
Evaluating Data Observability Tools: A Comprehensive Guide
Data Engineering Tools Evaluation Series


Click the Link Below to Get Your Free Data Observability Buyers Guide:
https://bit.ly/data-observability-buyers-guide
The Buyer Guide for Data Observability is out. Please feel free to make a copy or comment to add more criteria.
I want to extend my gratitude to the Data Heroes Community for their valuable insights and discussions, which served as the foundation for this piece. The points and thoughts shared here are largely drawn from the community's collective knowledge and contributions. Aswin & I have merely composed and organized their ideas to present the buyer’s guide.
The Rise of Data Observability
Data observability has become increasingly critical as companies seek greater visibility into their data processes. This growing demand has found a natural synergy with the rise of the data lake. In the pre-data-lake era, traditional data warehouses were limited by disk space and processing power. Storage and computing were tightly coupled within a single, large system, making running additional processes, such as observability tools, difficult without straining the system’s resources. As a result, monitoring data in real time was often an afterthought.
The advent of data lakes has changed the landscape of data infrastructure in two fundamental ways:
1. Decoupling of Storage and Compute: Data lakes allow observability tools to run alongside core data pipelines without competing for resources by separating storage from compute resources.
2. Comprehensive Data Management: Data lakes enable storing both structured and unstructured data in a single repository, providing a more holistic view of an organization’s data. This opens up new possibilities for monitoring and diagnosing data issues across various sources.
These innovations have driven the emergence of data observability tools, which can now operate efficiently without burdening the core infrastructure. Organizations can track, troubleshoot, and optimize their data pipelines in real-time, ensuring smoother operations and better insights.
However, as with any advanced tool, data observability comes with costs and complexities. The buyer’s guide aims to help data professionals make an informed decision when choosing the data observability tool.
Why Data Observability is More Relevant in Unified Data Architecture
In today’s data-driven world, organizations rely on massive amounts of data to make critical business decisions. However, data pipelines are often complex and distributed, making them prone to errors such as data loss, schema drift, and quality issues. A single failure can disrupt business operations, lead to compliance violations, and reduce decision-making effectiveness.
Data observability acts as the nervous system of your data platform, continuously monitoring data pipelines for issues like data quality degradation, freshness, and anomalies. It ensures you can trust the data flowing through your systems and react quickly to any issues. Observability provides full visibility into the health and performance of data systems, allowing teams to prevent outages and fix data issues proactively before they affect downstream processes.
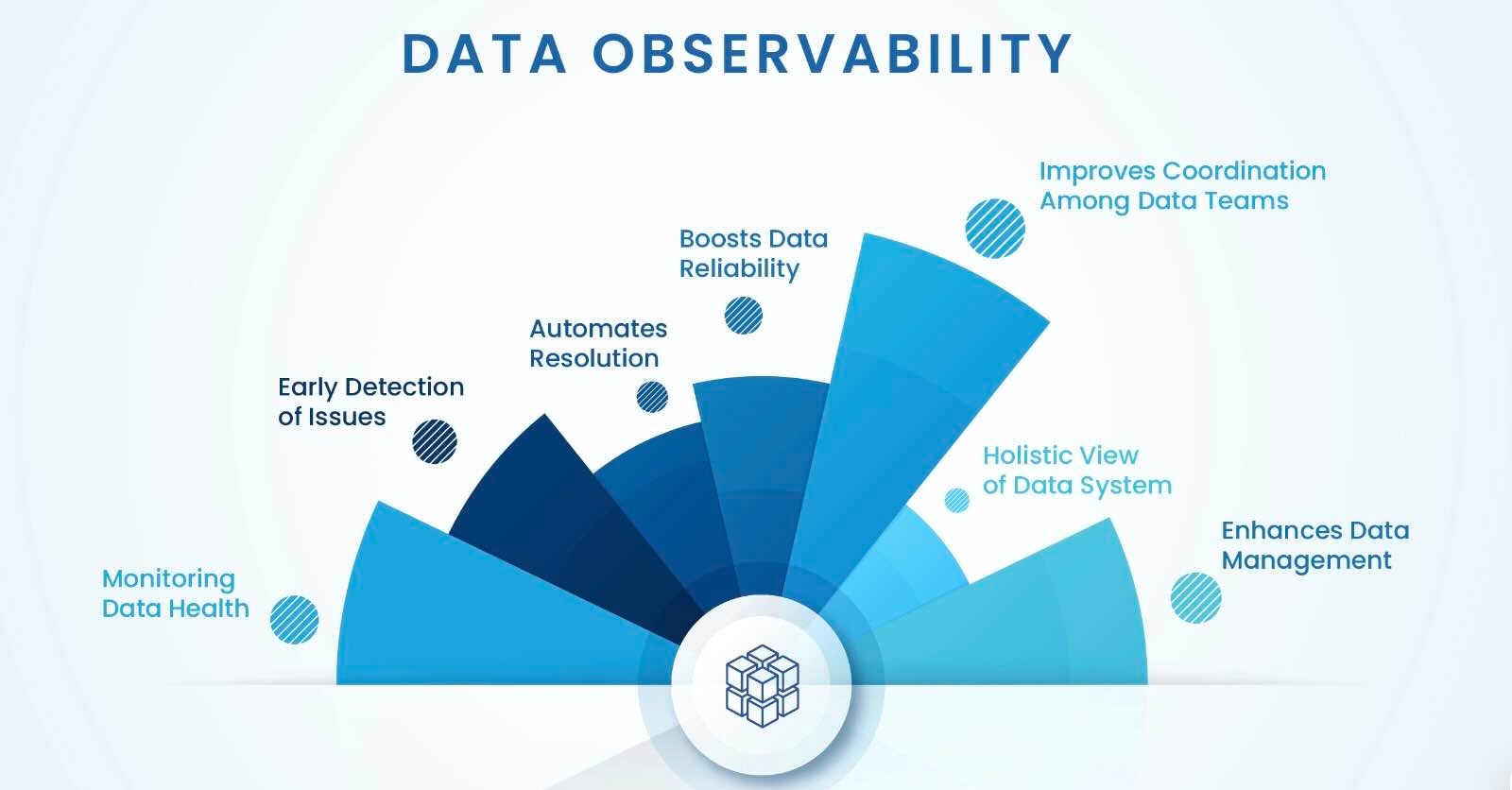
source: https://www.acceldata.io/why-data-observability
Without data observability, organizations risk making decisions based on incomplete, inaccurate, or outdated data, which can have serious consequences.
What is the Difference Between Data Testing and Data Observability?
Data testing and data observability are both critical to ensuring data quality but serve different purposes:
Data Testing
This involves writing specific test cases to verify that data meets the expected criteria at various points in the pipeline. Data tests check for missing values, schema mismatches, and incorrect data types. Testing is a proactive way to catch known issues, but it only works for pre-defined cases.
Data testing can be categorized into:
- Unit tests: Check individual components of the data pipeline.
- Integration tests: Ensure smooth interaction between systems.
- End-to-end tests: Validate the entire pipeline from source to target.
While necessary, data testing can only catch issues that have been explicitly anticipated.
Data Observability:
In contrast, observability is a continuous, real-time monitoring approach that offers holistic insight into data systems. It goes beyond pre-defined tests to detect unknown or unforeseen problems across the entire data pipeline, such as data drift, anomalies, or delayed data.

Source: MonteCarlo Data
Key Differences:
- Data testing is proactive, catching known problems.
- Data observability is reactive, monitoring for unknown issues in real-time.
Data testing checks for rule-based validations, while observability ensures overall pipeline health, tracking aspects like latency, freshness, and lineage.
In short, While a test can check if a dataset has 10,000 rows, observability ensures the data arriving continuously through the pipeline matches historical behavior, identifies trends, and flags anomalies.
How to Evaluate a Data Observability Tool
When selecting a data observability tool, assessing both functionality and how well it integrates into your existing data stack is important. Based on our evaluation criteria, here’s how to choose the right tool:
1. Integration & Connectivity:
The tool should seamlessly connect with your data sources, whether SaaS applications, databases, or cloud platforms.
2. Data Quality Monitoring:
Evaluate whether the tool can continuously monitor essential metrics such as:
- Schema drift detection: Automatically alerts you when schema changes occur.
- Anomaly detection: Identifies unexpected changes in your data.
- Data freshness checks: Ensures that data is timely and up to date.
- Custom data quality rules: Ability to set custom rules for your specific data quality needs.
A strong observability tool will not only detect these issues but also provide automated suggestions or alerts to fix them before they become larger problems.
3. End-to-End Observability:
The tool should provide full visibility across the entire pipeline, including data ingestion, transformation, and consumption. It should offer:
- Data lineage tracking: Understand the flow and transformations of data through various systems.
- Pipeline health monitoring: Track data health at every stage, preventing bottlenecks and data loss.
Reference: At Grab, engineers use observability to track every data point in their pipeline, ensuring reliable and scalable data infrastructure.
4. Real-Time Monitoring & Alerts:
Look for tools that provide real-time alerts to flag data issues as they happen. These alerts should be customizable based on thresholds or specific business rules, and the system should integrate with incident management platforms like PagerDuty or Opsgenie for immediate resolution.
Reference: Drift Monitoring Architecture explains how real-time data monitoring can prevent schema drift and other common issues.
5. Root Cause Analysis (RCA):
A good tool must offer robust RCA capabilities, enabling data engineers to quickly diagnose the cause of issues in the data pipeline. Visualization tools that map out pipeline dependencies are particularly helpful here.
6. Scalability & Performance:
Your observability tool should scale with your data volume and be able to monitor both small and enterprise-scale datasets. It should also support streaming data observability, ensuring that real-time data flows are continuously monitored.
Reference: Checkout.com demonstrates how to monitor large-scale data systems focusing on performance.
7. Automation & Machine Learning:
Advanced tools leverage machine learning to predict anomalies and suggest remediation steps. Automation of common tasks like reconciling data or fixing issues is essential for a tool to be efficient at scale.
Reference: DBT Test Options discusses how automation in testing and monitoring can increase efficiency.
8. Compliance & Security:
Ensure the tool helps you comply with regulations such as GDPR and HIPAA by providing features like audit trails, role-based access control, and data sovereignty features.
9. Cost-Effectiveness:
Evaluate the total cost of ownership of the tool, considering the initial investment and operational costs. The tool should offer a balance between features and pricing.
10. User Experience & Collaboration:
Look for customizable dashboards and collaboration features that make it easier for various teams (data engineers, analysts, etc.) to work together. Tools should also offer self-service capabilities, empowering users to monitor data quality independently.
Conclusion
Data observability has become a crucial component of a reliable data infrastructure in an era where data is the backbone of decision-making. While data testing is essential for checking known issues, it is not enough to maintain overall data health. Data observability takes this a step further, providing continuous, real-time insights into your data pipelines, enabling organizations to prevent costly outages and ensure data reliability at scale.
When choosing a data observability tool, keep in mind the comprehensive evaluation criteria discussed in this article. By selecting the right tool, you can ensure that your data pipelines are always healthy and deliver trustworthy and accurate data.
References:
- [Facebook Watch](https://m.facebook.com/watch/9445547199/490224945331402)
- [Grab Engineering](https://engineering.grab.com/data-observability)
- [Drift Monitoring Architecture](https://medium.com/@linghuang_76674/drift-monitoring-architecture-aa57fc26a19c)
- [DBT Test Options](https://datacoves.com/post/dbt-test-options)
- [Checkout.com Tech Blog](https://medium.com/checkout-com-techblog/testing-monitoring-the-data-platform-at-scale-e22d9cf433e8)
- [Policygenius Tech Blog](https://medium.com/policygenius-stories/data-warehouse-testing-strategies-for-better-data-quality-d5514f6a0dc9)
- [Monte Carlo](https://www.montecarlodata.com/blog-data-observability-in-practice-using-sql-1/)
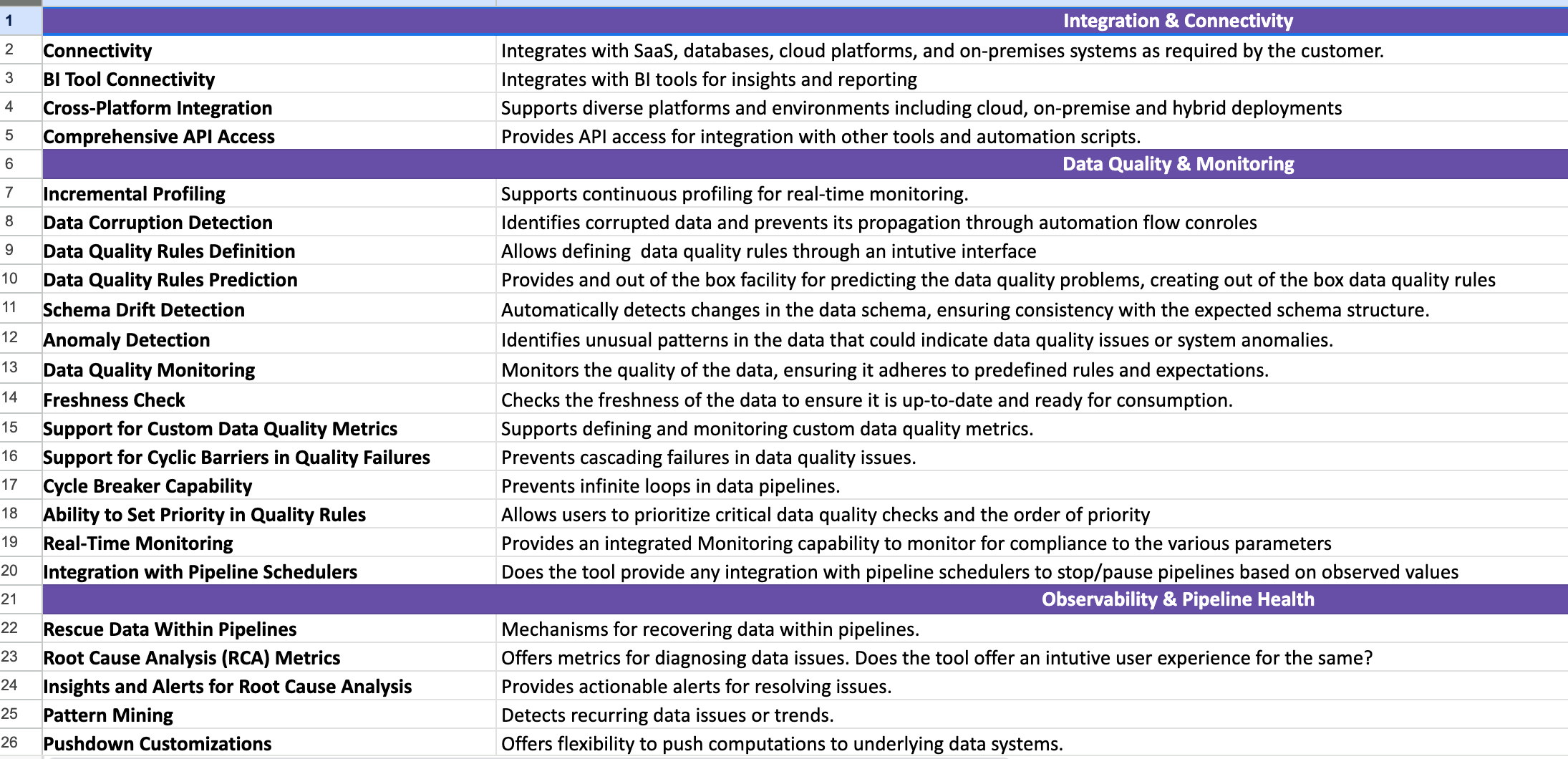
exhaustive points on Observability
Lot of companies ask build vs buy and how to integrate the complex web of applications. Any take on that?