
Engineering Growth: The Data Layers Powering Modern GTM
Building privacy-preserving pipelines that unify zero-, first-, second-, third-, and fourth-party data into a coherent GTM ecosystem.

Growth no longer rewards the widest net. Modern Go-To-Market(GTM) teams win with precision, not volume. They build revenue on infrastructure—pipelines, warehouses, and customer data platforms that turn signals into action.
The shift is fundamental. Marketing teams once measured impressions and clicks. Sales teams worked from cold lists. Customer success reacted to churn. Today, these functions operate as a unified data ecosystem, synchronizing zero-, first-, second-, third-, and fourth-party data into coordinated market motion.
Data engineers architect this system. We design the pipelines that define GTM accuracy, latency, and trust. When we build it well, the marketing, sales, and customer success move in harmony. When we don’t, the entire revenue engine stutters.
But not all data is created equal. The modern GTM stack draws from five distinct data sources, each with unique engineering challenges, governance requirements, and strategic value:
Zero-party data: What customers intentionally share through preferences and explicit consent
First-party data: What you observe through behavioral tracking and product interactions
Second-party data: What partners share through privacy-preserving collaboration
Third-party data: What vendors sell through aggregated external sources
Fourth-party data: What emerges from multi-company consortium networks
Each data type requires different infrastructure, carries different levels of trust, and demands different engineering disciplines. Understanding these distinctions isn’t academic—it’s foundational to building GTM systems that scale, comply with regulations, and deliver measurable business impact.
This article examines the GTM stack through the lens of data provenance, exploring not only what data powers modern go-to-market strategies but also how to engineer systems that integrate these five data sources responsibly and effectively.
Zero-Party Data: Consent by Design
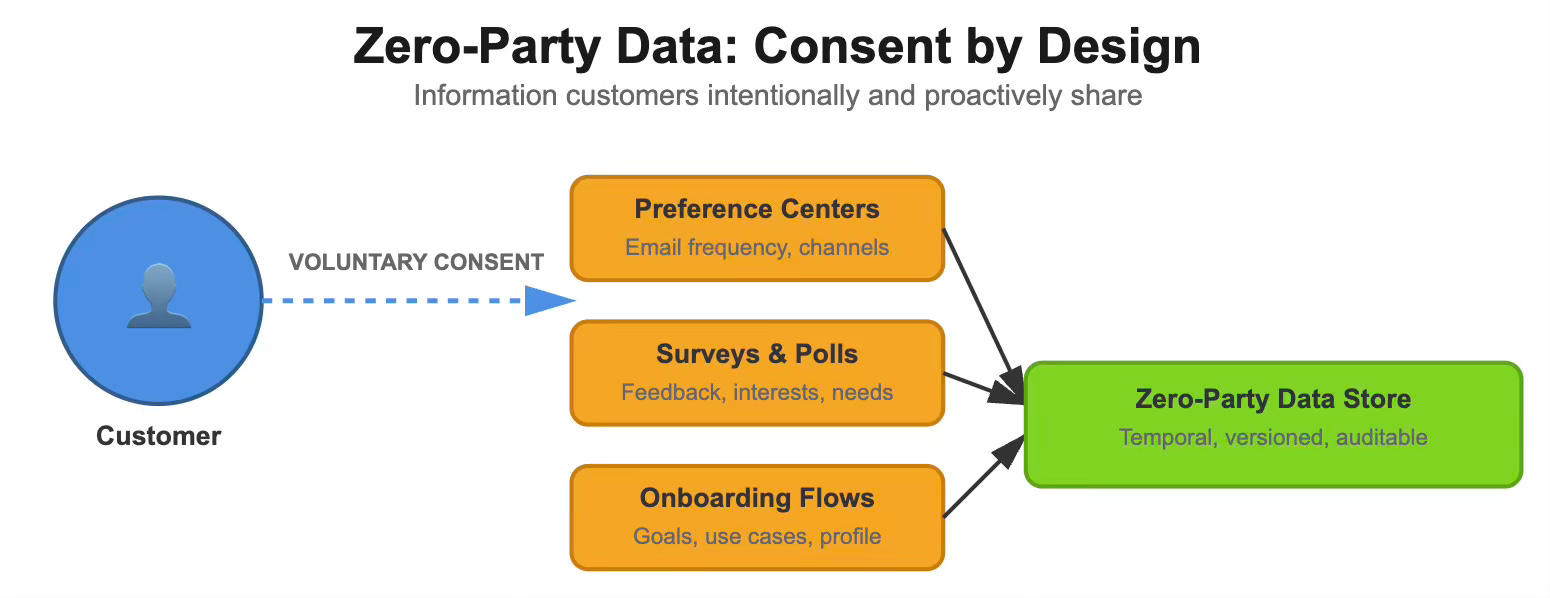
Zero-party data captures what customers intentionally share, including their preferences, intentions, and explicit consents. Customers provide this data through surveys, preference centers, and onboarding flows. Unlike behavioral data, which you infer, zero-party data comes with clarity—but also volatility.
The Engineering Challenge
Preference data ages quickly. A customer who opted into weekly emails in January may want to switch to monthly emails by March. Engineers must design systems that support versioning, temporal validity, and schema evolution to ensure seamless integration and maintainability.
Implementation Pattern
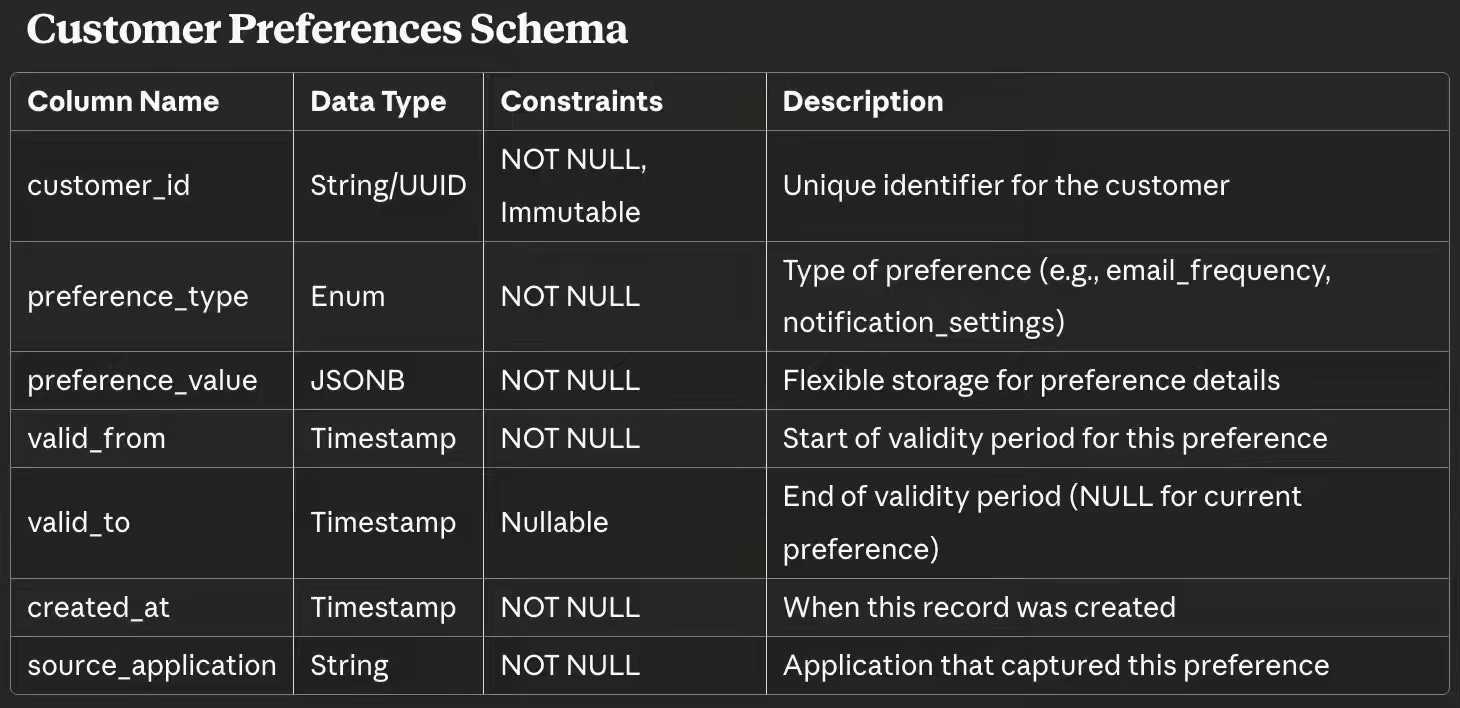
Store preferences as temporal records, not mutable fields. When a customer updates a preference, insert a new row with a new valid_from timestamp and update the previous record by setting its valid_to timestamp to the current date. This approach preserves history and enables point-in-time queries—critical when you need to prove compliance or analyze preference drift over time.
Don’t store preferences as boolean flags in your user table—you lose history and make schema evolution painful.
First-Party Data: The Behavioral Graph
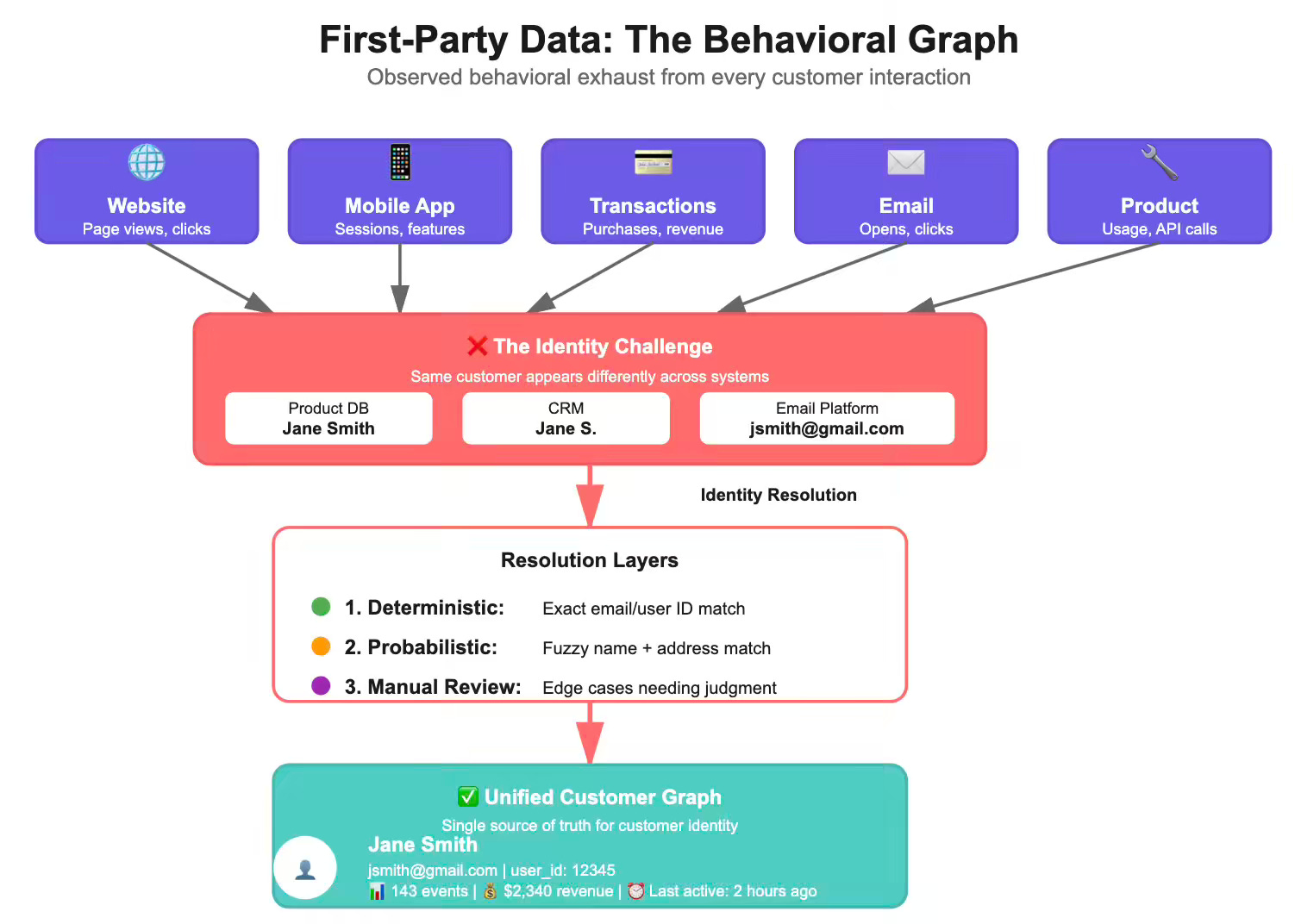
First-party data captures every digital interaction: product usage, transactions, email clicks, and app sessions. The challenge isn’t collection—it’s connection. Every event must resolve to a unified customer identity.
The Identity Resolution Problem
Your product database knows “Jane Smith.” Your CRM tracks “Jane S.” Your email platform sends to “jsmith@gmail.com.” These might represent the same person, or three different people. Identity resolution determines GTM accuracy.
A Practical Resolution Strategy
Most organizations approach identity resolution in layers:
Deterministic matching: Exact matches on email, user ID, or phone number
Probabilistic matching: Fuzzy matches on name + address, device fingerprints, or behavioral patterns
Manual review: Edge cases requiring human judgment
The critical decision: where do you perform this resolution?
Option A: In your CDP
Pros: Real-time resolution, vendor-managed complexity
Cons: Vendor lock-in, limited customization, expensive at scale
Best for: Teams prioritizing speed-to-market over cost optimization
Option B: In your data warehouse
Pros: Full control, lower marginal cost, custom logic
Cons: Higher initial complexity, requires strong data engineering
Best for: Teams with mature data practices and cost sensitivity
Option C: Hybrid approach
Pros: Real-time resolution for activation, batch resolution for analytics
Cons: Maintaining consistency across systems requires discipline
Best for: Most organizations once they scale past initial CDP adoption
Our recommendation: Start with CDP resolution for activation use cases. As you scale, move probabilistic matching and analytics-focused resolution into your warehouse. Use your CDP as the activation layer and your warehouse as the source of truth.
Cost consideration: At 10 million monthly active users, warehouse-native identity resolution typically costs 60-80% less than CDP-only approaches, though implementation requires 2-3 months of engineering time.
Second-Party Data: Privacy-Preserving Collaboration
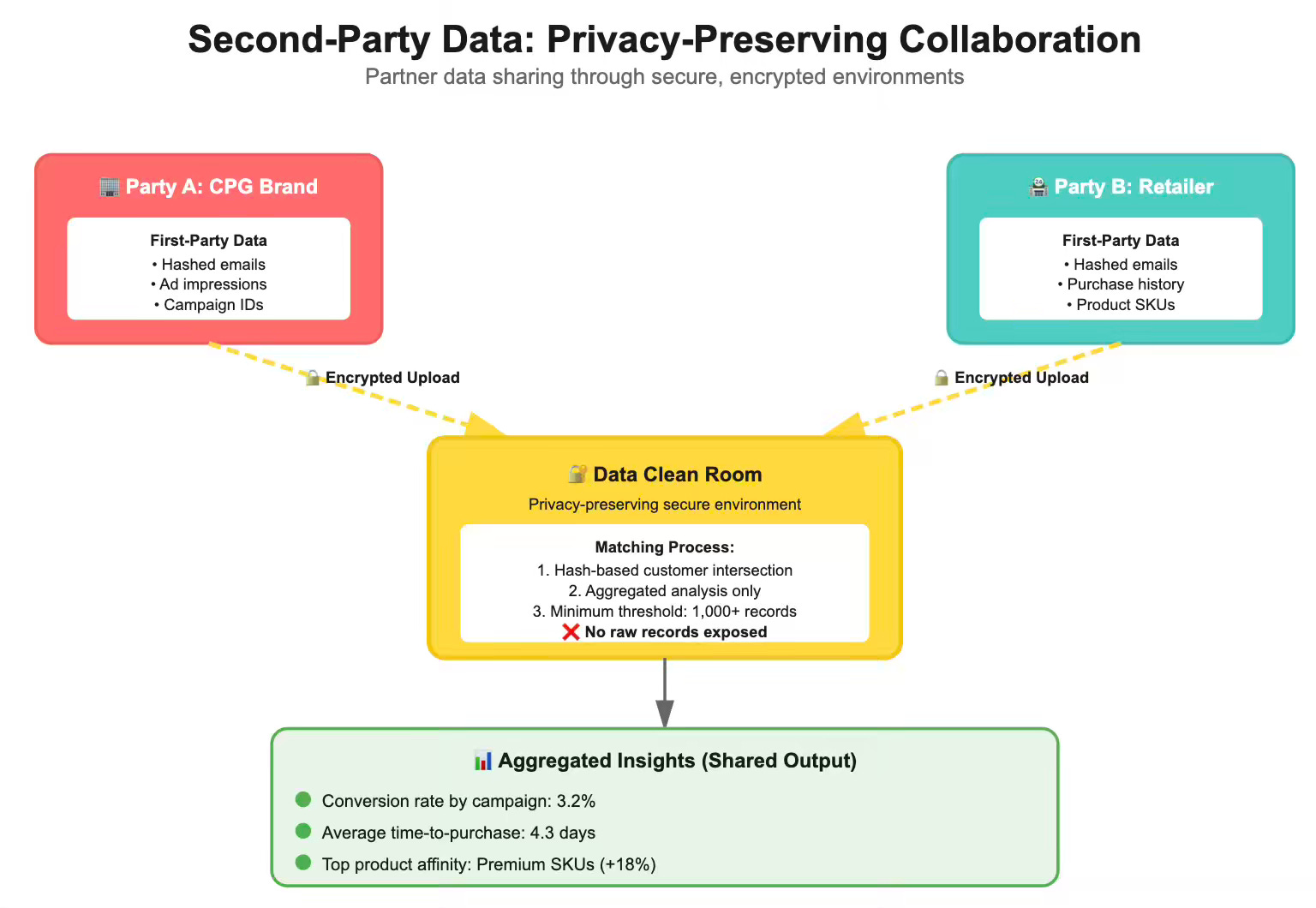
Second-party data flows through partnerships—one company’s first-party data, shared under agreement. A retailer might share purchase data with a brand. A publisher might share engagement data with an advertiser.
The engineering challenge: how do you join datasets without exposing raw customer records?
Data Clean Rooms
Clean rooms provide secure environments where two parties can match customer data, run analysis, and activate insights—all without sharing underlying records.
How Clean Rooms Work?
Both parties upload hashed customer identifiers (typically SHA-256 of email addresses)
The clean room performs an intersection to find overlapping customers
Analysts run pre-approved queries against aggregated data
Results return only if they meet minimum threshold requirements (typically 1,000+ matched records)
Neither party sees the other’s raw data
Implementation Example
A CPG brand wants to measure how its retail media spend drives in-store purchases. The retailer won’t share customer purchase records. The brand won’t share its media exposure data. A typical clean room workflow will be,
Brand uploads: hashed_email, ad_impression_timestamp, campaign_id
Retailer uploads: hashed_email, purchase_timestamp, product_sku
Clean room joins on hashed_email and produces
Aggregate conversion rate by campaign
Time-to-purchase distribution
Product affinity analysis
No individual-level records exposed
Governance Requirements
Second-party data partnerships require more than technical infrastructure. Engineers must navigate:
Data Processing Agreements (DPAs): Legal contracts defining allowed uses
Schema contracts: Agreed-upon data formats and refresh cadences
Audit trails: Logging all queries and data access
Encryption standards: Typically AES-256 for data at rest, TLS 1.3 for transit
Don’t build direct API integrations that expose customer-level data—even with authentication, this creates compliance risk.
Third-Party Data: The Fading Giant
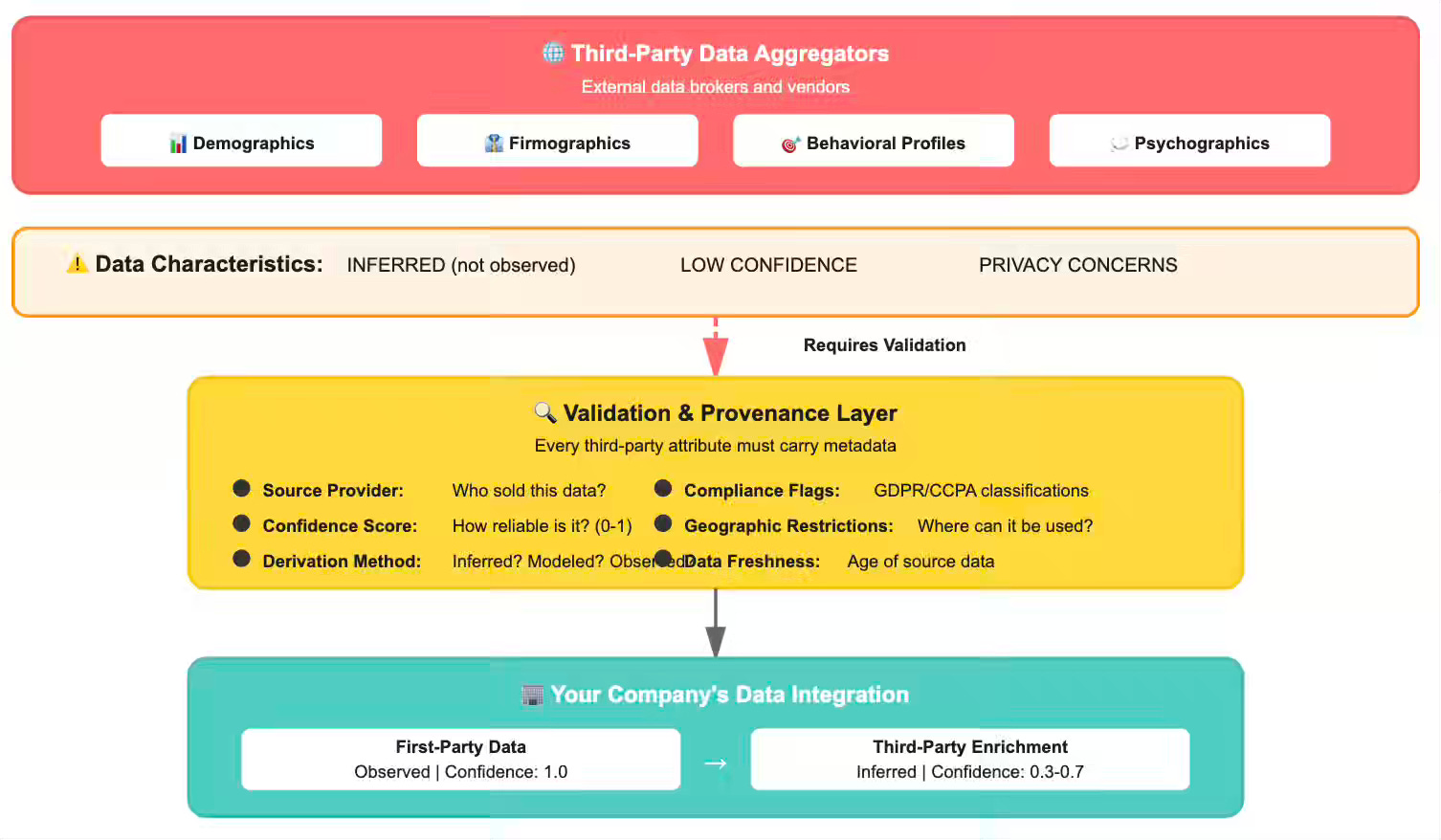
Third-party data once ruled the digital advertising world. Aggregators and data brokers built empires by collecting behavioral profiles from across the web—tracking users through cookies, pixels, and cross-site identifiers.
The foundation of this ecosystem has crumbled. Safari’s Intelligent Tracking Prevention arrived in 2017. Firefox followed with Enhanced Tracking Protection in 2019. Chrome’s planned cookie phase-out will complete the technical dismantling. Meanwhile, GDPR (2018), CCPA (2020), and expanding global privacy laws have made the business model legally untenable. The era of invisible tracking is coming to an end.
Yet third-party data hasn’t disappeared entirely. When engineered correctly and used responsibly, it still provides value—just in fundamentally different ways than before.
Where Third-Party Data Still Matters
Market Intelligence Before First-Party Scale
Companies entering new markets lack first-party data. A startup targeting healthcare providers requires a baseline understanding of the market size, competitive landscape, and characteristics of the addressable audience. Third-party firmographic data provides this foundation before the company accumulates its own behavioral signals.
Training Data for Cold Start Problems
Machine learning models need training sets. When launching a recommendation engine, you lack customer behavioral data. Third-party purchase pattern datasets can be used to bootstrap initial models. As customers interact with your platform, first-party behavioral data gradually replaces the third-party training foundation.
Enrichment with Appropriate Skepticism
Third-party vendors sell demographic and psychographic enrichment: estimated income brackets, household composition, lifestyle indicators, and purchase propensity scores. These attributes can fill gaps in sparse customer profiles.
The Engineering Challenge: Integration Without Contamination
The difficulty isn’t whether to use third-party data—it’s how to integrate it without compromising data quality, customer trust, or regulatory compliance. Third-party data requires a different infrastructure than first-party data.
Provenance Tracking as First-Class Metadata
Every third-party data point needs comprehensive provenance metadata. Downstream systems must answer: Where did this come from? How was it derived? How confident should we be? When does it expire?
Hierarchical Treatment: Observed Beats Inferred
Third-party data should never receive equal weight to first-party observed behavior. Systems must explicitly prioritize actual customer actions over vendor inferences.
Data Validation Before Integration
Third-party data frequently contains errors, outdated information, and logical inconsistencies. Vendors may provide income estimates that contradict income brackets, demographic data that violates geographic distributions, or confidence scores that don’t match actual accuracy.
Geographic and Regulatory Filtering
Third-party data that is acceptable in one jurisdiction may be in violation of regulations in another. Data collected under the “legitimate interest” principle in the US may be considered illegal for use with EU customers under the GDPR. Demographic inferences made about most customers may qualify as “sensitive personal information” under the CCPA for California residents.
Fourth-Party Data: Collaborative Intelligence Networks
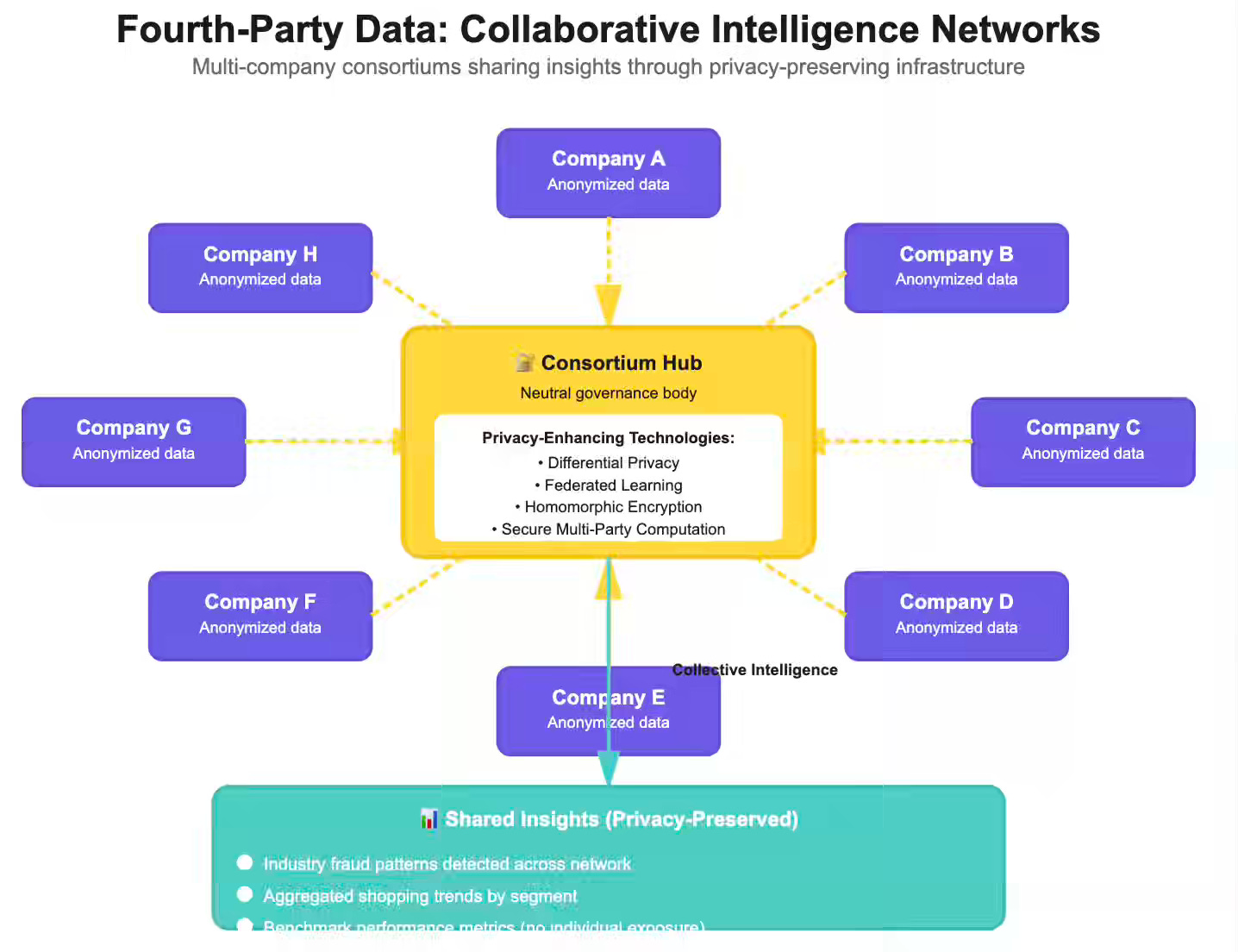
Fourth-party data represents the next evolution of data collaboration. While second-party data involves direct partnerships between two companies, fourth-party data emerges from multi-company consortiums—industry networks where dozens or hundreds of organizations pool anonymized insights through secure, privacy-preserving infrastructure.
Think of credit bureaus, but purpose-built for specific industries. A retail consortium might include fifty brands sharing aggregated shopping patterns through clean rooms. A financial services network might pool fraud signals across hundreds of institutions. An advertising cooperative might combine campaign performance data across dozens of publishers. No single company sees another’s raw data, but all benefit from collective intelligence.
The Distinction from Second-Party Data
Second-party partnerships are bilateral—Brand A works directly with Retailer B. They negotiate terms, share specific datasets, and derive mutual benefit from their unique relationship.
Fourth-party ecosystems are multilateral, with thirty companies contributing to a shared intelligence pool governed by consortium rules, standardized data formats, and technical safeguards managed by a neutral third party or a consortium governance body.
The infrastructure differs fundamentally. Second-party clean rooms typically involve two parties matching their customer bases. Fourth-party networks involve many-to-many matching, requiring more sophisticated privacy preservation and governance.
How Fourth-Party Networks Operate
Trade associations or industry groups establish data cooperatives. Members contribute anonymized, aggregated data in accordance with consortium standards. A neutral entity manages the infrastructure and ensures no single member can reverse-engineer another’s proprietary data.
Example: A group of regional banks pools anonymized fraud signals. When one bank detects a fraud pattern, the consortium disseminates a privacy-preserving alert to all members without disclosing individual customer identities or specific transaction details.
Engineering Challenges in Fourth-Party Networks
Data Standardization at Scale
Bilateral second-party partnerships can negotiate custom schemas. Fourth-party consortia require standardized data formats across dozens of participants. This demands rigorous schema governance, versioning protocols, and transformation pipelines that normalize each member’s data into consortium standards.
Attribution and Contribution Tracking
In bilateral partnerships, both parties are aware of their respective contributions. In multilateral consortia, members require proof that they’re contributing valuable data without revealing specific details about their business. This requires privacy-preserving contribution metrics—ways to measure data quality and volume without exposing competitive intelligence.
Governance and Access Control
Who can query the consortium data? What analyses are permitted? How are disputes resolved? Fourth-party networks require formal governance structures, technical access controls that enforce policy, and audit trails that prove compliance without compromising privacy.
The Vendor Landscape: Technology by Data Type

The modern GTM data stack spans dozens of vendor categories, each serving different data types and engineering needs. Understanding which vendors operate in which layer helps data engineers make informed decisions about building versus buying and evaluating technology partnerships. Zero-party data typically requires custom engineering with consent management platforms. First-party infrastructure divides between CDPs for real-time activation and warehouses for analytical identity resolution. Second-party collaboration happens through clean rooms—either walled gardens, cloud-native solutions, or independent platforms. Third-party vendors provide enrichment from B2B firmographics to behavioral intent signals, though usage requires validation and skepticism. Fourth-party infrastructure enables multi-company consortia through dedicated platforms or custom-built clean room networks.
Conclusion: From Infrastructure to Impact
The five-party data taxonomy isn’t static—it’s evolving as privacy regulations become more stringent and technology advances. Zero-party data will become increasingly valuable as third-party sources become less relevant or disappear entirely. Second-party and fourth-party collaborations will grow as companies realize collective intelligence beats proprietary hoarding. The data engineers who master privacy-preserving technologies—such as differential privacy, federated learning, and secure computation—will architect the next generation of GTM systems. Build your pipelines with this evolution in mind: prioritize first-party infrastructure, invest in clean room capabilities, and design for a future where trust and transparency aren’t optional—they’re the foundation of competitive advantage.
All rights reserved, Dewpeche Pvt Ltd, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
Hi! Have you seen arrangements like data clean rooms (2nd or 4th party data) work efficiently in practice?
How does one make sure that partners are properly incentivized to share data about customer behavior that other partners in the consortium might find valuable? How does one make sure that partners are happy with what they receive in return, making sure they don’t feel like they are oversharing and retracting from the deal?