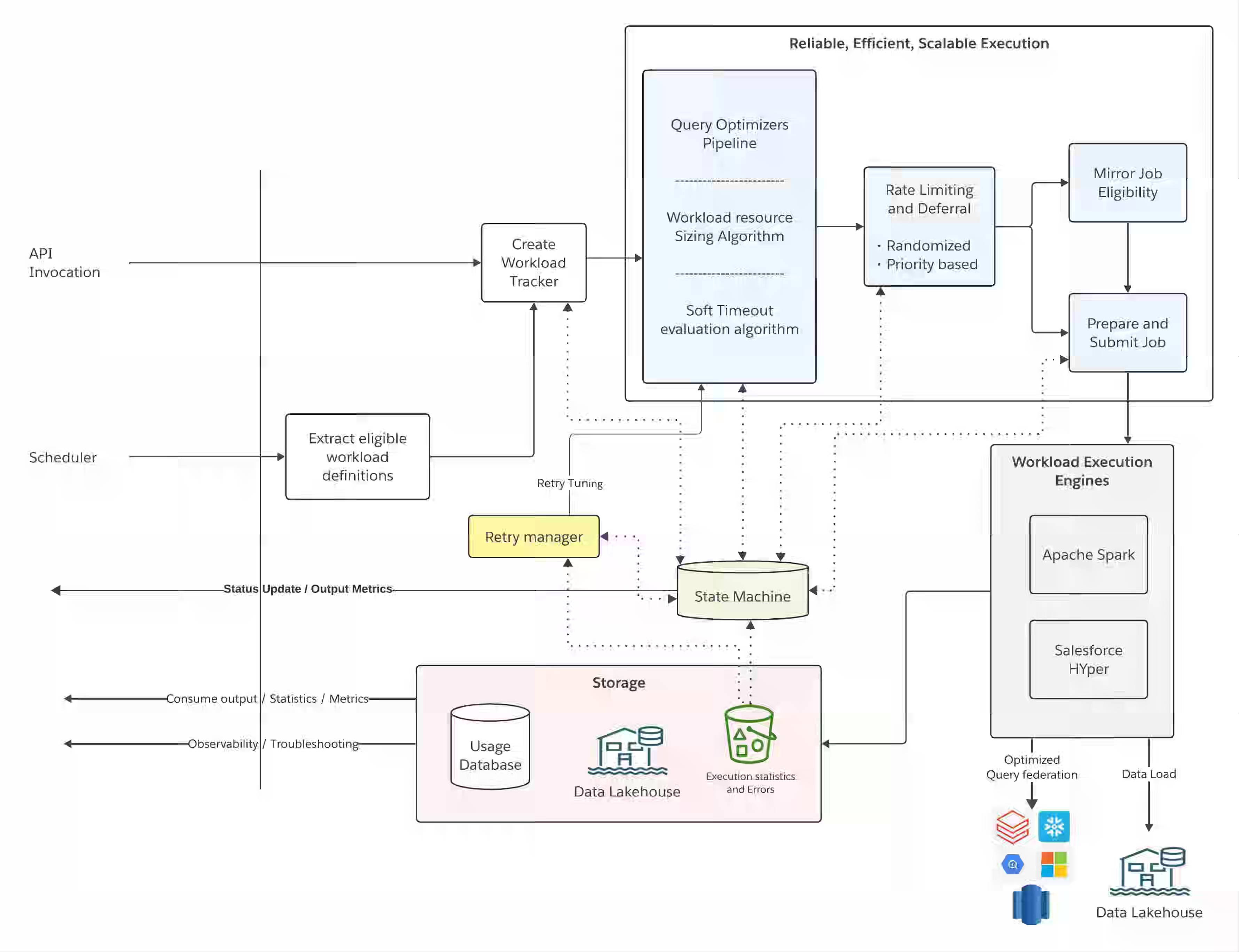
Distributed systems stay predictable by controlling schema, relationships, and workload shape — but handing those to the customer forces reliability from runtime adaptation, not design-time assumptions. Salesforce interprets arbitrary customer schemas and relationship graphs at runtime in Data 360, adding phased query planning that decomposes optimization when plan candidates reach the billions. The platform maintains 99.95% reliability across three million monthly Spark jobs, anchored in workload-size estimation that right-sizes each job rather than overprovisioning.
Shopify: Teaching Sidekick to say no - automated data curation with LLM judge consensus
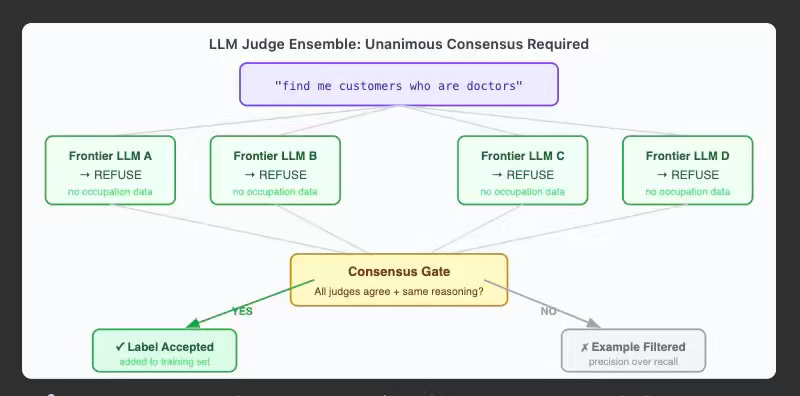
Production logs are a survivorship-biased corpus — they capture only successful queries, so a fine-tuned model never learns when to refuse an impossible request. Shopify teaches its Sidekick text-to-query skill to say no — seeding a four-judge LLM ensemble with a small annotated set and gating on unanimous consensus to label refusals. The consensus gate raised the skill’s pass rate from 0.762 to 0.798 at 86% refusal accuracy, anchored to a flywheel that recycles production traffic each cycle.
https://shopify.engineering/sidekick-curation
Trivago: How We Cut Kafka Consumer Deployment Costs by 83%
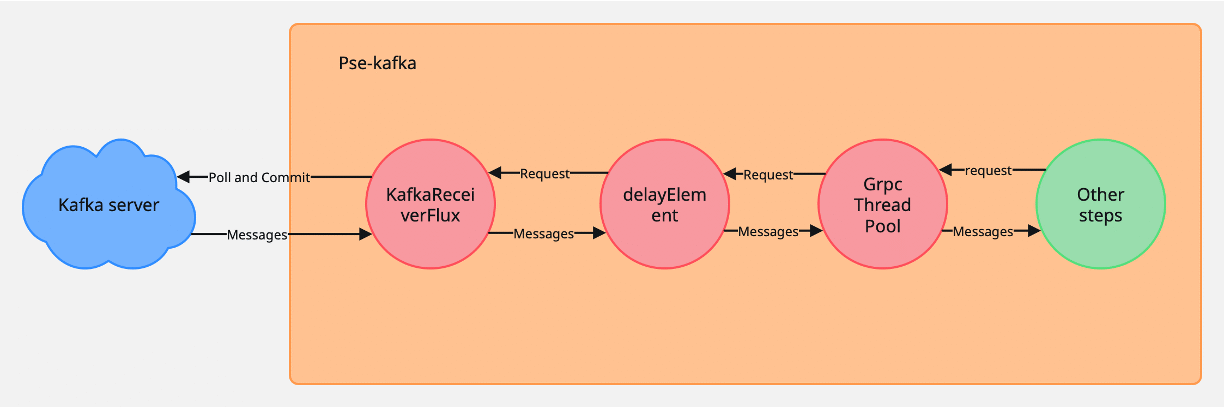
Architectural choices that fit the workload when made silently calcify into bottlenecks as throughput grows, while reactive scaling hides the root cause. Trivago traces a Kafka consumer’s chronic lag to three compounding bottlenecks that each moved nothing alone — coupled commits, a delay ceiling, and an undersized gRPC pool. Migrating to reactor-kafka, removing the delay, and resizing the pool cut pod count from 60 to 6, anchored to fixing compound bottlenecks together.
https://tech.trivago.com/post/2026-06-12-how-we-cut-kafka-consumer-deployment-costs-by-83
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.