
Engineering Privacy: A Technical Overview of Privacy in Data Systems
From Collection to Deletion: Safeguarding Data at Every Stage


Once again, I want to thank the Data Heros community. Last Friday, we discussed the challenges in bulk discovery and anonymization processes in data warehouses. The collective design choices and ideas lead to a comprehensive overview of thinking about designing data infrastructure with a privacy-first approach.
Why care about privacy?
Privacy and access management within data infrastructure is not just a best practice; it's a necessity. Regulations like GDPR (General Data Protection Regulation), focusing on data subject rights and cross-border data flows, have significant implications for data handling practices. Robust privacy and access management protocols are crucial for GDPR compliance, protecting sensitive information, and maintaining user trust.
Simultaneously, The proliferation of AI and language models has led to surging regulatory requirements. Let's briefly tour the AI regulations shaping the global landscape.

By prioritizing these measures, you mitigate legal and financial risks and demonstrate your commitment to data privacy, which can be a significant differentiator in the marketplace and positively impact your business.
Privacy in Modern Data Infrastructure
When it comes to privacy in data infrastructure, there are three key components: enforcing least privilege access, encrypting sensitive data, and effectively managing data deletion. Let's examine them in more detail.
Least Privilege Access: Keep It Tight
The least privileged access model gives users the minimal level of access they need to do their jobs—nothing more. This approach isn’t just a good practice; it’s a requirement in many privacy regulations. For example, GDPR and HIPAA require strict access controls to protect sensitive data. Using Role-Based Access Control (RBAC) or Attribute-Based Access Control (ABAC) in LakeHouse architectures helps enforce this model. Regularly auditing and adjusting access roles ensures that only the right people can access the right data at the right time. Not only does this reduce the risk of breaches, but it also checks a key box in regulatory compliance.
Data Anonymization: Protect What Matters
Data anonymization is your best line of defense against unauthorized access. Encrypting data at rest and in transit ensures that sensitive information stays safe, even if someone gains access. Regulations like GDPR, HIPAA, and PCI-DSS make encryption a must-have. Most cloud providers offer built-in encryption options and key management systems (KMS), making it easier to stay compliant without sacrificing security. Encryption is one of the easiest ways to demonstrate that you're taking privacy seriously, especially in a data breach where encrypted data is often exempt from notification requirements.
Data Deletion: Clean Up Your Digital Footprint
Data deletion is not just a nice-to-have—it’s a regulatory obligation. Laws like GDPR's 'Right to be Forgotten' and CCPA’s data retention rules require organizations to delete personal data when it’s no longer needed or a user requests it. Implementing automated lifecycle policies to delete data after a specific period is crucial for compliance and reducing the risk of unnecessary data retention.
Reference Architecture
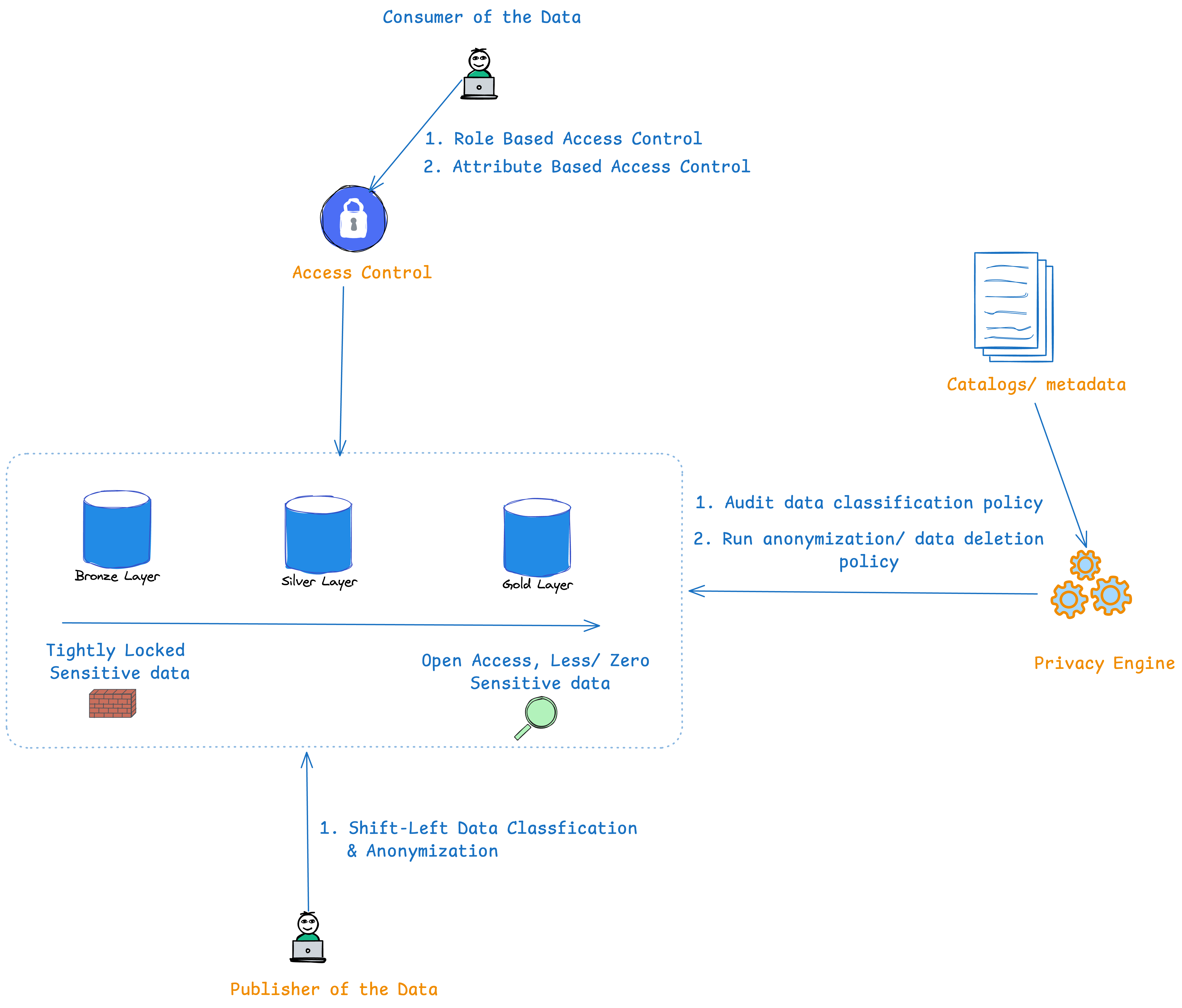
Data Organization: The Medallion Architecture
A fundamental principle of privacy-conscious data management is treating data based on sensitivity. The Medallion Architecture, also known as the "Bronze, Silver, Gold" architecture, is a robust approach that segregates data into layers of increasing refinement and accessibility:
Bronze Layer: Various sources ingest raw, unprocessed data into this landing zone, where privacy-sensitive data exists. The data team should always tightly lock and have restricted access to the bronze layer.
Silver Layer: In this zone, data undergoes cleaning, transformation, and enrichment, becoming suitable for analytics and reporting. Access expands to data analysts and scientists, though sensitive elements should remain masked or anonymized.
Gold Layer: This layer contains highly curated, aggregated data, often optimized for specific business use cases. It's accessible to a wider audience, including business users and BI tools.
The flow of sensitive data through this architecture ensures that it's progressively desensitized as it moves from Bronze to Gold. A conscious design choice to reduce the sensitive data as it flows through the right minimizes the risk of exposure while still enabling valuable insights to be extracted.
Access Control: RBAC & ABAC
Protecting data requires fine-grained control over who can access what. Two prevalent models are:
Role-Based Access Control (RBAC): This system assigns permissions based on predefined organizational roles (e.g., data analyst, marketing manager). It's relatively simple to implement and manage but can become rigid in dynamic environments.
Attribute-Based Access Control (ABAC): Grants or denies access based on attributes of both the user (e.g., department, clearance level) and the data (e.g., sensitivity, project). It offers greater flexibility and granularity but can be more complex to configure and maintain.

The choice between RBAC and ABAC depends on your organization's specific needs. Smaller organizations or those with stable roles may find RBAC sufficient, while larger enterprises or those with complex data-sharing requirements benefit from ABAC's adaptability. Grab’s blog on migrating from RBAC to ABAC is an excellent reference design.
Privacy Engine: Auditing and Anonymization
A privacy engine acts as a watchdog within your data warehouse, ensuring compliance with data classification policies and enabling automated data protection actions. Key functions include:
Auditing data classification policy enforcement: The engine continuously monitors data access patterns and flags any violations of classification rules. This helps identify unauthorized access attempts or data misclassification.
Bulk deleting and anonymization: When data reaches its end-of-life or needs to be desensitized, the engine can perform bulk deletion or anonymization jobs. Anonymization techniques like masking, pseudonymization, and generalization render data unidentifiable while preserving its utility for analysis.
Challenges in this area include:
Ensuring consistent enforcement of policies across diverse data stores.
Managing secret keys for the anonymization algorithms.
Mutation is an expensive operation in LakeHouse and modern data warehouses.
BYOC is another architectural style to consider in the anonymization process. With BYOC, all the data anonymization for a client happens via a customer-supplied secret key, aka BYOC(Bring Your Own Key). Clients can remove their keys when they no longer require the service, which makes the data non-readable. Slack writes an in-depth article on how it manages enterprise keys as a reference design.
Shift-Left Data Governance: Early Classification and Anonymization
Traditional data governance models focus on applying privacy controls after collecting data. However, a "shift-left" approach advocates integrating data classification and anonymization into the data publishing phase. This has several advantages:
Privacy is baked in from the start: Sensitive data is protected as soon as it enters the system, reducing the risk of accidental exposure.
Reduced downstream complexity: Classifying and anonymizing data early reduces the effort required to manage and enforce policies in the data warehouse.
Improved data quality: Early classification enables better data lineage and more accurate data cataloging.
Conclusion
Privacy by design is often an afterthought in an organization. However, streamlining the medallion architecture from a privacy perspective can give enough time to strengthen with anonymization and access control. If you’re in the middle of or thinking about the privacy architecture in your organization, please feel free to schedule a time to chat here.
All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer” opinions.
Can you elaborate on shift left with an example? E.g. what do you mean by publishing? Is it when the data is collected at the source (OLTP/SaaS applications) or is it when the data is landed raw in a lake/warehouse? At what point would you apply shift left?