
Data Engineering Weekly #99
The Weekly Data Engineering Newsletter


Data Engineering Weekly Is Brought to You by RudderStack
RudderStack provides data pipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. Sign up free to test out the tool today.
Benn Stancil: How Snowflake fails
Many companies are swinging the pendulum towards cost optimization, given the current economic condition. I ran a LinkedIn poll to find how much time the data engineers spend on cost optimization. Almost 1/3 of the engineers spend more than 20% of their time optimizing the cost.
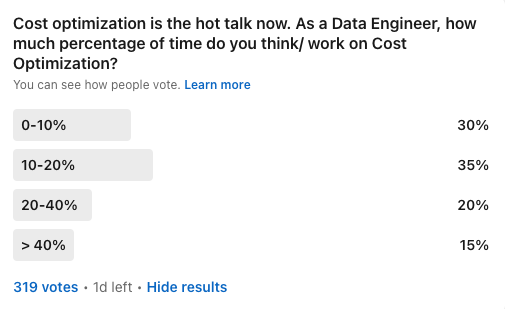
The increased focus on cost brings a lot of criticism to the cloud data warehouses and the transformation frameworks like dbt. Are we expecting too many things from the DB? Benn discusses on this blog Snowflake & data warehouse cost.
https://benn.substack.com/p/how-snowflake-fails
Ternary Data: Data Contract Battle Royale w/ Chad Sanderson vs. Ethan Aaron
The awareness of Data Contracts is on the rise, and many companies are adopting it using an Excel sheet or GitHub repo or via a schema registry. It also brings some confusion for many folks.
Historically, a centralized team changed the schema, which made the data warehouse slow and bureaucratic. There is a skepticism that data contracts (rightfully so) may fall into the same trap. However, there is no way one person in an organization can hold the entire data model.
A data contract should be decentralized, dynamically evolving, and collaborative. Schemata is one such attempt to bring decentralized, dynamic & collaborative data contracts.
Chad & Ethan had an exciting conversation on the data contract this week.
My take on data contracts

Meta: Introducing Velox: An open-source unified execution engine
Meta writes about Velox, its open-source unified execution engine for the data workload. The project is an exciting one to watch and how it gets adopted.
It is moving away from the default JVM-based execution engines with Spark & Presto yet provides full query compatibility.
The dataframe libraries can represent the execution plan as the Velox plan, which open the possibility of having a unified execution engine for both dataframe and SQL workloads.
https://engineering.fb.com/2022/08/31/open-source/velox/
Prukalpa: Key Takeaways from Gartner Data & Analytics Summit 2022
An excellent summarization of key takeaways from Gartner data & analytical summit 2022. The highlight on delivering the right insights at the right time, which I suppose we will keep trying to solve.
https://towardsdatascience.com/key-takeaways-from-gartner-data-analytics-summit-2022-ec908f9599df
Sponsored: Firebolt - A Fast Cloud Data Warehouse, But What About Other Features?
Robert Harmon from Firebolt responded to Tristan Handy, dbt Labs, and David Jayatillake, Metaplane, following their sharp review of Firebolt. He explains where the platform is currently at, what we're doing around mutability, and what we're building RIGHT NOW
https://www.firebolt.io/blog/hey-david-and-tristan-this-is-where-firebolt-is-at
ML6: Our takeaways and sessions to rewatch from Beam Summit 2022
Another excellent summarization blog on data conferences, where the ML6 team wrote about the Apache Beam Summit highlights and recommended rewatch sessions.
https://blog.ml6.eu/our-takeaways-and-sessions-to-rewatch-from-beam-summit-2022-fecee83d892e
Charlie Gerard: Building an aircraft radar system in JavaScript
One of the exciting articles I read over last week is about building an aircraft radar system in JavaScript. The blog is an excellent read for aspiring data engineers on how to think about data collection from a data source and derive insights to make a difference.
https://charliegerard.dev/blog/aircraft-radar-system-rtl-sdr-web-usb/
Sponsored: Hands-On Workshop: Data Incident Management for dbt | September 6 | 10.30 am EDT | 4.30 pm CEST
Learn how to integrate the transformational power of dbt with Soda's data incident management in this hands-on workshop, presented by Bastien Boutonnet. See how, with dbt + Soda, data teams can augment the tests that they run in dbt to manage data reliability and quality incidents, whether at the dataset or record level. And a whole lot more...including how to store dbt test results over time in Cloud Metrics Store to test and validate data and alert the right people at the right time before there is a downstream impact. Register now to listen, learn, and like on September 6.
https://www.eventbrite.com/e/data-incident-management-with-soda-and-dbt-tickets-348553873017
Monzo: The many layers of data lineage
Though it is a bold claim, lineage is vital for operating data. But How can we create a single interface that everyone can consume and understand the data lineage? The author discusses the layered approach from Google Maps and what data lineage visualization tools can learn from it.
https://medium.com/data-monzo/the-many-layers-of-data-lineage-2eb898709ad3
Coupang: Eats data platform: Empowering businesses with data
Coupang writes about its data platform for its food delivery business, Eats. The blog narrates all three types of data pipeline architecture depending on the data processing window.
Non-Real-Time
Near-RealTime
Real-time
The blog is an excellent characterization of the data pipeline, demonstrating how the architecture design varies for each category.
Sponsored: Announcing HIPAA Compliance
RudderStack is now HIPAA compliant and ready to sign BAAs with customers. Here, you'll learn how RudderStack makes security and compliance easy for healthcare data teams with its warehouse-first approach and features such as in-flight data transformations.
https://www.rudderstack.com/blog/announcing-hipaa-compliance
Trivago: Powering ML-Based Systems With Reliable Data: The Data Annotation Journey
Reliable labeled data is vital for efficient ML-based systems. Trivago shared its experience and practical tips on designing and tweaking data annotation projects to produce high-quality label data.
https://tech.trivago.com/post/2022-09-01-powering-ml-based-systems-with-reliable-data-annotation/
NuBank: Acing the Data Science Interview - 8 Practical Tips with Examples
Interviewing is always stressful, and it is exciting to see companies like NuBank sharing practical tips to ace data science interviews.
https://building.nubank.com.br/data-science-interview-pratical-tips/
Josh Berry: Finding Gaps with SQL
Finding the gaps/ missing value is the 99% case for the root cause analytics. The author echoes the same pattern and explains techniques and approaches to find the gaps with SQL.
https://medium.com/@jberry_33001/finding-gaps-with-sql-4f62982f797d
All rights reserved Pixel Impex Inc, India. Links are provided for informational purposes and do not imply endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.