
ETL is Dead
Why the shift from human-operated to agent-operated data warehouses demands a new architecture

More ETL pipelines will run in 2027 than in any year in history. AI will generate more extraction jobs, more transformation logic, and more loading routines than any team of data engineers could write by hand. The volume of ETL will explode.
And ETL is still dead.
Not dead the way Latin is dead — no one speaks it. Dead, the way landlines are dead — they still work, millions exist, but nobody builds their communication strategy around one. ETL is dead as the defining work of data engineering. Dead as the thing we hire for, build careers around, and organize teams to do. The pipelines keep running. The professional identity built around them does not survive.
The Warehouse Was Always a Metaphor. Now the Metaphor Is Breaking.
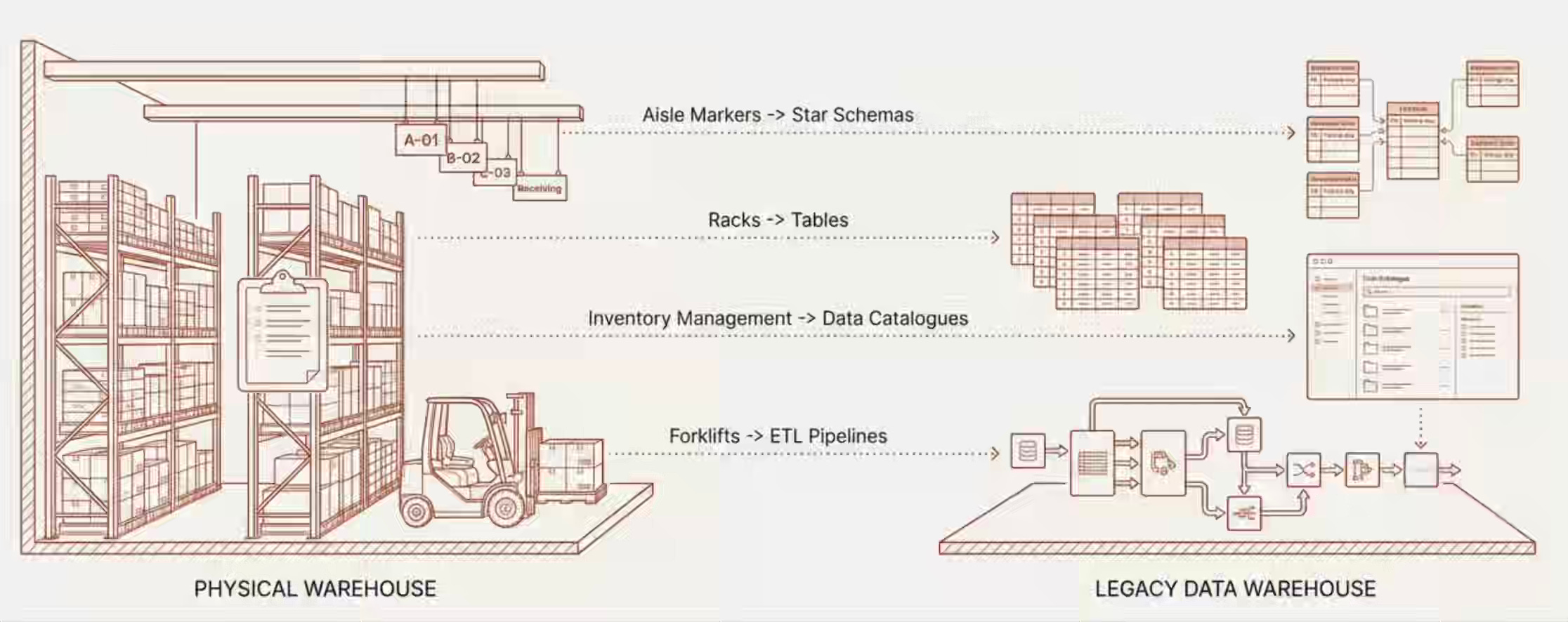
We literally called it a data warehouse. And that wasn’t just naming — we replicated the entire physical warehouse operating model into the digital world. Racks became tables. Inventory management became catalogs. Forklifts became ETL pipelines. Floor workers became data engineers. Shift supervisors became analytics leads.
Every technique we built — star schemas, slowly changing dimensions, medallion architectures, conformed dimensions — served the same purpose as aisle markers and shelf labels in a physical warehouse: help a human walk in, find what they need, and carry it out.
Data modeling organizes information so humans can discover it. Data catalogs provided wayfinding to help humans navigate them. The medallion architecture created a pick-pack-ship assembly line where humans inspected and validated data at each station. Naming conventions — fact_orders, dim_customers — acted as signage so humans could read the shelves at a glance.
Every design decision is optimized for human cognition. And then the operator changed.
What Happened When Robots Entered the Physical Warehouse
When Amazon deployed Kiva robots, they didn’t replace human tasks one-for-one. They redesigned the entire warehouse around a different operator.
Physical warehouses built for humans had wide aisles because humans need space to walk. They grouped items logically because humans need to remember where things are. They placed high-demand products at eye level because humans have ergonomic constraints. They posted signage everywhere because humans need wayfinding.
Robotic warehouses threw all of that out. Aisles shrank because robots don’t need shoulder width. Shelving went floor-to-ceiling because robots don’t have ergonomic limits. Logical grouping became unnecessary because robots navigate by coordinates, not memory. Signage disappeared because robots don’t read signs — they read instructions.
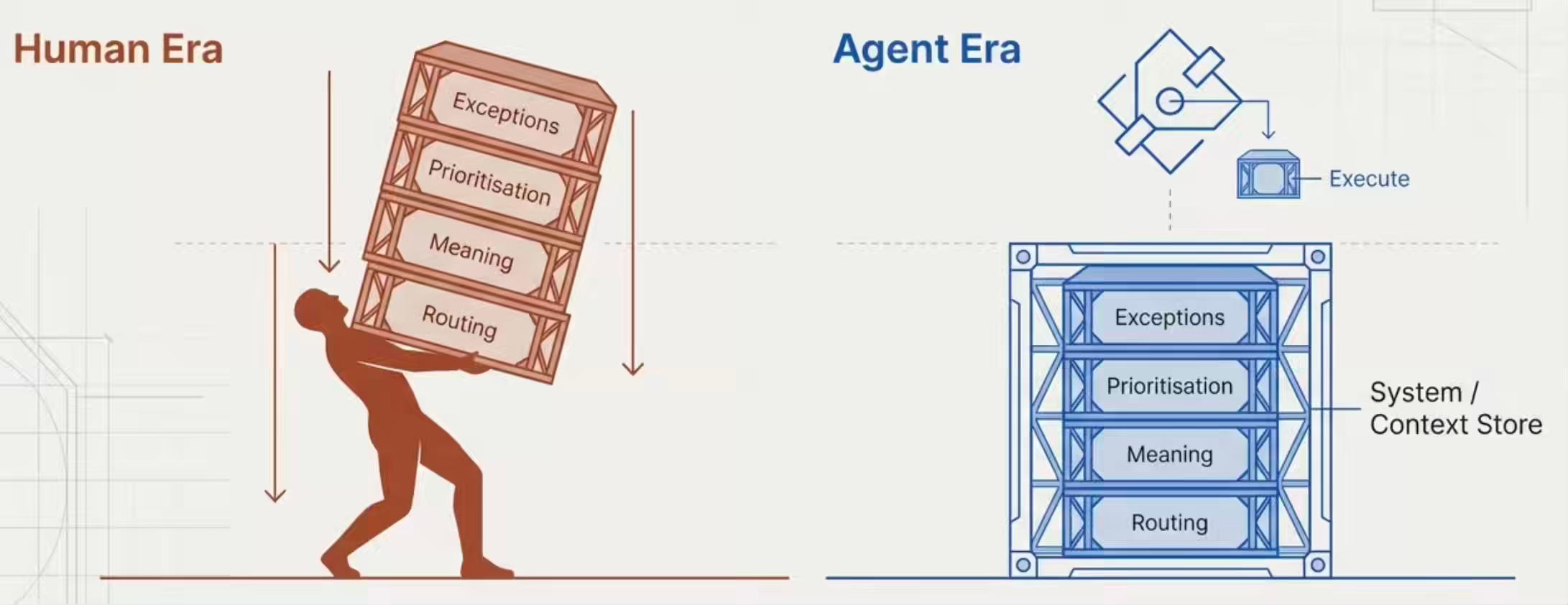
But the biggest gains weren’t physical. They were cognitive. Human warehouse workers carried an enormous cognitive load — remembering locations, making routing decisions, prioritizing picks, and mentally handling exceptions. Robots eliminated that cognitive burden entirely. The warehouse didn’t just move faster. It became a fundamentally different system that could handle complexity no human floor operation could manage.
The Data Warehouse Is Still Designed for Human Forklift Operators
Now look at our data warehouse through this lens.
Star schemas and dimensional modeling exist so a human analyst can visualize how tables relate. A human needs to see the star — the fact table at the center, dimensions radiating outward. An agent doesn’t need a star. It needs a validated semantic definition of what each entity means and how entities connect.
Data catalogs are digital signage. We built them because humans need to browse and discover what’s in the warehouse. An agent doesn’t browse a catalog the way a human walks an aisle. It queries for a validated meaning.
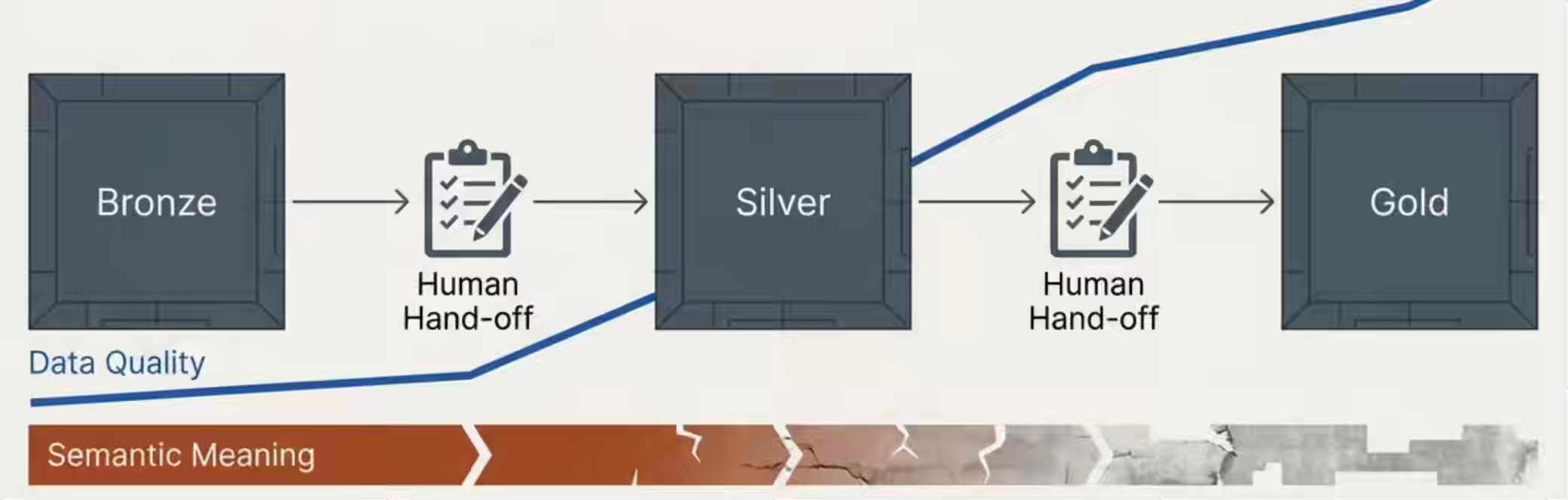
The medallion architecture — Bronze to Silver to Gold — is an assembly line designed for human inspection at each station. Raw data lands, gets progressively cleaned, and arrives ready for consumption. Each station assumes a human will inspect, validate, and pass the data forward. And at each handoff, context erodes — the original meaning collapses a little more, like a game of telephone played silently in the pipeline.
We optimized every layer of the data warehouse for human cognitive constraints. And just like the physical warehouse, those very optimizations become limitations when the operator changes.
Where the Analogy Holds — and Where It Breaks
I want to be precise about this, because imprecise analogies are how our industry ends up with decade-long hype cycles built on half-truths.
The analogy holds powerfully for navigation and discovery. Physical warehouses organized shelves for human wayfinding. Data warehouses organize tables for human querying. Robots don’t need aisle signs. Agents don’t need star schemas to find data. That part maps cleanly.
But here’s where it breaks: physical goods don’t change meaning based on how you store them. A box of shoes is a box of shoes, whether it sits on shelf A3 or shelf Z9. Data is different. How you structure data shapes what questions you can ask of it. A normalized schema enables different analytical patterns than a denormalized one. A slowly changing dimension preserves the temporal context that a snapshot table destroys.
Structure still matters for agent-operated data. It just serves a different purpose. Instead of organizing for human navigation — “how do I find the data?” — you organize for agent operation — “what data and context does this agent need for this task?” Think about how AI tools work with a scoped working folder. You don’t reorganize your filesystem into an agent-friendly layout. You give the agent a well-scoped boundary, and it operates within it. The structure shifts from navigational to operational — from shelf labels to access boundaries.
The Thinking Survives. The Format May Not
I took the last class Ralph Kimball taught before his retirement. I remember the vivid conversation around HBase (which was popular at the time) and the notion of versioning to handle slowly changing dimensions. I’ve internalized dimensional modeling deeply enough to know which parts are permanent and which parts are artifacts of their era.
Kimbal didn’t start the training with the star schema and slowly changing dimensions. Kimball’s dimensional modeling process starts with two steps: identify the business process and select the grain. These steps ask the most fundamental questions in data engineering — what does the business actually do, and at what level of detail does it matter? Only after answering those do you design the dimensions, the facts, and the star schema.
Steps one and two are context architecture. They always were. Identifying the business process means understanding the semantic reality of what the organization does. Selecting the grain means choosing the level of meaning that matters. That thinking is more relevant today than it was in 1996.
Steps three and four — the star schema, the dimension tables, the fact tables — were a rendering choice. They were the best output format for the consumer of that era: a human analyst writing SQL against a relational database. The star schema serialized business understanding into a structure that humans could query using the available tools.
The consumer has changed or is changing. The rendering should too. When the consumer is an AI agent, the same analytical thinking about business processes and grain produces a Context Store entry — a validated, versioned, queryable semantic definition — not a fact table. The thinking survives. The format may not.
Dismissing dimensional modeling entirely would be ignorant. Clinging to its output format when the consumer has fundamentally changed would be equally so.
The Pendulum
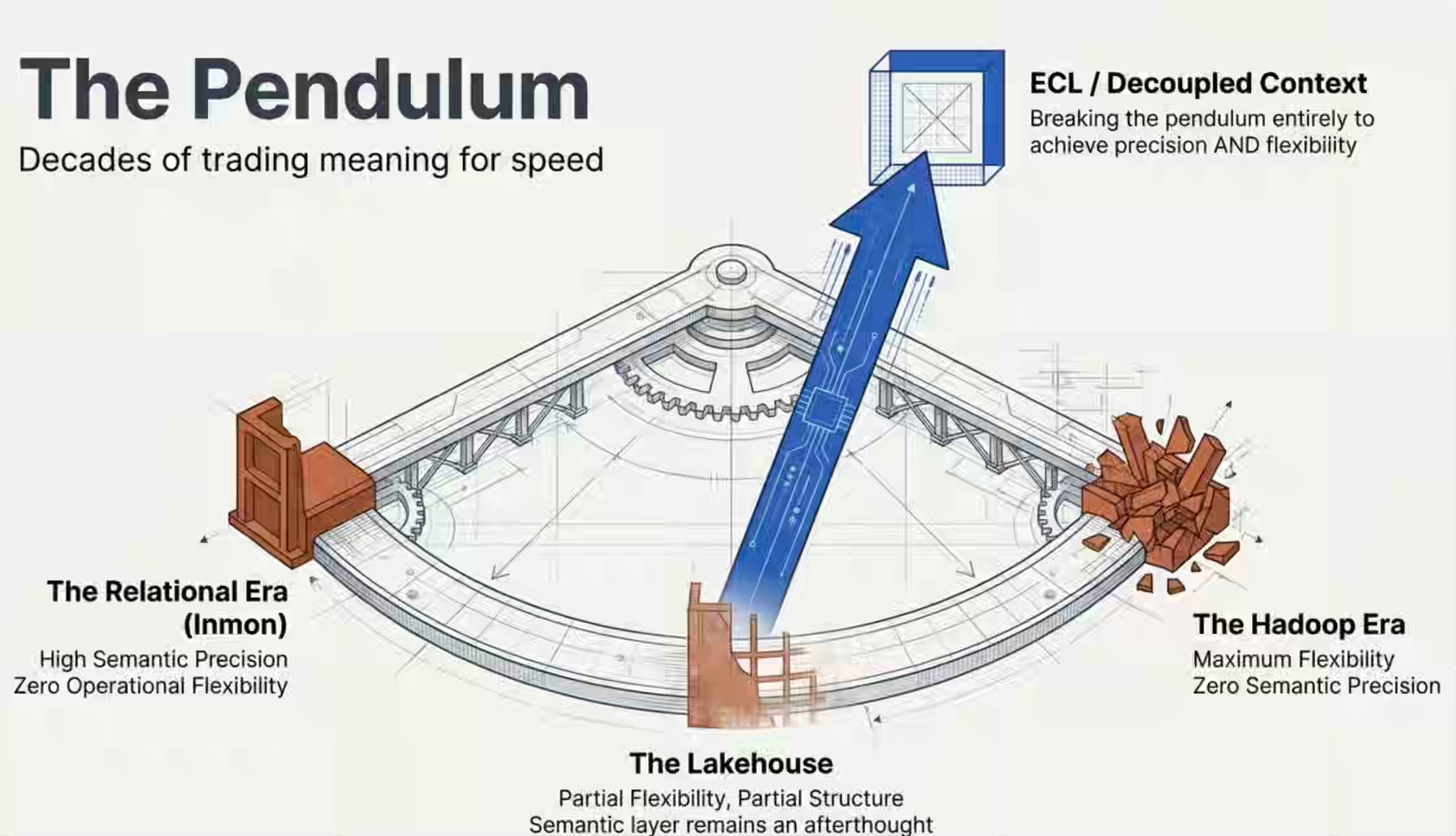
Every era of data architecture has tried to solve the same tension: semantic precision versus operational flexibility.
The relational era chose precision. ERDs, primary keys, foreign keys, referential integrity, constraints — the schema was the semantic contract. Bill Inmon’s Corporate Information Factory formalized this into an enterprise architecture. It worked. It encoded business meaning directly into the physical structure. But it was rigid. I remember interviewing at a company in the pre-Hadoop era and asking what their current priority was. The interviewer told me they were working on implementing a schema change in a day rather than a month. That was the state of the art — a month to add a column, because the semantic contracts were so tightly welded to the physical structure that touching one meant touching everything.
Hadoop’s answer was brute force. Sheer machine power, schema-on-read, commodity hardware — throw everything in and figure it out later. It broke the operational rigidity overnight. And it also broke every semantic contract the relational era had built. We traded meaning for speed and went too far. The data lake became a data swamp because nobody could remember what anything meant — the constraints that encoded that meaning were gone.
The lakehouse tried to find a middle ground. Iceberg, Delta, Hudi — the flexibility of the lake with some structure of the warehouse. Better. But the semantic layer remained an afterthought.
catalogs, documentation, and governance overlays that nobody maintained because nobody’s career depended on them being right.
Even recent efforts like Snowflake’s Open Semantic Interchange initiative acknowledge the gap — the industry is only now trying to standardize how semantic meaning travels between tools.
Each swing of the pendulum traded one problem for another. Rigidity for meaninglessness. Meaninglessness for a partial structure. What none of them achieved was decoupling — semantic precision that doesn’t require physical rigidity. Context that travels alongside the data but isn’t welded to the table structure. Change the schema in seconds. The context updates through the Contextualize pipeline. The meaning stays current without the rigidity.
That decoupling is what ECL provides. It’s the first architecture that doesn’t force you to choose between knowing what your data means and being able to change it.
The Graveyard of Good Intentions

I know what the skeptics are thinking, because I’ve thought it myself: we’ve heard this before.
Bill Inmon literally wrote the book on this in 2007 — Business Metadata: Capturing Enterprise Knowledge — which covers semantics, ontologies, business rules, and the capture of tacit knowledge. He laid out a complete methodology for capturing it. The methodology was sound. The economics weren’t there yet.
Business glossaries in the 2000s promised to capture institutional knowledge. They became static documents that nobody updated. Semantic layers in the 2010s promised a unified layer of meaning. They became another piece of middleware to maintain. Data catalogs promised discoverability and governance, but soon proved to be useless. Many became expensive shelfware. Enterprise knowledge graphs promised connected meaning. Most never made it past the proof-of-concept stage.
Every generation of data practitioners has pointed at the same north star: capture business meaning as a first-class artifact. Every generation has underestimated the organizational gravity that pulls teams back to “just get the data there, and we’ll figure out what it means later.”
So what makes this time structurally different? One thing: the consumer changed from forgiving to unforgiving.
When the consumer was a human analyst, missing context was inconvenient. The analyst would Slack a colleague, read the dbt code, ask in standup, and check the wiki. Humans are remarkably good at filling semantic gaps through social channels. Bad metadata produced frustrated analysts, not system failures.
When the consumer is an AI agent, missing context produces systematic errors at scale. The agent doesn’t Slack anyone. It doesn’t read tribal knowledge. It sees a column called rev_adj, makes its best inference, and acts — confidently, consistently, and potentially wrong across every downstream decision. Bad context doesn’t produce frustration. It produces hallucination at an enterprise scale.
For the first time, the cost of missing context exceeds the cost of maintaining it. That economic inversion is what none of the previous attempts had. Business glossaries failed because humans bore the cost of maintaining them, while the benefit was diffuse. The Context Store succeeds or fails based on whether agents produce reliable results — and that feedback loop is immediate, measurable, and impossible to ignore.
The graveyard is real. But the economics changed.
What Replaces It
ETL asked: Did the data land? ECL asks: Can the data be trusted? I introduced the ECL framework in my earlier article on data engineering after AI.
Extract remains. Data still moves from source systems to analytical environments. That work still requires engineering judgment about reliability, latency, and failure modes. AI handles more of the mechanical construction. Humans make the architectural decisions.
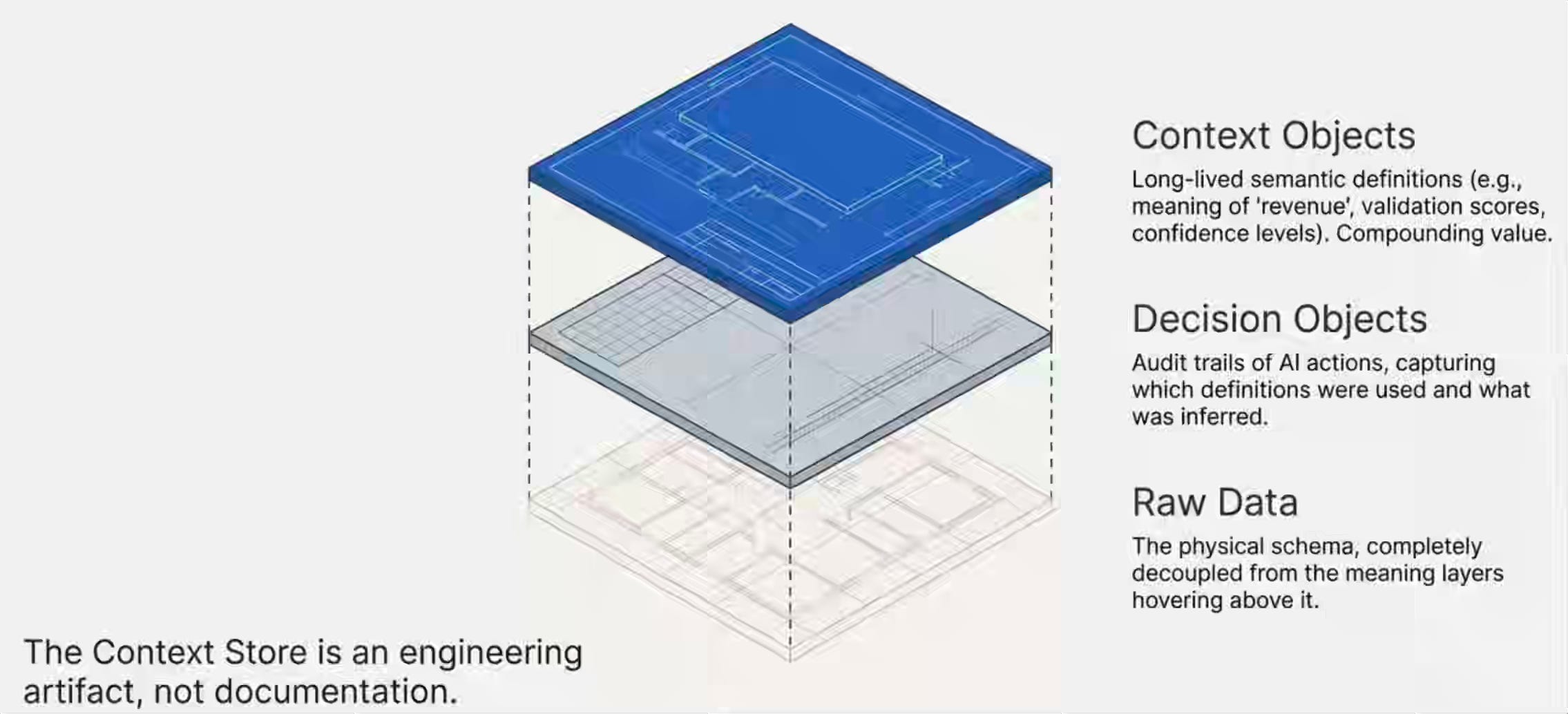
Contextualize is the new center of gravity. A dedicated, agentic pipeline that builds and maintains a living store of semantic context. It isn’t documentation. It isn’t a catalog. It’s an engineering artifact with its own trigger model, validation layer, and storage — the Context Store.
The Context Store holds two types of objects. Context objects capture long-lived semantic definitions — what “revenue” means, who validated that definition, when, and at what confidence level. These compounds increase in value over time. Decision objects capture what agents produce when they act on context — which definitions they used, what they inferred, and what they recommended. These create the audit trail.
Link connects entities across the data landscape — and emerging standards like Model Context Protocol (MCP) are starting to standardize how agents access data without moving it. Not just table joins — semantic relationships between business entities across systems. A customer in CRM is linked to a user in your product, linked to a session in your support tool. Whether you implement that as a graph, a mapping table, or a markdown file matters less than whether the linkage is validated and the semantic relationship is explicit.
And because data is inherently social in nature, you don’t build this all at once. You start with one business flow. One critical table. Early bind where you control the data and can hold producers accountable for meaning. Late bind where data comes from outside your accountability boundary — third-party feeds, undocumented internal systems, legacy data where the person who knew what the fields meant left five years ago. Even one table, well contextualized, starts compounding as you connect it to the next one, and the next one.
Long Live the Context Architect
The physical warehouse workers who resisted robotics didn’t save their jobs. They delayed their own transition. Those who moved into robotics coordination, system design, and exception architecture found themselves more valued, more strategic, and more central to the operation than they were when driving forklifts.
Data engineers who built their identity around moving data from one bucket to another have felt that identity under pressure for a while now. That pressure isn’t going away. AI will write your Spark jobs. AI will generate your dbt models. AI will build more pipelines in a year than your team could build in a decade.
But AI cannot decide what “revenue” means for your organization. It cannot negotiate data contracts between producing and consuming teams. It cannot design the appropriate level of context for an agent addressing a specific business problem. It cannot build the organizational agreements that make semantic definitions stick. That work requires institutional knowledge, cross-functional coordination, and architectural judgment. That work is context architecture.
The data engineer’s value migrates from pipeline reliability to semantic reliability. From “the job ran” to “the meaning is right.” From operating the warehouse floor to designing the system that makes robotic operation trustworthy.
The frontier is genuinely open. Nobody has this figured out yet. The practitioners who invest in the architecture of meaning — not just the mechanics of movement — will define this discipline for the next decade.
ETL is dead. Long live the Context Architect.
All rights reserved, Dewpeche Private Limited. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employers’ opinions.
Please don’t ever say “xyz” is dead. It makes you look like an idiot. I mean, really, really stupid and/or ignorant. Or a bot.
/unsubscribe
Largely agree with your views.
Had similar observations some time back.
https://substack.com/@mayankm/note/c-187457704?r=1fbv4
BTW, love the analogy 'Dead like landline, not like Latin' :)