
Data Engineering Weekly #276
The Weekly Data Engineering Newsletter


How to Build a Data Platform From Scratch
We wrote an eBook on Data Platform Fundamentals to help you be like the happy data teams, operating under a single platform.
In this book, you’ll learn:
- How composable architectures allow teams to ship faster
- Why data quality matters and how you can catch issues before they reach users
- What observability means, and how it will help you solve problems more quickly
Jack Vanlightly: Can We Agree on a Storage/Workload Architecture Taxonomy?
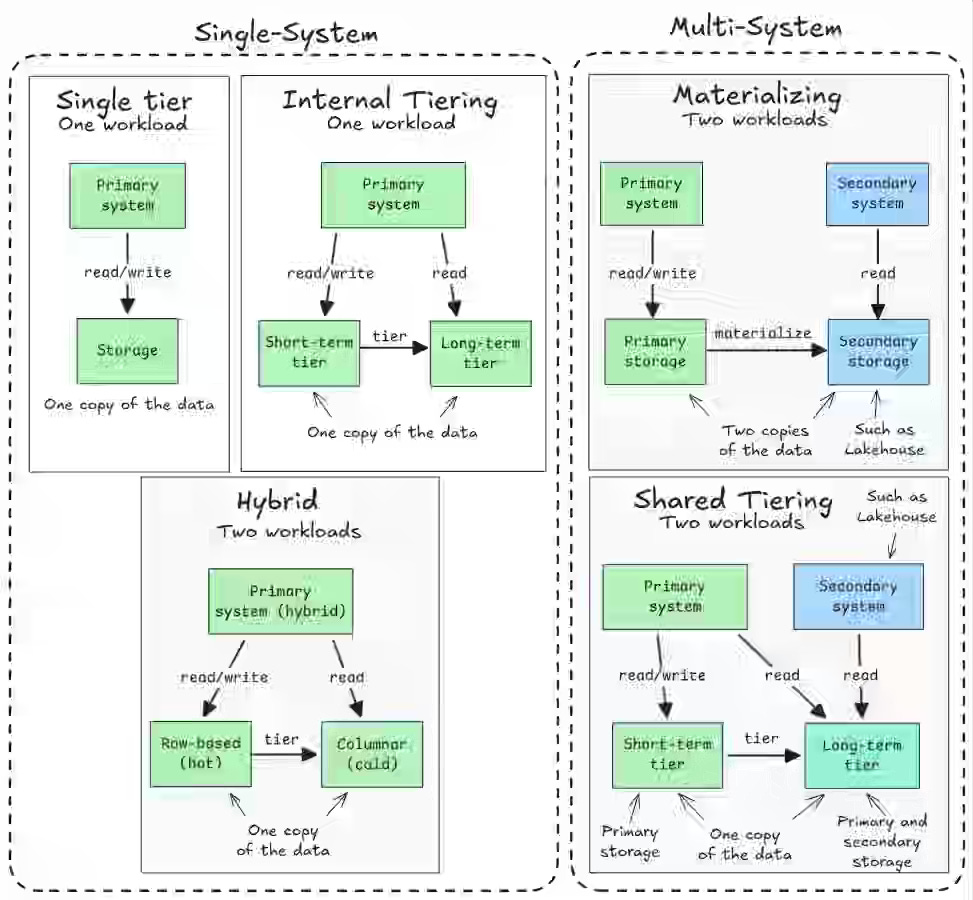
OLTP, OLAP, HTAP, and now LTAP? Yes, we need to agree on storage/ workload architecture. I wrote about the emerging LakeDB architecture in lakedb.cloud, describing its target characteristics. It is high time to rephrase this taxonomy and update the Lakedb characteristics.
https://jack-vanlightly.com/blog/2026/6/21/can-we-agree-on-a-storage/workload-architecture-taxonomy
Pinterest: Automated Schema Evolution in Pinterest’s Next-Generation DB Ingestion Framework
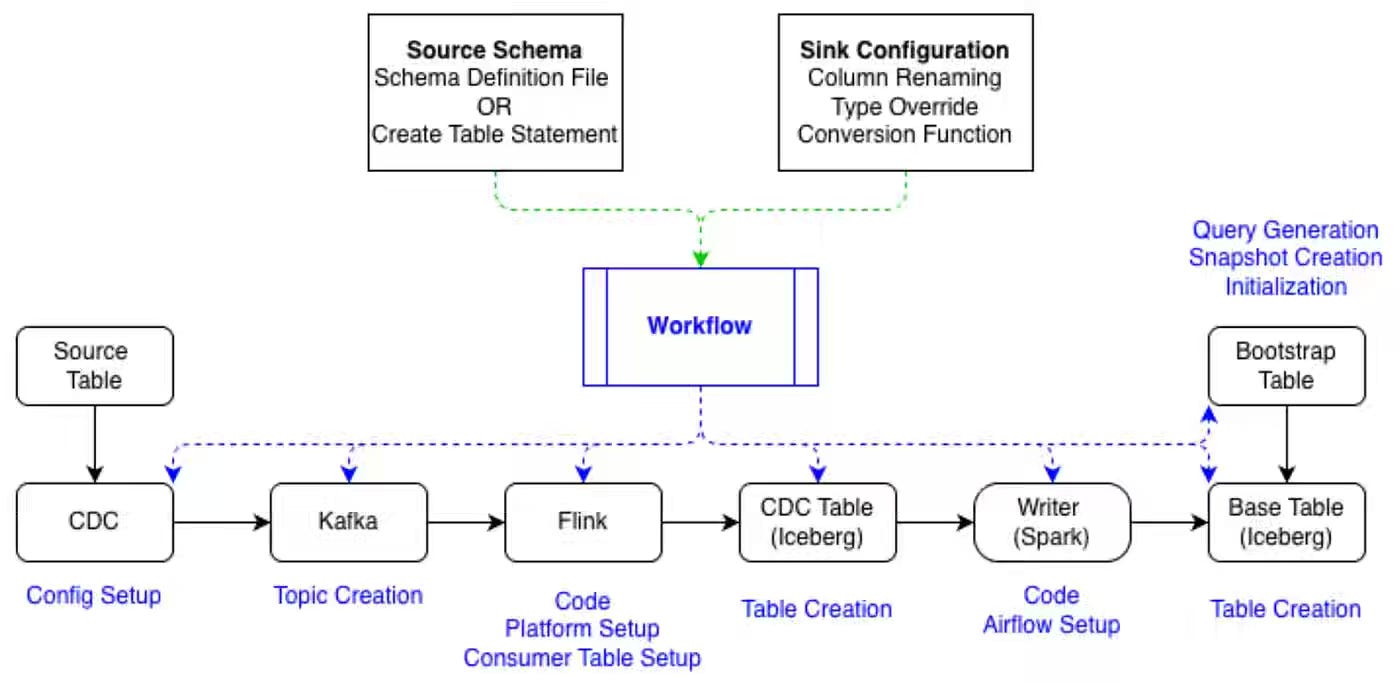
Maintaining backward compatibility for schema changes is a must-have for any data platform. The adoption of message protocols such as protobuf enables compile-time schema evolution. You would encounter an issue where protocols such as Protobuf are indexed-based systems, whereas catalogs are name-based. Pinterest writes about its data management system, which follows basic schema management principles to enable backward-compatible schema evolution.
Uber: Zone-Failure-Resilient OpenSearch® at Uber
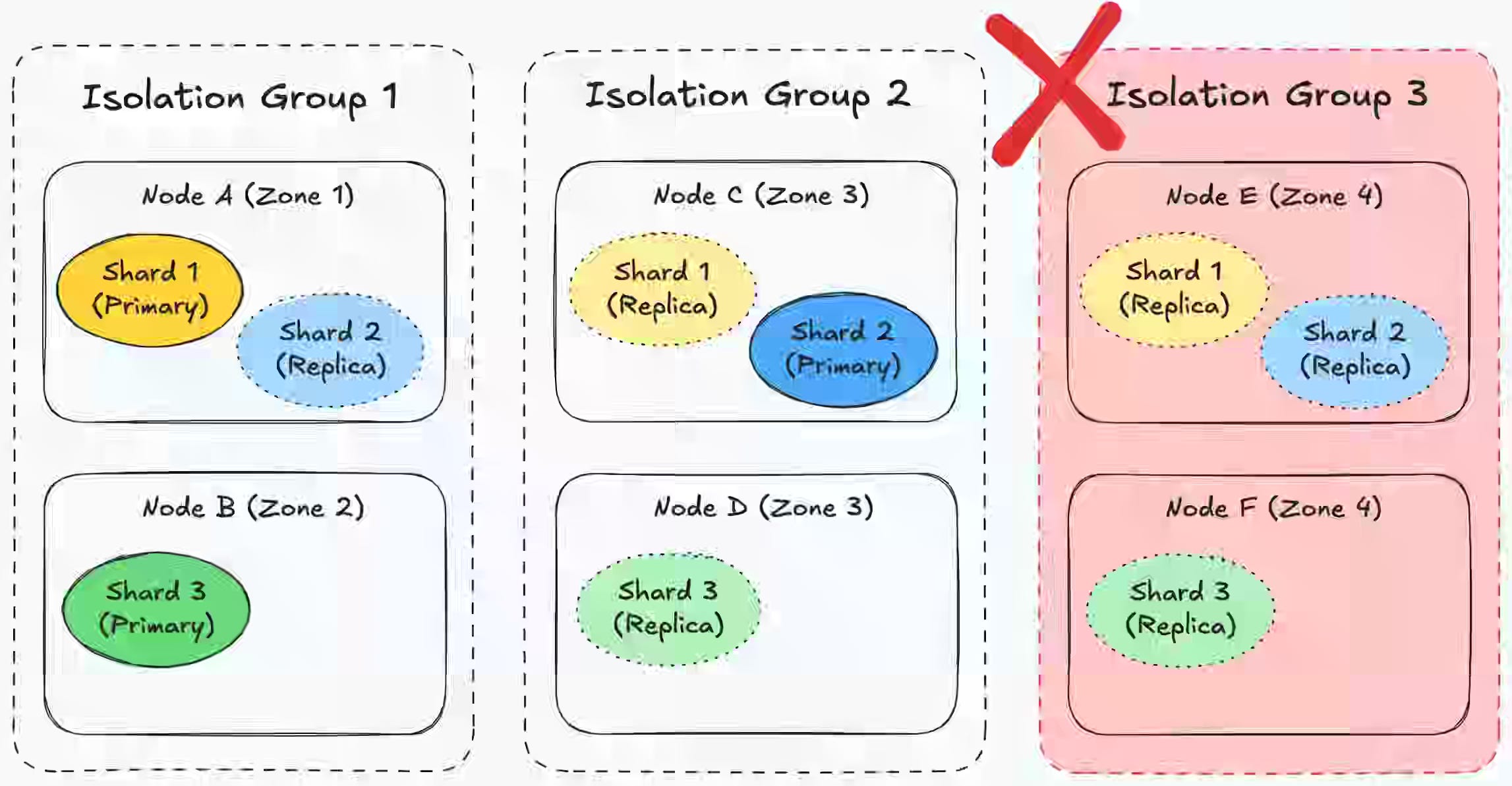
Uber writes about how it achieved Zone-failure-Resilience by combining OpenSearch’s native shard-allocation awareness features with its in-house isolation-group infrastructure. Uber combines this with forced shard allocation awareness to prevent chaotic data rebalancing during an outage, prioritizing overall cluster stability over immediate replication.
https://www.uber.com/us/en/blog/zone-failure-resilient/
Sponsored: AI Modernization Guide

AI is reshaping how data teams operate. But legacy pipelines, brittle workflows, and fragmented tooling weren’t designed for this shift.
Learn how leading teams are future-proofing their infrastructure before AI demands overwhelm it.
Tejas Sridhar: Computational Synapses: Rethinking Notebooks as Stateful Reasoning Systems
The author makes an interesting argument that we need to stop treating data notebooks as simple, linear scripts and start architecting them as "stateful computational nervous systems. The author proposes three distinct layers of observability in Notebook.
The Dataflow Layer: Tracking what depends on what (standard lineage).
The Reasoning Layer: Tracking why the pathway exists (turning business logic and assumptions into explicit code objects).
The Memory Layer: Tracking what actually happened during execution (cache status, runtime logs, validation checks).
Razorpay: Turning Scattered Data Into Queryable Segments at Scale: How Razorpay Built Its Customer Data Platform
Razorpay writes about its consent-native Customer Data Platform to unify billions of scattered user transactions into cohesive profiles. The architecture utilizes Spark for segment computation, DynamoDB for sub-30ms real-time serving, and Theta Sketches for rapid audience size estimation.
Grab: Architecting isolation, identity, and auditability for AI agents.
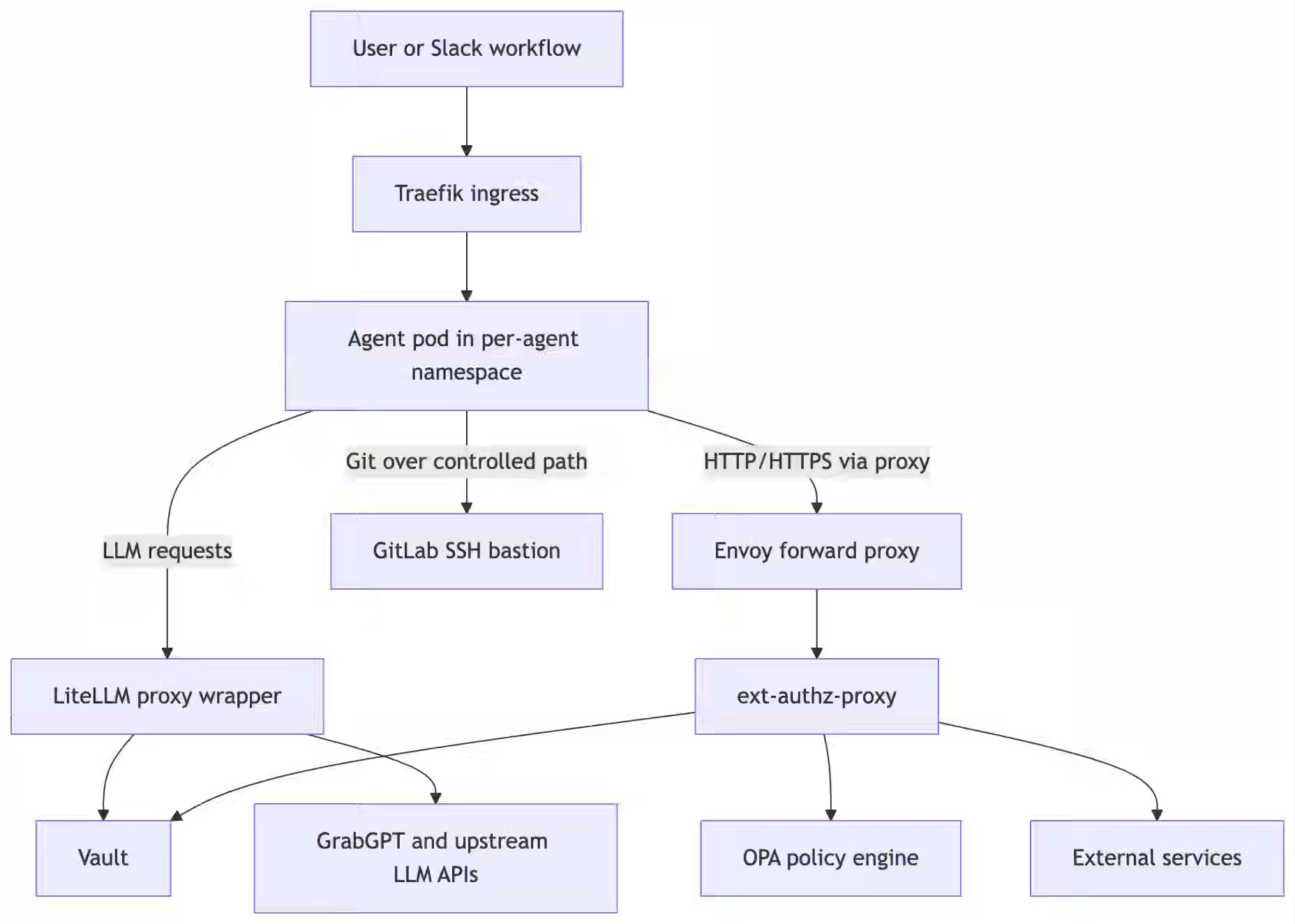
Grab writes about Palana, a Kubernetes-native substrate isolating each agent in its own namespace — handing agents placeholder tokens that an egress proxy swaps for real Vault credentials. The platform keeps real secrets out of agent runtime and routes every call through OPA-checked Envoy egress, anchored to an external control plane that terminates uncooperative agents.
Part 1: https://engineering.grab.com/palana-part-1-secure-platform-for-ai-agents
Part2: https://engineering.grab.com/part-2-palana-architecture
Fixel Smith: Six SQL patterns I use to catch transaction fraud
There is a lot more you can do with SQL alone. I believe we will be switching from spec-driven development to SQL-Driven development soon. SQL is something many have tried to break, with no success. The article is a classic example of why SQL is so powerful, yet simple.
https://analytics.fixelsmith.com/posts/sql-fraud-patterns/
Data Strata: How Ads Ranking Works: The Data System Behind Every Ad You See
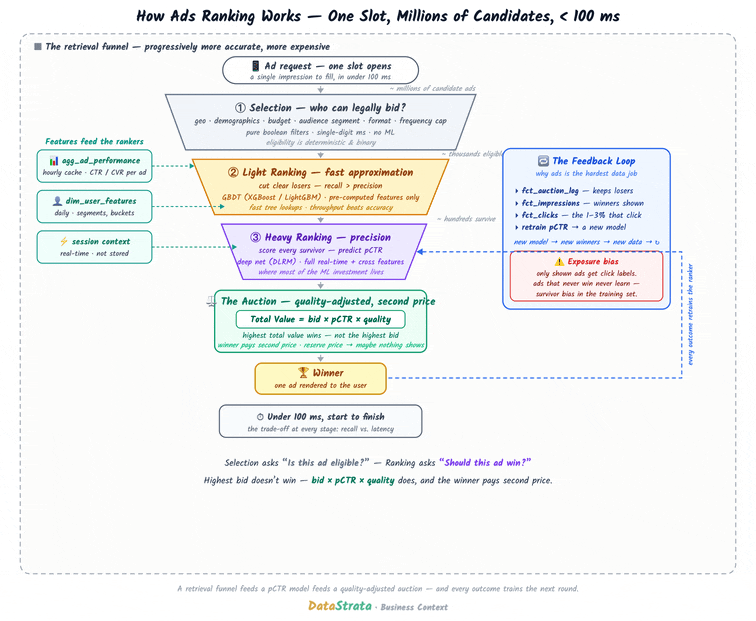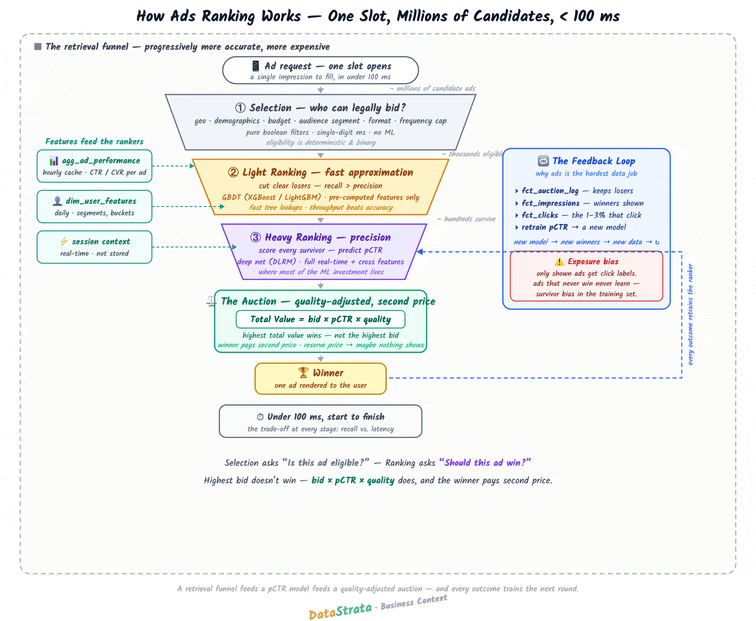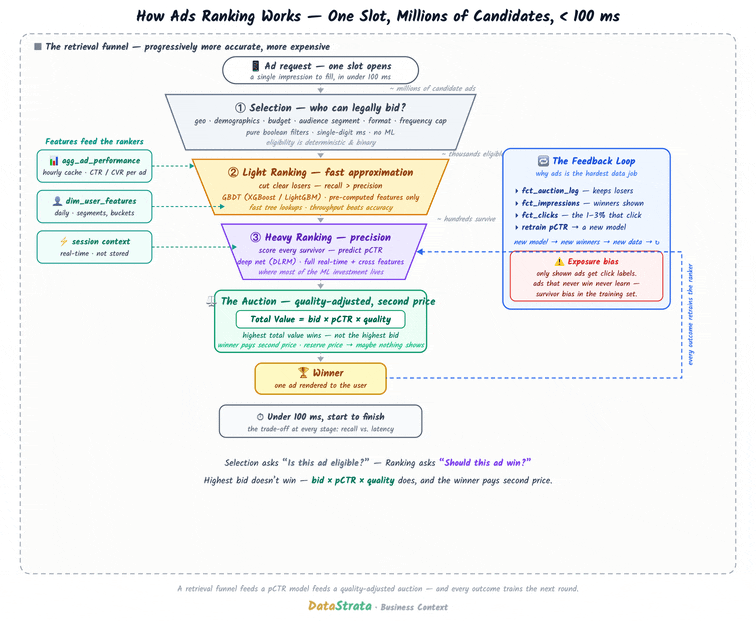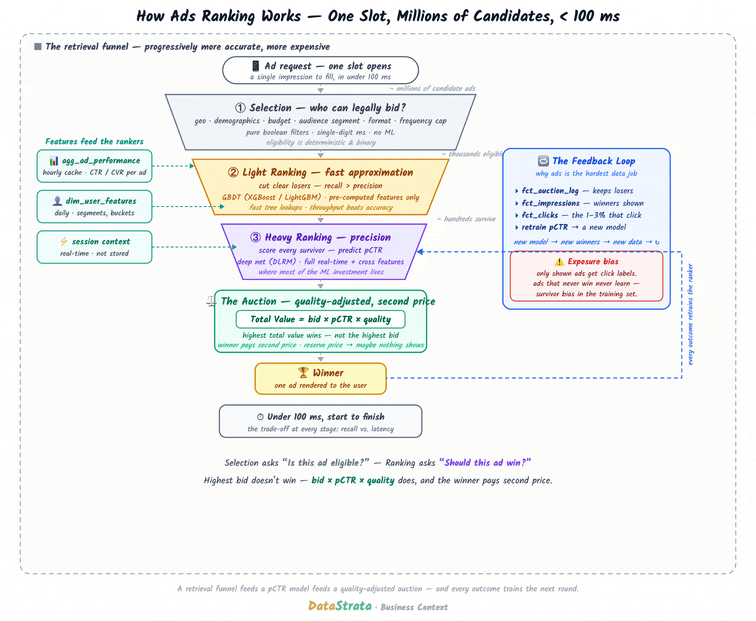
I’ve been getting a full 360-degree view of ad tech and data engineering for the ads engine recently. It is indeed a fascinating industry in which the entire financial model relies on data engineering efficiency. The article is a pretty good read to headstart data systems for ad ranking.
KoliStat: the-stats-duck v0.6.0 — statistics that live in your SQL
Data profiling is a key part of the system for overall data management. A good profiling tool can help auto-generate data contracts, run data quality checks efficiently, and be used for synthetic data generation as an indicator of the data distribution, etc. The author highlights that the stat-ducked plugin provides out-of-the-box integration with DuckDB. I believe this should be the default for the Lakehouse formats.
https://kolistat.com/blog/the-stats-duck-v0-6-0/
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.